
Projeto e implementação do DeepSearch e do DeepResearch

Estamos apenas em fevereiro e a pesquisa profunda já está se tornando o novo padrão de pesquisa para 2025. Gigantes como o Google e a OpenAI revelaram seus produtos de "pesquisa profunda" em um esforço para ficar à frente da onda tecnológica. (Também nos orgulhamos de ter lançado nosso produto de código abertonode-deepresearch).
Perplexidade seguiu o exemplo com sua Deep Research, enquanto a X AI de Musk deu um passo além ao integrar recursos de pesquisa profunda diretamente em sua Grok 3, que é essencialmente uma variante do Deep Research.
Sinceramente, o conceito de pesquisa profunda não é uma grande inovação; é essencialmente o que costumávamos chamar de RAG (Retrieval Augmented Generation) ou quizzing multihop no ano passado. Mas no final de janeiro deste ano, com Deepseek-r1 No entanto, após seu lançamento, ele ganhou atenção e crescimento sem precedentes.
No último fim de semana, tanto o Baidu Search quanto o Tencent WeChat Search integraram o Deepseek-r1 em seus mecanismos de busca.Ao incorporar processos de pensamento e raciocínio de longo prazo ao sistema de busca, é possível obter uma recuperação mais precisa e aprofundada do que nunca.
Mas por que essa mudança está acontecendo agora? Ao longo de 2024, a "Deep(Re)Search" não parece ter atraído muita atenção. Deve-se lembrar que, no início de 2024, o Stanford NLP Lab publicou TEMPESTADE Projeto, geração de relatórios longos com base na Web. Será que é só porque "Deep Search" parece mais moderno do que mais QA, RAG ou STORM? Honestamente, porém, às vezes basta uma reformulação bem-sucedida da marca para que o setor adote repentinamente algo que já existe.
Acreditamos que o verdadeiro ponto de inflexão é o lançamento da OpenAI em setembro de 2024 doo1-previewEle introduziu o conceito de "computação em tempo de teste" e mudou sutilmente a percepção do setor.O termo "computar enquanto raciocina" refere-se ao investimento de mais recursos computacionais na fase de raciocínio (ou seja, a fase em que o modelo de linguagem grande gera o resultado final), em vez de se concentrar nas fases de pré-treinamento ou pós-treinamento. Exemplos clássicos incluem o raciocínio Chain-of-Thought (CoT), além de abordagens como"Wait" Técnicas como injeção (também conhecida como controle de orçamento), que dão ao modelo um escopo mais amplo para reflexão interna, como avaliação de várias respostas possíveis, planejamento mais aprofundado e autorreflexão antes de dar uma resposta final.
Esse conceito de "computação enquanto raciocina", bem como os modelos que se concentram no raciocínio, levam os usuários a aceitar um conceito de "gratificação atrasada":Troque tempos de espera mais longos por resultados mais úteis e de maior qualidade. Como no famoso experimento do marshmallow de Stanford, as crianças que conseguem resistir à tentação de comer um marshmallow imediatamente para poder comer dois marshmallows mais tarde tendem a ter mais sucesso a longo prazo. O deepseek-r1 solidifica ainda mais essa experiência do usuário, que a maioria dos usuários aceitou implicitamente, quer você goste ou não.
Isso marca um afastamento significativo das necessidades de pesquisa tradicionais. No passado, se a sua solução não conseguisse dar uma resposta em 200 milissegundos, era praticamente um fracasso. Mas em 2025, desenvolvedores de pesquisa experientes e RAG Engenheiros, coloquem a precisão e a revocação top-1 antes da latência. Os usuários se acostumaram a tempos de processamento mais longos: desde que possam ver o sistema lutando com a<thinking>.
Em 2025, a exibição do processo de raciocínio tornou-se uma prática padrão, com muitas interfaces de bate-papo renderizadas em áreas dedicadas da interface do usuário <think> O conteúdo.
Neste artigo, discutiremos os princípios do DeepSearch e do DeepResearch examinando nossa implementação de código aberto. Apresentaremos as principais decisões de design e apontaremos as possíveis ressalvas.
O que é Deep Search?
