
A primeira lista de benchmarks de avaliação do "AI Search" foi lançada! A margem de liderança da 4o é pequena, e os grandes modelos domésticos têm um desempenho brilhante, com um total de 5 bases, 11 cenários e 14 modelos.


O lançamento da avaliação de referência do Big Model AI Search (SuperCLUE-AISearch) chinês é uma avaliação aprofundada da capacidade do Big Model combinado com a pesquisa. A avaliação não se concentra apenas nos recursos básicos do Big Model, mas também examina seu desempenho em aplicativos de cenário. A avaliação abrange 5 recursos básicos, como recuperação de informações e aquisição de informações atualizadas, bem como 11 aplicativos de cenário, como notícias e aplicativos de vida, para testar de forma abrangente o desempenho do modelo na combinação de pesquisa em diferentes recursos básicos e tarefas de aplicativos de cenário. Para conhecer o esquema de avaliação, consulte: "AI Search" Benchmark Evaluation Scheme Release. Desta vez, avaliamos os recursos de pesquisa de IA de 14 grandes modelos representativos no país e no exterior, e o relatório de avaliação detalhado é o seguinte.
Resumo da avaliação da pesquisa de IA
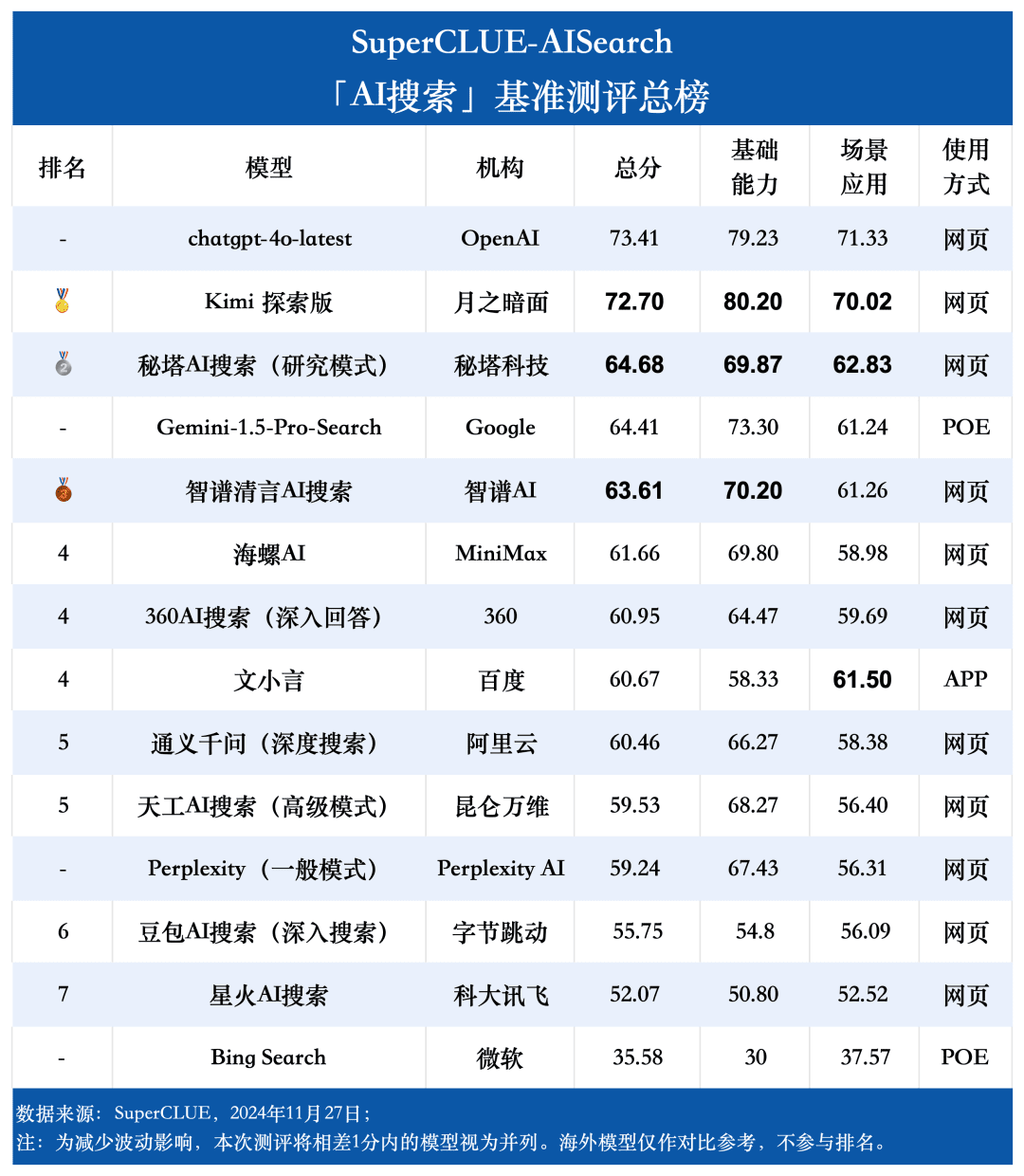
Ponto de medição 1Na avaliação, o chatgpt-4o-latest obteve 73,41 pontos com excelente desempenho, à frente de outros modelos participantes. Enquanto isso, o grande modelo doméstico Kimi O desempenho da Explorer Edition também é digno de nota, com bom desempenho nos tópicos de compras e cultura no aplicativo de cenário, demonstrando excelentes recursos de pesquisa de IA, bem como excelente desempenho abrangente em várias dimensões.
