Guia para evitar as armadilhas: Pacote de instalação do Taobao DeepSeek R1 com upsell pago? Ensine a você a implantação local gratuitamente (com o instalador de um clique)

Recentemente, na plataforma Taobao DeepSeek O fenômeno da venda de pacotes de instalação despertou uma preocupação generalizada. É surpreendente que algumas empresas estejam lucrando com esse modelo de IA gratuito e de código aberto. Isso também é um reflexo do boom de implantação local que os modelos do DeepSeek estão gerando.

Ao procurar por "DeepSeek" em plataformas de comércio eletrônico como Taobao e Jinduoduo, você pode encontrar muitos comerciantes vendendo recursos que poderiam ter sido obtidos gratuitamente, incluindo pacotes de instalação, pacotes de palavras-chave, tutoriais, etc. Até mesmo alguns vendedores marcaram tutoriais relacionados ao DeepSeek para venda. Alguns vendedores até mesmo vendem tutoriais relacionados ao DeepSeek a um preço marcado, mas, na realidade, os usuários podem encontrar facilmente um grande número de links para download gratuito simplesmente usando um mecanismo de busca.
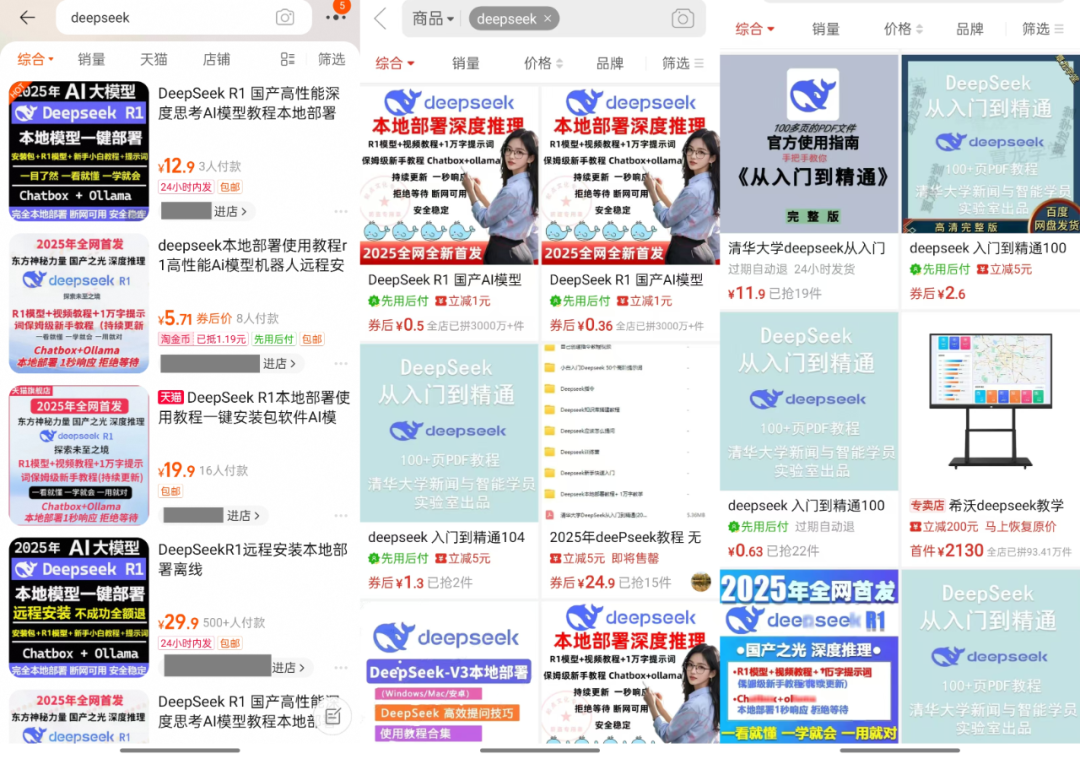
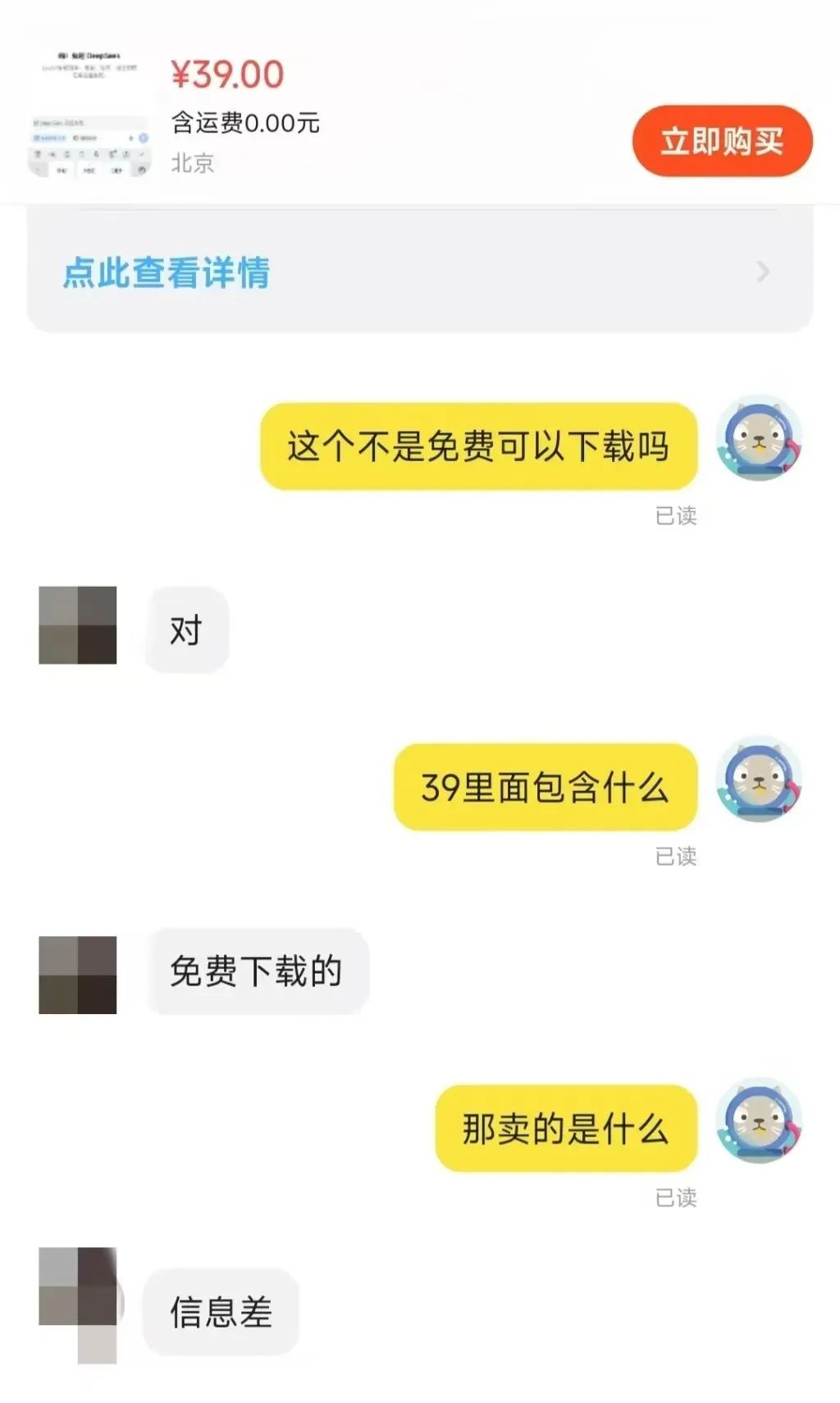
Então, por quanto esses recursos são vendidos? Foi observado que o preço do pacote "instalador + tutoriais + dicas" geralmente varia de US$ 10 a US$ 30, e a maioria dos comerciantes também oferece um certo grau de suporte de atendimento ao cliente. Entre eles, muitos dos produtos foram vendidos centenas de cópias, alguns produtos populares e até mesmo mil pessoas para pagar a escala. O mais surpreendente é que os pacotes de software e tutoriais custaram US$ 100, mas 22 pessoas também optaram por comprar.