A ideia central do DeepSearch é encontrar a resposta ideal percorrendo os três estágios de pesquisa, leitura e raciocínio até que a resposta ideal seja encontrada. A sessão de pesquisa explora a Internet usando um mecanismo de pesquisa, enquanto a sessão de leitura se concentra na análise exaustiva de páginas da Web específicas (por exemplo, usando o Jina Reader). A sessão de raciocínio é responsável por avaliar o estado atual e decidir se o problema original deve ser dividido em subproblemas menores ou se devem ser tentadas estratégias de pesquisa alternativas.
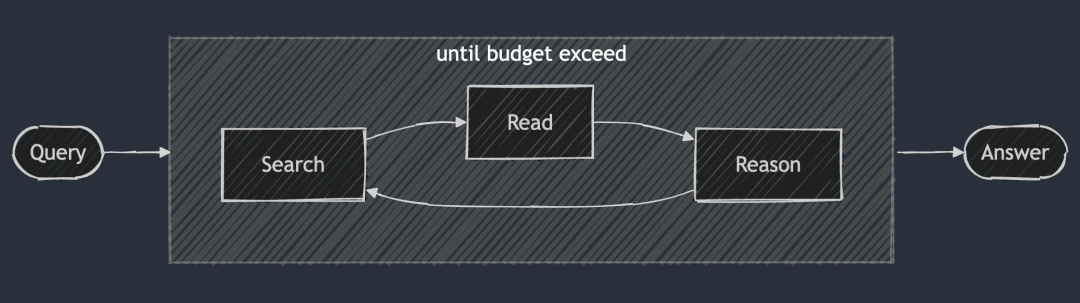 DeepSearch - Pesquisa contínua, leitura de páginas da Web e raciocínio até que a resposta seja encontrada (ou além) token (Orçamento).
DeepSearch - Pesquisa contínua, leitura de páginas da Web e raciocínio até que a resposta seja encontrada (ou além) token (Orçamento).
Ao contrário do sistema RAG 2024, que normalmente executa um único processo de geração de pesquisa, o DeepSearch executa várias iterações que exigem condições de parada explícitas. Essas condições podem se basear em limites de uso de tokens ou no número de tentativas fracassadas.
Experimente o DeepSearch em search.jina.ai e observe o <thinking>nele para ver se você consegue identificar onde o loop ocorre.
Em outras palavras.O DeepSearch pode ser visto como um LLM Agent equipado com várias ferramentas da Web, como mecanismos de pesquisa e leitores da Web.O agente analisa as observações atuais e as ações anteriores para determinar o próximo curso de ação: dar uma resposta diretamente ou continuar explorando a rede. Isso cria uma arquitetura de máquina de estado, em que o LLM é responsável por controlar as transições entre os estados.
Em cada ponto de decisão, você tem duas opções disponíveis: pode criar dicas que permitam que o modelo generativo padrão produza instruções de ação específicas; ou, alternativamente, pode usar um modelo de inferência especializado como o Deepseek-r1 para derivar naturalmente a próxima ação que deve ser tomada. No entanto, mesmo com o r1, você precisará interromper periodicamente o processo generativo para injetar o resultado da ferramenta (por exemplo, resultados de pesquisa, conteúdo da página da Web) no contexto e solicitar que ele continue com o processo de raciocínio.
Em última análise, esses são apenas detalhes de implementação. Independentemente de você estar criando palavras-chave ou apenas usando um modelo de inferência, oTodos eles seguem os princípios centrais de design do DeepSearch: pesquisar, ler e inferirdo ciclo contínuo.
E o que é DeepResearch?
O DeepResearch adiciona ao DeepSearch uma estrutura estruturada para gerar relatórios de pesquisa de formato longo. Seu fluxo de trabalho geralmente começa com a criação de um índice e, em seguida, aplica sistematicamente o DeepSearch a cada seção necessária do relatório: da introdução ao trabalho relacionado, à metodologia e à conclusão final. Cada seção do relatório é gerada pela alimentação de perguntas de pesquisa específicas no DeepSearch. Por fim, todas as seções foram integradas em uma única dica para melhorar a coerência da narrativa geral do relatório.
