
Doubao-1.5-pro lançado: um novo modelo de base multimodal para o equilíbrio final
Doubao-1.5-pro
Perfil do modelo
O Doubao-1.5-pro é um arquivo altamente esparso Arquitetura do MoENos quatro quadrantes de Prefill/Decode e Attention/FFN, as características de computação e acesso são significativamente diferentes. Para os quatro quadrantes diferentes, adotamos hardware heterogêneo combinado com diferentes estratégias de otimização de baixa precisão para aumentar significativamente a taxa de transferência e, ao mesmo tempo, garantir baixa latência e reduzir o custo total, levando em conta as metas de otimização de TTFT e TPOT, alcançando o equilíbrio final entre desempenho e eficiência de inferência.
- parâmetro de ativação menorDesempenho de modelos densos muito grandes: superando o desempenho de modelos densos muito grandes.
- Adaptação para várias cenasDesempenho superior em vários benchmarks de análise.
Avaliação de desempenho
Resultados do Doubao-1.5-pro em vários benchmarks
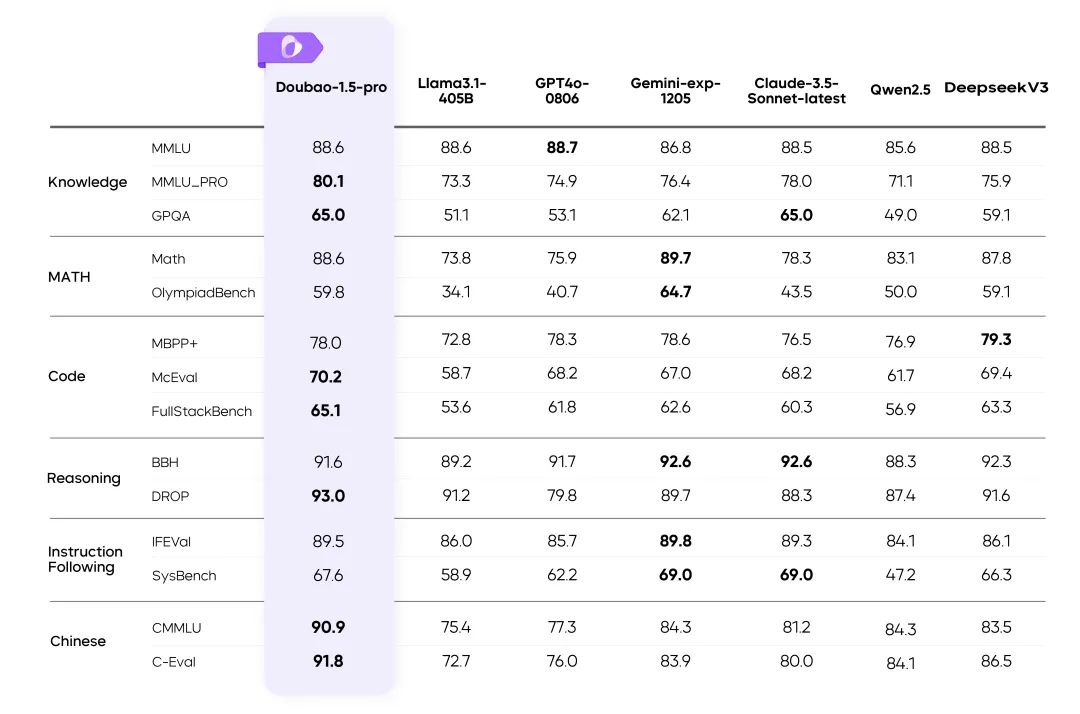
instruções::
- As métricas para o restante dos modelos na tabela foram extraídas dos resultados oficiais, e as partes não publicadas foram feitas por uma plataforma de avaliação interna.
- GPT4o-0806 Excelente desempenho em análises públicas de modelos de linguagem, consulte: simple-evals.
⚙️ Equilíbrio entre desempenho e raciocínio
Arquitetura eficiente do MoE
- fazer uso de Arquitetura MoE esparsa Obtenção da otimização dupla da eficiência do treinamento e do raciocínio.
