Raciocínio complexo com modelos grandes da OpenAI-o1
Em 2022, a OpenAI lançou o ChatGPT, que se tornou o aplicativo mais rápido do mundo a ultrapassar as centenas de milhões de usuários e, naquela época, as pessoas achavam que estávamos mais próximos da IA real. Mas as pessoas logo descobriram que o ChatGPT podia manter conversas e até escrever poemas e artigos, mas ainda era insatisfatório em lógica simples, como o famoso "morango" com vários "r".
Agora, dois anos depois, a OpenAI lançou o modelo o1, que gerou discussões acaloradas sobre a metodologia por trás dele com sua poderosa capacidade de raciocínio lógico e a poderosa capacidade de ocultação de tecnologia da OpenAI. Neste artigo, analisamos alguns artigos relacionados para dar uma olhada no desenvolvimento do recurso de raciocínio complexo de modelos grandes, usando a especulação sobre a tecnologia do modelo o1 como guia.
01 Histórico
Chain of Thought (Cadeia de pensamento), ou CoT, é um conceito da psicologia cognitiva e da educação que descreve o processo passo a passo pelo qual o pensamento das pessoas se desenvolve à medida que elas resolvem problemas ou tomam decisões. Em vez de simplesmente saltar diretamente da pergunta para a resposta, o processo envolve várias etapas, cada uma das quais pode envolver a coleta, a análise, a avaliação e a revisão de conclusões anteriores. Dessa forma, os indivíduos são capazes de lidar com problemas complexos de forma mais sistemática e construir soluções racionais.
Ajuste fino supervisionadoA aprendizagem supervisionada, ou aprendizado supervisionado, é a forma mais comum de treinamento de modelos no campo da aprendizagem de máquina, usando conjuntos de dados rotulados para que o modelo aprenda a classificar dados com precisão ou prever resultados. À medida que os dados de entrada entram no modelo, o aprendizado supervisionado ajusta os pesos do modelo até que ele produza um ajuste adequado.
O ajuste fino supervisionado, ou SFT, refere-se à aprendizagem supervisionada, em que treinamos um modelo com um conjunto de dados que se concentra em uma tarefa específica sobre um modelo de base existente, visando à sua capacidade de aprender com ele para resolver a tarefa específica.
Aprendizado por reforçoO aprendizado por reforço, ou RL, é um dos três paradigmas básicos de aprendizado de máquina, juntamente com o aprendizado supervisionado e não supervisionado. O aprendizado por reforço se concentra em encontrar um equilíbrio entre a exploração (o desconhecido) e o aproveitamento (o conhecido), permitindo que os modelos aprendam os comportamentos certos com o objetivo de maximizar os retornos de longo prazo.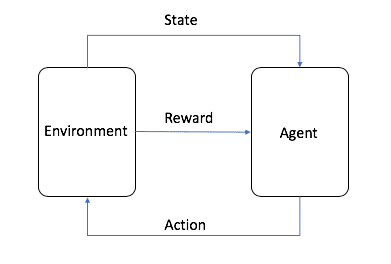
A imagem é da AWS, conforme mostrado na figura, no aprendizado por reforço, o agente é o alvo final que precisamos treinar e interagir com o ambiente definido (Environment) para executar ações e gerar recompensas (Reward) e transferência de estado (state), o agente com base nas recompensas para aprender a selecionar melhor a próxima ação Esse ciclo é o processo de treinamento da aprendizagem por reforço.
No processo de treinamento do LLM, a RL desempenha um papel importante, e tornou-se um consenso no setor que a fase de pré-treinamento é alinhada com a ajuda da RLHF. No aprendizado por reforço do LLM, geralmente precisamos de outro modelo para simular o ambiente para recompensar a saída do LLM, que é chamado de Modelo de Recompensa, ou RM.
Teremos vários modelos: o modelo Actor, o modelo Critic e o modelo Reward. De acordo com a estrutura de treinamento de RL padrão acima, o Actor e o Critic formam o Agente e a Recompensa é treinada como o Ambiente no processo de treinamento de RL.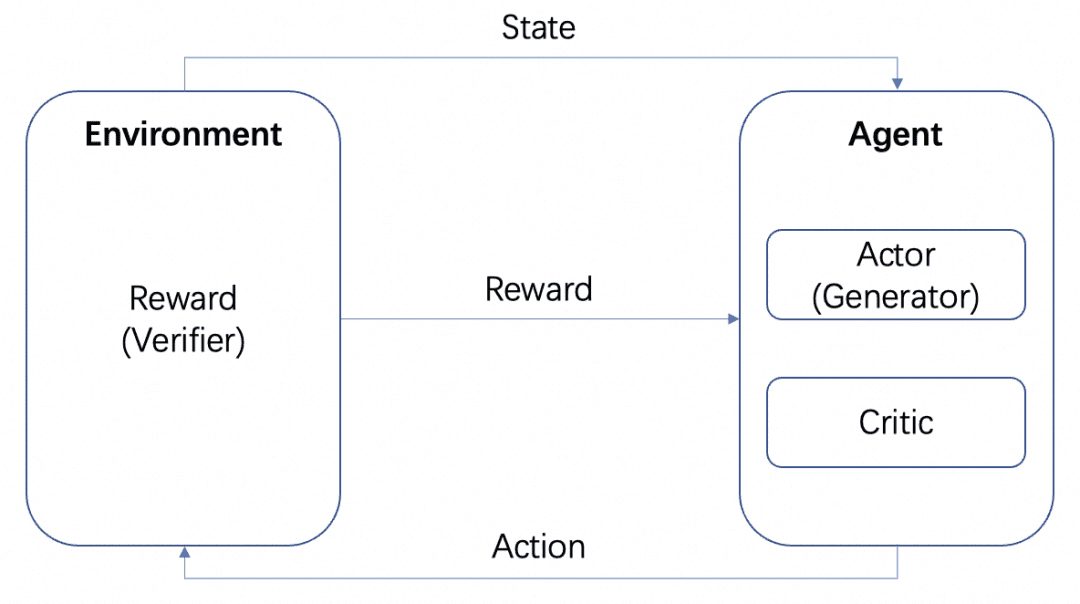
Mas, após o treinamento, podemos implantar os modelos Actor ou Reward separadamente, em que o modelo Actor é o nosso Generator e o modelo Reward é o Verifier que usamos para medir a qualidade da geração do Generator, que é a estrutura Generator-Verifier mencionada pela OpenAI no documento Let's verify step by step. Essa é a estrutura Gerador-Verificador mencionada no documento Vamos verificar passo a passo da OpenAI.
E os modelos de recompensa podem ser categorizados de acordo com o grau de detalhamento do feedback:
-Modelo de recompensa baseado em processo PRM: o PRM fornece feedback com base nos resultados intermediários do LLM.
-Modelo de recompensa baseado em resultados ORM: o ORM fornece feedback somente após o resultado final.
Abordamos esses dois conceitos em cenários específicos a seguir.