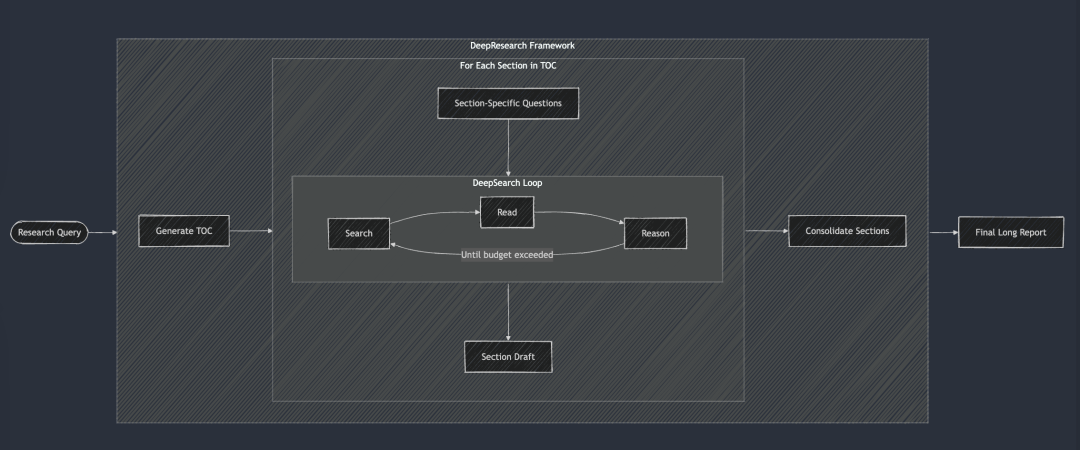 O DeepSearch serve como o bloco de construção básico para o DeepResearch. Cada capítulo é construído iterativamente por meio do DeepSearch e, em seguida, a coerência geral é aprimorada antes da geração do relatório final longo.
O DeepSearch serve como o bloco de construção básico para o DeepResearch. Cada capítulo é construído iterativamente por meio do DeepSearch e, em seguida, a coerência geral é aprimorada antes da geração do relatório final longo.
Em 2024, também fizemos o projeto "Pesquisa" internamente e, naquela época, para garantir a coerência do relatório, adotamos uma abordagem um tanto estúpida, que era levar todos os capítulos em consideração em cada iteração e fazer vários aprimoramentos de coerência. Mas agora parece que essa abordagem é um pouco difícil demais, porque os grandes modelos de linguagem atuais têm uma janela de contexto muito longa, e é possível concluir revisões coerentes de uma só vez, o que é muito mais eficaz.
No entanto, não lançamos o projeto "Pesquisa" por vários motivos:
O mais notável é que a qualidade dos relatórios não atendia de forma consistente aos nossos padrões internos. Nós o testamos com duas consultas internas conhecidas: "Análise da concorrência da Jina AI" e "Estratégia de produto da Jina AI". Os resultados foram decepcionantes, os relatórios eram medíocres e sem brilho, e não nos proporcionaram nenhuma surpresa "ah-ha". Em segundo lugar, a confiabilidade dos resultados da pesquisa é ruim, e a ilusão é um problema sério. Por fim, a legibilidade geral é ruim, com muita repetição e redundância entre as seções. Em resumo, é inútil. E o relatório é tão longo que é uma perda de tempo e uma leitura improdutiva.
No entanto, esse projeto também nos proporcionou uma experiência valiosa e gerou vários subprodutos:
Por exemplo.Nossa profunda compreensão da confiabilidade dos resultados de pesquisa e da importância da verificação de fatos no nível do parágrafo e até mesmo da frase levou diretamente ao desenvolvimento subsequente do endpoint g.jina.ai.Também percebemos o valor da expansão de consultas e começamos a investir esforços no treinamento de Small Language Models (SLMs) para a expansão de consultas. Por fim, gostamos muito do nome ReSearch, que é uma expressão inteligente da ideia de reinventar a pesquisa e um trocadilho. Foi uma pena não usá-lo, por isso acabamos usando-o no anuário de 2024.
No verão de 2024, nosso projeto "Pesquisa" adotou uma abordagem "incremental", concentrando-se na geração de relatórios mais longos. Ela começa com a geração simultânea do índice do relatório (TOC), seguida pela geração simultânea do conteúdo de todos os capítulos. Por fim, cada capítulo é revisado de forma incremental e assíncrona, com cada revisão levando em conta o conteúdo geral do relatório. No vídeo de demonstração acima, a consulta que usamos foi "Competitive Analysis for Jina AI".