- Destaques da pesquisaDeterminar a proporção ideal de equilíbrio entre desempenho e eficiência por meio da Lei de Escala de Esparsidade.
Perda de treinamento vs.

Comparação de desempenho de modelos
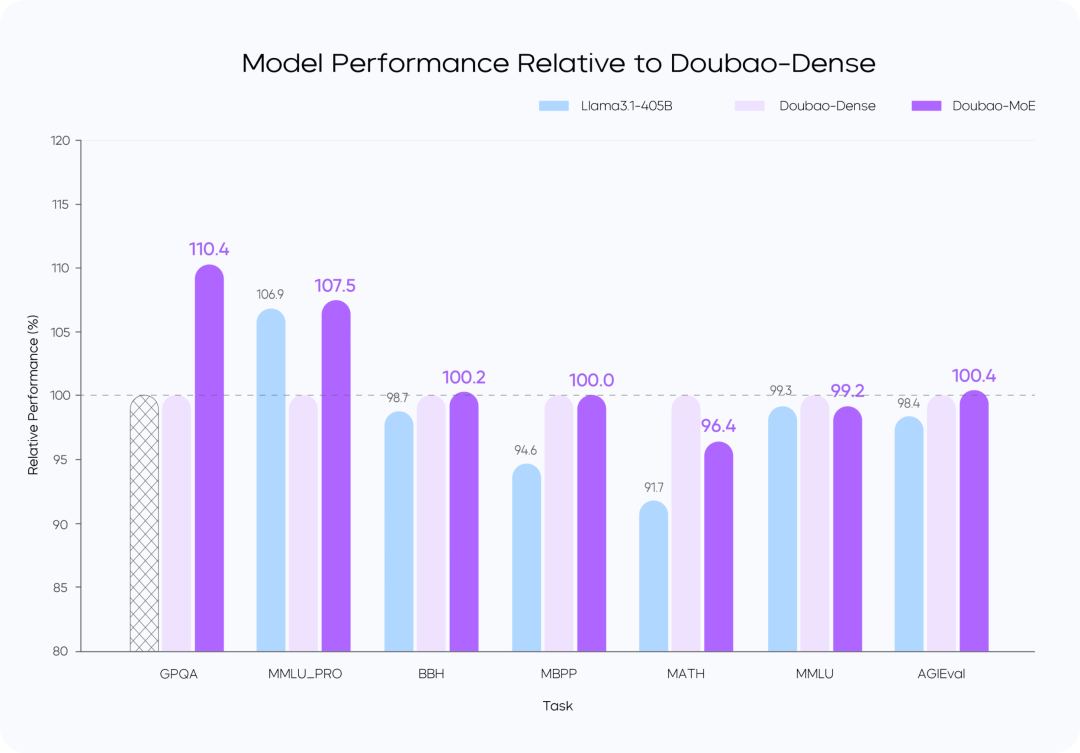
instruções::
- O modelo Doubao-MoE supera um modelo denso com sete vezes o número de parâmetros ativados (DoubaoDense).
- Doubao O treinamento de modelos densos é mais eficiente do que Lhama 3.1-405BA qualidade dos dados e a otimização da hiper-referência são fundamentais.