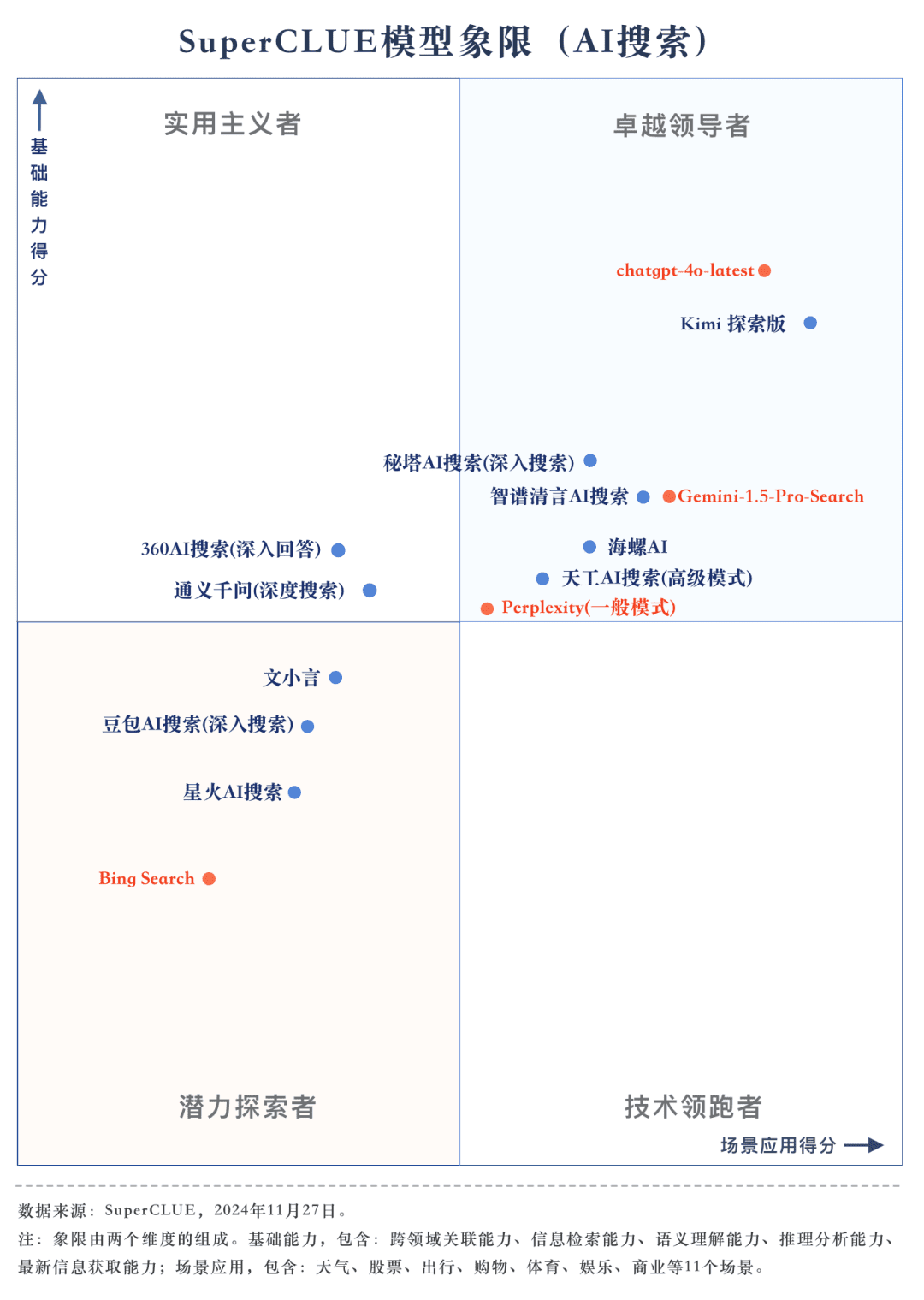
Ponto de medição 2De acordo com os resultados da avaliação, os grandes modelos nacionais, como o Secret Tower AI Search (modo de pesquisa), o Wisdom Spectrum Clear Speech AI Search e o Conch AI, são mais impressionantes em termos de desempenho geral, no mesmo nível do grande modelo estrangeiro Gemini-1.5-Pro-Search. Além disso, o desempenho de vários modelos nacionais de grande porte no meio do desempenho geral, como o 360AI Search (resposta aprofundada), o Wen XiaoYin, o Tongyi QianQi (pesquisa profunda) e outros modelos de grande porte, não são semelhantes, apresentando uma pequena diferença.
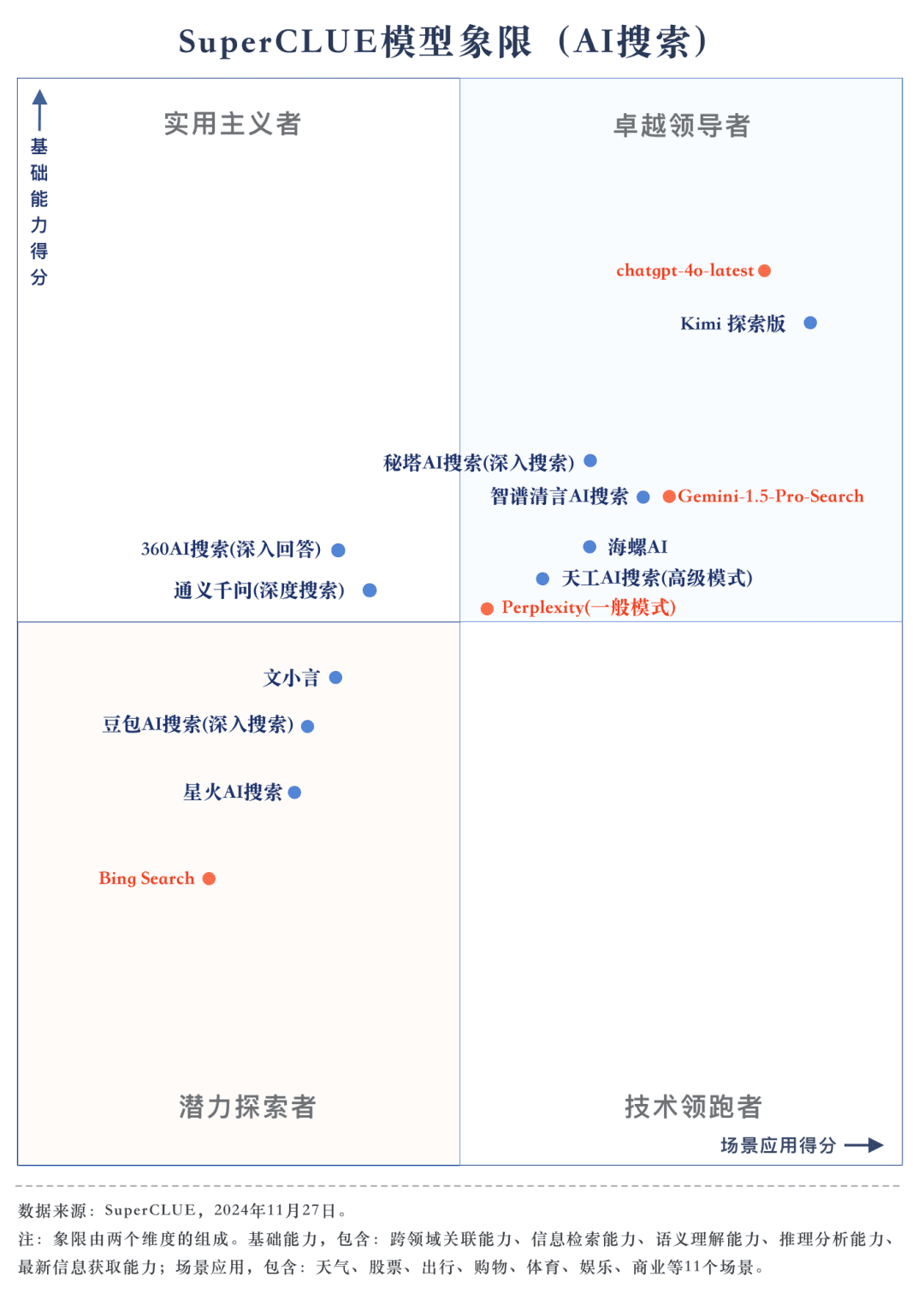