DeepSearch vs DeepResearch
Muitas pessoas tendem a confundir DeepSearch com DeepResearch. Mas, em nossa opinião, eles resolvem problemas completamente diferentes.O DeepSearch é o bloco de construção do DeepResearch, o mecanismo principal no qual o último é executado.
O foco do DeepResearch é a elaboração de relatórios de pesquisa de alta qualidade, legíveis e de formato longo.Não se trata apenas de buscar informações, é um projeto sistemáticoO projeto DeepSearch foi desenvolvido para ser uma ferramenta altamente eficaz para a função de pesquisa, exigindo a integração de elementos de visualização eficazes (por exemplo, gráficos, tabelas), uma estrutura lógica de capítulos que garanta um fluxo suave entre os subcapítulos, terminologia consistente em todo o texto, evitando a redundância de informações e o uso de transições suaves para vincular os contextos. Esses elementos não estão diretamente relacionados à funcionalidade de pesquisa subjacente, e é por isso que estamos nos concentrando mais no DeepSearch como empresa.
Para resumir as diferenças entre o DeepSearch e o DeepResearch, consulte a tabela abaixo. Vale a pena mencionar queTanto o DeepSearch quanto o DeepResearch são inseparáveis dos modelos de contexto e inferência longos, mas por motivos ligeiramente diferentes.
O DeepResearch requer um contexto longo para gerar relatórios longos, o que é compreensível. E, embora o DeepSearch possa parecer uma ferramenta de pesquisa, ele também precisa se lembrar de tentativas de pesquisa anteriores e do conteúdo de páginas da Web para planejar operações subsequentes, portanto, contextos longos são igualmente essenciais.

Saiba mais sobre a implementação do DeepSearch
Link de código aberto: https://github.com/jina-ai/node-DeepResearch
No centro do DeepResearch está seu mecanismo de raciocínio circular. Ao contrário da maioria dos sistemas RAG que tentam responder às perguntas em uma única etapa, usamos um loop iterativo. Ele continua a pesquisar informações, ler fontes relevantes e raciocinar até encontrar uma resposta ou esgotar o orçamento de tokens. Aqui está um esqueleto condensado desse grande loop while:
// 主推理循环
while (tokenUsage < tokenBudget && badAttempts <= maxBadAttempts) {
// 追踪进度
step++; totalStep++;// Obter o problema atual da fila de lacunas ou usar o problema original se ele não estiver disponível
const currentQuestion = gaps.length > 0 ? gaps.shift() : question;/
/ Gerar prompts com base no contexto atual e nas ações permitidas
system = getPrompt(diaryContext, allQuestions, allKeywords.
allowReflect, allowAnswer, allowRead, allowSearch, allowCoding.
badContext, allKnowledge, unvisitedURLs);/
/ Deixe o LLM decidir o que fazer em seguida
const result = await LLM.generateStructuredResponse(system, messages, schema);
thisStep = result.object;/
/ Executar ações selecionadas (responder, refletir, pesquisar, visitar, codificar)
Se (thisStep.action === 'answer') {
// Processar ações de resposta...
} else if (thisStep.action === 'reflect') {
// Processamento de ações reflexivas...
} // ... E assim por diante para as outras ações
Para garantir a estabilidade e a estrutura do resultado, foi tomada uma medida fundamental:Desativar seletivamente determinadas operações em cada etapa.
Por exemplo, desativamos a operação "visitar" quando não há URL na memória e impedimos que o Agente repita a operação "responder" imediatamente se a última resposta tiver sido rejeitada. Esse mecanismo de restrição orienta o Agente na direção certa e evita que ele fique dando voltas no mesmo lugar.
sinalização do sistema
Para o design dos prompts do sistema, usamos tags XML para definir as várias partes, o que nos permite gerar prompts do sistema e conteúdo gerado mais robustos. Ao mesmo tempo, descobrimos que diretamente no esquema JSON description campos com restrições de campo para obter melhores resultados. É verdade que os modelos de inferência, como o DeepSeek-R1, podem teoricamente gerar a maioria das palavras-chave automaticamente. No entanto, dadas as restrições do comprimento do contexto e a nossa necessidade de controle refinado do comportamento do agente, essa maneira de escrever explicitamente as palavras-chave é mais confiável na prática.
