
Como calcular o número de parâmetros de um modelo grande e o que significam 7B, 13B e 65B?
Recentemente, muitas pessoas envolvidas no treinamento e na inferência de modelos grandes têm discutido a relação entre o número de parâmetros do modelo e o tamanho do modelo. Por exemplo, a famosa série alpaca de modelos grandes LLaMA contém quatro versões com diferentes tamanhos de parâmetros: LLaMA-7B, LLaMA-13B, LLaMA-33B e LLaMA-65B.
O "B" aqui é uma abreviação de "Billion", que significa bilhão. Assim, o menor modelo LLaMA-7B contém cerca de 7 bilhões de parâmetros, enquanto o maior modelo LLaMA-65B contém cerca de 65 bilhões de parâmetros.
Então, como essas contagens de parâmetros são calculadas? Além disso, qual é o nível aproximado de contagem de parâmetros de modelos grandes correspondente a um arquivo de modelo de 100 GB? Bilhões, dezenas de bilhões, centenas de bilhões ou trilhões? Este documento responderá a essas perguntas em profundidade.
I. Métodos para calcular grandes quantidades de parâmetros do modelo
Tomaremos o Transformer, a infraestrutura do modelo grande, como exemplo e analisaremos em detalhes o processo de cálculo do número de parâmetros.
Um padrão Transformador O modelo consiste em L camadas idênticas empilhadas umas sobre as outras, e cada camada contém duas partes principais: a camada de autoatenção (SAL) e a camada de rede neural de avanço (MLP).
1. autoatenção
O mecanismo de autoatenção é o núcleo do transformador. Independentemente de ser autoatenção ou autoatenção de várias cabeças (MHA), o cálculo da quantidade do parâmetro do núcleo é o mesmo.
Na camada de autoatenção, a sequência de entrada é primeiramente mapeada em três vetores: um vetor de consulta (Query, Q), um vetor de chave (Key, K) e um vetor de valor (Value, V). No MHA, esses três vetores são divididos em várias cabeças, cada uma das quais é responsável por se concentrar em uma parte diferente da sequência de entrada.

- Auto-atenção de cabeça única. Q, K, V são transformados linearmente por uma matriz de peso de formato [h, h], em que h é a dimensão da camada oculta. Assim, o número total de parâmetros de Q, K, V é 3h². Além disso, há uma camada de transformação linear para a saída com a mesma forma de matriz de peso [h, h]. Portanto, o número total de parâmetros para a autoatenção de cabeça única é 4h² (ignore o termo de polarização).
- Atenção Multidirecional (MHA). Suponha que haja n_cabeças, cada uma com dimensão h_cabeça = h / n_cabeça. Cada cabeça tem uma matriz de peso Q, K, V separada da forma [h, h_cabeça]. Portanto, a quantidade paramétrica da matriz de peso Q, K, V para cada cabeçote é 3 * h * h_head = 3h²/n_head. O número total de quantidades paramétricas para os n_cabeçotes é n_head * (3h²/n_head) = 3h². Por fim, a forma da matriz de peso da transformação linear para a camada de saída é [h, h]. Portanto, o número total de parâmetros no MHA também é 4h² (ignore o termo de polarização).
Portanto, o número de parâmetros na camada de autoatenção pode ser aproximado como 4h², tanto para cabeças únicas quanto para múltiplas cabeças.
2 Camada de rede neural feed-forward (MLP)
A camada MLP consiste em duas camadas lineares. A primeira camada linear amplia a dimensão da camada oculta h para 4h, e a segunda camada linear reduz a dimensão de 4h para h.

- A matriz de peso da primeira camada linear tem a forma [h, 4h] e o número de parâmetros é 4h².
- A segunda camada linear tem uma matriz de peso do formato [4h, h] com a mesma quantidade paramétrica de 4h².
O número total de parâmetros na camada MLP é, portanto, 8h² (ignorando o termo de polarização).