Raciocínio de alto desempenho
Otimização de recursos computacionais e de acesso
O Doubao-1.5-pro tem bom desempenho em quatro quadrantes computacionais: Preenchimento, Decodificação, Atenção e FFN.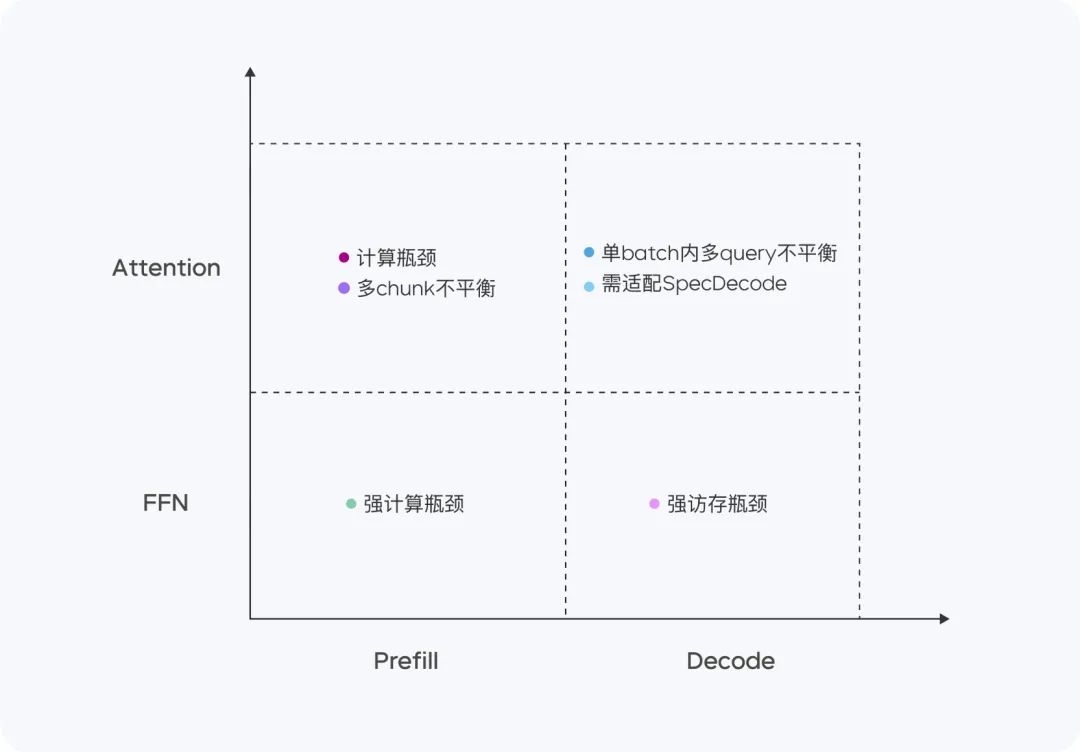
Na fase de Prefill, o gargalo de comunicação e acesso não é óbvio, mas o gargalo de computação é facilmente alcançado. Considerando as características da atenção unidirecional do LLM, realizamos o Chunk-PP Prefill Serving em vários dispositivos com altas taxas de acesso computacional, de modo que a taxa de utilização do Tensor Core no sistema on-line seja próxima de 60%.
- Prefill Attention: estende a implementação de código aberto do FlashAttention de 8 bits com instruções como MMA/WGMMA, combinadas com Per N tokens A estratégia de quantificação por sequência garante que essa fase possa ser executada sem perdas em GPUs de diferentes arquiteturas. Enquanto isso, ao modelar o consumo de atenção de fatias de diferentes comprimentos e ao combinar com a estratégia dinâmica de lotes de consultas cruzadas, ele alcança o equilíbrio entre placas durante a execução do Chunk-PP, eliminando efetivamente a execução vazia causada pelo desequilíbrio de carga;
- FFN de pré-preenchimento: a quantificação do W4A8 reduz efetivamente a sobrecarga de acesso de especialistas em MoE esparsos e fornece mais entradas para o estágio FFN por meio da estratégia de lote de consultas cruzadas, o que melhora a MFU para 0,8.
Na fase de decodificação, o gargalo computacional não é óbvio, mas os requisitos de comunicação e memória são relativamente altos. Usamos o Serving, um dispositivo com menos computação e memória, para obter um ROI mais alto e, ao mesmo tempo, usamos amostragem de custo muito baixo e estratégia de decodificação especulativa para reduzir as métricas de TPOT.
- Decodificar a atenção: o TP é implementado para otimizar o cenário comum de grandes diferenças nos comprimentos de KV de diferentes consultas em um único lote por meio de pesquisa heurística e estratégia agressiva de divisão de frases longas; em termos de precisão, a quantificação por N tokens por sequência ainda é adotada; além disso, o cálculo da atenção durante a amostragem aleatória é otimizado para garantir que o cache de KV seja acessado apenas uma vez. Além disso, otimizamos o cálculo da atenção durante o processo de amostragem aleatória para garantir que o cache KV seja acessado apenas uma vez.
