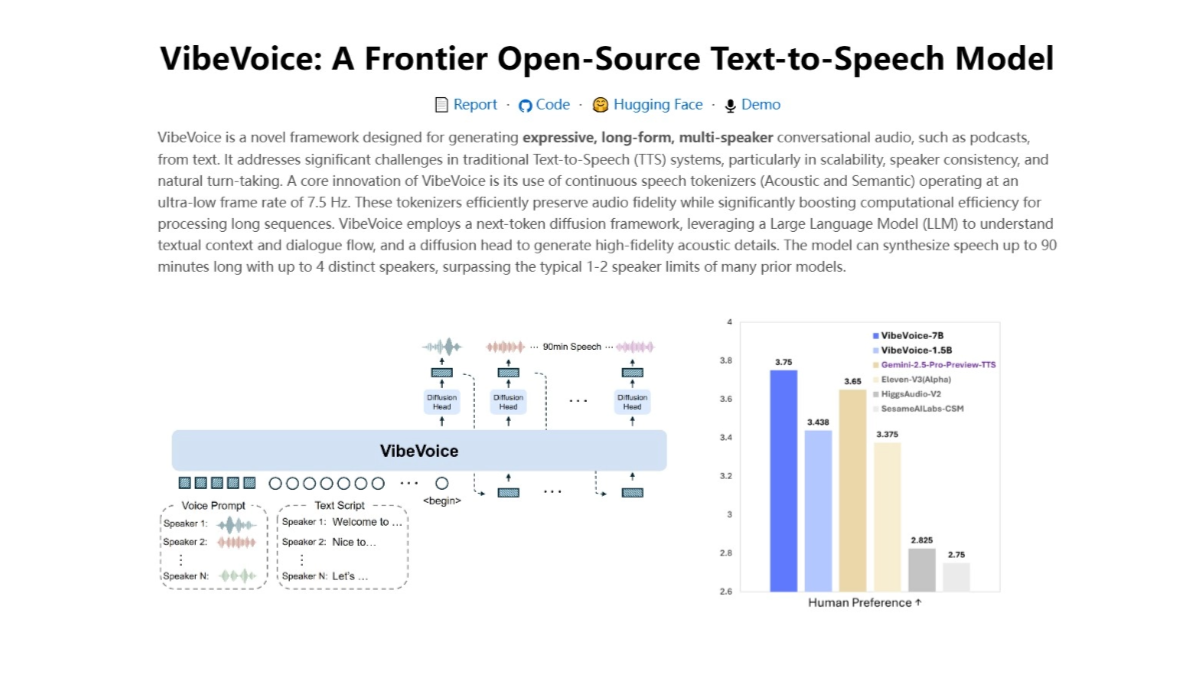
DeepCoder-14B-Preview: um modelo de código aberto que se destaca na geração de código

Introdução geral
O DeepCoder-14B-Preview é um modelo de geração de código-fonte aberto desenvolvido pela equipe da Agentica e lançado na plataforma Hugging Face. Ele se baseia no DeepSeek-R1-Distilled-Qwen-14B, otimizado por técnicas de aprendizado por reforço distribuído (RL), e é capaz de lidar com até 64K token de contextos muito longos. O modelo tem 14 bilhões de parâmetros e alcançou uma precisão Pass@1 de 60,6% no teste LiveCodeBench v5 (1º de agosto de 2024 a 1º de fevereiro de 2025), uma melhoria de 8% em relação ao modelo básico e um desempenho próximo ao o3-mini da OpenAI. O objetivo do DeepCoder é ajudar os desenvolvedores a escrever códigos complexos com eficiência, especialmente para competições de programação e projetos de grande escala.

Lista de funções
- Gerar código longo: suporta contextos de até 64 mil tokens e pode gerar e manipular códigos muito longos.
- Saída de alta precisão: 60,6% Pass@1 no LiveCodeBench v5 para uma qualidade de código confiável.
