
Tandem langchain abre palavras-chave de pesquisa profunda

Para unir o processo de execução do projeto e traduzir as instruções da palavra-chave, precisamos basear nosso projeto noprompts.pypara descrever em detalhes o fluxo de execução de cada etapa e suas instruções de palavras-chave correspondentes.
Processo de execução do projeto e instruções de palavras-chave correspondentes
1. gerar consultas de pesquisa para ajudar a planejar relatórios
- Prompt:
report_planner_query_writer_instructions = """ 你是一名专家技术写手,正在帮助计划一份报告。 <报告主题> {topic} </报告主题> <报告组织> {report_organization} </报告组织> <任务> 你的目标是生成 {number_of_queries} 个搜索查询,以帮助收集全面的信息来规划报告部分。 这些查询应当: 1. 与报告主题相关 2. 帮助满足报告组织中规定的要求 使查询足够具体,以找到高质量、相关的资源,同时覆盖报告结构所需的广度。 </任务> """
2. plano para geração de relatórios
- Prompt:
report_planner_instructions = """ 我需要一个报告计划。 <任务> 生成一个报告部分的列表。 每个部分应当包含以下字段: - 名称 - 报告部分的名称。 - 描述 - 本部分涵盖的主要主题的简要概述。 - 研究 - 是否需要为本部分报告进行网络研究。 - 内容 - 本部分的内容,现在可以留空。 例如,介绍和结论将不需要研究,因为它们将从报告的其他部分提炼信息。 </任务> <主题> 报告的主题是: {topic} </主题> <报告组织> 报告应遵循此组织: {report_organization} </报告组织> <上下文> 以下是用于规划报告部分的上下文: {context} </上下文> <反馈> 以下是对报告结构的审查反馈(如果有): {feedback} </反馈> """
3. preparação de consultas de pesquisa
- Prompt:
query_writer_instructions = """ 你是一名专家技术写手,正在编写有针对性的网络搜索查询,以收集撰写技术报告部分的全面信息。 <部分主题> {section_topic} </部分主题> <任务> 你的目标是生成 {number_of_queries} 个搜索查询,以帮助收集有关本部分主题的全面信息。 这些查询应当: 1. 与主题相关 2. 检查该主题的不同方面 使查询足够具体,以找到高质量、相关的资源。 </任务> """
4. componente de elaboração de relatórios
- Prompt:
section_writer_instructions = """ 你是一名专家技术写手,正在撰写技术报告的一个部分。 <部分主题> {section_topic} </部分主题> <现有部分内容(如果已填写)> {section_content} </现有部分内容> <源材料> {context} </源材料> <撰写指南> 1. 如果现有部分内容未填写,则从头撰写新的部分。 2. 如果现有部分内容已填写,请撰写一个新的部分,将现有内容与新信息综合起来。 <长度和风格> - 严格限制在150-200字 - 不使用营销语言 - 技术重点 - 使用简单、清晰的语言 - 用**加粗**的最重要的见解开头 - 使用简短的段落(每段最多2-3句话) - 使用 ## 作为部分标题(Markdown格式) - 仅在有助于澄清观点时使用一个结构元素: * 要么是比较2-3个关键项目的集中表格(使用Markdown表格语法) * 要么是使用正确的Markdown列表语法的简短列表(3-5项): - 使用 `*` 或 `-` 表示无序列表 - 使用 `1.` 表示有序列表 - 确保正确的缩进和间距 - 以参考以下源材料的###来源结束: * 列出每个来源的标题、日期和URL * 格式:`- 标题 : URL` </长度和风格> <质量检查> - 恰好150-200字(不包括标题和来源) - 仔细使用一个结构元素(表格或列表),仅在有助于澄清观点时 - 一个具体的例子/案例研究 - 以加粗见解开头 - 在创建部分内容之前不作任何序言 - 在结尾引用来源 </质量检查> """
5. avaliação do componente de relatório
- Prompt:
section_grader_instructions = """ 审核相对于指定主题的报告部分: <部分主题> {section_topic} </部分主题> <部分内容> {section} </部分内容> <任务> 评估该部分是否通过检查技术准确性和深度,充分涵盖了主题。 如果该部分未满足任何标准,请生成具体的后续搜索查询以收集缺失的信息。 </任务> <格式> grade: Literal["pass","fail"] = Field( description="评估结果,指示响应是否符合要求('通过')或需要修订('失败')。" ) follow_up_queries: List[SearchQuery] = Field( description="后续搜索查询列表。", ) </格式> """
6. escrever a seção do relatório final
- Prompt:
final_section_writer_instructions = """ 你是一名专家技术写手,正在撰写综合报告其他部分信息的部分。 <部分主题> {section_topic} </部分主题> <可用报告内容> {context} </可用报告内容> <任务> 1. 部分特定方法: 对于介绍: - 使用 # 作为报告标题(Markdown格式) - 50-100字限制 - 使用简单和清晰的语言 - 重点介绍报告的核心动机,1-2段 - 使用清晰的叙述弧线介绍报告 - 不使用任何结构元素(无列表或表格) - 不需要来源部分 对于结论/总结: - 使用 ## 作为部分标题(Markdown格式) - 100-150字限制 - 对于比较报告: * 必须包含使用Markdown表格语法的集中比较表 * 表格应提炼报告中的见解 * 保持表格条目清晰简洁 - 对于非比较报告: * 仅在有助于提炼报告中的要点时使用一个结构元素: * 要么是比较报告中项目的集中表格(使用Markdown表格语法) * 要么是使用正确的Markdown列表语法的简短列表: - 使用 `*` 或 `-` 表示无序列表 - 使用 `1.` 表示有序列表 - 确保正确的缩进和间距 - 以具体的下一步或影响结束 - 不需要来源部分 3. 撰写方法: - 使用具体细节而非一般陈述 - 每个字都要有意义 - 重点突出最重要的一点 </任务> <质量检查> - 对于介绍:50-100字限制,# 作为报告标题,无结构元素,无来源部分 - 对于结论:100-150字限制,## 作为部分标题,仅使用一个结构元素,无来源部分 - Markdown格式 - 不在响应中包含字数或任何序言 </质量检查> """
Processo de execução em tandem
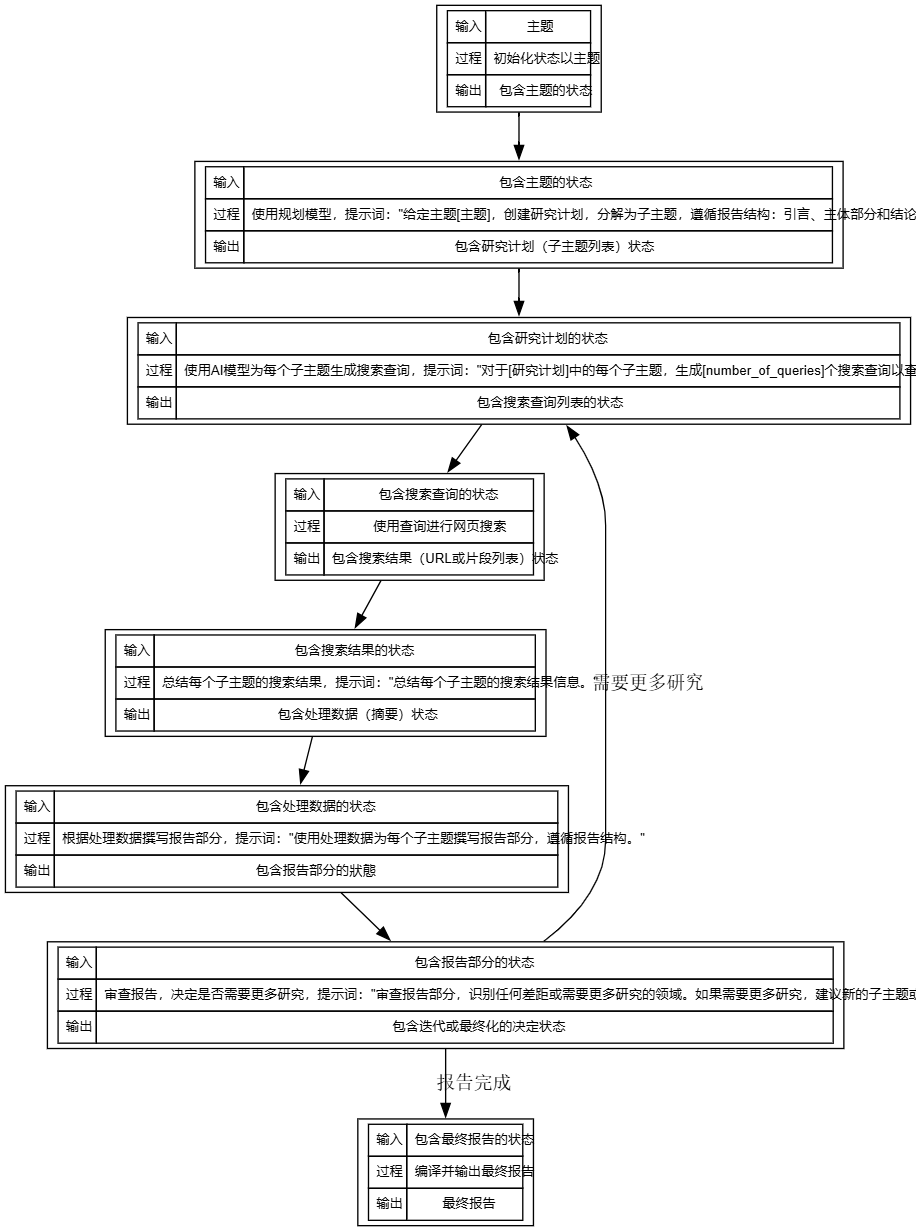
1. inicialização (Start)