function getPrompt(params...) {
const sections = [];// Adicionar um cabeçalho com comandos do sistema
sections.push("Você é um assistente de pesquisa de IA sênior especializado em raciocínio em várias etapas...") ;
// Adicionar fragmentos de conhecimento acumulado (se houver)
se (knowledge?.length) {
seções.push("[entrada de conhecimento]");;
}// Adicionar informações de contexto para ações anteriores
Se (context?.length) {
seções.push("[Histórico de ações]");;
}
// Adicione tentativas fracassadas e estratégias aprendidas
Se (badContext?.length) {
seções.push("[tentativas fracassadas]");;
sections.push("[improved strategy]");;
}
// Definir as opções de ação disponíveis com base no estado atual
seções.push("[definições de ações disponíveis]");;
// Adicionar instruções de formatação da resposta
sections.push("Por favor, responda em um formato JSON válido que corresponda estritamente ao esquema JSON.");;
return sections.join("nn");
}
Como superar o problema da lacuna de conhecimento
No DeepSearch, oUma "pergunta de lacuna de conhecimento" refere-se a uma lacuna de conhecimento que o Agente precisa preencher antes de responder à pergunta principal.Em vez de tentar responder diretamente à pergunta original, o Agente identifica e resolve subperguntas que constroem a base de conhecimento necessária.
Essa é uma maneira muito elegante de lidar com isso.
// 在“反思行动”中识别出知识空白问题后
if (newGapQuestions.length > 0) {
// 将新问题添加到队列的头部
gaps.push(...newGapQuestions);// Sempre adicione a pergunta original ao final da fila
gaps.push(originalQuestion);
}
Ele cria uma fila FIFO (First In First Out) com um mecanismo de rotação que segue as seguintes regras:
- Novas perguntas sobre lacunas de conhecimento são priorizadas e colocadas no topo da fila.
- A pergunta original está sempre no final da fila.
- O sistema extrai problemas do cabeçalho da fila em cada etapa para processamento.
A sutileza desse design é que ele mantém um contexto compartilhado para todos os problemas. Ou seja, quando um problema de lacuna de conhecimento é resolvido, o conhecimento adquirido pode ser aplicado imediatamente a todos os problemas subsequentes e, por fim, também nos ajudará a resolver o problema original.
Fila FIFO versus recursão
Além das filas FIFO, também podemos usar a recursão, que corresponde a uma estratégia de busca em profundidade. Para cada problema de "lacuna de conhecimento", a recursão cria uma pilha de chamadas totalmente nova com um contexto separado. O sistema deve resolver completamente cada problema de lacuna de conhecimento (e todos os seus possíveis subproblemas) antes de retornar ao problema principal.
Como exemplo, uma recursão simples de problemas de lacunas de conhecimento profundo em três níveis, com os números nos círculos indicando a ordem em que os problemas são resolvidos.
No modo recursivo, o sistema deve resolver totalmente o Q1 (e seus possíveis subproblemas derivados) antes de poder passar para outros problemas! Isso contrasta com a abordagem de fila, que reverteria para Q1 depois de lidar com 3 problemas de lacuna de conhecimento.
Na prática, descobrimos que os métodos recursivos são difíceis de controlar o orçamento. Como os subproblemas podem continuar a gerar novos subproblemas, é difícil determinar quanto orçamento de token deve ser alocado a eles sem diretrizes claras. A vantagem da recursão em termos de isolamento contextual claro é pequena em comparação com a complexidade do controle de orçamento e a possibilidade de retornos atrasados. Por outro lado, o design das filas FIFO equilibra bem a profundidade e a amplitude, garantindo que o sistema continue a acumular conhecimento, melhore com o tempo e, por fim, retorne ao problema original em vez de se afundar ainda mais em um atoleiro de recursão potencialmente infinito.
