Extração de informações valiosas do PDF: Solução Gemini 2.0 Structured Output

Na semana passada.O Google DeepMind lança o Gemini 2.0Isso inclui Gêmeos 2.0 Flash (totalmente disponível), Gemini 2.0 Flash-Lite (novo e econômico) e Gemini 2.0 Pro (experimental). Todos os modelos suportam pelo menos 1 milhão de Token da janela de contexto de entrada e suporta texto, imagem e áudio, bem como chamadas de função/saída estruturada. Este documento também serve como o Limitações do LLM OCR: Desafios de análise de documentos sob o glamour O material de leitura de referência.

Isso abre excelentes casos de uso para o processamento de PDFs. A conversão de PDF em texto estruturado ou legível por máquina sempre foi um grande desafio. Imagine se pudéssemos converter PDFs de documentos em dados estruturados? É aqui que o Gemini 2.0 entra em ação.
Neste tutorial, o leitor aprenderá a usar o Gemini 2.0 para extrair informações estruturadas, como números de faturas e datas, diretamente de documentos PDF:
- Configuração do ambiente e criação do cliente de raciocínio
- Manuseio de PDF e outros documentos
- Saída estruturada com Gemini 2.0 e Pydantic
- Extração de dados estruturados de PDF com o Gemini 2.0
1. configurar o ambiente e criar o cliente de raciocínio
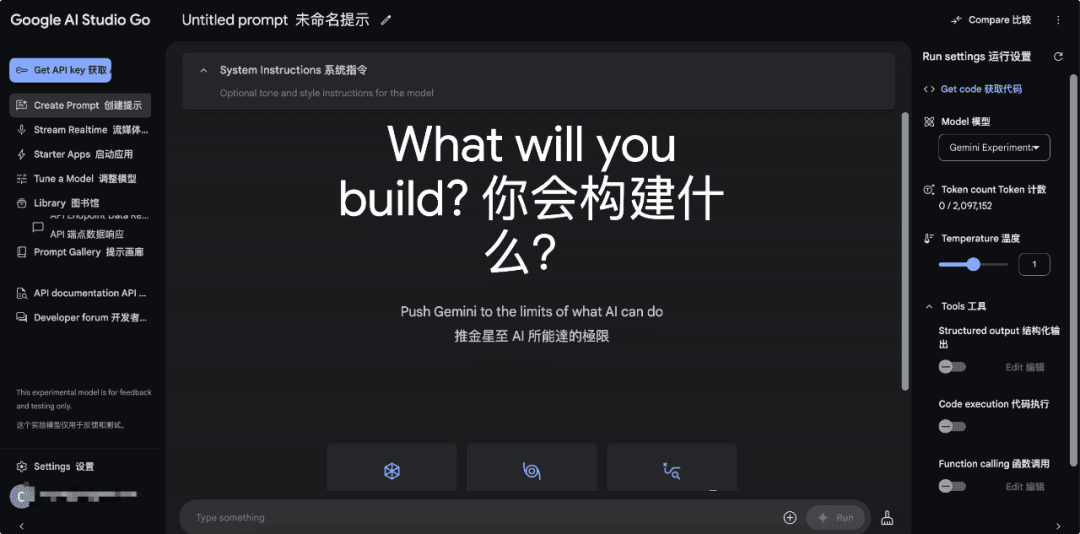
A primeira tarefa é instalar o google-genai SDK do Python e obter a chave da API. Se o leitor ainda não tiver a chave da API, ele poderá obtê-la na seção Estúdio de IA do Google Obter:Obter a chave da API da Gemini.
%pip install "google-genai>=1"
Uma vez de posse do SDK e da chave de API, o leitor pode criar um cliente e definir o modelo que será usado, ou seja, o novo modelo Gemini 2.0 Flash, que está disponível por meio de um nível gratuito com 1.500 solicitações por dia (a partir de 6 de fevereiro de 2025).
from google import genai # Create a client api_key = "XXXXX" client = genai.Client(api_key=api_key) # Define the model you are going to use model_id = "gemini-2.0-flash" # or "gemini-2.0-flash-lite-preview-02-05" , "gemini-2.0-pro-exp-02-05"
Observação: Se o leitor quiser usar o Vertex AI, favorClique aquiSaiba como criar um cliente
2. processamento de PDF e outros documentos
O modelo Gemini é capaz de lidar comImagens e vídeosIsso pode ser feito com uma string base64 ou usando o files A API do Python inclui métodos de upload e exclusão. Depois de fazer upload de um arquivo, o leitor pode incluir o URI do arquivo diretamente na chamada.A API do Python inclui métodos de upload e exclusão.
Para este exemplo, o usuário tem 2 amostras de PDF, uma fatura básica e um formulário com valores manuscritos.
!wget -q -O https://storage.googleapis.com/generativeai-downloads/data/pdf_structured_outputs/handwriting_form.pdf !wget -q -O https://storage.googleapis.com/generativeai-downloads/data/pdf_structured_outputs/invoice.pdf
O leitor pode agora usar o cliente e upload para carregar um arquivo. Vamos testá-lo em um dos arquivos.
invoice_pdf = client.files.upload(file="invoice.pdf", config={'display_name': 'invoice'})
Observação: a API de arquivos permite até 20 GB de arquivos por projeto, com um tamanho máximo de 2 GB por arquivo. Os arquivos são armazenados por 48 horas. Durante esse período, os arquivos podem ser acessados usando a chave de API do usuário, mas não podem ser baixados. Os uploads de arquivos são gratuitos.
Depois que o arquivo é carregado, o leitor pode verificar em quantos tokens ele foi convertido, o que não só ajuda a entender o contexto do que o usuário está lidando, mas também ajuda a controlar o custo.
file_size = client.models.count_tokens(model=model_id,contents=invoice_pdf)
print(f'File: {invoice_pdf.display_name} equals to {file_size.total_tokens} tokens')
# File: invoice equals to 821 tokens
3. saída estruturada usando Gemini 2.0 e Pydantic