- Decodificar FFN: manter o W4A8 quantificado e implantado usando EP.
Em geral, implementamos as seguintes otimizações no sistema Serving separado por PD:
- Backend RPC personalizado para transferência de Tensor e eficiência de transferência de Tensor otimizada na rede TCP/RDMA por meio de cópia zero, paralelismo de vários fluxos etc., o que, por sua vez, melhora a eficiência de transferência do cache KV sob separação de PD.
- Ele oferece suporte à alocação flexível e à expansão e contração dinâmicas de clusters de Prefill e Decode, e realiza a expansão elástica de HPA para cada função de forma independente para garantir que tanto o Prefill quanto o Decode não tenham aritmética redundante e que a alocação aritmética dos dois lados esteja alinhada com o padrão de tráfego on-line real.
- Na estrutura da computação da GPU e do pré e pós-processamento assíncrono da CPU, de modo que a etapa N de raciocínio da GPU quando a CPU lança antecipadamente o Kernel da etapa N + 1, para manter a GPU sempre cheia, toda a ação de processamento da estrutura da GPU raciocina sem sobrecarga. Além disso, com nossa solução de cluster de servidor desenvolvida por nós mesmos e suporte flexível para chips de baixo custo, o custo de hardware é significativamente menor do que a solução do setor. Também otimizamos significativamente a eficiência da comunicação