As oportunidades de negócios apresentadas pela lacuna de informações são, portanto, evidentes.
Neste artigo, orientaremos o leitor sobre como implementar os modelos do DeepSeek localmente, sem nenhum custo. Antes disso, analisaremos brevemente a necessidade da implementação local.
Por que optar por implantar o DeepSeek-R1 localmente?
DeepSeek-R1 embora possam não ser os modelos de inferência de melhor desempenho disponíveis atualmente, são certamente uma opção muito procurada no mercado. No entanto, ao usar diretamente os serviços de plataformas de hospedagem oficiais ou de terceiros, os usuários frequentemente sofrem com o congestionamento do servidor.
Um modelo de implementação local pode contornar esse problema de forma eficaz. Em resumo, a implementação local significa instalar modelos de IA nos próprios dispositivos dos usuários, em vez de depender de APIs de nuvem ou serviços on-line. Os métodos comuns de implantação local incluem os seguintes:
- Raciocínio local leveLlama.cpp, Whisper, modelos de formato GGUF: Executa em um PC ou dispositivo móvel, por exemplo, modelos de formato Llama.cpp, Whisper, GGUF.
- Implementação de servidor/estação de trabalhoExecute modelos grandes com GPUs ou TPUs de alto desempenho, como a NVIDIA RTX 4090, A100, etc.
- Servidores de nuvem privada/intranetImplementação em servidores locais, por exemplo, usando ferramentas como TensorRT, ONNX Runtime, vLLM.