Reescrita de consulta
Um desafio bastante interessante que encontramos foi como reescrever efetivamente a consulta de pesquisa do usuário:
// 在搜索行为处理器中
if (thisStep.action === 'search') {
// 搜索请求去重
const uniqueRequests = await dedupQueries(thisStep.searchRequests, existingQueries);// Reescreva as consultas em linguagem natural em expressões de pesquisa mais eficientes
const optimisedQueries = await rewriteQuery(uniqueRequests);
// Garantir que não haja duplicação de pesquisas anteriores
const newQueries = await dedupQueries(optimisedQueries, allKeywords);
// Executar uma pesquisa e armazenar os resultados
for (const query of newQueries) {
const results = await searchEngine(query);
Se (results.length > 0) {
storeResults(results);
allKeywords.push(query);
}
}
}
Descobrimos queA reescrita de consultas é muito mais importante do que o esperado e é, sem dúvida, um dos fatores mais importantes para determinar a qualidade dos resultados de pesquisa.Um bom reescritor de consultas não apenas transforma a linguagem natural do usuário em algo mais apropriado para a BM25 Os algoritmos processam formulários de palavras-chave que também ampliam a consulta para abranger mais respostas possíveis em diferentes idiomas, tons e formatos de conteúdo.
Em termos de desduplicação de consultas, inicialmente tentamos um esquema baseado em LLM, mas descobrimos que era difícil controlar com precisão o limite de similaridade, e os resultados não foram satisfatórios. No final, escolhemos o esquema jina-embeddings-v3. Seu excelente desempenho na tarefa de similaridade de texto semântico nos permitiu obter facilmente a desduplicação entre idiomas sem ter que nos preocupar com consultas em outros idiomas sendo filtradas por falsos positivos. Coincidentemente, foi o modelo Embedding que acabou desempenhando um papel fundamental. A princípio, não tínhamos a intenção de usá-lo para recuperação na memória, mas ficamos surpresos ao descobrir que ele teve um desempenho muito eficiente na tarefa de eliminação de duplicação.
Rastreamento de conteúdo da Web
O rastreamento da Web e o processamento de conteúdo também são uma parte crucial do processo, em que usamos o Jina Reader Além do conteúdo completo da página da Web, coletamos trechos de resumo retornados pelo mecanismo de busca como informações de apoio para o raciocínio subsequente. Esses snippets podem ser vistos como um resumo conciso do conteúdo da página da Web.
// 访问行为处理器
async function handleVisitAction(URLs) {
// 规范化并过滤已访问过的 URL
const uniqueURLs = normalizeAndFilterURLs(URLs);// Processar cada URL em paralelo
const results = await Promise.all(uniqueURLs.map(async url => {
tente {
// Obter e extrair o conteúdo
const content = await readUrl(url);
// Armazenado como conhecimento
addToKnowledge(`O que há em ${url}? `, content, [url], 'url');
return {url, success: true};
} catch (error) {
return {url, success: false};
} finally {
visitedURLs.push(url);
}
}));
// Atualizar os registros com base nos resultados
updateDiaryWithVisitResults(results).
}
Para facilitar o rastreamento, normalizamos os URLs e limitamos o número de URLs acessados por etapa para controlar o espaço de memória do agente.
gerenciamento de memória
Um dos principais desafios do raciocínio em várias etapas é o gerenciamento eficiente da memória do agente. O sistema de memória que projetamos faz distinção entre o que conta como "memória" e o que conta como "conhecimento". Mas, de qualquer forma, todos eles fazem parte do contexto da dica do LLM, separados por diferentes tags XML:
// 添加知识条目
function addToKnowledge(question, answer, references, type) {
allKnowledge.push({
question: question,
answer: answer,
references: references,
type: type, // 'qa', 'url', 'coding', 'side-info'
updated: new Date().toISOString()
});
}// Registre as etapas no log
function addToDiary(step, action, question, result, evaluation) {
diaryContext.push(`
Na etapa ${passo}, você tomou **${ação}** na pergunta: "${pergunta}".
[Detalhes e resultados] [Avaliação (se houver)] `); e
}
Dada a tendência de contextos muito longos no LLM 2025, optamos por abandonar os bancos de dados vetoriais em favor de uma abordagem de memória contextual. A memória do agente consiste em três partes dentro de uma janela de contexto: conhecimento adquirido, sites visitados e registros de tentativas fracassadas. Essa abordagem permite que o agente acesse diretamente o histórico completo e o estado do conhecimento durante o processo de raciocínio, sem etapas adicionais de recuperação.
