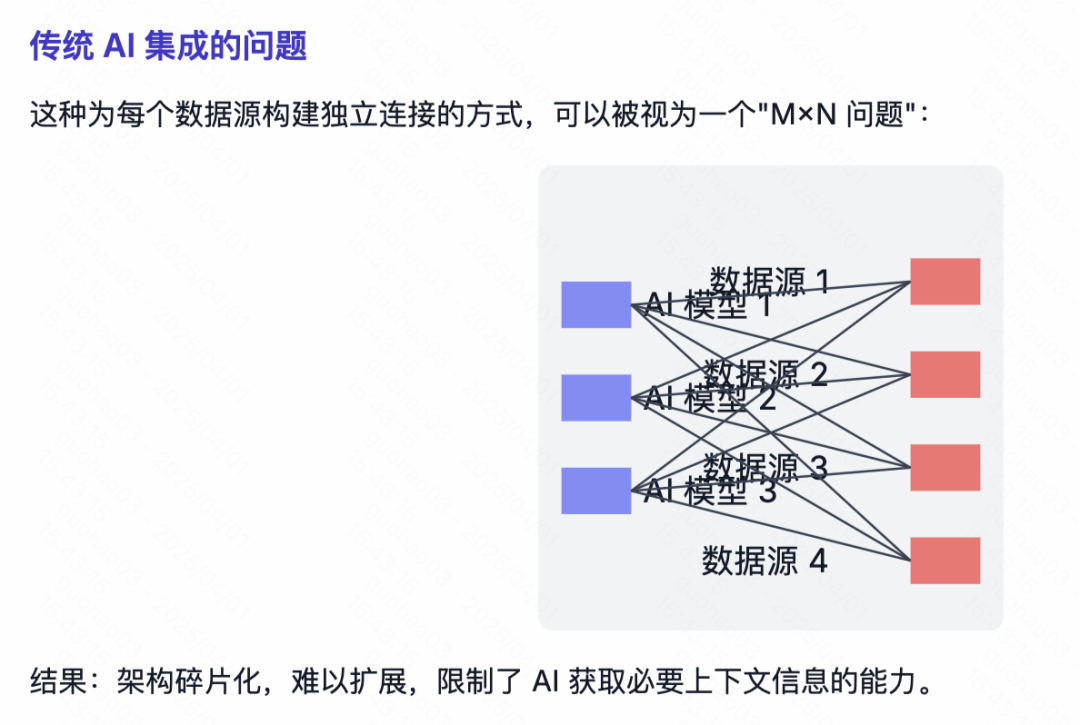
Guia de casos de uso comuns do Claude: Atribuição de ordens de serviço
Este guia descreve como aproveitar os recursos avançados de compreensão de linguagem natural do Claude para categorizar as ordens de serviço de suporte ao cliente em escala, com base na intenção do cliente, na urgência, na prioridade, no perfil do cliente e em outros fatores.
Definir se o Claude deve ou não ser usado para atribuição de ordens de serviço
Aqui estão algumas métricas importantes que indicam que você deve usar LLMs (Large Language Models) como o Claude em vez de métodos tradicionais de aprendizado de máquina para tarefas de classificação:
Você tem dados limitados de treinamento de anotação disponíveis
Os processos tradicionais de aprendizado de máquina exigem grandes conjuntos de dados anotados. O modelo pré-treinado do Claude pode reduzir significativamente o tempo e o custo da preparação de dados, classificando com eficiência as ordens de serviço usando apenas algumas dezenas de exemplos anotados.
Suas categorias de classificação podem mudar ou evoluir com o tempo
Depois que um método tradicional de aprendizado de máquina é estabelecido, modificá-lo pode ser um processo demorado e que consome muitos dados. Por outro lado, à medida que o seu produto ou as necessidades do cliente mudam, o Claude pode se adaptar facilmente às mudanças nas definições de categoria ou às novas categorias sem a necessidade de rotular novamente os dados de treinamento.