de pacotes por meio de NICs personalizadas e protocolos de rede desenvolvidos por nós mesmos. No nível aritmético, conseguimos uma sobreposição eficiente (Overlap) entre a computação e a comunicação, garantindo assim a estabilidade e a eficiência do raciocínio distribuído em vários computadores.
Rotulagem de dados: sem atalhos
- Criar um sistema eficiente de produção de dados que combine Equipe de rotulagem responder cantando Modelagem de técnicas de autoelevaçãoA qualidade dos dados foi significativamente aprimorada.
🖼️ Recursos multimodais
Multimodalidade visual: cenas complexas facilitadas
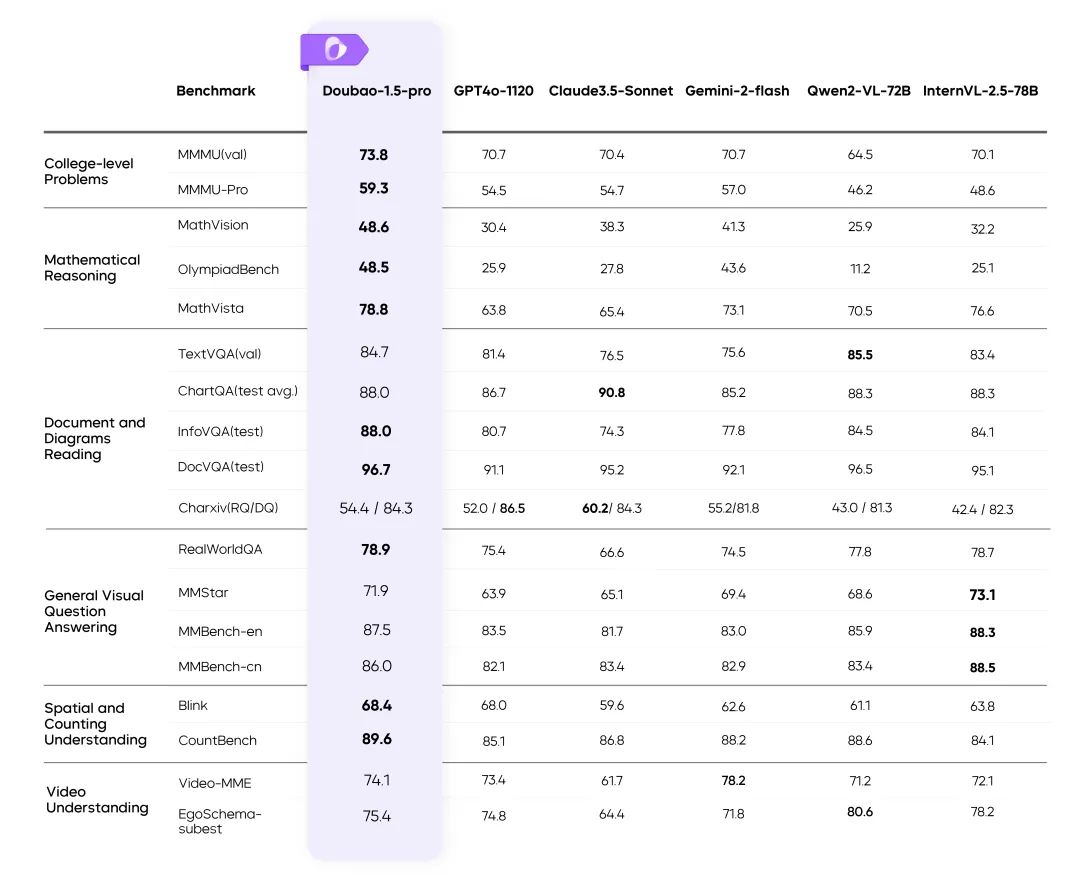
Treinamento de resolução dinâmica: aprimoramento da taxa de transferência 60%
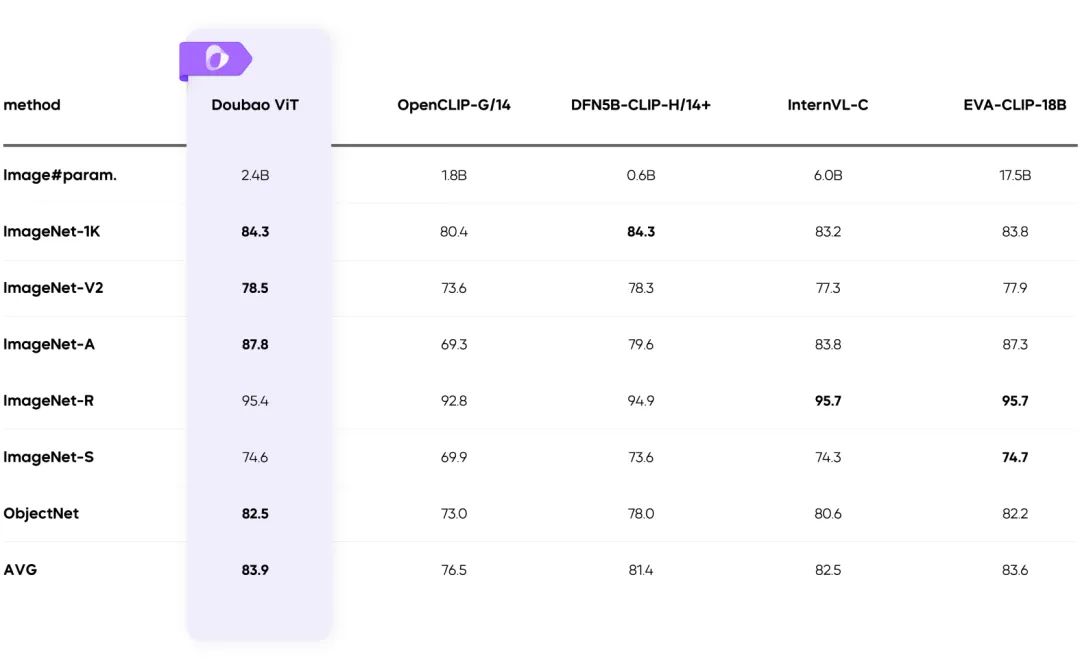
- Resolve o problema de carga desigual do codificador visual e melhora significativamente a eficiência.
Resumo
O Doubao-1.5-pro encontra o equilíbrio ideal entre alto desempenho e baixo custo de inferência e faz avanços em cenários multimodais:
- Projeto inovador de arquitetura esparsa.
- Dados de treinamento e sistemas de otimização de alta qualidade.
- Conduzindo um novo benchmark em tecnologia multimodal.
© declaração de direitos autorais
Direitos autorais do artigo Círculo de compartilhamento de IA A todos, favor não reproduzir sem permissão.
Artigos relacionados



Nenhum comentário...