Avaliação das respostas
Também descobrimos que a geração e a avaliação de respostas eram mais bem realizadas se fossem colocadas em palavras-chave diferentes.Em nossa implementação, quando um novo problema é recebido, primeiro identificamos os critérios de avaliação e depois os avaliamos um a um. O avaliador se refere a um pequeno número de exemplos para avaliação da consistência, o que é mais confiável do que a autoavaliação.
// 独立评估阶段
async function evaluateAnswer(question, answer, metrics, context) {
// 根据问题类型确定评估标准
const evaluationCriteria = await determineEvaluationCriteria(question);// Avaliar cada critério individualmente
const results = [];
for (const criterion of evaluationCriteria) {
const result = await evaluateSingleCriterion(criterion, question, answer, context);
results.push(result);
}
// Determinar se a resposta é aprovada na avaliação geral
retornar {
pass: results.every(r => r.pass),
think: results.map(r => r.reasoning).join('n')
};
}
Controle orçamentário
O controle orçamentário não se trata apenas de economia de custos, mas de garantir que o sistema resolva adequadamente os problemas antes que o orçamento se esgote e evite retornar respostas prematuramente.Desde o lançamento do DeepSeek-R1, nosso pensamento sobre o controle orçamentário deixou de ser apenas a economia de orçamentos e passou a incentivar o pensamento mais profundo e a buscar respostas de alta qualidade.
Em nossa implementação, exigimos explicitamente que o sistema identifique as lacunas de conhecimento antes de tentar responder.
if (thisStep.action === 'reflect' && thisStep.questionsToAnswer) {
// 强制深入推理,添加子问题
gaps.push(...newGapQuestions);
gaps.push(question); // 别忘了原始问题
}
Com a flexibilidade de ativar e desativar determinadas ações, podemos direcionar o sistema para usar ferramentas que aprofundem o raciocínio.
// 在回答失败后
allowAnswer = false; // 强制代理进行搜索或反思
Para evitar o desperdício de tokens em caminhos inválidos, limitamos o número de tentativas fracassadas. Ao nos aproximarmos do limite orçamentário, ativamos o "Modo Fera" para garantir que daremos uma resposta de qualquer maneira e evitaremos voltar para casa de mãos vazias.
// 启动野兽模式
if (!thisStep.isFinal && badAttempts >= maxBadAttempts) {
console.log('Enter Beast mode!!!');// Configurar prompts para orientar respostas decisivas
system = getPrompt(
diaryContext, allQuestions, allKeywords.
false, false, false, false, false, false, false, false, // desativar outras operações
badContext, allKnowledge, unvisitedURLs.
true // Ativar o Beast Mode
);
// Forçar a geração de respostas
const result = await LLM.generateStructuredResponse(system, messages, answerOnlySchema);
thisStep = result.object;
thisStep.isFinal = true;
}
A mensagem do prompt do Beast Mode é deliberadamente exagerada, informando explicitamente ao LLM que agora ele deve tomar uma decisão decisiva e dar uma resposta com base nas informações disponíveis!
<action-answer>
🔥 启动最高战力! 绝对优先! 🔥Diretriz principal:
- Elimine toda hesitação! É melhor dar uma resposta do que ficar em silêncio!
- Uma estratégia localizada pode ser adotada, usando todas as informações conhecidas!
- Permitir a reutilização de tentativas anteriores que não deram certo!
- Quando você não consegue se decidir: com base nas informações disponíveis, ataque de forma decisiva!
O fracasso não é uma opção! Não deixe de atingir suas metas! ⚡️
</action-answer>
Isso garante que, mesmo diante de perguntas difíceis ou vagas, possamos dar uma resposta útil em vez de nada.
chegar a um veredicto
Pode-se dizer que o DeepSearch é um avanço importante na tecnologia de pesquisa para lidar com consultas complexas. Ele divide todo o processo em etapas independentes de pesquisa, leitura e raciocínio, superando muitas das limitações dos sistemas tradicionais de RAG de rodada única ou de questionário de vários saltos.
Durante o processo de desenvolvimento, refletimos constantemente sobre como deve ser a futura base da tecnologia de pesquisa em 2025, em face das mudanças drásticas em todo o setor de pesquisa após o lançamento do DeepSeek-R1. Que novas necessidades estão surgindo? Quais necessidades estão obsoletas? Quais necessidades são, na verdade, pseudo-necessidades?