- Implantação de dispositivos de bordaExecute modelos de IA em sistemas incorporados ou dispositivos de IoT, como o Jetson Nano, Raspberry Pi, etc.
Diferentes métodos de implementação são adequados para diferentes cenários de aplicativos. As tecnologias de implementação local mostraram seu valor exclusivo em várias áreas, por exemplo:
- Aplicativos de IA no localCriação de chatbots privados, sistemas de análise de documentos, etc.
- cálculos de pesquisa científicaAplicações em análise de dados e treinamento de modelos em biomedicina, simulação física e outros campos.
- Recursos de IA off-lineReconhecimento de fala: fornece recursos de reconhecimento de fala, OCR e processamento de imagens em um ambiente sem rede.
- Auditoria e monitoramento de segurançaPara auxiliar nas análises de conformidade em setores jurídicos, financeiros e outros.
Neste artigo, vamos nos concentrar na inferência local leve, que é a opção de implantação mais relevante para uma ampla gama de usuários individuais.
Vantagens da implantação local
Além de resolver a causa principal do problema do "servidor ocupado", a implementação local oferece várias vantagens:
- Privacidade e segurança de dadosImplementação de modelos de IA localmente elimina a necessidade de carregar dados confidenciais na nuvem, evitando efetivamente o risco de vazamento de dados. Isso é fundamental para setores como o financeiro, o de saúde e o jurídico, que exigem altos níveis de segurança de dados. Além disso, a implementação local também ajuda as empresas ou organizações a atender aos requisitos de conformidade de dados, como a Lei de Segurança de Dados da China e o GDPR da UE.
- Baixa latência e desempenho em tempo realComo todos os cálculos são realizados localmente sem solicitações de rede, a velocidade de inferência depende inteiramente do desempenho computacional do dispositivo local. Portanto, desde que o desempenho do dispositivo seja suficiente, os usuários podem obter uma excelente resposta em tempo real, o que torna a implantação local ideal para cenários de aplicativos exigentes em tempo real, como reconhecimento de fala, direção automatizada e inspeção industrial.
- Custo-benefício de longo prazoA implantação nativa elimina a necessidade de taxas de assinatura de API, permitindo o uso de longo prazo em uma única implantação. Para aplicativos com requisitos de baixo desempenho, os custos de hardware também podem ser reduzidos com a implantação de modelos leves, como os modelos quantised INT de 8 ou 4 bits.
- Disponibilidade off-lineOs modelos de IA podem ser usados mesmo quando não há conexão de rede, o que é adequado para computação de ponta, escritório off-line, ambiente remoto e outros cenários. A capacidade de execução off-line também garante a continuidade de serviços essenciais e evita interrupções nos negócios devido à desconexão da rede.
- Altamente personalizável e controlávelImplementação local: a implementação local permite que os usuários ajustem e otimizem o modelo para melhor atender às necessidades comerciais específicas. Por exemplo, o modelo DeepSeek-R1 gerou várias versões ajustadas e destiladas, incluindo a versão irrestrita deepseek-r1-abliterated. Além disso, as implementações locais não estão sujeitas a alterações de políticas de terceiros, proporcionando maior controle e evitando riscos potenciais, como ajustes de preços de API ou restrições de acesso.
Limitações da implementação local
As vantagens da implantação local são significativas, mas as limitações não são desprezíveis, principalmente a capacidade de computação necessária para modelos de grande escala.
- Entradas de custo de hardwareO que acontece é que os usuários individuais geralmente têm dificuldade para executar modelos com parâmetros grandes em seus equipamentos locais, enquanto os modelos com parâmetros menores podem ter o desempenho comprometido. Portanto, os usuários precisam fazer um balanço entre o custo do hardware e o desempenho do modelo. A busca por modelos de alto desempenho inevitavelmente exigirá investimentos adicionais em hardware.
- Capacidade de processamento de tarefas em grande escalaQuando se depara com tarefas que exigem processamento de dados em larga escala, o suporte de hardware em nível de servidor geralmente é necessário para concluí-las com eficiência. Os dispositivos pessoais têm um gargalo natural na capacidade de processamento.
- limiar tecnológicoEm comparação com a conveniência dos serviços em nuvem, que podem ser usados simplesmente visitando uma página da Web ou configurando uma API, há uma barreira técnica para a implementação local. Se os usuários precisarem ajustar ainda mais seus modelos, a implementação será ainda mais difícil. Felizmente, as barreiras técnicas à implementação local estão sendo gradualmente reduzidas.
- custo de manutençãoAtualização e iterações do modelo e das ferramentas associadas podem causar problemas com a configuração do ambiente, exigindo que o usuário invista tempo e esforço em manutenção e solução de problemas.