Monte Carlo Tree Search O Monte Carlo Tree Search, ou MCTS, é um algoritmo de busca em árvore com a ideia central de que, a cada etapa, vários comportamentos são tentados e os possíveis payoffs futuros dos comportamentos são previstos, concentrando-se na exploração seletiva de alguns dos comportamentos mais recompensadores.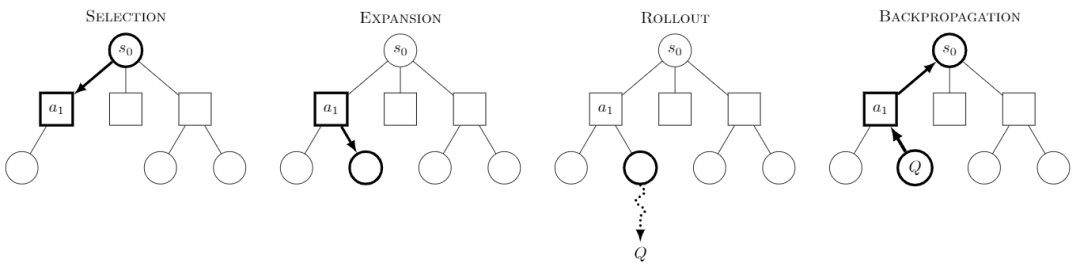
Imagem da Wikipedia. Diz-se que cada missão é dividida em quatro etapas:
-Seleção: selecione um nó
-Expansão: gera um novo nó a partir desse nó a ser explorado
-Rollout: executa uma simulação ao longo desse novo nó para produzir um resultado
-Propagação para trás: os resultados da simulação são propagados para trás, atualizando os nós nos caminhos.
Ao explorar continuamente, obtemos uma árvore e cada nó tem um possível resultado da exploração e podemos pesquisar nessa árvore para obter o melhor caminho ou resultado.
O uso do MCTS para RL resultou em modelos bem conhecidos, como o AlphaZero, que executa as etapas de seleção e distribuição usando um modelo treinável. A abordagem do AlphaZero é usar modelos treináveis para executar as etapas de seleção e lançamento, reduzindo assim o grande espaço de pesquisa e o custo de simulação do MCTS para obter com eficiência a solução ideal, por exemplo, usando a Policy Network para pesquisar com eficiência a próxima etapa possível e usando a Value Network para determinar o valor de cada etapa em vez da simulação de lançamento.
A capacidade de raciocínio em várias etapas da o1 Quando se trata do modelo o1, temos que falar sobre sua incrível capacidade de raciocínio em várias etapas, e o site da OpenAI dá vários exemplos para mostrar sua capacidade de raciocínio em várias etapas em senhas, códigos, matemática, palavras cruzadas e assim por diante. No exemplo relacionado à "senha", o resultado da decodificação é "THERE ARE THREE R'S IN STRAWBERRY", que também é o resultado da "senha" existente. ChatGPT Capacidade de raciocínio para responder.
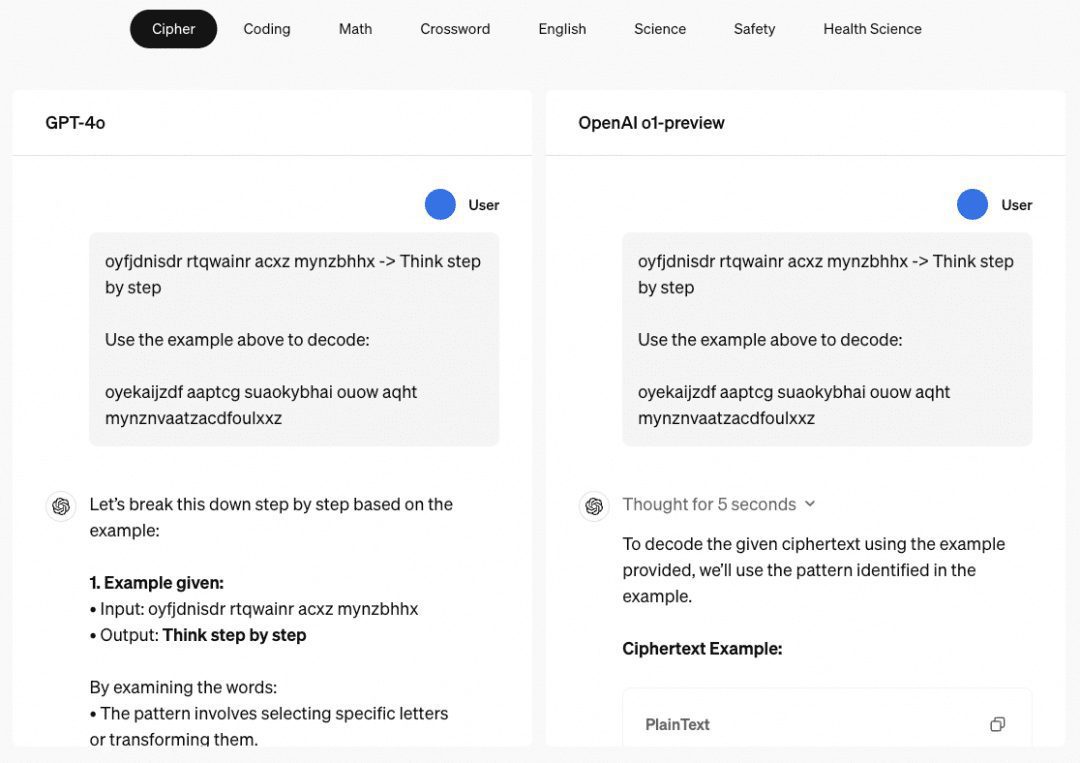
Portanto, exploramos vários documentos principalmente nessa capacidade, reunidos e resumidos conforme descrito abaixo.
02 Engenharia da palavra-chave
Atualmente, o treinamento de IA geralmente requer uma grande quantidade de dados de exemplo, enquanto o aprendizado com poucos dados de exemplo é chamado de Few-Shot ou Zero-Shot, se nenhum exemplo for fornecido.
