Crawl4AI: ferramenta de rastreamento assíncrono da Web de código aberto para extrair dados estruturados sem LLM
Introdução geral
O Crawl4AI é uma ferramenta de rastreamento assíncrono da Web de código aberto projetada para modelos de linguagem grande (LLMs) e aplicativos de inteligência artificial (IA). Ele simplifica o processo de rastreamento da Web e de extração de dados, oferece suporte ao rastreamento eficiente da Web e fornece formatos de saída compatíveis com LLMs, como JSON, HTML limpo e Markdown. O Crawl4AI oferece suporte ao rastreamento de vários URLs ao mesmo tempo, é totalmente gratuito e de código aberto e é adequado para uma variedade de necessidades de rastreamento de dados.
Lista de funções
- Arquitetura assíncrona: processamento eficiente de várias páginas da Web, rastreamento rápido de dados
- Vários formatos de saída: suporte a JSON, HTML, Markdown
- Rastreamento de vários URLs: rastreie várias páginas da Web ao mesmo tempo
- Extração de tags de mídia: extraia tags de imagem, áudio e vídeo
- Extração de links: extrai todos os links externos e internos
- Extração de metadados: extração de metadados de uma página
- Ganchos personalizados: suporte para autenticação, cabeçalhos de solicitação e modificações de página
- Personalização do agente do usuário: personalização dos agentes do usuário
- Captura de tela da página: Captura de tela da página de rastreamento
- Executar JavaScript personalizado: Executar vários JavaScripts personalizados antes do rastreamento
- Suporte a proxy: aprimorando a privacidade e o acesso
- Gerenciamento de sessões: como lidar com cenários complexos de rastreamento de várias páginas
Usando a Ajuda
Processo de instalação
O Crawl4AI oferece opções de instalação flexíveis para uma variedade de cenários de uso. Você pode instalá-lo como um pacote Python ou usar o Docker.
Instalação com pip
- Instalação básica
pip install crawl4aiIsso instalará a versão assíncrona do Crawl4AI por padrão, usando o Playwright para rastreamento da Web.
- Instalação manual do Playwright (se necessário)
playwright installou
python -m playwright install chromium
Instalação com o Docker
- Extração de uma imagem do Docker
docker pull unclecode/crawl4ai - Execução de contêineres do Docker
docker run -it unclecode/crawl4ai
Diretrizes para uso
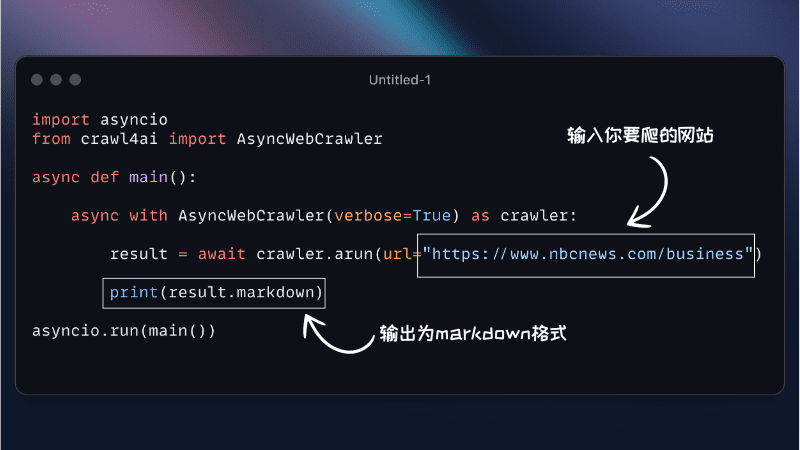
- Uso básico
from crawl4ai import AsyncWebCrawler crawler = AsyncWebCrawler() results = crawler.crawl(["https://example.com"]) print(results) - Configurações personalizadas
from crawl4ai import AsyncWebCrawler crawler = AsyncWebCrawler( user_agent="CustomUserAgent", headers={"Authorization": "Bearer token"}, custom_js=["console.log('Hello, world!')"] ) results = crawler.crawl(["https://example.com"]) print(results) - Extração de dados específicos
from crawl4ai import AsyncWebCrawler crawler = AsyncWebCrawler() results = crawler.crawl(["https://example.com"], extract_media=True, extract_links=True) print(results) - Gerenciamento de sessões
from crawl4ai import AsyncWebCrawler crawler = AsyncWebCrawler() session = crawler.create_session() session_results = session.crawl(["https://example.com"]) print(session_results)
O Crawl4AI oferece um rico conjunto de recursos e opções de configuração flexíveis para uma variedade de necessidades de rastreamento da Web e de dados. Com guias detalhados de instalação e uso, os usuários podem começar facilmente e aproveitar ao máximo os recursos avançados da ferramenta.
© declaração de direitos autorais
Direitos autorais do artigo Círculo de compartilhamento de IA A todos, favor não reproduzir sem permissão.
Artigos relacionados


Nenhum comentário...