Você precisa lidar com entradas de texto complexas e não estruturadas
Os modelos tradicionais de aprendizado de máquina geralmente têm dificuldades com dados não estruturados e exigem uma extensa engenharia de recursos. A compreensão avançada de linguagem do Claude permite uma classificação precisa com base no conteúdo e no contexto, sem depender de estruturas ontológicas rígidas.
Suas regras de classificação são baseadas na compreensão semântica
Os métodos tradicionais de aprendizado de máquina geralmente dependem de modelos de saco de palavras ou de correspondência simples de padrões. Quando as categorias são definidas por condições e não por exemplos, o Claude se destaca na compreensão e na aplicação dessas regras subjacentes.
Você precisa de um raciocínio interpretável para decisões categóricas
O claude pode fornecer explicações legíveis por humanos para suas decisões de classificação, aumentando assim a confiança no sistema automatizado e facilitando a adaptação quando necessário.
Você deseja lidar com casos extremos e ordens de serviço ambíguas com mais eficiência
Os sistemas tradicionais de aprendizado de máquina costumam ter um desempenho ruim ao lidar com anomalias e entradas ambíguas, muitas vezes classificando-as incorretamente ou atribuindo-as a uma categoria "genérica". Os recursos de processamento de linguagem natural do Claude permitem que ele interprete melhor o contexto e as nuances nas ordens de serviço de suporte, reduzindo potencialmente o número de ordens de serviço classificadas incorretamente ou não classificadas que exigem intervenção humana. O número de ordens de serviço classificadas incorretamente ou não classificadas que exigem intervenção manual pode ser reduzido.
Você precisa oferecer suporte multilíngue sem manter vários modelos
As abordagens tradicionais de aprendizado de máquina normalmente exigem a manutenção de modelos separados ou a execução de processos de tradução extensos para cada idioma suportado. Os recursos multilíngues do Claude possibilitam a classificação de ordens de serviço em vários idiomas sem a necessidade de modelos separados ou de processos de tradução extensos, simplificando assim o suporte global ao cliente.
Crie e implemente seu modelo de Big Language para dar suporte a fluxos de trabalho
Conheça seus métodos de suporte atuais
Antes de mergulhar na automação, é fundamental entender primeiro o sistema de ordens de serviço existente. Comece investigando como sua equipe de suporte lida atualmente com o encaminhamento de ordens de serviço.
As seguintes perguntas podem ser consideradas:
- Quais critérios foram usados para determinar o SLA/plano de serviço aplicável?
- O roteamento de ordens de serviço é usado para determinar para qual nível de suporte ou especialista de produto a ordem de serviço deve ser encaminhada?
- Já existem regras ou fluxos de trabalho automatizados em vigor? Em que circunstâncias eles falham?
- Como são tratados os casos extremos ou as ordens de serviço imprecisas?
- Como as equipes priorizam as ordens de serviço?
Quanto mais você souber sobre como os seres humanos lidam com determinadas situações, melhor poderá se comunicar com os clientes. Claude Colaborar nas tarefas.
Definir categorias de intenção do usuário
Uma lista bem definida de categorias de intenção do usuário é essencial para categorizar com precisão as ordens de serviço de suporte usando o Claude. A capacidade do Claude de encaminhar com eficácia as ordens de serviço em seu sistema está diretamente relacionada à clareza das definições de categoria em seu sistema.
Abaixo estão alguns exemplos de categorias e subcategorias de intenção do usuário.
Problemas técnicos
- Problemas de hardware
- vulnerabilidade de software
- problema de compatibilidade
- Problemas de desempenho
gerenciamento de contas
- Redefinir senha
- Problemas de acesso à conta
- Consulta de faturamento
- Alteração de assinatura
Informações sobre o produto
- Consulta de funções
- Problemas de compatibilidade do produto
- Informações sobre preços
- Consultas de disponibilidade
Guia do usuário
- Guia de operação
- Ajuda de função
- Recomendações de melhores práticas
- Guia de solução de problemas
enviar informações de volta
- Relatórios de vulnerabilidade
- Solicitação de função
- Comentários ou sugestões gerais
- reclamar .