A saída estruturada é um recurso que garante que o Gemini sempre gere uma resposta que esteja em conformidade com um formato predefinido, como um esquema JSON. Isso significa que o usuário tem mais controle sobre a saída e como ela é integrada ao aplicativo, pois é garantido que ela retorne objetos JSON válidos com um esquema definido pelo usuário.
Atualmente, o Gemini 2.0 suporta 3 tipos diferentes de definições de esquema JSON:
- Um único tipo Python, como no anotação de digitação O mesmo usado no
- Pydantic BaseModel
- genai.types.Schema / Pydantic BaseModel equivalente no dicionário
Vamos dar uma olhada em um exemplo rápido baseado em texto.
from pydantic import BaseModel, Field
# Define a Pydantic model
# Use the Field class to add a description and default value to provide more context to the model
class Topic(BaseModel):
name: str = Field(description="The name of the topic")
class Person(BaseModel):
first_name: str = Field(description="The first name of the person")
last_name: str = Field(description="The last name of the person")
age: int = Field(description="The age of the person, if not provided please return 0")
work_topics: list[Topic] = Field(description="The fields of interest of the person, if not provided please return an empty list")
# Define the prompt
prompt = "Philipp Schmid is a Senior AI Developer Relations Engineer at Google DeepMind working on Gemini, Gemma with the mission to help every developer to build and benefit from AI in a responsible way. "
# Generate a response using the Person model
response = client.models.generate_content(model=model_id, contents=prompt, config={'response_mime_type': 'application/json', 'response_schema': Person})
# print the response as a json string
print(response.text)
# sdk automatically converts the response to the pydantic model
philipp: Person = response.parsed
# access an attribute of the json response
print(f"First name is {philipp.first_name}")
4. extrair dados estruturados do PDF usando o Gemini 2.0
Agora, vamos combinar a API File com a saída estruturada para extrair informações do PDF. O usuário pode criar um método simples que usa um caminho de arquivo local e um modelo Pydantic e retorna dados estruturados para o usuário. O método irá:
- Carregamento de arquivos para a API de arquivos
- fazer uso de API Gemini Gerar uma resposta estruturada
- Converte a resposta em um modelo Pydantic e retorna o
def extract_structured_data(file_path: str, model: BaseModel):
# Upload the file to the File API
file = client.files.upload(file=file_path, config={'display_name': file_path.split('/')[-1].split('.')[0]})
# Generate a structured response using the Gemini API
prompt = f"Extract the structured data from the following PDF file"
response = client.models.generate_content(model=model_id, contents=[prompt, file], config={'response_mime_type': 'application/json', 'response_schema': model})
# Convert the response to the pydantic model and return it
return response.parsed
No exemplo, cada PDF é diferente do outro. Portanto, o usuário precisa definir um modelo Pydantic exclusivo para cada PDF a fim de demonstrar o desempenho do Gemini 2.0. Se o usuário tiver PDFs muito semelhantes e quiser extrair as mesmas informações, o mesmo modelo poderá ser usado para todos os PDFs.
Invoice.pdfNúmero da fatura: extrai o número da fatura, a data e todos os itens da lista, incluindo a descrição, a quantidade, o valor total e o valor bruto totalhandwriting_form.pdfNúmero do formulário de saque, data de início do plano e responsabilidades do plano no início e no final do ano
Observação: Usando o recurso Pydantic, os usuários podem adicionar mais contexto ao modelo para torná-lo mais preciso e realizar alguma validação dos dados. A adição de uma descrição abrangente pode melhorar significativamente o desempenho do modelo. Bibliotecas como a instructor adicionam novas tentativas automáticas com base em erros de validação, o que pode ser muito útil, mas acrescenta custos adicionais de solicitação.
Fatura.pdf