- Código aberto disponível: arquivos de modelo, conjuntos de dados e scripts de treinamento estão disponíveis para download gratuito e personalização.
- Oferece suporte a uma ampla gama de tarefas de programação: adequado para responder a perguntas de concursos, depuração de código e desenvolvimento de projetos.
- Raciocínio contextual longo: otimizado pelas técnicas GRPO+ e DAPO para garantir recursos de geração de código longo.
Usando a Ajuda
O DeepCoder-14B-Preview é uma ferramenta poderosa que pode ajudá-lo a gerar código ou lidar com tarefas complexas de programação. Abaixo está um guia detalhado de instalação e uso.
Processo de instalação
Para usar o DeepCoder-14B-Preview localmente, você precisa preparar o ambiente e fazer o download do modelo. As etapas são as seguintes:
- Preparar hardware e software
- É necessário um computador com uma GPU, recomenda-se a NVIDIA H100 ou uma placa de vídeo com pelo menos 24 GB de RAM.
- Instalando o Python 3.10: Executar
conda create -n deepcoder python=3.10 -yEm seguida, ative o ambienteconda activate deepcoder. - Instalar as bibliotecas dependentes: executar
pip install transformers torch huggingface_hub vllm.
- Modelos para download
- Visite a página oficial em https://huggingface.co/agentica-org/DeepCoder-14B-Preview.
- Em "Files and versions" (Arquivos e versões), localize os arquivos de modelo (por exemplo
model-00001-of-00012.safetensors). - Use o comando download:
huggingface-cli download agentica-org/DeepCoder-14B-Preview --local-dir ./DeepCoder-14B - Após o download, os arquivos do modelo são salvos localmente
./DeepCoder-14BPasta.
- Modelos de carregamento
- Carregar o modelo em Python:
from transformers import AutoModelForCausalLM, AutoTokenizer model_path = "./DeepCoder-14B" model = AutoModelForCausalLM.from_pretrained(model_path, torch_dtype="auto", device_map="auto") tokenizer = AutoTokenizer.from_pretrained(model_path) - Isso carregará o modelo na GPU, pronto para uso.
- Carregar o modelo em Python:
Como usar os principais recursos
O núcleo do DeepCoder é gerar código e lidar com contextos longos. Veja como isso funciona:
Gerar código
- Requisitos de programação de entrada
- Prepare um problema, como "Escreva uma função Python que encontre o valor máximo em uma matriz".
- Converter requisitos em texto:
prompt = "写一个 Python 函数,找出数组中的最大值"
- Gerar código
- Use o código a seguir para gerar a resposta:
inputs = tokenizer(prompt, return_tensors="pt").to(model.device) outputs = model.generate(**inputs, max_new_tokens=512, temperature=0.6, top_p=0.95) result = tokenizer.decode(outputs[0], skip_special_tokens=True) print(result) - Possíveis saídas:
def find_max(arr): if not arr: return None max_value = arr[0] for num in arr: if num > max_value: max_value = num return max_value
- Use o código a seguir para gerar a resposta:
- Geração otimizada
- Se for necessário um código mais longo, ajuste o
max_new_tokensé 1024 ou superior. - configurar
max_tokens=64000O desempenho ideal do contexto longo é alcançado.
- Se for necessário um código mais longo, ajuste o
Manuseio de contextos longos
- Digite o código longo
- Digamos que você tenha um código com 32 mil tokens e queira que o modelo o renove:
long_code = "def process_data(data):\n # 几千行代码...\n return processed_data" prompt = long_code + "\n请为这个函数添加异常处理"
- Digamos que você tenha um código com 32 mil tokens e queira que o modelo o renove:
- Gerar uma continuação
- Insira e gere:
inputs = tokenizer(prompt, return_tensors="pt").to(model.device) outputs = model.generate(**inputs, max_new_tokens=512, temperature=0.6, top_p=0.95) result = tokenizer.decode(outputs[0], skip_special_tokens=True) print(result) - O resultado pode ser:
def process_data(data): try: # 几千行代码... return processed_data except Exception as e: print(f"错误: {e}") return None
- Insira e gere:
- Resultados da verificação
- Verifique se o código atende aos requisitos. Se não atender, descreva os requisitos com mais clareza.
