DINOv3 - Modelo básico de visão autossupervisionada de última geração da Meta AI
O que é o DINOv3?
DINOv3 Sim Meta AI O DINOv3 é uma nova geração de modelo de base de visão autossupervisionada, que adota o paradigma de aprendizado autossupervisionado para aprender recursos de imagem sem rotular dados. O DINOv3 oferece duas arquiteturas de rede de backbone, ViT e ConvNeXt, das quais a ViT-7B é a maior versão no momento, contendo 6,7 bilhões de parâmetros. O modelo pode gerar representações de recursos densos de alta qualidade que capturam com precisão as relações locais e as informações espaciais das imagens. Ele tem um bom desempenho em uma ampla gama de tarefas visuais, como classificação de imagens, detecção de alvos, segmentação semântica, etc., e pode superar muitos modelos profissionais sem o ajuste fino específico da tarefa. O DINOv3 oferece suporte à extração de recursos de alta resolução, o que é adequado para análise de imagens médicas, monitoramento ambiental e outros cenários que exigem recursos de alta precisão.
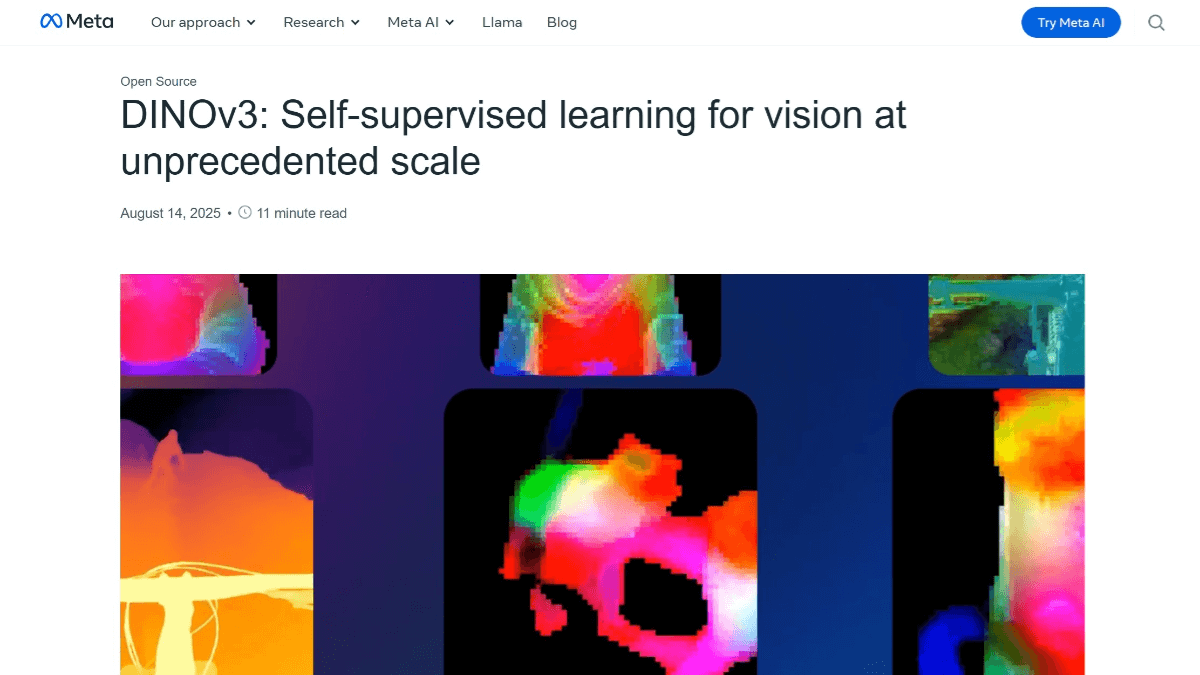
Recursos do DINOv3
- Capacidade de aprendizado autossupervisionadoO modelo pode aprender recursos de imagem sem dados rotulados e resolve o problema de degradação de recursos no treinamento de longo prazo, aprimorando a preparação de dados e introduzindo a ancoragem Gram, o que melhora a capacidade de generalização do modelo.