O artigo "Chain of Thought Prompting Elicits Reasoning in Large Language Models" propõe uma abordagem Few-Shot para aprimorar o raciocínio matemático dos modelos:
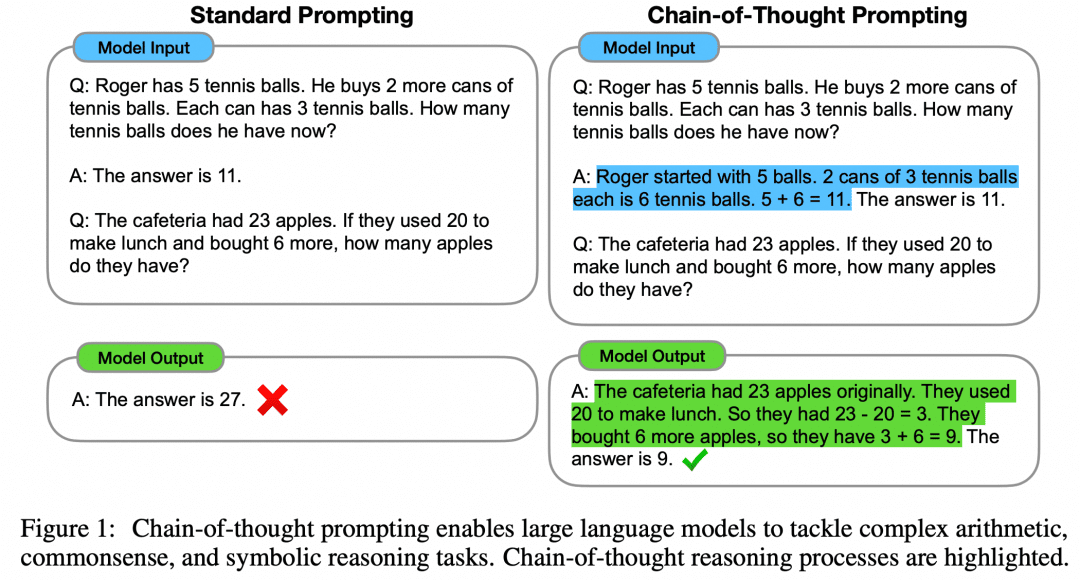
Conforme mostrado na figura, o lado esquerdo fornece uma amostra para o LLM aprender no Prompt de entrada do LLM, que é o Few-Shot Learning, mas seu efeito ainda é insatisfatório. O documento propõe esse paradigma Few-Shot com CoT no lado direito. Portanto, à direita, no Few-Shot, não são fornecidas apenas a pergunta e a resposta de um exemplo, mas também o processo intermediário e o resultado. Os autores descobriram que o Few-Shot Prompt construído dessa forma, usando CoT, melhora a inferência do modelo.
À medida que o próprio modelo é aprimorado e mais pesquisas são feitas, o artigo "Large Language Models are Zero-Shot Reasoners" revela ainda que o Zero-Shot também pode usar a CoT para aprimorar os recursos do modelo:

Em vez de se dar ao trabalho de construir um processo intermediário de CoT, ou mesmo de construir exemplos para Few-Shot, um simples "Vamos pensar passo a passo" pode aprimorar o LLM. Parece uma decisão fácil. Posteriormente, a OpenAI alterou esse prompt para "Vamos verificar passo a passo", e esse documento agora é o núcleo de leituras repetidas por qualquer pessoa que queira entender o1.
É claro que a criação da CoT com base apenas na engenharia de palavras-chave não pode ser o motivo pelo qual o1 é tão eficiente, mas a CoT, uma abordagem passo a passo para avançar a lógica, tornou-se a direção dominante para aumentar o raciocínio em modelos grandes.
03 CoT + ajuste fino supervisionado
É claro que houve tentativas de ensinar os recursos de raciocínio em várias etapas da CoT aos LLMs usando o SFT. "STaR: Bootstrapping Reasoning With Reasoning" é uma das primeiras tentativas. A imagem abaixo foi extraída desse documento: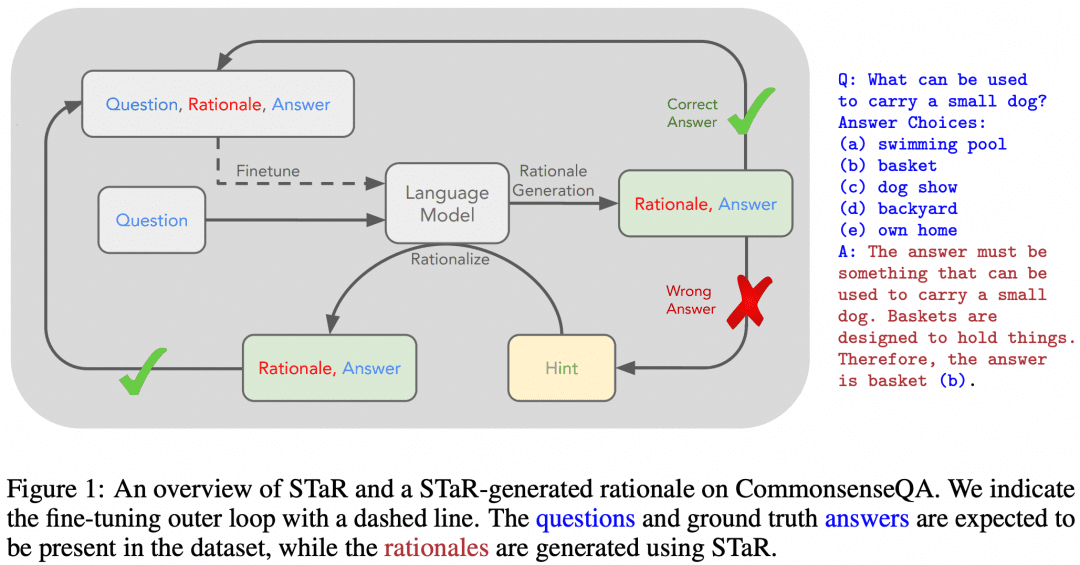
A ideia do artigo é a seguinte. Em primeiro lugar, usamos a abordagem de engenharia de palavras-chave mencionada acima para fazer com que o modelo experimente a CoT para raciocinar sobre o conjunto de dados, o que resultará em um lote de respostas que, naturalmente, terá respostas certas e erradas:
Se obtivermos uma resposta correta, consideraremos a CoT correspondente gerada pelo modelo como uma CoT de alta qualidade e, em seguida, coletaremos essas amostras de "pergunta-CoT-resposta" de alta qualidade para obter um novo conjunto de dados e usaremos esse conjunto de dados para SFT do nosso LLM e continuaremos a repetir para obter o LLM com melhor capacidade de raciocínio. LLM;
Se houver algumas perguntas que o LLM sempre responde de forma errada, então permitimos que o LLM veja diretamente a "Pergunta+Resposta" e que ele gere uma CoT da pergunta para a resposta, e podemos pensar que a CoT gerada pelo LLM está correta quando a resposta é conhecida, e essa parte da amostra "Pergunta-CoT-Resposta" também pode ser usada para treinamento. A amostra "Pergunta-CoT-Resposta" também pode ser usada para treinamento.
Como esse estudo é bastante antigo, é fácil encontrar as lacunas nele agora, por exemplo, o LLM, na verdade, costuma ter "processo errado, mas resultado certo" ou "processo certo, mas resultado errado", o que significa que as amostras que usamos para o treinamento acima não são realmente de alta qualidade. Isso significa que as amostras que usamos para o treinamento acima não são realmente de alta qualidade. Então, como obter um processo de inferência mais correto?
04 Pesquisa em árvore Monte Carlo
Aprendemos acima que a CoT decompõe a lógica da pergunta à resposta em um processo de pensamento intermediário após um processo de pensamento intermediário, portanto, o MCTS pode ser usado para procurar a melhor etapa de pensamento para a próxima etapa de raciocínio e, portanto, a melhor cadeia de pensamentos de raciocínio? Naturalmente, sim.
O raciocínio mútuo torna os LLMs menores mais fortes Os solucionadores de problemas desenvolveram esse algoritmo MCTS, chamado rStar, e abriram o projeto no GitHub. A imagem abaixo foi extraída do artigo, e ela não tem alguma semelhança com a imagem do MCTS acima?