Analisando a implementação do DeepSearch, identificamos cuidadosamente o que era esperado e essencial, o que considerávamos garantido e não era realmente necessário e o que não prevíamos, mas acabou se tornando essencial.
Em primeiro lugar.Um LLM de contexto longo que gera saída em um formato canônico (por exemplo, esquema JSON) é essencial!. Talvez também seja necessário um modelo de inferência para aprimorar o raciocínio da ação e a expansão da consulta.
As extensões de consulta também são absolutamente necessáriasO SLM é uma parte inevitável do processo, seja ele implementado usando SLM, LLM ou modelos de inferência especializados. Mas depois de realizar esse projeto, percebemos que o SLM pode não ser adequado para a tarefa, pois a expansão da consulta deve ser inerentemente multilíngue e não pode se limitar à simples substituição de sinônimos ou à extração de palavras-chave. Ela precisa ser abrangente o suficiente para ter uma base de tokens que cubra vários idiomas (de modo que a escala possa chegar facilmente a 300 milhões de parâmetros) e precisa ser inteligente o suficiente para pensar fora da caixa. Portanto, o dimensionamento de consultas somente pelo SLM pode não funcionar.
As habilidades de pesquisa e leitura na Web são, sem dúvida, uma prioridade máxima!Felizmente, nosso [Reader (r.jina.ai)] teve um desempenho muito bom e não é apenas poderoso, mas também tem boa extensibilidade, o que me inspirou a pensar em como podemos melhorar nosso endpoint de pesquisa (s.jina.ai) são muitas inspirações que podem ser focadas na otimização da próxima iteração.
Os modelos vetoriais são úteis, mas usados em lugares completamente inesperados. Originalmente, pensamos que ele seria usado para recuperação na memória ou em conjunto com um banco de dados vetorial para compactar o contexto, mas nenhum dos dois se mostrou necessário. Por fim, descobrimos que era melhor usar o modelo vetorial para a desduplicação, essencialmente uma tarefa de STS (Semantic Text Similarity). Como o número de consultas e lacunas de conhecimento geralmente está na faixa de centenas, é perfeitamente suficiente calcular a similaridade de cosseno diretamente na memória sem usar um banco de dados de vetores.
Não usamos o modelo RerankerO modelo Embeddings e Reranker pode ser usado como uma ferramenta para ajudar a determinar quais URLs devem ser priorizados para acesso com base na consulta, no título do URL e no snippet de resumo, em teoria. Para os modelos Embeddings e Reranker, o recurso multilíngue é um requisito básico, pois as consultas e perguntas são multilíngues. O processamento de contexto longo é útil para os modelos Embeddings e Reranker, mas não é um fator decisivo. Não encontramos nenhum problema causado pelo uso de vetores, provavelmente graças ao fato de que o jina-embeddings-v3 (um excelente comprimento de contexto de 8192 tokens). Em conjunto, ojina-embeddings-v3 responder cantando jina-reranker-v2-base-multilingual Ainda é minha primeira opção, pois eles têm suporte a vários idiomas, desempenho SOTA e bom manuseio de contexto longo.
A estrutura do agente acabou se mostrando desnecessária. Em termos de design do sistema, preferimos ficar próximos dos recursos nativos dos LLMs e evitamos introduzir camadas de abstração desnecessárias. O Vercel AI SDK oferece muita conveniência na adaptação a diferentes fornecedores de LLMs, o que reduz muito o esforço de desenvolvimento, pois apenas uma linha de código precisa ser alterada para criar um novo LLM no Gêmeos Alternando entre Studio, OpenAI e Google Vertex AI. O gerenciamento de memória proxy faz sentido, mas a introdução de uma estrutura especializada para ele é questionável. Pessoalmente, acho que a dependência excessiva de frameworks pode criar uma barreira entre o LLM e o desenvolvedor, e o açúcar sintático que eles fornecem pode se tornar um fardo para o desenvolvedor. Muitos frameworks LLM/RAG já validaram isso. É mais sensato adotar os recursos nativos do LLM e evitar ficar preso a estruturas.
Esta postagem é do WeChat: Jina AI
© declaração de direitos autorais
Direitos autorais do artigo Círculo de compartilhamento de IA A todos, favor não reproduzir sem permissão.
Artigos relacionados



Nenhum comentário...