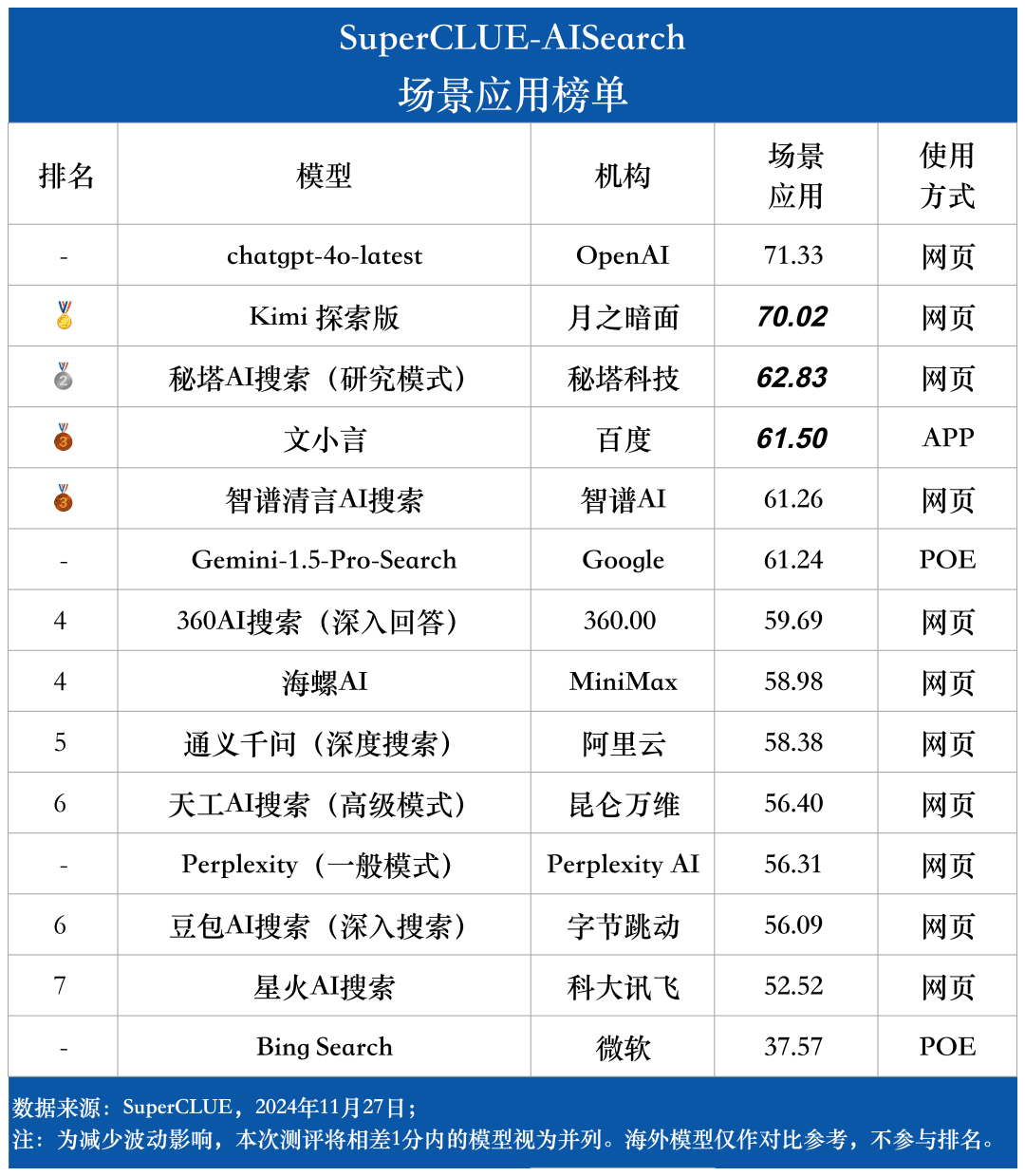
Ponto de medição 3Os modelos mostram diferentes graus de desempenho em diferentes cenários de aplicação. Na avaliação da pesquisa de IA, também nos concentramos no desempenho de cada grande modelo em diferentes cenários de aplicação. Os grandes modelos nacionais tiveram um desempenho relativamente bom em cenários como ciência e tecnologia, cultura, negócios e entretenimento, demonstrando excelentes recursos de recuperação e integração de informações e, ao mesmo tempo, compreendendo a atualidade das informações. No entanto, ainda há espaço para os grandes modelos nacionais melhorarem em aplicações de cenários como ações e esportes.
Visão geral da lista
Introdução ao SuperCLUE-AISearch