- Várias arquiteturas de rede de backboneDuas arquiteturas de rede de backbone, ViT e ConvNeXt, estão disponíveis para atender a diferentes necessidades de computação, sendo a ViT-7B a maior versão até o momento, com 6,7 bilhões de parâmetros.
- Representação de recursos de alta qualidadeRepresentações de recursos densos de alta qualidade que capturam com precisão as relações locais e as informações espaciais das imagens para uma ampla gama de tarefas visuais.
- Versatilidade em multitarefasO sistema de classificação de imagens da Microsoft tem um bom desempenho em tarefas como classificação de imagens, detecção de alvos e segmentação semântica, superando muitos modelos profissionais sem o ajuste fino específico da tarefa e reduzindo significativamente os custos de inferência.
- Extração de recursos de alta resoluçãoExtração de recursos de alta resolução: suporta a extração de recursos de alta resolução para cenários que exigem recursos de alta precisão, como análise de imagens médicas e monitoramento ambiental.
Principais benefícios do DINOv3
- Aprendizagem autossupervisionada avançadaEle não requer uma grande quantidade de dados rotulados e consegue um aprendizado eficiente por meio de um mecanismo inovador de autossupervisão, que resolve o problema de degradação de recursos e melhora a capacidade de generalização do modelo.
- Opções flexíveis de arquiteturaAs arquiteturas de rede de backbone ViT e ConvNeXt estão disponíveis para atender a diferentes recursos de computação e requisitos de tarefas, equilibrando desempenho e eficiência.
- Representação de recursos de alta qualidadeCaracterísticas: Os recursos gerados capturam com precisão as relações locais e as informações espaciais da imagem e são adequados para uma ampla gama de tarefas visuais com excelente desempenho.
- Versatilidade em multitarefasDesempenho superior ao de modelos profissionais sem ajuste fino específico em tarefas como classificação de imagens, detecção de alvos, segmentação semântica etc., reduzindo os custos de desenvolvimento.
- Extração de recursos de alta resoluçãoSuporte para extração de recursos de alta resolução e é adequado para análise de imagens médicas, monitoramento ambiental e outros cenários que exigem alta precisão.
- Código aberto e facilidade de usoCódigo e modelos de código-fonte aberto, suporte para as bibliotecas Hugging Face Hub e Transformers, fácil de começar rapidamente e desenvolvimento de aplicativos.
Qual é o site oficial do DINOv3?
- Site do projeto:: https://ai.meta.com/blog/dinov3-self-supervised-vision-model/
- Biblioteca do modelo HuggingFace:: https://huggingface.co/docs/transformers/main/en/model_doc/dinov3
- Documentos técnicos:: https://ai.meta.com/research/publications/dinov3/
Para quem é o DINOv3
- Pesquisadores de visão computacionalDINOv3 oferece recursos avançados de aprendizado autossupervisionado e representações de recursos de alta qualidade, adequados para profissionais envolvidos em pesquisas sobre tarefas visuais, como classificação de imagens, detecção de alvos e segmentação semântica.
- Desenvolvedores de aprendizagem profundaCódigo-fonte aberto e modelos pré-treinados tornam o DINOv3 ideal para que os desenvolvedores de aprendizagem profunda criem e implementem rapidamente aplicativos de visão para cenários que exigem desenvolvimento e otimização eficientes.
- Especialista em imagens médicasDescrição: O recurso de extração de recursos de alta resolução tem grande potencial no campo da análise de imagens médicas para tarefas de diagnóstico médico que exigem recursos de alta precisão, como análise de raios X, tomografia computadorizada e ressonância magnética.
- Profissionais de monitoramento ambiental e de sistemas de informações geográficas (GIS)DINOv3 pode ser usado para tarefas de monitoramento ambiental, como análise de imagens de satélite e monitoramento de desmatamento, fornecendo suporte técnico para trabalhos relacionados ao GIS.
- Engenheiro de visão de robôsDINOv3: Os recursos de visão de alta precisão e a versatilidade multitarefa do DINOv3 o tornam ideal para sistemas de visão robótica para tarefas de percepção visual em ambientes complexos, como os robôs de exploração de Marte.
© declaração de direitos autorais
Direitos autorais do artigo Círculo de compartilhamento de IA A todos, favor não reproduzir sem permissão.
Artigos relacionados


Nenhum comentário...