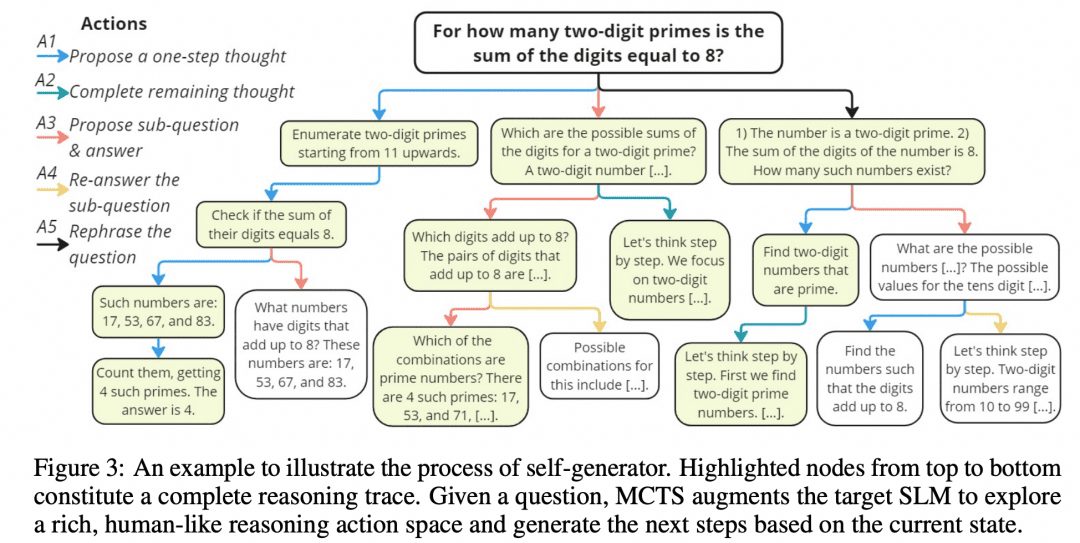
Conforme mostrado na figura acima, os pesquisadores dividiram as etapas intermediárias da CoT em 5 tipos de nós:
1. geração das próximas etapas do raciocínio
2. gerar todos os raciocínios subsequentes
3. gere uma subpergunta e uma resposta
4. responder novamente às subperguntas
5. problemas de reconfiguração
O MCTS é então usado para determinar o próximo nó da etapa de pensamento. O caminho ligado por nó após nó de pensamento é o CoT. Simplesmente pegamos todos os resultados finais que recebemos e votamos neles.
É claro que os autores estudaram mais do que isso, pois, conforme mencionado acima, é necessário medir a correção dos nós e a correção do raciocínio em cada etapa, e os pesquisadores desenvolveram o seguinte método:
-Filtragem de discriminador: após a obtenção do caminho de inferência original, mascare aleatoriamente uma parte dele e, em seguida, use outro modelo para a saída; se obtivermos o mesmo resultado que o gerador original, então o caminho de inferência original é confiável.
-Correção da resposta: todas as respostas finais são coletadas e a proporção de uma determinada resposta em relação a todas as respostas é a pontuação da resposta.
-Correção do processo: para cada nó de raciocínio no caminho, vários nós do tipo 2 são gerados em paralelo para gerar vários resultados finais de uma etapa, e a proporção desses resultados que são o resultado final do caminho atual é considerada como a pontuação do processo desse nó de raciocínio. A medida de três partes leva a um caminho ideal, e o resultado final do caminho ideal é considerado como o resultado do MCTS.
05 Gerador + verificador
Além do MCTS acima, que permite que os processos de pensamento sejam organizados em árvores e explorados, há outras maneiras de fazer isso. O aprendizado por reforço, por exemplo, e mais uma vez vamos dar uma olhada na introdução ao aprendizado por reforço: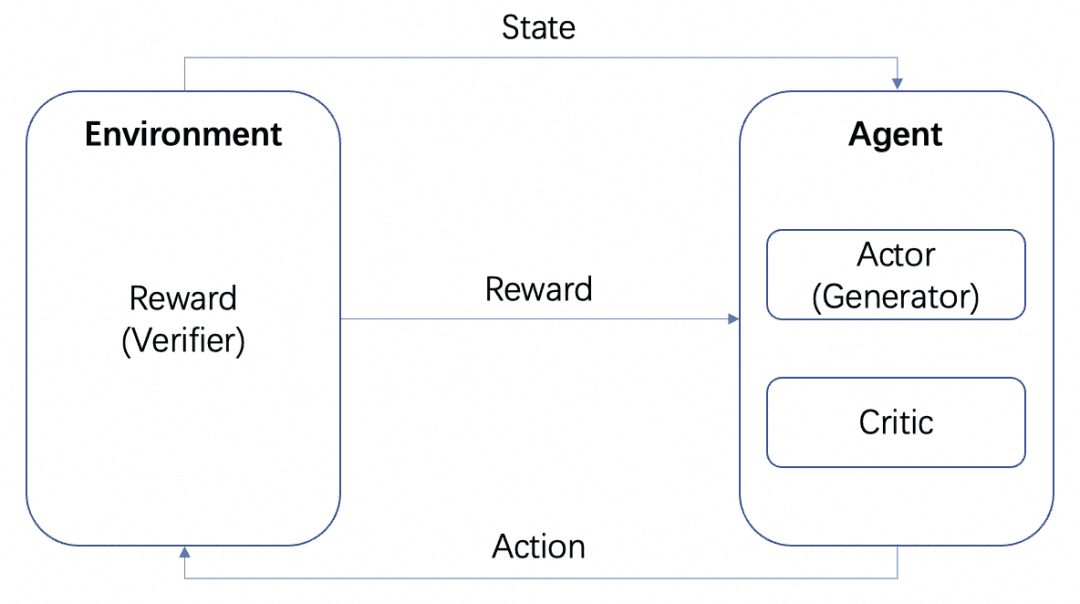
Se considerarmos o LLM como o Ator, outro RM treinado no problema como o Ambiente e um Crítico implícito, um loop de aprendizagem por reforço seria: o Ator produz um resultado para o problema, o RM verifica a exatidão do resultado e o alimenta para o Agente, e o Ator e o Crítico treinam de acordo com a Recompensa. O Ator e o Crítico são treinados com base na Recompensa. Chamamos o Agente de Gerador, porque sua tarefa é gerar o resultado, e o RM de Verificador, porque sua tarefa é verificar o resultado.
Se você pensar bem, a relação entre Ator e Crítico em um Agente não é muito semelhante à rede de Política e Valor usada pelo AlphaZero? Também é verdade que as redes de Política e Valor se encaixam na estrutura de Ator e Crítico.
Agora resumimos que um processo de aprendizagem por reforço envolve três redes: Actor, Critic e RM. Na implementação, diferentes estruturas são usadas dependendo da situação: em um jogo de tabuleiro, o vencedor só pode ser conhecido no final do jogo, e o RM oferece uma recompensa muito pequena, portanto, optamos por manter a estrutura Actor-Critic na implementação e, em seguida, executar o MCTS para obter uma solução melhor; enquanto na implementação do LLM, nosso RM treinado pode fornecer feedback oportuno, portanto, podemos combinar naturalmente o Actor e o RM em uma estrutura Generator-Verifier na implementação. Na implementação do LLM, nosso RM treinado pode fornecer feedback oportuno, de modo que podemos combinar naturalmente o Actor e o RM na estrutura do Gerador-Verificador no momento da implementação.