3. normalização de camadas
Após cada camada de Self-Attention e MLP, e após a última camada de saída do Transformer, geralmente há uma operação de normalização de camada. Cada camada de normalização de camada contém dois parâmetros treináveis:
- Parâmetro de escala (gama): A forma é [h].
- Parâmetro de conversão (beta): a forma é [h].
Como cada camada do Transformer tem duas Normalizações de Camada (após Self-Attention e MLP, respectivamente) mais uma após a camada de saída, o número total de parâmetros de Normalização de Camada para o Transformer de camada L é (2L + 1) * 2h.
4. incorporação
O texto de entrada precisa primeiro ser convertido em vetores de palavras por meio da camada de incorporação de palavras. Supondo que o tamanho da lista de palavras seja V e a dimensão do vetor de palavras seja h, o número de parâmetros da camada de incorporação de palavras é Vh.
5. camada de saída
A matriz de peso da camada de saída geralmente é compartilhada com a camada de incorporação de palavras (Weight Tying) para reduzir o número de parâmetros e, possivelmente, melhorar o desempenho. Portanto, se o compartilhamento de peso for usado, a camada de saída geralmente não introduz um número adicional de parâmetros. Se ela não for compartilhada, o número de parâmetros será Vh.
6. codificação posicional
A codificação de posição é usada para fornecer ao modelo informações sobre a posição das palavras na sequência de entrada.
- Códigos de posição treináveis. Se for usada a codificação posicional treinável, o número de parâmetros será N * h, em que N é o comprimento máximo da sequência. Por exemplo, o comprimento máximo da sequência do ChatGPT é 4k.
- Código de posição relativa (por exemplo, RoPE ou ALiBi). Esses métodos não introduzem parâmetros treináveis.
Devido ao número relativamente pequeno de parâmetros codificados posicionalmente, eles geralmente são insignificantes no cálculo do número total de parâmetros.
7. cálculo do número total de participantes
Em resumo, o número total de parâmetros para um modelo de transformador de camada L é:
Número total de parâmetros = L * (parâmetro Self-Attention + parâmetro MLP + parâmetro LayerNorm * 2) + parâmetro Embedding + parâmetro da camada de saída + parâmetro LayerNorm (após a camada de saída)
Número total de parâmetros ≈ L * (4h² + 8h² + 4h) + Vh + (Vh opcional) + 2h
Número total de parâmetros ≈ L * (12h² + 4h) + Vh + 2h (supondo que a camada de saída compartilhe pesos com a camada de incorporação de palavras)
Quando a dimensão oculta h é grande, os termos primários 4h e 2h são insignificantes e o número de parâmetros do modelo pode ser aproximado como:
Número total de participantes ≈ 12Lh² + Vh
8. número estimado de participantes do LLaMA
A tabela a seguir mostra alguns dos principais parâmetros das diferentes versões do LLaMA e a estimativa de suas contagens de parâmetros:
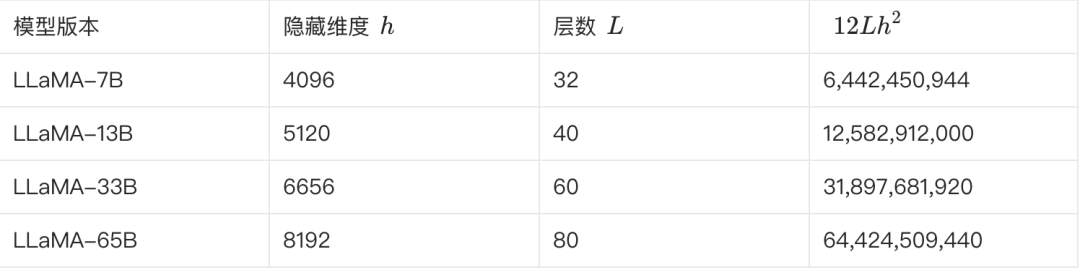
**Podemos verificar isso de acordo com a fórmula acima. Tomando o LLaMA-7B como exemplo, de acordo com a tabela, L=32, h=4096, V=32000.**
Número estimado de parâmetros ≈ 12 * 32 * 4096² + 32000 * 4096 ≈ 6,55B
Essa estimativa está mais próxima de 6,7 bilhões. Várias outras versões podem ser estimadas e validadas dessa forma.