- importação Tópicos fornecidos pelo usuário, como "Overview of the AI Reasoning market with a focus on Fireworks, Together.ai, Groq" (Visão geral do mercado de raciocínio de IA com foco em Fireworks, Together.ai, Groq).
- curso dos acontecimentos O sistema inicializa o estado e armazena o tópico como parte do estado sem chamadas de modelo de IA.
- exportações Status do tópico: contém o status do tópico para uso nas etapas subsequentes.
2. planejamento
- importação Status do tópico: Contém o status do tópico.
- curso dos acontecimentos Gerar um plano de pesquisa usando um modelo de planejamento, como o padrão OpenAI o3-mini ou o deepseek-r1-distill-llama-70b do Groq. A palavra-chave é: "Dado um tópico [tema], crie um plano de pesquisa, dividido em subtópicos, que siga a estrutura do relatório: introdução, seção principal do corpo e conclusão."
- exportações Status: atualizado para incluir programas de pesquisa (lista de subtópicos), por exemplo, "1. definição do mercado de inferência de IA; 2. papel dos fogos de artifício; 3. JuntosUm estudo de caso do .ai", entre outros.
- Fonte de palavras-chave Estrutura do relatório: Presumivelmente a partir da DEFAULT_REPORT_STRUCTURE do configuration.py, a estrutura consiste em uma introdução, uma seção do corpo principal e uma conclusão, sendo que a seção do corpo principal precisa abranger os principais conceitos, definições e exemplos.
3. geração de consultas
- importação Status do programa de pesquisa: Contém o status do programa de pesquisa.
- curso dos acontecimentos Use o modelo de IA para gerar uma consulta de pesquisa para cada subtópico com a seguinte frase: "Para cada subtópico em [plano de pesquisa], gere [número_de_consultas] consultas de pesquisa para encontrar informações relevantes." O número_de_consultas padrão é 2.