A OpenAI tem trabalhado nessa direção desde os dias do GPT3 (o ChatGPT é baseado no modelo GPT-3.5). A solução que eles deram foi o documento Training Verifiers to Solve Math Word Problems. A imagem abaixo foi extraída desse documento:
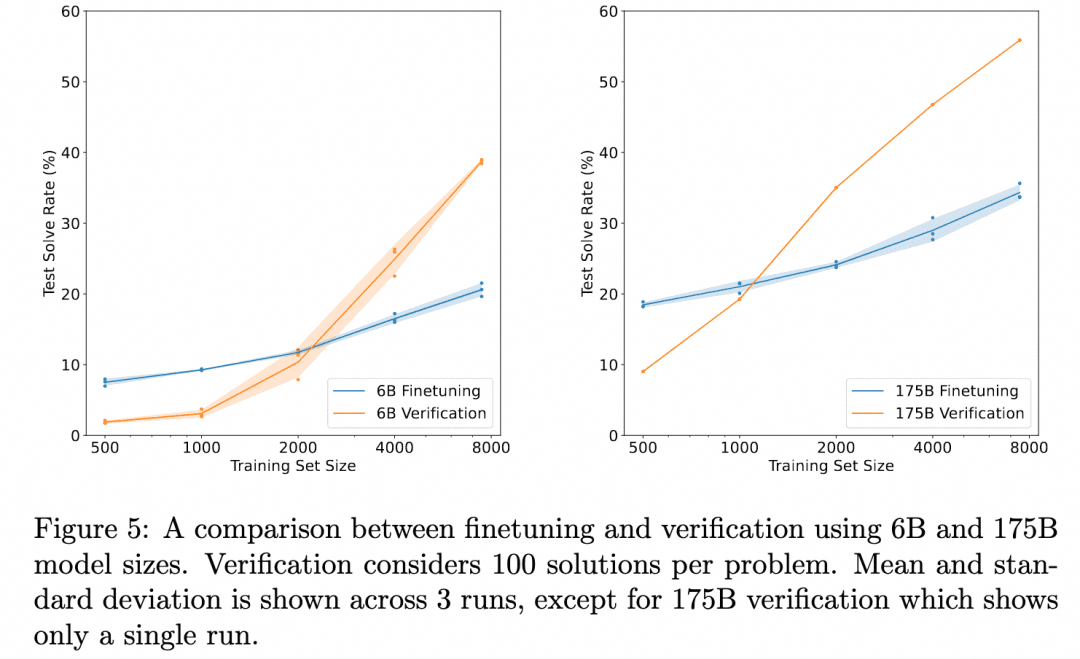
O gráfico acima compara: "Correção dos resultados obtidos apenas com o ajuste fino do Gerador" com "Correção dos resultados obtidos com o ajuste fino de um Verificador, avaliando vários resultados produzidos pelo Gerador e selecionando o resultado mais bem avaliado". Isso demonstra a eficácia do Verificador.
Isso ocorre porque a tarefa aqui é: raciocinar sobre o problema para obter o resultado. Portanto, o Gerador usado não produz um processo de raciocínio intermediário, mas produz o resultado diretamente, e o Verificador também é o ORM (Outcome Based Reward Model) que mencionamos na seção sobre Aprendizado por reforço, que serve para produzir uma pontuação com base no resultado do Gerador. Portanto, não há nenhum processo de inferência de várias etapas envolvido aqui que queremos explorar, apenas a descoberta de que a validação do ORM produz melhores resultados finais do que o simples ajuste fino.
Assim, a equipe da OpenAI foi além: por um lado, eles fizeram com que o Generator não produzisse resultados diretamente, mas gerasse um raciocínio passo a passo; por outro lado, eles treinaram um PRM (Process-based Reward Model) que atua como um Verificador, cuja função é gerar pontuações para cada etapa do processo de raciocínio do Generator. Acreditamos que os resultados produzidos pela busca da exatidão no processo de raciocínio do Generator dessa forma são os mais prováveis de serem corretos.
Esse é o Let's verify passo a passo que mencionamos acima. Nesse trabalho, a equipe comparou os resultados de inferência gerados pela pesquisa do mesmo gerador com PRM e ORM como verificadores (nesse ponto, o gerador deles já era GPT-4) e provou que o PRM como verificador buscou resultados mais precisos. A figura abaixo foi extraída do documento:
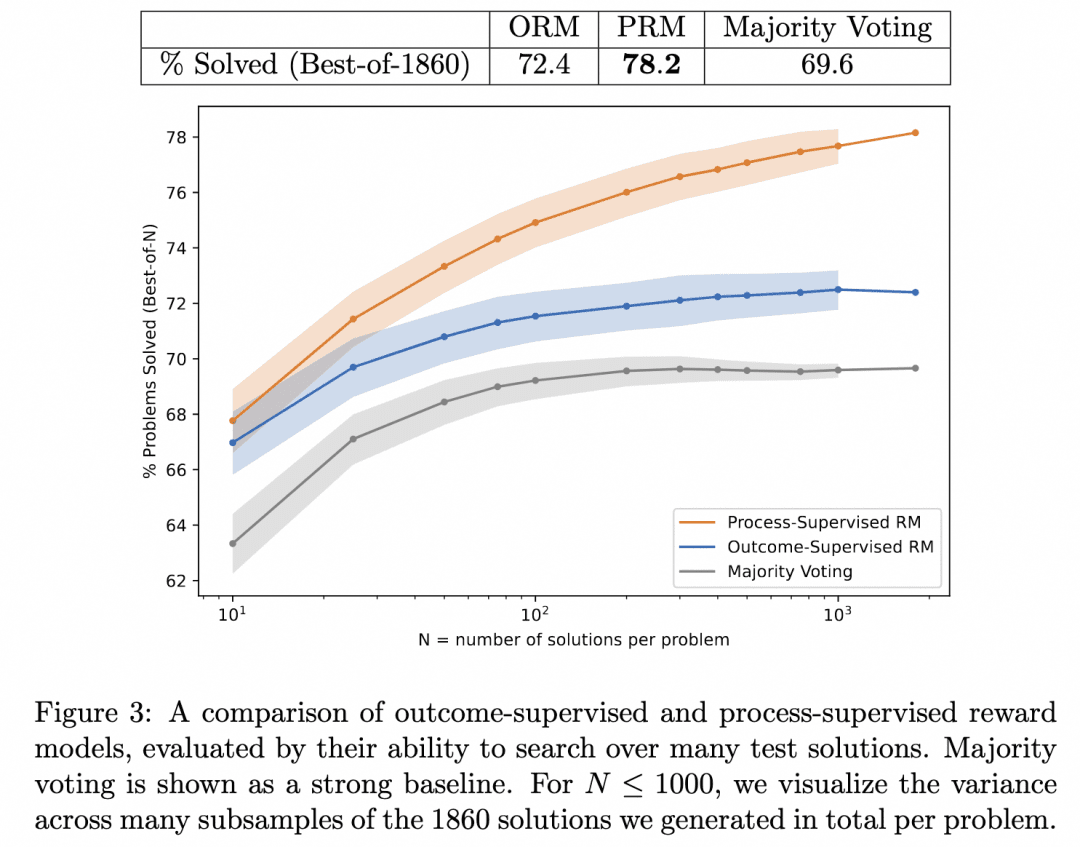
A figura acima ilustra que o mesmo gerador de inferência por etapas produz resultados em que é válido usarmos o ORM como um verificador para escolher a melhor resposta para o resultado, mas é mais provável que estejamos corretos quando usamos o PRM como um verificador para escolher a melhor resposta para o processo!