Relacionado a pedidos
- Consulta sobre o status do pedido
- Informações de logística
- devolver um produto por outro item
- Modificação de pedidos
solicitação de serviço
- Assistência à instalação
- solicitação de escalonamento
- Programa de manutenção
- Cancelamento do serviço
problema de segurança
- Consulta sobre privacidade de dados
- Relatórios de atividades suspeitas
- Ajuda dos recursos de segurança
Conformidade e jurídico
- Questões de conformidade regulatória
- Consulta sobre os Termos de Serviço
- Solicitações de documentos legais
Suporte emergencial
- Falha de sistemas críticos
- Questões de segurança de emergência
- Questões sensíveis ao tempo
Treinamento e educação
- Solicitações de treinamento de produtos
- Pesquisa de documentos
- Informações sobre webinar ou workshop
Integração e API
- Assistência à integração
- Problemas de uso da API
- Verificação de compatibilidade com terceiros
Além da intenção do usuário, o roteamento e a priorização de ordens de serviço podem ser influenciados por outros fatores, como urgência, tipo de cliente, SLAs ou idioma. Não deixe de considerar outros critérios de roteamento ao criar um sistema de roteamento automatizado.
Estabelecimento de critérios de sucesso
Trabalhe com sua equipe de suporte para usar referências, limites e metas mensuráveisDefinir critérios claros de sucesso.
A seguir, padrões e referências comuns ao usar o Modelo de Linguagem Grande (LLM) para atribuição de ordens de serviço:
Consistência da classificação
Essa métrica avalia a consistência da categorização de ordens de serviço semelhantes da Claude ao longo do tempo. Isso é fundamental para manter a confiabilidade da alocação. Ao usar um conjunto padronizado de modelos de teste de entrada regularmente, a meta é uma consistência de 95% ou melhor.
Velocidade de adaptação
Essa métrica mede a rapidez com que o Claude se adapta a novas categorias ou a mudanças nos padrões das ordens de serviço. Isso é feito por meio da introdução de novos tipos de ordens de serviço e da medição do tempo necessário para que o modelo atinja uma precisão satisfatória (por exemplo, >90%) nessas novas categorias. A meta é conseguir a adaptação em 50 a 100 amostras de ordens de serviço.
processamento multilíngue
Essa métrica avalia a capacidade do Claude de atribuir com precisão ordens de serviço multilíngues. Mede a precisão da atribuição em diferentes idiomas, com o objetivo de não reduzir a precisão em mais de 5-10% em idiomas não dominantes.
Processamento de casos de borda
Essa métrica avalia o desempenho do Claude ao processar ordens de serviço incomuns ou complexas. Um conjunto de testes de casos extremos é criado com o objetivo de obter uma precisão de atribuição de pelo menos 801 TP3T nessas entradas complexas.
enfraquecimento do viés
Essa métrica mede a imparcialidade da alocação do Claude entre diferentes grupos de clientes. As decisões de alocação são revisadas regularmente quanto a possíveis tendências, com o objetivo de obter uma precisão de alocação consistente (dentro de 2-3%) em todos os grupos de clientes.
Eficiência do taco
Esse critério avalia o desempenho do Claude em condições de contexto mínimo, em que é necessário um número reduzido de tokens. Mede a precisão das atribuições quando diferentes quantidades de contexto são fornecidas, com o objetivo de atingir uma precisão de 90% ou mais quando apenas o título da ordem de serviço e uma breve descrição são fornecidos.
Escores de interpretabilidade
Esse indicador avalia a qualidade e a relevância das explicações do Claude sobre suas decisões de alocação. Um avaliador humano pode classificar as explicações (por exemplo, de 1 a 5) com o objetivo de obter uma classificação média de 4 ou mais.
