
Meeseeks - Conjunto de avaliação de código aberto do Meeseeks para avaliar a capacidade de seguir instruções de modelos
O Meeseeks é um conjunto de avaliação de modelos grandes de código aberto usado pela equipe M17 da Meituan para avaliar a capacidade de um modelo de seguir instruções. O Meeseeks usa uma estrutura de avaliação de três níveis para medir de forma abrangente se um modelo é capaz de gerar respostas estritamente de acordo com as instruções do usuário, do nível macro ao micro, e não avalia o conhecimento do conteúdo da resposta como um fator positivo...

gpt-realtime - o mais recente modelo de fala de IA da OpenAI
O gpt-realtime é um modelo de fala avançado da OpenAI que oferece suporte ao processamento direto de áudio para gerar uma fala natural e suave. O modelo é compatível com vários idiomas e estilos, compreende sinais não verbais, como risadas, e pode alternar entre idiomas.
Youtu-agent - estrutura de corpo inteligente eficiente de código aberto da Tencent
O Youtu-agent é uma estrutura de código aberto para criar e executar inteligências autônomas do Tencent Youtu Labs. A estrutura tem bom desempenho nos benchmarks WebWalkerQA e GAIA, com uma precisão de 71,47% e 72,8%, respectivamente.

HunyuanVideo-Foley - Modelo de geração de som de vídeo de código aberto da Tencent
O HunyuanVideo-Foley é um modelo de geração de som de vídeo de código aberto da equipe Mixed Yuan da Tencent, que oferece suporte à adição de efeitos sonoros combinados com precisão a vídeos silenciosos. O modelo é baseado em um treinamento de conjunto de dados em grande escala, com uma arquitetura de conversor de difusão multimodal, combinado com a representação da função de perda de alinhamento e técnicas de otimização de VAE de áudio...
PixVerse V5 - Modelo de vídeo com IA desenvolvido pela própria Aishi Technologies
O PixVerse V5 é um grande modelo de geração de vídeo com IA lançado pela Aishi Technology. O modelo pode gerar conteúdo de vídeo de alta qualidade com base em descrições de texto ou imagens inseridas pelo usuário e suporta uma variedade de estilos, como anime, ficção científica e estilo nacional.
Ask White 5 - Modelo de IA tudo em um da Ask White
O Ask White 5 é o principal modelo "All in One" com um nível muito alto de inteligência. O modelo tem um bom desempenho em muitas avaliações, como a pontuação de avaliação composta do AA-Index de 64,7 e a pontuação de avaliação de habilidade STEM de 86, que é próxima à do líder mundial GPT-5.
Gemini 2.5 Flash Image - O modelo mais avançado de geração e edição de imagens do Google
O Gemini 2.5 Flash Image (codinome nano banana) é um modelo de geração e edição de imagens de última geração do Google que mantém a consistência dos caracteres em todas as cenas e oferece suporte à edição precisa de imagens por meio de linguagem natural, como desfoque de fundos e remoção de manchas.

Wan2.2-S2V - modelo de geração de vídeo orientado por áudio de código aberto de Ali Tongyi
O Wan2.2-S2V é um modelo de geração de vídeo multimodal de código aberto de Ali Tongyi, com apenas uma imagem estática e um trecho de áudio, que pode gerar vídeo humano digital de alta qualidade e oferece suporte a vários tipos de imagens e quadros.
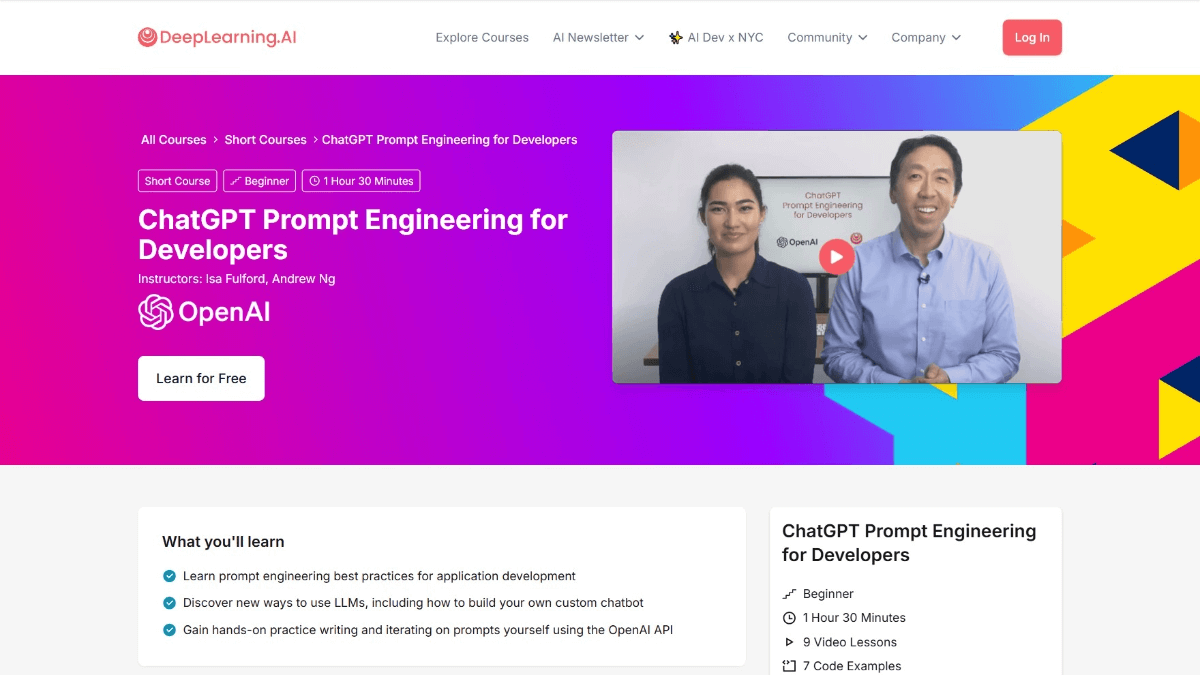
Curso gratuito sobre engenharia de dicas do ChatGPT para desenvolvedores, ministrado por Ernest Ng
O ChatGPT Tip Engineering for Developers é um curso conjunto da DeepLearning.AI e da OpenAI projetado para desenvolvedores, com Isa Fulford, Andrew Ng para ensinar como usar modelos de linguagem grande (LLM...
Ask o4 - Um modelo de pensamento paralelo introduzido pelo Ask o4 que abre 8 caminhos de pensamento ao mesmo tempo
O Ask White o4 é um modelo inovador de pensamento paralelo que abre 8 caminhos de pensamento ao mesmo tempo, analisa o problema a partir de várias perspectivas e filtra automaticamente a solução ideal. O modelo incorpora técnicas avançadas de aprendizado por reforço Long-CoT e aprendizado por recompensa de processo, tem recursos avançados de raciocínio profundo e apresenta bom desempenho em tarefas complexas.