É essa a tecnologia por trás do o1 que estamos procurando? Neste momento, só podemos supor que essa é uma das principais tecnologias por trás dele. Os motivos são os seguintes:
1, este documento está relativamente longe do lançamento do o1, e um ano é tempo suficiente para que os pesquisadores da OpenAI se aprofundem nessa direção. Devido à validade do PRM, embora um ano também seja tempo suficiente para se ajustar a outras direções, ainda achamos que eles estão se aprofundando em vez de se voltarem.
2. o documento demonstra a eficácia do PRM como verificador, e está claro que a próxima etapa poderia ser aprimorar o gerador com um verificador poderoso para produzir melhores resultados. Mas o documento não vai até lá, então temos motivos para acreditar que a OpenAI deve ter tentado, e não está claro se o resultado foi o1.
Com essa suposição fora do caminho, vamos explorar outras maneiras de usar o Verifier para pesquisa. O artigo "Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters" (Dimensionar a computação do tempo de teste do LLM de forma otimizada pode ser mais eficaz do que dimensionar os parâmetros do modelo) do Google DeepMind em agosto passado faz mais pesquisas. Esse artigo é visto por muitos como mostrando uma linha técnica semelhante aos princípios por trás do o1. A imagem abaixo é desse documento:
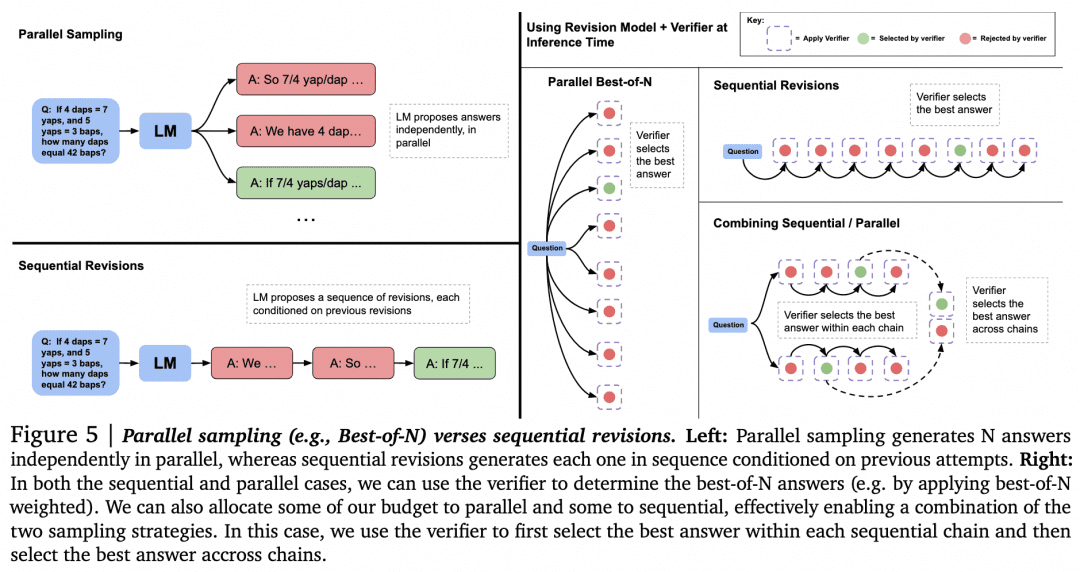
Agora que temos um Gerador e um Verificador, como podemos fazer com que eles trabalhem em conjunto para obter os melhores resultados? Uma maneira de fazer isso, conforme mencionado acima, é fazer com que o Gerador faça uma amostragem paralela para obter vários resultados, e o Verificador os avalia e escolhe a pontuação mais alta. Essa é a abordagem de amostragem paralela + melhor de N à esquerda na figura acima. Mas, obviamente, há outras abordagens:
-Ao gerar vários resultados, além da amostragem de vários resultados em paralelo, também é possível que o Generator gere um resultado e, em seguida, verifique e corrija o próprio resultado para obter uma sequência de respostas, em que elas não estão mais em paralelo umas com as outras.
-Pode haver alternativas para o melhor de N quando a seleção é feita pelo verificador. Conforme mostrado na figura a seguir, retirada do documento:
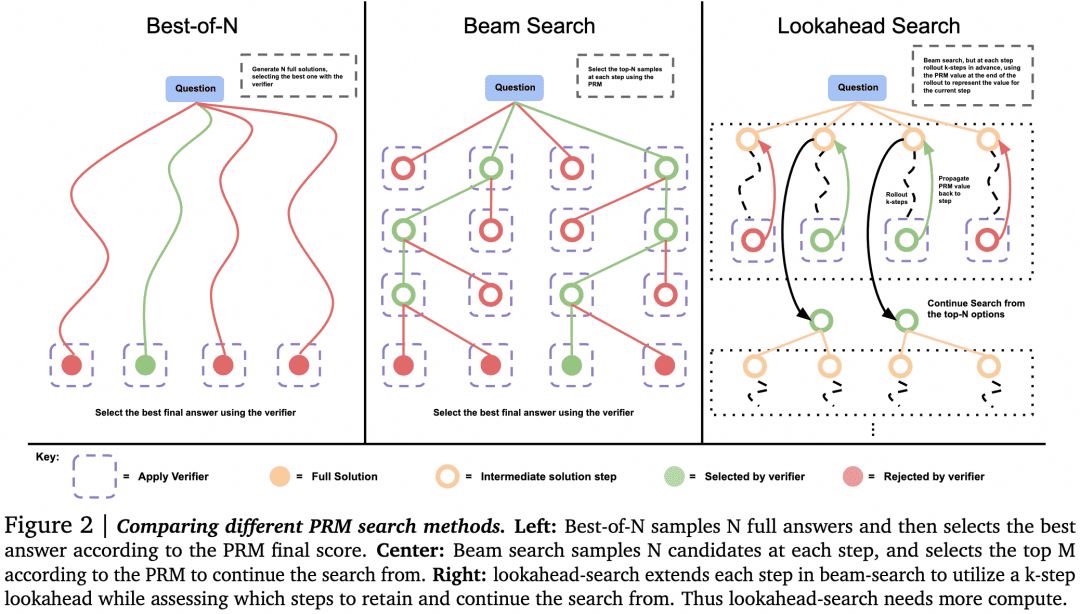
O documento concluiu que, para problemas simples, devemos usar o Verifier para incentivar o Generator a se autoverificar e corrigir, em vez de fazer buscas cegas em paralelo. Para problemas complexos, é melhor que o Generator tente diferentes soluções em paralelo.