Aqui estão alguns critérios de sucesso comuns, independentemente de você usar ou não um modelo de linguagem grande:
Precisão da distribuição
A precisão da atribuição mede se uma ordem de serviço foi corretamente atribuída à equipe ou ao indivíduo certo na primeira vez. Normalmente, ela é medida como uma porcentagem do total de ordens de serviço atribuídas corretamente. Os benchmarks do setor geralmente visam a uma taxa de precisão de 90-95%, mas isso depende da complexidade da estrutura de suporte.
slot
Essa métrica monitora a rapidez com que uma ordem de serviço é atribuída após ser enviada. Tempos de alocação mais rápidos geralmente levam a uma resolução mais rápida e a uma maior satisfação do cliente. O tempo médio de alocação para sistemas ideais é normalmente inferior a 5 minutos, com muitos sistemas buscando uma alocação quase instantânea (o que é possível quando se usa o LLM).
taxa de redistribuição
A taxa de realocação indica a frequência com que uma ordem de serviço precisa ser realocada após a alocação inicial. Uma taxa de realocação menor indica uma alocação inicial mais precisa. A meta é manter a taxa de redistribuição abaixo de 101 TP3T, com os sistemas de melhor desempenho atingindo 51 TP3T ou menos.
Taxa de resolução no primeiro contato
Essa métrica mede a porcentagem de ordens de serviço que são resolvidas na primeira interação com o cliente. Taxas mais altas de resolução na primeira vez indicam atribuições eficientes e equipes de suporte bem preparadas. Os benchmarks do setor são normalmente de 70 a 751 TP3T, sendo que as equipes de melhor desempenho atingem taxas de resolução na primeira vez de 801 TP3T ou mais.
Tempo médio de processamento
O tempo médio de processamento mede o tempo necessário para resolver uma ordem de serviço do início ao fim. A alocação eficaz pode reduzir significativamente esse tempo. Os parâmetros de referência variam de acordo com o setor e a complexidade, mas muitas organizações buscam manter o tempo médio de processamento de problemas não urgentes em menos de 24 horas.
Índice de satisfação do cliente
Normalmente medidas por meio de pesquisas pós-interação, essas classificações refletem a satisfação geral do cliente com o processo de suporte. A distribuição eficaz contribui para a satisfação. A meta é atingir um índice de satisfação do cliente (CSAT) de 90% ou superior, com as equipes de melhor desempenho atingindo um índice de satisfação de 95% ou superior.
taxa de promoção
Esse indicador mede a frequência com que as ordens de serviço precisam ser escaladas para um nível mais alto de suporte. Uma taxa de escalonamento menor geralmente indica uma atribuição inicial mais precisa. A meta é manter a taxa de escalonamento abaixo de 201 TP3T, com o sistema ideal atingindo uma taxa de escalonamento de 101 TP3T ou menos.
Produtividade dos funcionários
Essa métrica mede o número de ordens de serviço que podem ser processadas com eficiência pela equipe de suporte após a implementação de uma solução de distribuição. O aprimoramento da distribuição deve resultar em aumento da produtividade. Medida pelo rastreamento do número de ordens de serviço resolvidas por funcionário por dia ou hora, a meta é aumentar a produtividade em 10-20% após a implementação de um novo sistema de distribuição.
Taxa de triagem por autoatendimento
Essa métrica mede a porcentagem de possíveis ordens de serviço resolvidas por meio de opções de autoatendimento antes de entrar no sistema de distribuição. Taxas de triagem mais altas indicam triagem pré-atribuição eficaz. A meta é atingir uma taxa de triagem de 20-301 TP3T, com as equipes de melhor desempenho atingindo 401 TP3T ou mais.
Custo por ordem de serviço
Essa métrica calcula o custo médio para resolver cada ordem de serviço de suporte. Uma distribuição eficiente deve ajudar a reduzir os custos ao longo do tempo. Embora os padrões de referência variem muito, muitas organizações têm como objetivo reduzir o custo por ordem de serviço em 10-151 TP3T após a implementação de um sistema de distribuição aprimorado.