Portanto, a escolha da implantação local ou do modelo on-line precisa ser considerada de acordo com a situação real do usuário. A seguir, um breve resumo dos cenários em que a implantação local é ou não aplicável:
- Cenários adequados para implantação localRequisitos de alta privacidade, requisitos de baixa latência, uso a longo prazo (por exemplo, assistentes de IA corporativos, sistemas de análise jurídica etc.).
- Cenários não adequados para implantação localValidação de teste de curto prazo, altos requisitos aritméticos, dependência de modelos muito grandes (por exemplo, nível de parâmetro 70B+).
A implementação privada usando servidores gratuitos na nuvem também é uma boa opção, recomendada há muito tempo, mas requer uma certa base técnica:Implementando o modelo de código aberto DeepSeek-R1 on-line com potência de GPU gratuita
Implantação local do DeepSeek-R1 em ação
Há muitas maneiras de implantar o DeepSeek-R1 localmente, mas neste artigo apresentaremos duas opções simples: com base no Ollama métodos de implantação e cenários de implantação de código zero usando o LM Studio.
Opção 1: Implementação baseada em Ollama do DeepSeek-R1
O Ollama é a estrutura dominante para implementar e executar modelos de linguagem nativa. É leve e altamente dimensionável, e ganhou destaque desde o lançamento da família de modelos Llama do Meta. Apesar de seu nome, o projeto Ollama é orientado pela comunidade e não está diretamente relacionado ao desenvolvimento do Meta e da família de modelos Llama.

O projeto Ollama está crescendo rapidamente, e a variedade de modelos e ecossistemas que ele suporta está se expandindo rapidamente.
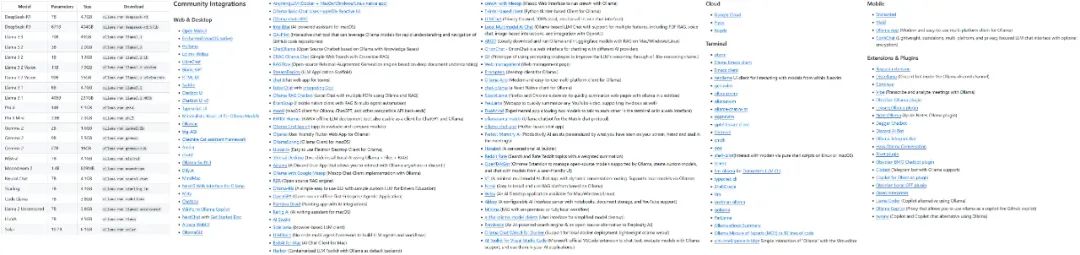
Alguns dos modelos e ecologias apoiados pela Ollama
O primeiro passo para usar o Ollama é fazer o download e instalar o software Ollama. Visite a página oficial de download do Ollama e selecione a versão que corresponde ao seu sistema operacional.
Download: https://ollama.com/download
Depois de instalar o Ollama, você precisa configurar o modelo de IA para o dispositivo. Vamos usar o DeepSeek-R1 como exemplo. Visite a biblioteca de modelos no site do Ollama para navegar pelos modelos e versões compatíveis:
https://ollama.com/search
O DeepSeek-R1 está disponível em 29 versões diferentes da biblioteca de modelos Ollama em escalas que variam de 1,5B a 67B, incluindo versões ajustadas, destiladas ou quantificadas com base nos modelos de código aberto Llama e Qwen.
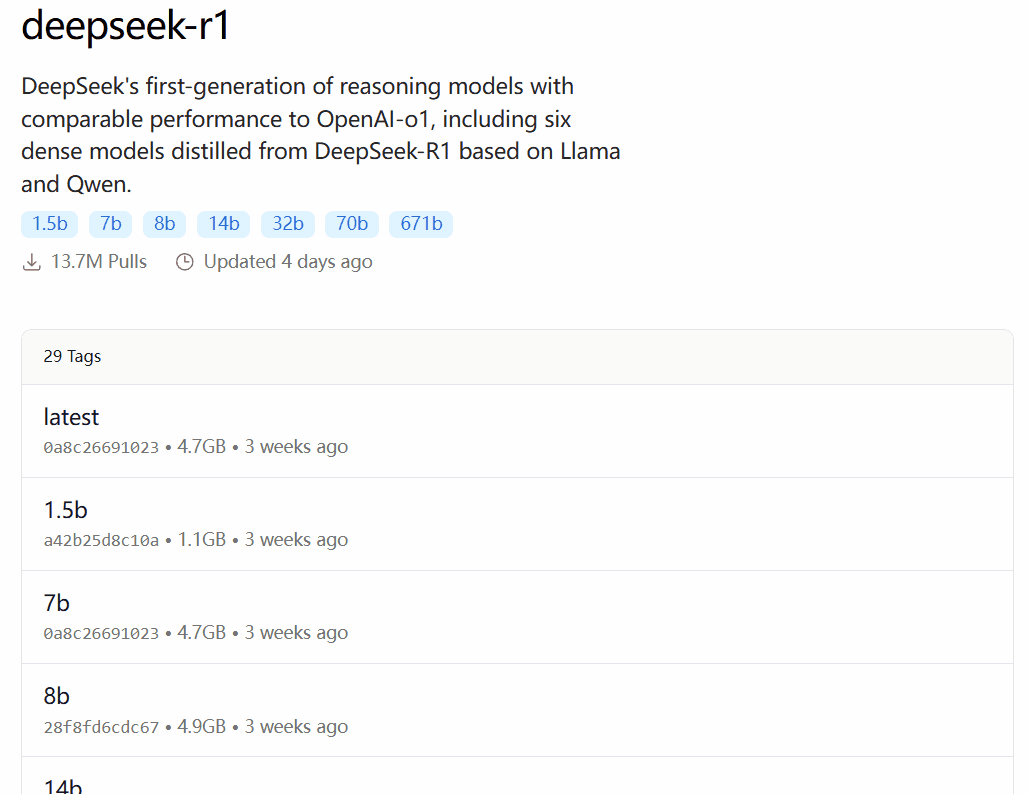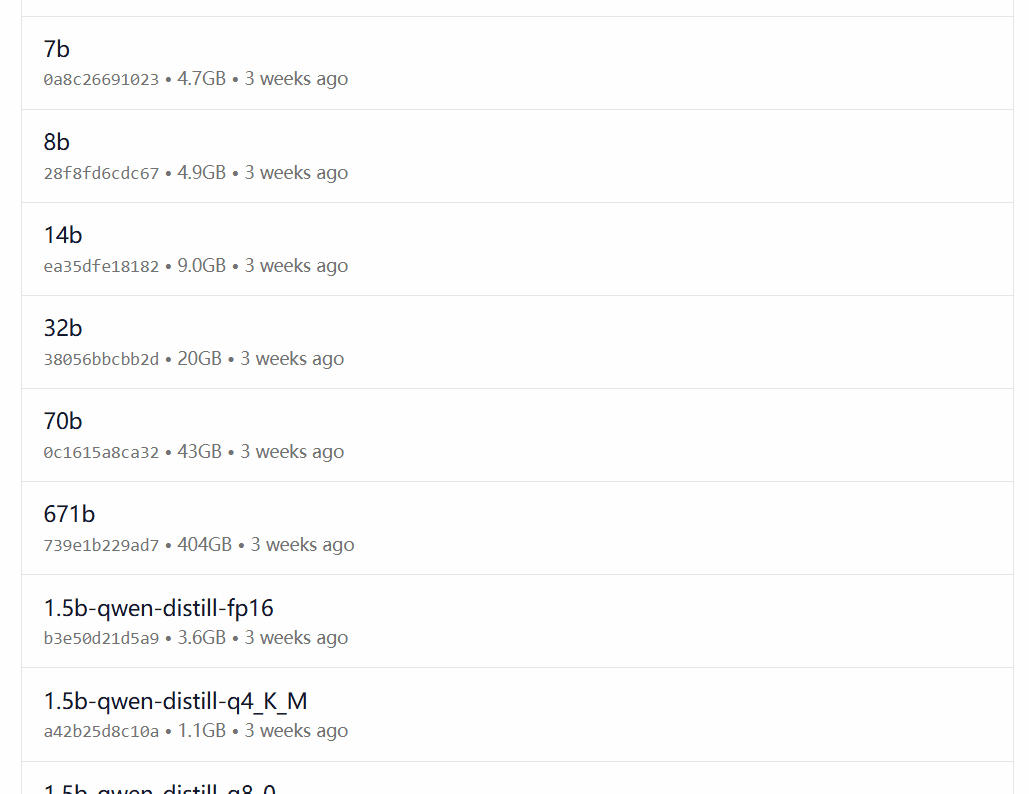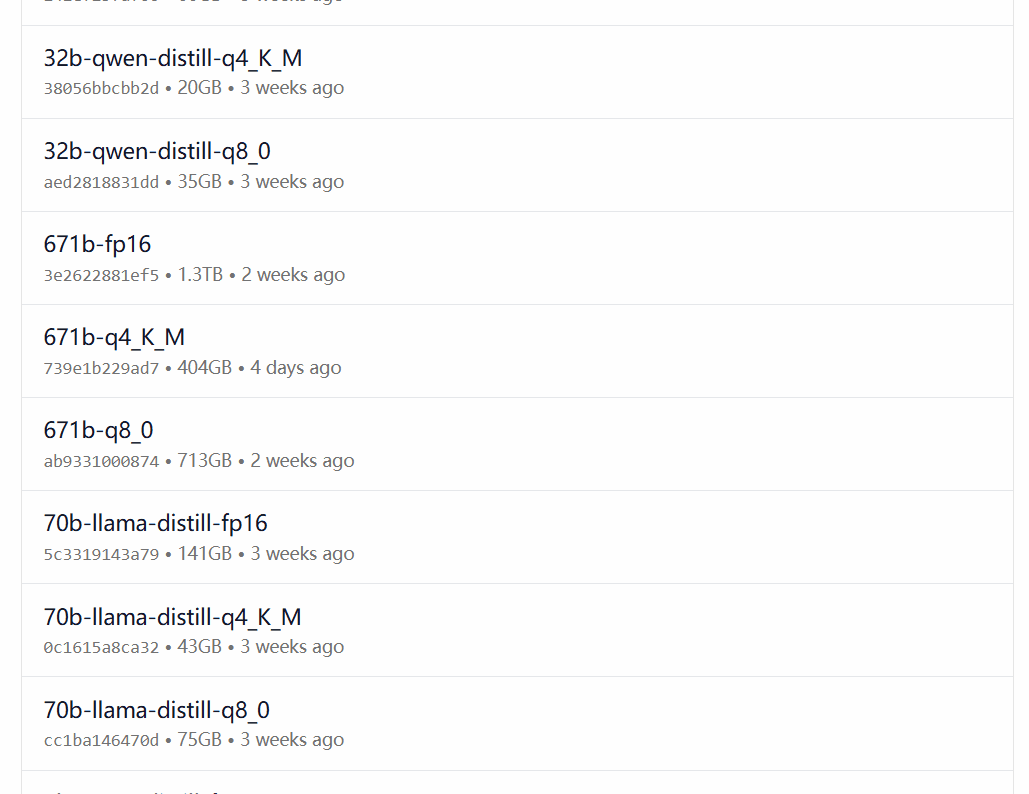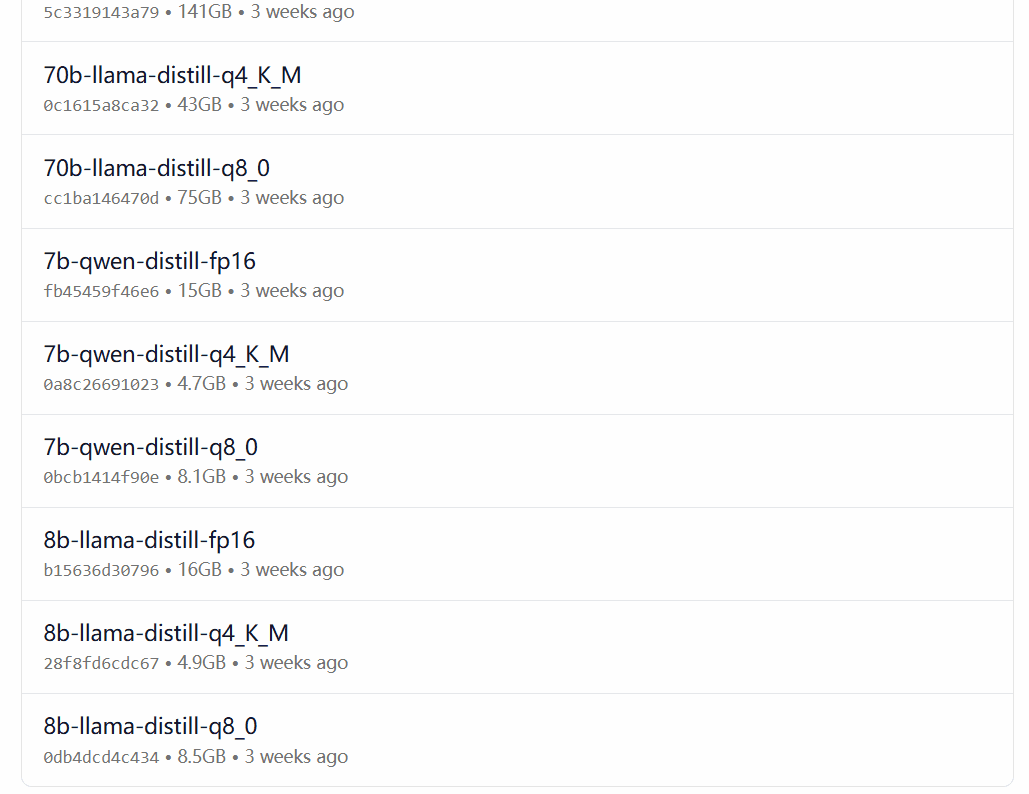