Funções em destaque Procedimento de operação
A capacidade de geração de código longo do DeepCoder é seu destaque, tornando-o adequado para competições e projetos de grande escala.
Resolução de concursos
- Obter título
- Encontre um tópico do Codeforces, como "Given an array, return all possible subsets" (Dada uma matriz, retorne todos os subconjuntos possíveis).
- Digite uma descrição do tópico:
prompt = "给定一个数组,返回所有可能的子集。例如,输入 [1,2,3],输出 [[],[1],[2],[3],[1,2],[1,3],[2,3],[1,2,3]]"
- Gerar código
- Execute o comando generate:
inputs = tokenizer(prompt, return_tensors="pt").to(model.device) outputs = model.generate(**inputs, max_new_tokens=512, temperature=0.6, top_p=0.95) result = tokenizer.decode(outputs[0], skip_special_tokens=True) print(result) - O resultado pode ser:
def subsets(nums): result = [[]] for num in nums: result += [curr + [num] for curr in result] return result
- Execute o comando generate:
- Resultados dos testes
- Para executar o código em Python, digite
[1,2,3]Verifique se a saída está correta.
- Para executar o código em Python, digite
código de depuração
- Digite o código da pergunta
- Suponha que haja um trecho de código com erros:
buggy_code = "def sum_numbers(n):\n total = 0\n for i in range(n)\n total += i\n return total" prompt = buggy_code + "\n这段代码有语法错误,请修复"
- Suponha que haja um trecho de código com erros:
- Gerar correções
- Insira e gere:
inputs = tokenizer(prompt, return_tensors="pt").to(model.device) outputs = model.generate(**inputs, max_new_tokens=512, temperature=0.6, top_p=0.95) result = tokenizer.decode(outputs[0], skip_special_tokens=True) print(result) - O resultado pode ser:
def sum_numbers(n): total = 0 for i in range(n): total += i return total
- Insira e gere:
- Correções de verificação
- Verifique se a sintaxe está correta e execute o código para confirmar o resultado.
Recomendações de uso
- Não adicione um prompt do sistema, informe o requisito diretamente no prompt do usuário.
- configurar
temperature=0.6responder cantandotop_p=0.95para obter os melhores resultados. - comandante-em-chefe (militar)
max_tokensDefina como 64000 para aproveitar os contextos longos.
cenário do aplicativo
- concurso de programação
O DeepCoder gera respostas a perguntas de concursos rapidamente e é adequado para tarefas complexas no LiveCodeBench ou no Codeforces. - Desenvolvimento de projetos em larga escala
Ele pode gerar módulos de código longos para ajudar os desenvolvedores a concluir grandes projetos. - Educação e aprendizado
Os alunos podem usá-lo para gerar código de amostra, aprender algoritmos ou depurar tarefas.
QA
- O DeepCoder-14B-Preview é gratuito?
Sim, ele é licenciado pelo MIT, tem código-fonte totalmente aberto e pode ser usado por qualquer pessoa. - Que hardware é necessário para executá-lo?
Recomenda-se usar um computador com uma GPU e pelo menos 24 GB de memória de vídeo. Se você usar uma CPU, será muito mais lento. - Quais linguagens de programação são compatíveis?
Ele é especializado principalmente em Python, mas também pode gerar código em Java, C++ e outras linguagens, dependendo da clareza do prompt.
© declaração de direitos autorais
Direitos autorais do artigo Círculo de compartilhamento de IA A todos, favor não reproduzir sem permissão.
Artigos relacionados


Nenhum comentário...