Selecionando o modelo Claude correto
A escolha do modelo depende do equilíbrio entre custo, precisão e tempo de resposta.
Muitos clientes acham que claude-3-haiku-20240307 Ideal para lidar com o roteamento de ordens de serviço, pois é o modelo mais rápido e econômico da família Claude 3, sem deixar de oferecer excelentes resultados. Se o seu problema de classificação exigir conhecimento profundo ou muito raciocínio de categoria intencional complexo, você poderá escolher o modelo O modelo de soneto maior.
Criando uma dica poderosa
O roteamento de ordens de serviço é uma tarefa de classificação. O Claude analisa o conteúdo das ordens de serviço de suporte e as classifica em categorias predefinidas com base no tipo de problema, na urgência, na especialização necessária ou em outros fatores relevantes.
Vamos escrever um prompt para classificação de ordens de serviço. O prompt inicial deve conter o conteúdo da solicitação do usuário e retornar o processo de raciocínio e a intenção.
Você pode experimentar o Console antrópico carregamento Gerador de dicas Deixe o Claude escrever a primeira versão do prompt para você.
Abaixo está um exemplo de um prompt de classificação de roteamento de ordem de serviço:
def classify_support_request(ticket_contents):
# 为分类任务定义提示
classification_prompt = f"""你将作为客户支持工单分类系统。你的任务是分析客户支持请求,并输出每个请求的适当分类意图,同时给出你的推理过程。
这是你需要分类的客户支持请求:
<request>{ticket_contents}</request>
请仔细分析上述请求,以确定客户的核心意图和需求。考虑客户询问的内容和关注点。
首先,在 <reasoning> 标签内写出你对如何分类该请求的推理和分析。
然后,在 <intent> 标签内输出该请求的适当分类标签。有效的意图包括:
<intents>
<intent>支持、反馈、投诉</intent>
<intent>订单追踪</intent>
<intent>退款/换货</intent>
</intents>
一个请求只能有一个适用的意图。只包括最适合该请求的意图。
例如,考虑以下请求:
<request>您好!我在周六安装了高速光纤网络,安装人员 Kevin 的服务非常棒!我在哪里可以提交我的正面评价?谢谢您的帮助!</request>
这是你的输出应该如何格式化的示例(针对上述请求):
<reasoning>用户希望留下正面反馈。</reasoning>
<intent>支持、反馈、投诉</intent>
这里有几个更多的示例:
<examples>
<example 2>
示例 2 输入:
<request>我想写信感谢你们在上周末我父亲的葬礼上对我家人的关怀。你们的员工非常体贴和乐于助人,这让我们肩上的负担减轻了不少。悼念手册非常漂亮。我们永远不会忘记你们对我们的关爱,我们非常感激整个过程的顺利进行。再次感谢你们,Amarantha Hill 代表 Hill 家庭。</request>
示例 2 输出:
<reasoning>用户留下了他们对体验的正面评价。</reasoning>
<intent>支持、反馈、投诉</intent>
</example 2>
<example 3>
...
</example 8>
<example 9>
示例 9 输入:
<request>你们的网站一直弹出广告窗口,挡住了整个屏幕。我花了二十分钟才找到电话投诉的号码。我怎么可能在这些弹出窗口的干扰下访问我的账户信息?你能帮我访问我的账户吗,因为你们的网站有问题?我需要知道在档的地址。</request>
示例 9 输出:
<reasoning>用户请求帮助以访问其网络账户信息。</reasoning>
<intent>支持、反馈、投诉</intent>
</example 9>
请记住,始终在实际意图输出之前包括分类推理。推理应包含在 <reasoning> 标签内,意图应包含在 <intent> 标签内。仅返回推理和意图。
"""
Vamos detalhar as partes principais dessa dica:
- Usamos a string f do Python para criar modelos de dicas que permitem a inclusão de
ticket_contentsinserir em<request>Tagged in. - Definimos claramente uma função para o Claude como um sistema de classificação que analisa cuidadosamente o conteúdo das ordens de serviço para determinar a intenção principal e as necessidades do cliente.
