FastVLM - 苹果公司推出的视觉语言模型
FastVLM是什么
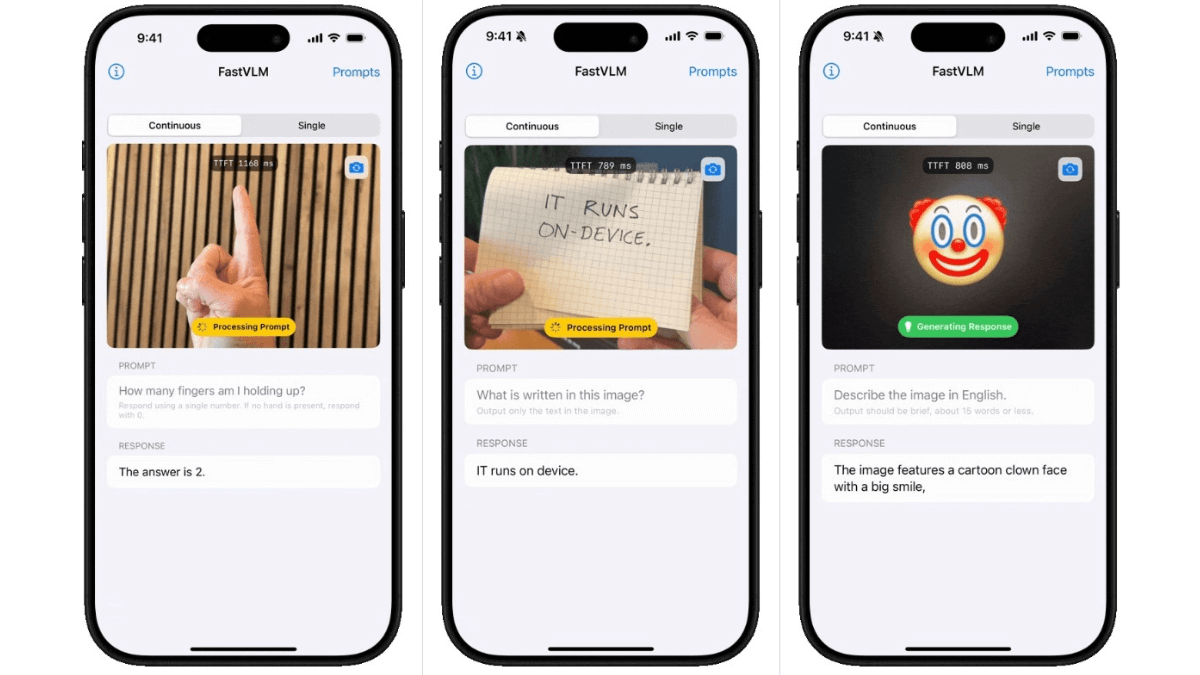
FastVLM(Fast Vision Language Model)是苹果公司推出的高效视觉语言模型。以FastViTHD混合视觉编码器为核心,融合了卷积和Transformer架构,可显著减少视觉token数量,降低编码时间和延迟。在处理高分辨率图像时,编码速度比同类模型快85倍,首次token生成时间(TTFT)提升了3.2倍,且视觉编码器尺寸更小,便于在移动设备上部署。
FastVLM的功能特色
- Processamento visual eficiente:FastVLM通过混合视觉编码器,结合卷积和Transformer架构,大幅减少视觉token数量,显著提升视觉信息的处理速度,尤其在高分辨率图像处理上表现出色。
- 低延迟交互:模型首次token生成时间显著缩短,能够快速响应用户输入,适合实时交互场景,如移动端图文问答助手,为用户提供即时反馈。
- Design leve:视觉编码器尺寸大幅缩小,便于在移动设备和边缘智能设备上部署,降低了硬件要求,提高了模型的可移植性和应用范围。
- alta precisão:在多项基准测试中,FastVLM的性能与更大模型相当,能够准确理解和生成与图像相关的内容,保证了模型的实用性。
- 简化架构:仅通过调整输入图像尺寸实现token数量和分辨率的平衡,无需额外的token剪枝,简化了模型设计,降低了开发和部署的复杂度。
FastVLM的核心优势
- Capacidade de processamento eficiente:FastVLM采用混合视觉编码器,结合卷积和Transformer架构,显著减少视觉token数量,提升编码效率,尤其在高分辨率图像处理上表现出色,编码速度比同类模型快85倍。
- Resposta de baixa latência:首次token生成时间(TTFT)大幅缩短,响应速度快,适合实时交互场景,如移动端图文问答助手,能够快速给出答案。
- Design leve:视觉编码器尺寸大幅缩小,比同类模型小3.4倍,便于在移动设备和边缘智能设备上部署,降低了硬件要求,提高了模型的可移植性。
- alta precisão:在多项基准测试中,FastVLM的性能与更大模型相当,能够准确理解和生成与图像相关的内容,保证了模型的实用性。
- 简化设计:仅通过调整输入图像尺寸实现token数量和分辨率的平衡,无需额外的token剪枝,简化了模型设计,降低了开发和部署的复杂度。
FastVLM的官网是什么
- Repositório do GitHub:https://github.com/apple/ml-fastvlm
- Biblioteca do modelo HuggingFace:https://huggingface.co/collections/apple/fastvlm-68ac97b9cd5cacefdd04872e
- Artigo técnico do arXiv:https://www.arxiv.org/pdf/2412.13303
FastVLM的适用人群
- Usuários de dispositivos móveis:FastVLM适合使用智能手机或平板电脑的用户,需要快速获取图像相关信息的人群,如学生、旅行者和上班族。
- 智能穿戴设备用户:对于使用智能眼镜或其他可穿戴设备的用户,FastVLM能提供实时场景提示和信息辅助,提升用户体验。
- Educadores e alunos:在教育领域,FastVLM可以帮助教师和学生通过图像问答快速获取知识,辅助教学和学习。
- Equipe da empresa:在办公场景中,FastVLM能帮助员工快速处理图像中的文字和数据,提高工作效率,适用于需要移动办公的人员。
- Desenvolvedor de tecnologia:对于开发移动应用或智能设备的开发者,FastVLM提供了一个高效、轻量级的视觉语言模型,可用于构建各种智能交互功能。
© declaração de direitos autorais
Direitos autorais do artigo Círculo de compartilhamento de IA A todos, favor não reproduzir sem permissão.
Artigos relacionados



Nenhum comentário...