II. conversão de grandes quantidades paramétricas de modelos em tamanhos de modelos
Ao entender como o número de parâmetros é calculado, veremos a seguir como o número de parâmetros e o tamanho do modelo são convertidos.
Ainda usamos o LLaMA-7B como exemplo, que tem cerca de 7 bilhões de participantes.
- Cálculos teóricos. Se cada parâmetro for armazenado no formato FP32 (número de ponto flutuante de 32 bits que ocupa 4 bytes), o tamanho teórico do LLaMA-7B será: 7B * 4 bytes = 28 GB.
- Armazenamento físico. Para economizar espaço de armazenamento e melhorar a eficiência computacional, os pesos do modelo geralmente são armazenados em um formato de precisão mais baixa, como FP16 (número de ponto flutuante de 16 bits ocupando 2 bytes) ou BF16. Ao usar o armazenamento FP16, o tamanho do LLaMA-7B é teoricamente: 7B * 2 bytes = 14 GB.
- Outros fatores. Além dos parâmetros de peso, o arquivo de modelo também pode conter informações sobre o estado do otimizador (por exemplo, momentum e variância do otimizador Adam), a lista de palavras, a configuração do modelo etc., que ocuparão espaço de armazenamento adicional. Além disso, alguns parâmetros (por exemplo, gama e beta para Normalização de Camadas) podem ser armazenados no formato FP32.
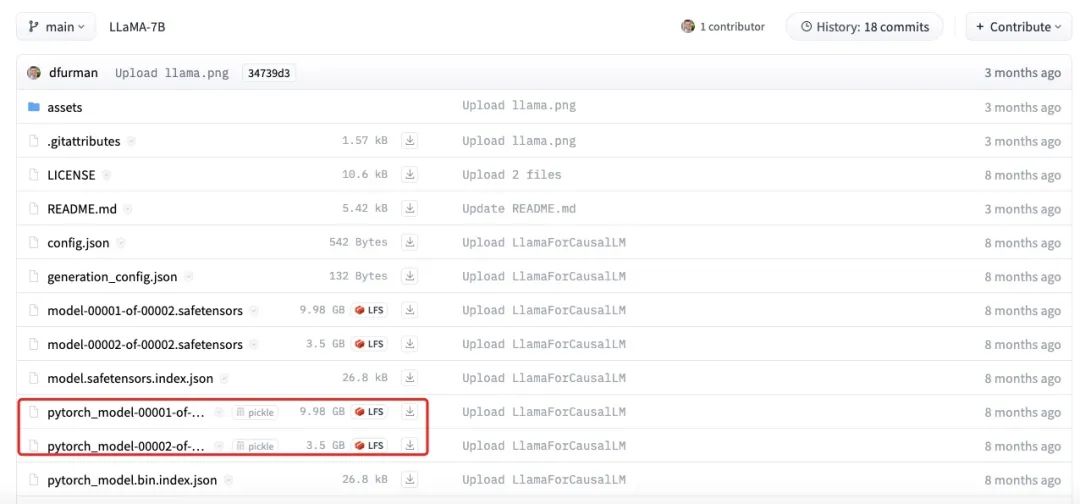
A figura acima mostra o tamanho real do arquivo do modelo LLaMA-7B. É possível observar que o tamanho total de cada parte é de cerca de 13,5 GB, o que está mais próximo de nossa estimativa de 14 GB. As pequenas diferenças podem ser causadas por erros de arredondamento, parâmetros de polarização ou pelo fato de que alguns parâmetros ainda são armazenados usando FP32.
© declaração de direitos autorais
Direitos autorais do artigo Círculo de compartilhamento de IA A todos, favor não reproduzir sem permissão.
Publicações relacionadas




Nenhum comentário...