A versão a ser escolhida depende da configuração de hardware do usuário. Avnish, da comunidade de desenvolvedores dev.to, escreveu um artigo que resume os requisitos de hardware para as versões de diferentes tamanhos do DeepSeek-R1:
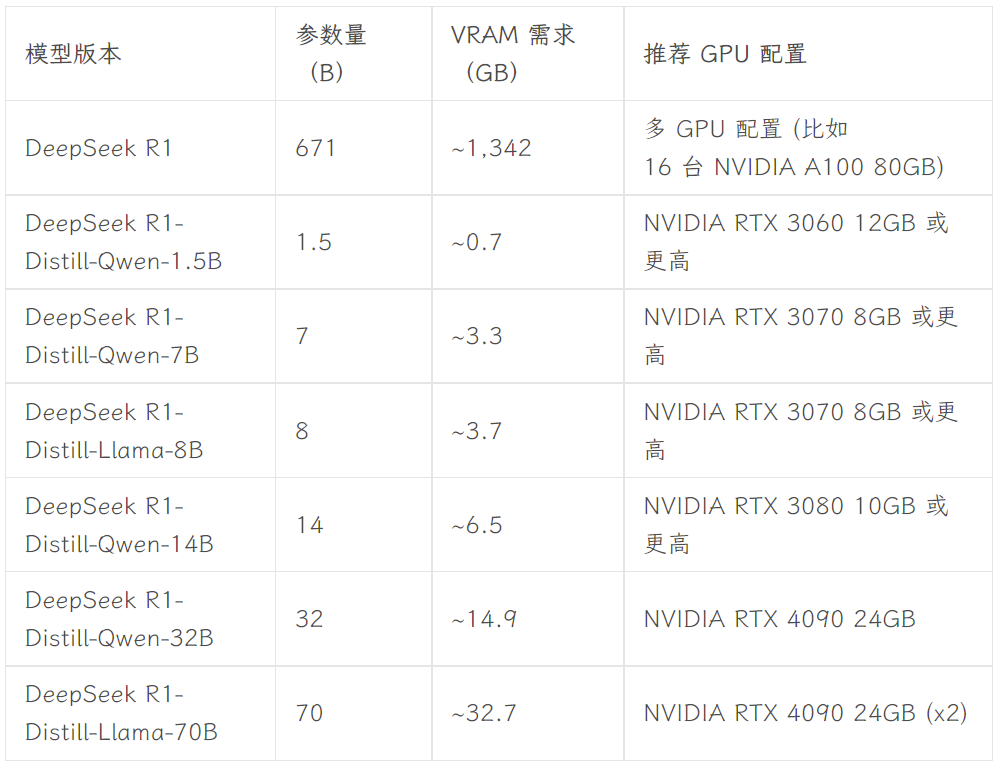
Fonte da imagem: https://dev.to/askyt/deepseek-r1-architecture-training-local-deployment-and-hardware-requirements-3mf8
Este artigo usa a versão 8B como exemplo para demonstração. Abra o terminal do dispositivo e execute o seguinte comando:
ollama run deepseek-r1:8b
Em seguida, basta aguardar o término do download do modelo. (O Ollama também suporta o download de modelos diretamente do Hugging Face, com o comando ollama run hf.co/{username}/{library}:{quantified version}, por exemplo, ollama run hf.co/bartowski/Llama-3.2-3B-Instruct-GGUF:Q8_0).

Depois de fazer o download do modelo, você pode conversar com a versão 8B do DeepSeek-R1 no terminal.

No entanto, esse tipo de diálogo de terminal não é intuitivo e conveniente para o usuário comum. Portanto, é necessário um front-end de interface gráfica fácil de usar. Há uma grande variedade de front-ends para escolher, por exemplo, o Abrir a WebUI Obtendo algo como ChatGPT ou você pode optar por Caixa de bate-papo e outros aplicativos de desktop. Mais opções de front-end podem ser encontradas na documentação oficial do Ollama:
https://github.com/ollama/ollama
- Abrir a WebUI
Se você escolher Open WebUI, basta executar as duas linhas de código a seguir no terminal:
Instale o Open WebUI:
pip install open-webui
Execute o serviço Open WebUI:
open-webui serve
Depois disso, acesse http://localhost:8080 em seu navegador para experimentar a interface da Web semelhante ao ChatGPT. Na lista de modelos da Open WebUI, você pode ver vários modelos que foram configurados pela Ollama local, incluindo as versões DeepSeek-R1 7B e 8B e outros modelos, como Llama 3.1 8B, Llama 3.2 3B, Phi 4, Qwen 2.5 Coder e assim por diante. O modelo DeepSeek-R1 8B foi escolhido para o teste:

- Caixa de bate-papo
Se preferir usar um aplicativo de desktop autônomo, considere ferramentas como o Chatbox. As etapas de configuração são igualmente simples, começando com o download e a instalação do aplicativo Chatbox:
https://chatboxai.app/zh
Depois de iniciar o Chatbox, entre na interface "Settings" (Configurações), selecione OLLAMA API em "Model Provider" (Provedor de modelo) e, em seguida, selecione o modelo que deseja usar na coluna "Model" (Modelo). Em seguida, selecione o modelo que deseja usar no campo "Model" e defina os parâmetros, como o número máximo de mensagens de contexto e a temperatura, de acordo com suas necessidades (você também pode manter as configurações padrão).