- Instruímos o Claude sobre o formato de saída correto no
<reasoning>A inferência e a análise são fornecidas nas tags e, posteriormente, na<intent>Emita as tags de categoria apropriadas dentro das tags. - Designamos categorias de intenção válidas: "Suporte, feedback, reclamações", "Rastreamento de pedidos" e "Reembolsos/trocas".
- São fornecidos alguns exemplos (ou seja, dicas de poucos disparos) para ilustrar como o resultado deve ser formatado, o que pode ajudar a melhorar a precisão e a consistência.
Queremos que o Claude divida a resposta em seções separadas de tags XML para que possamos extrair o raciocínio e a intenção separadamente usando expressões regulares. Isso nos permite criar etapas subsequentes direcionadas no fluxo de trabalho de encaminhamento de ordens de serviço, por exemplo, usando apenas a intenção para decidir para quem encaminhar a ordem de serviço.
Como implementar suas palavras-chave
Se não for implantado em um ambiente de produção de teste e Avaliação operacionalSe você não tiver uma palavra-chave, é difícil saber a eficácia de suas palavras-chave.
Vamos criar a estrutura de implantação. Comece definindo uma assinatura de método que envolverá nossas chamadas para o Claude. Usaremos o método que já começamos a escrever, que começa com o ticket_contents como entrada, agora retorna reasoning responder cantando intent tuplas como saída. Se você já tiver um método automatizado usando o aprendizado de máquina tradicional, é recomendável seguir a assinatura desse método.
import anthropic
import re
# 创建一个 Anthropic API 客户端实例
client = anthropic.Anthropic()
# 设置默认模型
DEFAULT_MODEL="claude-3-haiku-20240307"
def classify_support_request(ticket_contents):
# 为分类任务定义提示词
classification_prompt = f"""你将作为客户支持工单的分类系统。
...
... 推理结果应包含在 <reasoning> 标签中,意图应包含在 <intent> 标签中。仅返回推理和意图。
"""
# 将提示词发送到 API 以对支持请求进行分类
message = client.messages.create(
model=DEFAULT_MODEL,
max_tokens=500,
temperature=0,
messages=[{"role": "user", "content": classification_prompt}],
stream=False,
)
reasoning_and_intent = message.content[0].text
# 使用 Python 的正则表达式库提取 `reasoning`
reasoning_match = re.search(
r"<reasoning>(.*?)</reasoning>", reasoning_and_intent, re.DOTALL
)
reasoning = reasoning_match.group(1).strip() if reasoning_match else ""
# 同样提取 `intent`
intent_match = re.search(r"<intent>(.*?)</intent>", reasoning_and_intent, re.DOTALL)
intent = intent_match.group(1).strip() if intent_match else ""
return reasoning, intent
Este código:
- Importou a biblioteca Anthropic e criou uma instância de cliente usando sua chave de API.
- Define um
classify_support_requestque recebe uma funçãoticket_contentsCordas. - fazer uso de
classification_promptcomandante-em-chefe (militar)ticket_contentsEnvie-o para Claude para classificação. - Retorna o modelo extraído da resposta do
reasoningresponder cantandointent.
Como precisamos aguardar a inferência completa e a geração do texto de intenção antes da análise, vamos stream=False Defina o valor padrão.
Avalie suas dicas
O uso de palavras-chave geralmente requer testes e otimização para atingir o status de pronto para produção. Para determinar se sua solução está pronta, avalie seu desempenho com base em critérios e limites de sucesso previamente definidos.
Para executar uma avaliação, você precisa ter casos de teste para executar a avaliação. Este artigo pressupõe que você tenhaDesenvolveu seus casos de teste.
Construção da função de avaliação
Os exemplos de avaliações deste guia medem o desempenho do Claude por meio de três métricas principais:
- precisão
- Custo por classificação
Dependendo do que é importante para você, pode ser necessário avaliar a Claude em outras dimensões.