Um trabalho semelhante é A Comparative Study on Reasoning Patterns of OpenAI's o1 Model (Um estudo comparativo sobre padrões de raciocínio do modelo o1 da OpenAI). A equipe do artigo abriu o Open-o1, uma réplica do o1, no GitHub, e este artigo é o resultado de algumas de suas pesquisas após o lançamento do o1. A imagem abaixo foi extraída do artigo:
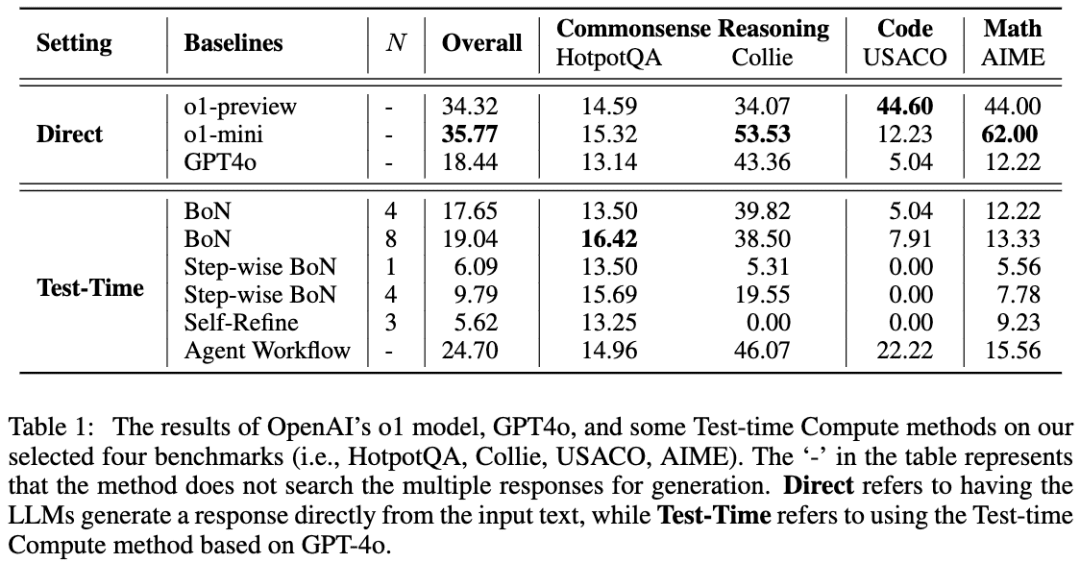
A equipe usou o GPT-4o como modelo de esqueleto e, em seguida, comparou seus resultados usando quatro abordagens comuns para fazer com que os LLMs pensem antes de raciocinar. A equipe constatou que, na tarefa HotpotQA, as abordagens Best-of-N e Step-wise BoN foram capazes de melhorar significativamente o raciocínio do LLM, sendo que a BoN até mesmo fez com que o GPT-4o superasse o modelo o1.
06 OpenR
Dos atuais projetos de código aberto que estão tentando replicar o o1, o OpenR é um dos que têm um grau relativamente alto de conclusão.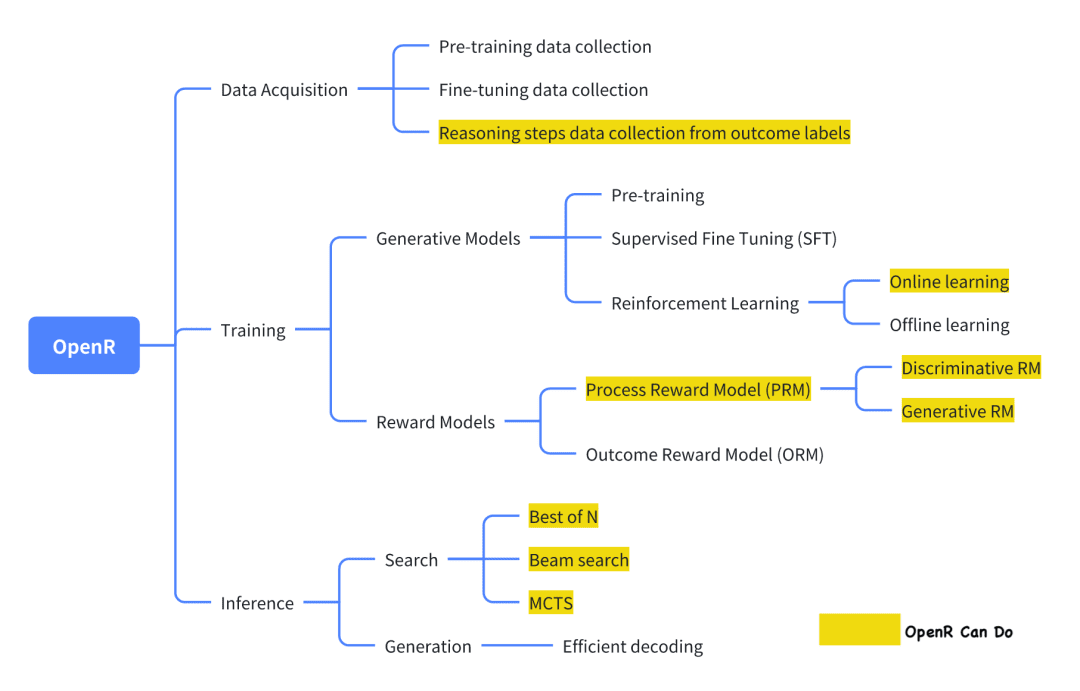
A imagem é de sua documentação oficial, que, como está, implementa a coleta de dados, bem como o treinamento e a implantação de acordo com a estrutura do Generator-Verifier.
Coleta de dados De acordo com a introdução oficial, o método de coleta de dados é do documento: "Improve Mathematical Reasoning in Language Models by Automated Process Supervision". Em resumo, trata-se de usar o MCTS para estender o conjunto de dados original problem-final_answer para gerar etapas de inferência de CoT. Por fim, é obtido um conjunto de dados MATH-APS.
Os conjuntos de dados relevantes foram hospedados no ModelScope:
Conjunto de dados PRM800K-Stepwise:
https://modelscope.cn/datasets/AI-ModelScope/openai-prm800k-stepwise-critic/
Conjunto de dados MATH-APS:
https://modelscope.cn/datasets/AI-ModelScope/MATH-APS/
Conjunto de dados Math-Shepherd:
https://modelscope.cn/datasets/AI-ModelScope/Math-Shepherd
A equipe de treinamento do Generator usa uma variante do algoritmo PPO do aprendizado por reforço para treinar o Generator. Em resumo, o algoritmo PPO usa as informações de Recompensa fornecidas pelo Modelo de Recompensa para treinar o Generator e, ao mesmo tempo, restringe o Ator para que ele não se desvie muito do Ator original durante o processo de aprendizado, para evitar a perda do conhecimento existente. Atualmente, o OpenR oferece suporte a três variantes: APPO, GRPO e TPPO.