Depois de configurado, você pode ter uma conversa tranquila com o modelo DeepSeek-R1 implantado localmente no Chatbox. No entanto, os resultados do teste mostram que o modelo DeepSeek-R1 7B tem um desempenho ligeiramente inferior ao processar comandos complexos. Isso confirma o ponto anterior de que os usuários individuais geralmente só podem executar modelos com desempenho relativamente limitado em dispositivos locais. No entanto, é previsível que, à medida que a tecnologia de hardware continuar a evoluir, as barreiras ao uso local de modelos de parâmetros grandes para usuários individuais serão reduzidas ainda mais no futuro - e esse dia pode não estar muito distante.

**Tanto o Open WebUI quanto o Chatbox suportam o acesso aos modelos do DeepSeek, ChatGPT e Claude por meio de APIs, Gêmeos e outros modelos de negócios. Os usuários podem usá-los como uma interface de front-end para o uso diário de ferramentas de IA. Além disso, os modelos configurados no Ollama podem ser integrados a outras ferramentas, como aplicativos de anotações como o Obsidian e o Civic Notes.
Opção 2: implantar o DeepSeek-R1 com código zero usando o LM Studio
Para os usuários que não estão familiarizados com a operação ou o código da linha de comando, é possível usar o LM Studio para implantar o DeepSeek-R1 sem nenhum código. Em primeiro lugar, visite a página oficial de download do LM Studio para baixar o programa que corresponde ao seu sistema operacional:
https://lmstudio.ai
Inicie o LM Studio após a conclusão da instalação. Na guia "My Models" (Meus modelos), defina a pasta de armazenamento local para os modelos:

Em seguida, baixe os arquivos de modelo de idioma necessários do Hugging Face e coloque-os na pasta acima, de acordo com a estrutura de diretório especificada (o LM Studio tem uma função de pesquisa de modelo integrada, mas ela não funciona bem na prática). Observe que você precisa fazer o download dos arquivos de modelo no formato .gguf. Por exemplo Sem pano Uma coleção de modelos DeepSeek-R1 fornecidos pela organização:
https://huggingface.co/collections/unsloth/deepseek-r1-all-versions-678e1c48f5d2fce87892ace5
Considerando a configuração do hardware, neste documento, escolhemos a versão DeepSeek-R1 Distillate (número de parâmetro 14B) com base no ajuste fino do modelo Qwen e a versão quantificada de 4 bits: DeepSeek-R1-Distill-Qwen-14B-Q4_K_M.gguf.
Após a conclusão do download, coloque os arquivos do modelo na pasta definida anteriormente, de acordo com a seguinte estrutura de diretórios:
Pasta do modelo /unsloth/DeepSeek-R1-Distill-Qwen-14B-GGUF/DeepSeek-R1-Distill-Qwen-14B-Q4_K_M.gguf
Por fim, abra o LM Studio e selecione o modelo que deseja carregar na parte superior da interface do aplicativo para conversar com o modelo local.

A maior vantagem do LM Studio é que ele é completamente sem código, não há necessidade de usar um terminal nem de escrever nenhum código - basta instalar o software e configurar as pastas, o que o torna muito fácil de usar.
resumos
Os tutoriais fornecidos neste artigo fornecem apenas um nível básico de implantação local do DeepSeek-R1. É necessária uma configuração mais detalhada, como a definição de prompts do sistema e o ajuste fino mais avançado do modelo, para integrar esse modelo popular mais profundamente aos fluxos de trabalho locais, RAG Integração, função de pesquisa, recursos multimodais e recursos de invocação de ferramentas. Ao mesmo tempo, como o hardware específico de IA e as tecnologias de modelos pequenos continuam a evoluir, acredito que as barreiras à implementação de modelos grandes localmente continuarão a cair no futuro. Depois de ler este artigo, você está disposto a tentar implantar o modelo DeepSeek-R1 por conta própria?
Pacote de instalação de um clique do DeepSeek R1+OpenwebUI anexado
O pacote de instalação com um clique fornecido pelo Sword27 integra especificamente para o DeepSeek o Abrir a WebUI
Implantação local do DeepSeek de execução com um clique, descompactado para uso Suporte 1.5b 7b 8b 14b 32b, suporte mínimo para placa de vídeo 2G
Processo de instalação
1.AI environment download: https://pan.quark.cn/s/1b1ad88c7244
2. download do pacote de instalação: https://pan.quark.cn/s/7ec8d85b2f95
Obtenha ajuda no artigo original: https://www.jian27.com/html/1396.html
© declaração de direitos autorais
Direitos autorais do artigo Círculo de compartilhamento de IA A todos, favor não reproduzir sem permissão.
Artigos relacionados



Nenhum comentário...