Para realizar a avaliação, primeiro precisamos modificar o script anterior adicionando uma função que compare a intenção prevista com a intenção real e calcule a porcentagem de previsões corretas. Também precisamos adicionar funções de medição de custo e tempo.
import anthropic
import re
# 创建 Anthropic API 客户端的实例
client = anthropic.Anthropic()
# 设置默认模型
DEFAULT_MODEL="claude-3-haiku-20240307"
def classify_support_request(request, actual_intent):
# 定义分类任务的提示
classification_prompt = f"""You will be acting as a customer support ticket classification system.
...
...The reasoning should be enclosed in <reasoning> tags and the intent in <intent> tags. Return only the reasoning and the intent.
"""
message = client.messages.create(
model=DEFAULT_MODEL,
max_tokens=500,
temperature=0,
messages=[{"role": "user", "content": classification_prompt}],
)
usage = message.usage # 获取 API 调用的使用统计信息,包括输入和输出 Token 数量。
reasoning_and_intent = message.content[0].text
# 使用 Python 的正则表达式库提取 `reasoning`。
reasoning_match = re.search(
r"<reasoning>(.*?)</reasoning>", reasoning_and_intent, re.DOTALL
)
reasoning = reasoning_match.group(1).strip() if reasoning_match else ""
# 同样,提取 `intent`。
intent_match = re.search(r"<intent>(.*?)</intent>", reasoning_and_intent, re.DOTALL)
intent = intent_match.group(1).strip() if intent_match else ""
# 检查模型的预测是否正确。
correct = actual_intent.strip() == intent.strip()
# 返回推理结果、意图、正确性和使用情况。
return reasoning, intent, correct, usage
As alterações que fizemos no código são as seguintes:
- nós iremos
actual_intentAdicionar do caso de teste aoclassify_support_requestA metodologia de Claude e um mecanismo de comparação foram estabelecidos para avaliar se a categorização de intenção de Claude era consistente com nossa categorização de intenção dourada. - Extraímos estatísticas de uso de chamadas de API para calcular os custos com base no uso de tokens de entrada e saída.
Faça sua avaliação
Uma avaliação bem desenvolvida requer limites e benchmarks claros para determinar o que constitui um bom resultado. O script acima nos fornecerá valores de tempo de execução para precisão, tempo de resposta e custo por classificação, mas ainda precisamos de limites claramente definidos. Exemplo:
- Precisão: 95% (100 testes)
- Custo por classificação: Redução média de 50% (100 testes) em comparação com os métodos de roteamento atuais
A definição desses limites permite que você avalie de forma rápida e fácil, em escala, qual abordagem é a melhor para você e, com dados empíricos imparciais, deixe claro quais melhorias precisam ser feitas para atender melhor às suas necessidades.
melhorar o desempenho
Em cenários complexos, considere ir além do padrão técnicas de engenharia imediata responder cantando estratégias de implementação de grades de proteção estratégias adicionais podem ser úteis. Aqui estão alguns cenários comuns:
No caso de mais de 20 categorias de intenção, use a hierarquia de classificação
À medida que o número de categorias aumenta, o mesmo acontece com o número de exemplos necessários, o que pode tornar o prompt pesado. Como alternativa, você pode considerar a implementação de um sistema de classificação hierárquica usando classificadores híbridos.
- Organize suas intenções em uma estrutura de árvore de classificação.
- Crie uma série de classificadores em cada nível da árvore, ativando o método de roteamento em cascata.
Por exemplo, você pode ter um classificador de nível superior que categoriza amplamente as ordens de serviço em "Problemas técnicos", "Problemas de faturamento" e "Consultas gerais". Cada uma dessas categorias pode ter seu próprio subclassificador para refinar ainda mais a classificação.