from pydantic import BaseModel, Field
class Item(BaseModel):
description: str = Field(description="The description of the item")
quantity: float = Field(description="The Qty of the item")
gross_worth: float = Field(description="The gross worth of the item")
class Invoice(BaseModel):
"""Extract the invoice number, date and all list items with description, quantity and gross worth and the total gross worth."""
invoice_number: str = Field(description="The invoice number e.g. 1234567890")
date: str = Field(description="The date of the invoice e.g. 2024-01-01")
items: list[Item] = Field(description="The list of items with description, quantity and gross worth")
total_gross_worth: float = Field(description="The total gross worth of the invoice")
result = extract_structured_data("invoice.pdf", Invoice)
print(type(result))
print(f"Extracted Invoice: {result.invoice_number} on {result.date} with total gross worth {result.total_gross_worth}")
for item in result.items:
print(f"Item: {item.description} with quantity {item.quantity} and gross worth {item.gross_worth}")
Fantástico! O modelo faz um excelente trabalho de extração de informações das faturas.
handwriting_form.pdf

class Form(BaseModel):
"""Extract the form number, fiscal start date, fiscal end date, and the plan liabilities beginning of the year and end of the year."""
form_number: str = Field(description="The Form Number")
start_date: str = Field(description="Effective Date")
beginning_of_year: float = Field(description="The plan liabilities beginning of the year")
end_of_year: float = Field(description="The plan liabilities end of the year")
result = extract_structured_data("handwriting_form.pdf", Form)
print(f'Extracted Form Number: {result.form_number} with start date {result.start_date}. \nPlan liabilities beginning of the year {result.beginning_of_year} and end of the year {result.end_of_year}')
# Extracted Form Number: CA530082 with start date 02/05/2022.
# Plan liabilities beginning of the year 40000.0 and end of the year 55000.0
Práticas recomendadas e limitações
Ao usar o Gemini 2.0 para o processamento de PDF, tenha em mente as seguintes considerações:
- Gerenciamento do tamanho do arquivo: embora a API de arquivos ofereça suporte a arquivos grandes, a prática recomendada é otimizar os PDFs antes de fazer o upload.
- Limites de token: ao trabalhar com documentos grandes, verifique as contagens de token para garantir que os usuários permaneçam dentro dos limites e orçamentos do modelo.
- Projeto de saída estruturado: projetar cuidadosamente o modelo Pydantic do usuário para capturar todas as informações necessárias e, ao mesmo tempo, manter a clareza; adicionar descrições e exemplos pode melhorar o desempenho do modelo.
- Tratamento de erros: implemente um tratamento robusto de erros para upload de arquivos e estados de processamento, incluindo novas tentativas e tratamento de mensagens de erro dos modelos.
chegar a um veredicto
Os recursos multimodais do Gemini 2.0, combinados com a saída estruturada, ajudam os usuários a processar e extrair informações de PDFs e outros documentos. Isso elimina processos complexos e demorados de extração de dados manuais ou semiautomatizados. Se você estiver criando um sistema de processamento de faturas, uma ferramenta de análise de documentos ou qualquer outro aplicativo centrado em documentos, experimente o Gemini 2.0, pois inicialmente ele é gratuito para testes e, depois, custa apenas US$ 0,1 por milhão de tokens de entrada. O Google enfatiza que o Gemini 2.0 é gratuito para ser testado inicialmente e depois custa apenas US$ 0,1 por milhão de tokens, o que certamente reduz a barreira para os usuários experimentarem a nova tecnologia, mas a relação custo-benefício a longo prazo ainda não foi revelada.
© declaração de direitos autorais
Direitos autorais do artigo Círculo de compartilhamento de IA A todos, favor não reproduzir sem permissão.
Publicações relacionadas



Nenhum comentário...