O SuperCLUE-AISearch é um conjunto de avaliação abrangente de modelos de pesquisa de IA chineses, com o objetivo de fornecer uma referência para avaliar a capacidade dos modelos de pesquisa de IA no domínio chinês.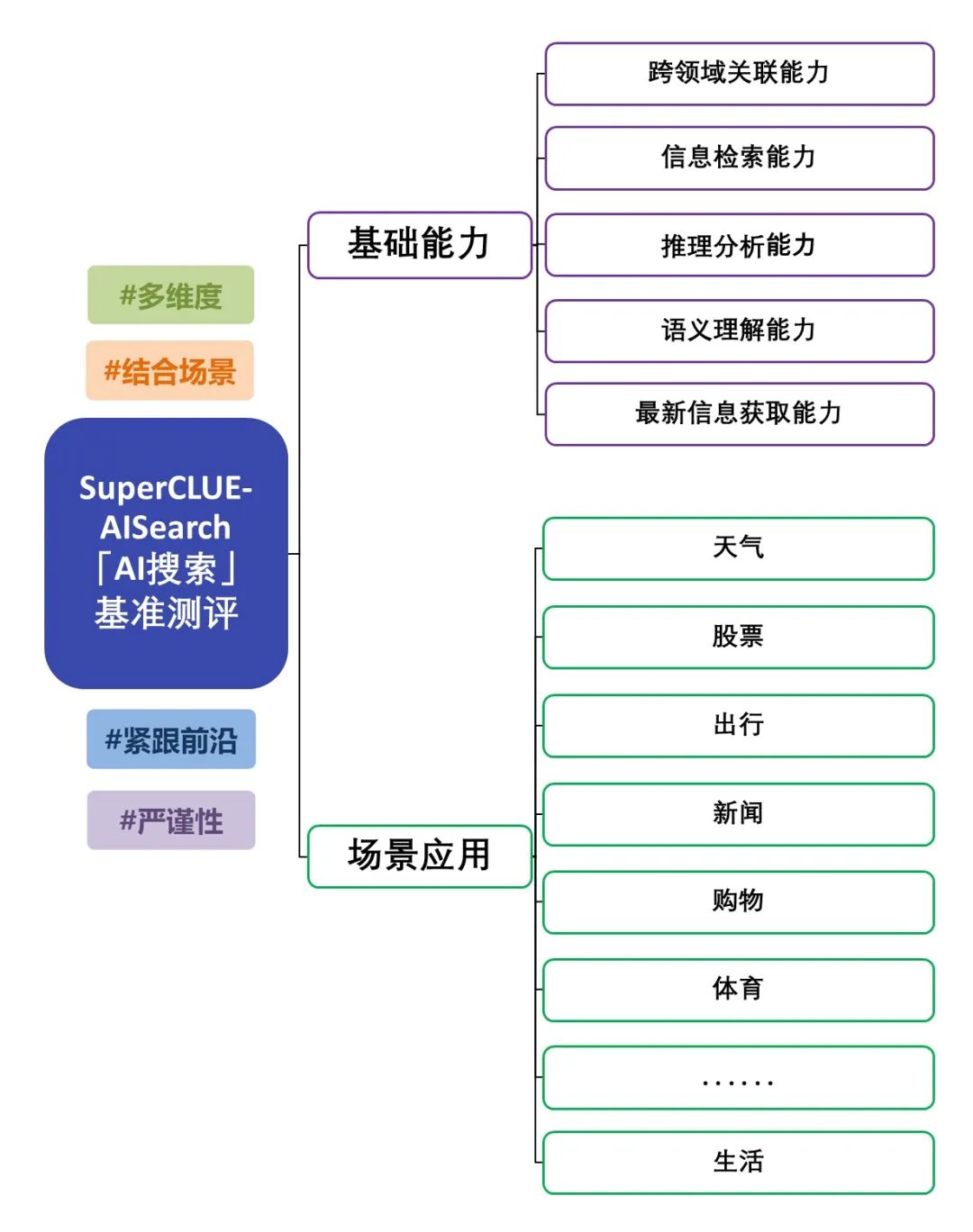
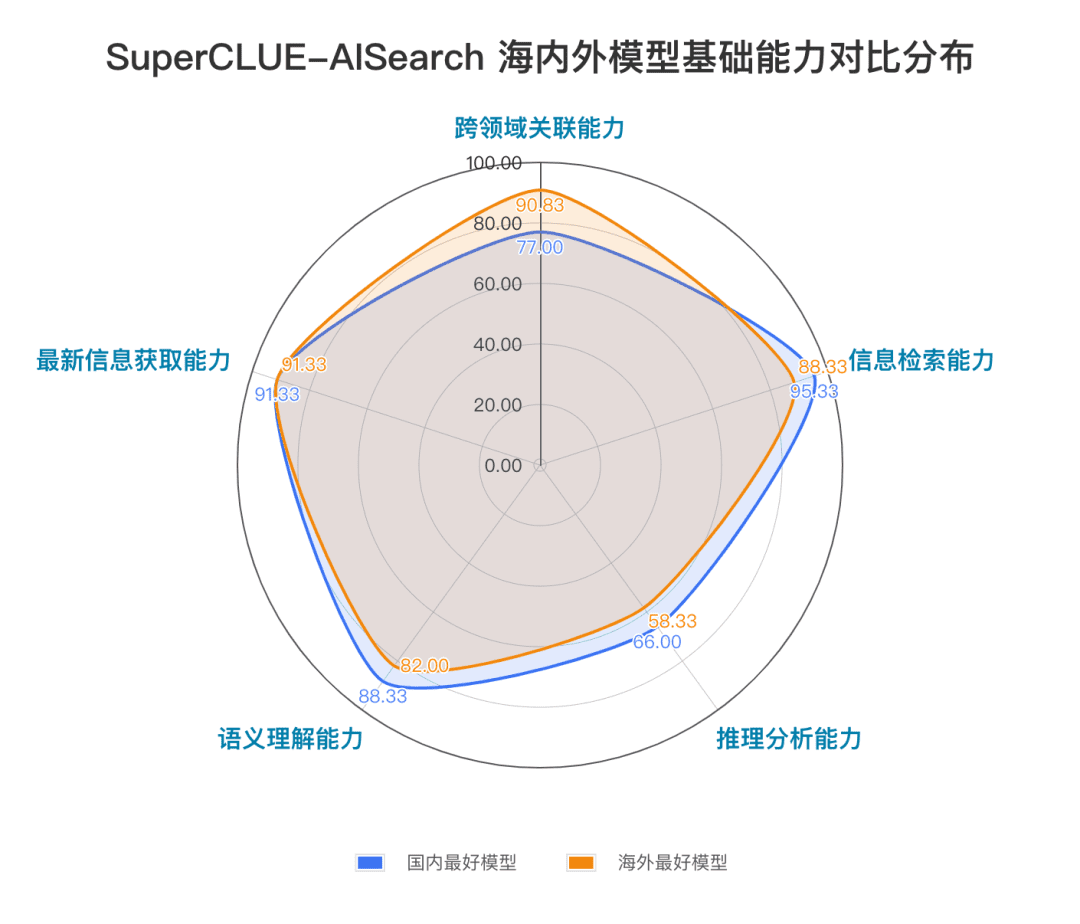
Os recursos fundamentais incluem cinco recursos necessários em tarefas de pesquisa de IA: relevância entre domínios, recuperação de informações, compreensão semântica, aquisição de informações atualizadas e raciocínio.
Os aplicativos de cenário incluem 11 cenários comuns às tarefas de pesquisa de IA: clima, ações, viagens, notícias, compras, esportes, entretenimento, educação, viagens, negócios, cultura, tecnologia, saúde e vida.
Metodologia