- Benefícios - Maior nuance e precisão: Você pode criar prompts diferentes para cada caminho principal, permitindo uma categorização mais direcionada e específica do contexto. Isso melhora a precisão e permite um tratamento mais granular das solicitações dos clientes.
- Desvantagens - Aumento da latência: Observe que vários classificadores podem resultar em maior latência, portanto, recomendamos implementar esse método ao usar nosso modelo mais rápido, o Haiku.
Uso de bancos de dados vetoriais e recuperação de pesquisa por similaridade para lidar com ordens de serviço altamente variáveis
Embora fornecer exemplos seja a maneira mais eficaz de melhorar o desempenho, pode ser difícil incluir exemplos suficientes em um único prompt se as solicitações de suporte forem muito variáveis.
Nesse caso, você pode usar o banco de dados vetorial para realizar uma pesquisa de similaridade no conjunto de dados de exemplo e recuperar os exemplos mais relevantes para uma determinada consulta.
Essa metodologia é usada em nossos receita de classificação que é descrita em detalhes, demonstrou melhorar o desempenho da precisão de 71% para 93%.
Consideração especial de casos extremos previstos
Aqui estão alguns cenários em que Claude pode classificar erroneamente uma ordem de serviço (pode haver outras situações que sejam exclusivas de sua situação). Nesses cenários, considere fornecer instruções ou exemplos claros nos prompts de como Claude deve lidar com casos extremos:
Os clientes fazem solicitações implícitas
Os clientes geralmente expressam suas necessidades de forma indireta. Por exemplo, "Estou esperando minha encomenda há mais de duas semanas" pode ser uma solicitação indireta de status do pedido.
- Solução: Forneça ao Claude alguns exemplos de clientes reais desse tipo de solicitação e sua intenção subjacente. Se você incluir uma lógica de categorização com nuances específicas para a intenção da ordem de serviço, poderá obter melhores resultados para que o Claude possa generalizar a lógica para outras ordens de serviço.
Claude prioriza a emoção em detrimento da intenção
Quando um cliente expressa insatisfação, Claude pode priorizar lidar com a emoção em vez de resolver o problema subjacente.
- Solução: Forneça ao Claude uma indicação de quando priorizar o sentimento do cliente. Isso poderia ser algo simples como "Ignore todos os sentimentos do cliente. Concentre-se apenas em analisar a intenção da solicitação do cliente e as informações que ele pode estar pedindo."
Vários problemas geram confusão na priorização de problemas
A Claude pode ter dificuldade para identificar as principais preocupações quando um cliente faz várias perguntas em uma única interação.
- Solução: Esclarecer a priorização das intenções para que o Claude possa priorizar melhor as intenções extraídas e identificar as principais preocupações.
Integração do Claude em seu fluxo de trabalho de suporte mais amplo
A integração adequada exige que você tome algumas decisões sobre como os scripts de roteamento de ordens de serviço baseados no Claude se encaixam na arquitetura mais ampla do sistema de roteamento de ordens de serviço. Você pode fazer isso de duas maneiras:
- Baseado em push: O sistema de ordens de serviço de suporte que você usa (por exemplo, Zendesk) aciona seu código enviando um evento webhook para o serviço de roteamento, que classifica e encaminha a intenção.
- Essa abordagem é mais dimensionável em termos de rede, mas exige que você exponha um endpoint.
- Baseado em pull: Seu código extrai a ordem de serviço mais recente com base na programação fornecida e a encaminha à medida que é extraída.
- Essa abordagem é mais fácil de implementar, mas pode fazer chamadas desnecessárias para o sistema de ordens de serviço de suporte se for acionada com muita frequência, ou pode ser muito lenta se for acionada com pouca frequência.
Para ambos os métodos, é necessário envolver os scripts em um serviço. O método escolhido depende de quais APIs o sistema de ordens de serviço de suporte fornece.
© declaração de direitos autorais
Direitos autorais do artigo Círculo de compartilhamento de IA A todos, favor não reproduzir sem permissão.
Artigos relacionados


Nenhum comentário...