A equipe de treinamento do Virifier usou o aprendizado supervisionado por SFT para treinar um PRM usando o conjunto de dados MATH-APS acima, bem como dois conjuntos de dados de código aberto, PRM800K e Math-Shepherd. Especificamente, nesses três conjuntos de dados em nível de etapa, a equipe rotulou cada etapa com um rótulo "+" ou "-" e, em seguida, pediu ao PRM que aprendesse a prever o rótulo de cada etapa e determinasse se estava correto ou incorreto.
O modelo usa dados "step-wise" para treinamento de PPO, e os pesos resultantes do modelo foram hospedados no ModelScope, que atualmente fornece pontos de verificação para modelos SFT, PRM e RL, bem como alguns formatos GGUF:
O modelo mistral-7b-sft:
https://modelscope.cn/models/AI-ModelScope/mistral-7b-sft
Modelo RL (versão GGUF):
https://modelscope.cn/models/QuantFactory/math-shepherd-mistral-7b-rl-GGUF
Modelagem de PRM:
-Versão GGUF: https://modelscope.cn/models/QuantFactory/math-shepherd-mistral-7b-prm-GGUF
-Modelo PRM: https://modelscope.cn/models/AI-ModelScope/math-shepherd-mistral-7b-prm
Implantação de raciocínio No momento da implantação, o OpenR usa algoritmos de pesquisa por meio do Gerador e do Verificador especificados para obter o processo de raciocínio e a resposta final. Atualmente, há suporte para MCTS, Beam Search e best_of_n.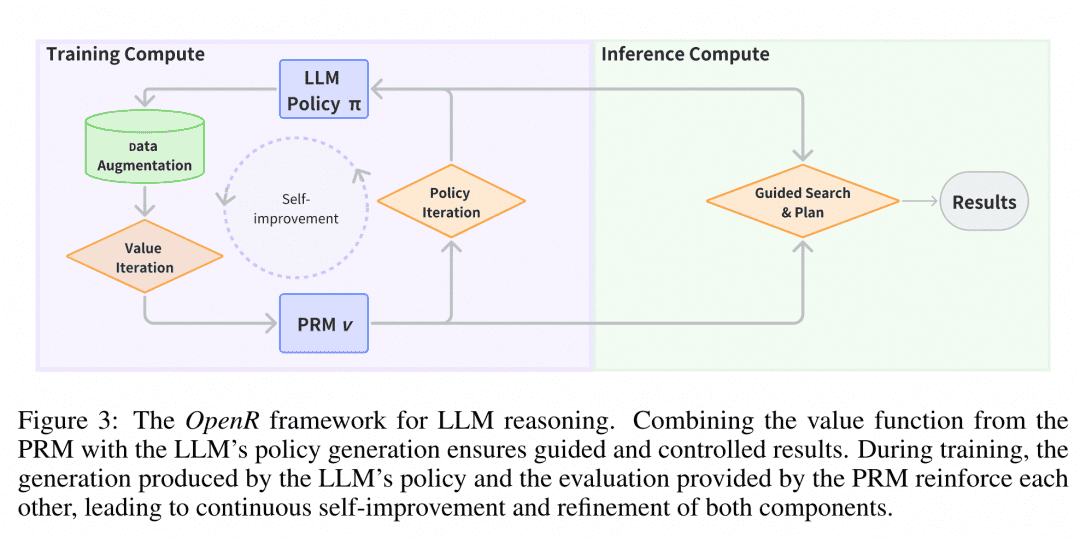
A estrutura do OpenR é mostrada na figura e, até o momento, o OpenR implementa uma réplica da cadeia do O1, desde a coleta de dados de treinamento, passando pelo treinamento de um PRM, até o uso do PRM para reforçar o aprendizado e, finalmente, a implementação do modelo. Atualmente, o OpenR implementa uma cadeia que replica o O1, desde a coleta de dados de treinamento, passando pelo treinamento de um PRM, até o uso do PRM para reforçar o aprendizado e a implantação do modelo para pesquisa, e a equipe tornou todo esse trabalho de código aberto para que a comunidade possa aprender e experimentar, para que possamos ter uma ideia.
Experiência no Espaço CriativoEmpregamos o serviço de inferência do OpenR no Espaço Criativo da Comunidade Magic Hitch, e os desenvolvedores podem experimentar os efeitos do OpenR on-line acessando o seguinte link: https://www.modelscope.cn/studios/modelscope/OpenR_Inference
07 Conclusão
Os artigos acima sobre raciocínio em várias etapas que investigamos demonstram que permitir que o LLM raciocine passo a passo em vez de pular processos intermediários pode aumentar significativamente sua precisão em problemas relacionados à lógica. Para permitir que o LLM raciocine passo a passo, podemos ajustá-lo usando alguns conjuntos de dados com processos intermediários, além de orientá-lo com engenharia simples de palavras-chave. De forma mais eficiente, podemos treinar um Verificador que possa verificar passo a passo a precisão do Gerador para pesquisar os resultados gerados pelo Gerador.
Com base nas especulações e nos documentos até o momento, parece que a tecnologia provável para avançar em direção à o1 baseia-se precisamente na cooperação entre o poderoso LLM Generator e o LLM Verifier. Esse tipo de auto iteração do pé esquerdo sobre o pé direito contra si mesmo não é a primeira vez na aprendizagem profunda, mas a OpenAI é a primeira a introduzir esse modelo no campo do LLM, que é muito caro apenas para treinar o Gerador, o que é realmente um grande problema.
Portanto, acreditamos que, se quisermos replicar o1, a primeira coisa de que precisamos é um Verificador que possa fornecer assistência e orientação ao Gerador e, para gerar os dados necessários para treinar o Verificador, podemos consultar os capítulos CoT + Supervised Fine-Tune e Monte Carlo Tree Search acima para obter dados de maior qualidade a um custo menor. Para gerar os dados necessários para treinar o Verificador, é possível consultar os capítulos CoT + Supervised Fine-Tune e Monte Carlo Tree Search acima para obter dados de maior qualidade a um custo mais baixo. É por isso que também apresentamos essas tarefas.
Por fim, apresentamos um projeto de código aberto altamente finalizado e, com base no trabalho deles, pudemos organizar nossos pensamentos e ideias.
08 Referência
A solicitação de cadeia de pensamento induz o raciocínio em modelos de linguagem grandes
Modelos de linguagem grandes são raciocinadores de tiro zero
STaR: Bootstrapping Reasoning With Reasoning
O raciocínio mútuo torna os LLMs menores mais fortes na solução de problemas
Treinamento de verificadores para resolver problemas matemáticos com palavras
Vamos verificar passo a passo
O dimensionamento ideal da computação do tempo de teste do LLM pode ser mais eficaz do que o dimensionamento dos parâmetros do modelo
Um estudo comparativo sobre os padrões de raciocínio do modelo o1 da OpenAI
OpenR: uma estrutura de código aberto para raciocínio avançado com grandes modelos de linguagem
© declaração de direitos autorais
Direitos autorais do artigo Círculo de compartilhamento de IA A todos, favor não reproduzir sem permissão.
Artigos relacionados




Nenhum comentário...