- exportações Status atualizado para incluir a lista de consultas de pesquisa, como "AI Reasoning Market Definition 2023", "Fireworks AI Service Case", etc.
- Fonte de palavras-chave Na documentação do projeto, é mencionado que o número de consultas pode ser configurado, supondo que a palavra de prompt seja uma forma genérica da consulta gerada.
4. pesquisa na Web
- importação Status da consulta de pesquisa: Contém o status da consulta de pesquisa.
- curso dos acontecimentos Execute cada consulta usando a API de pesquisa (por exemplo, Tavily padrão) para obter resultados de pesquisa na Web. Nenhuma chamada de modelo de IA, executada diretamente pela ferramenta.
- exportações Status: O status é atualizado para incluir resultados de pesquisa (URLs ou listas de snippets), como um resumo das páginas retornadas pela Tavily.
- Detalhes técnicos Dependência de tavily-python >= 0.5.0, necessidade de configurar TAVILY_API_KEY.
5 Processamento de dados
- importação Status da pesquisa: Contém o status dos resultados da pesquisa.
- curso dos acontecimentos Use o modelo de IA para resumir os resultados da pesquisa para cada subtópico com a frase de solicitação: "Summarize the search result information for each sub-topic."
- exportações Status atualizado para incluir dados de processamento (resumo), por exemplo, "Definição do mercado de inferência de IA: refere-se ao setor que usa modelos de IA para previsão em tempo real e está crescendo rapidamente até 2023".
- Fonte de palavras-chave Pressupostos para prompts genéricos para tarefas de resumo, com base nos objetivos do projeto para gerar relatórios.
6) Elaboração de relatórios
- importação Status dos dados processados: Contém o status dos dados processados.
- curso dos acontecimentos Use um modelo de escrita (por exemplo, padrão antrópico). Claude 3.5 Soneto) Escreva uma seção de relatório com base em dados processados com as seguintes palavras: "Use dados processados para escrever uma seção de relatório para cada subtema, seguindo a estrutura do relatório."
- exportações Status atualizado para incluir uma seção de relatório, por exemplo, "Introdução: o mercado de raciocínio de IA é uma área importante para a adoção de IA; Seção 1 do corpo principal: o Fireworks fornece serviços de raciocínio eficientes, com casos que incluem implantações em nuvem".
- Fonte de palavras-chave Em conjunto com DEFAULT_REPORT_STRUCTURE, o relatório precisa incluir uma visão geral, conceitos-chave e exemplos.
7. reflexão
- importação Status da seção do relatório: Contém o status da seção do relatório.
- curso dos acontecimentos Use o modelo de IA para revisar o relatório e determinar se mais pesquisas são necessárias, com as seguintes palavras: "Revise a seção do relatório e identifique quaisquer lacunas ou áreas em que mais pesquisas são necessárias. Se for necessária mais pesquisa, sugira novos subtópicos ou consultas."
- exportações Status atualizado para incluir a decisão de iteração (por exemplo, mais pesquisas necessárias) ou o relatório final. Se a iteração for necessária, produza novos subtópicos ou sugestões de consulta.
- Fonte de palavras-chave Observação: mencionar na documentação do projeto que a reflexão e a iteração são apoiadas, presumindo que a palavra-chave seja uma forma genérica de revisão e recomendação.
8. saída
- importação Status do relatório final: Contém o status do relatório final (quando o Reflection decide que o relatório está completo).
- curso dos acontecimentos Compilar todas as seções do relatório para gerar o relatório final no formato Markdown sem chamadas de modelo de IA.
- exportações Relatório final, por exemplo, documento Markdown completo para os usuários baixarem ou visualizarem.
© declaração de direitos autorais
Direitos autorais do artigo Círculo de compartilhamento de IA A todos, favor não reproduzir sem permissão.
Artigos relacionados




Nenhum comentário...