Referindo-se à abordagem de avaliação refinada do SuperCLUE, um conjunto dedicado de medições é construído, e cada dimensão é avaliada em um nível refinado, e um feedback detalhado pode ser fornecido.
1) Construção do conjunto de medição
Processo de construção do prompt em chinês: 1. referência ao prompt existente ---> 2. redação do prompt em chinês ---> 3. teste ---> 4. modificação e finalização do prompt em chinês; criação de um conjunto de avaliação dedicado para cada dimensão.
2) Método de pontuação
O processo de avaliação começa com a interação do modelo com o conjunto de dados, que precisa ser compreendido e respondido com base nas perguntas fornecidas.
Os critérios de avaliação abrangem as dimensões do processo de pensamento, do processo de solução de problemas, da reflexão e do ajuste.
As regras de pontuação combinam a pontuação quantitativa automatizada com a análise de especialistas para pontuar com eficiência e, ao mesmo tempo, garantir que a avaliação seja científica e justa.
3) Critérios de pontuação
Para a avaliação da qualidade da resposta de cada macromodelo nas tarefas de avaliação, foram usados dois critérios de avaliação para avaliar as perguntas subjetivas e objetivas no conjunto de avaliação, respectivamente. Esses critérios receberam pesos diferentes na avaliação para refletir totalmente o desempenho dos grandes modelos na tarefa de pesquisa de IA.
O sistema de avaliação SuperCLUE-AISearch foi projetado para pontuar as questões subjetivas em 5 pontos, que são avaliados a partir das dimensões de utilidade das informações, precisão analítica e clareza de expressão, das quais a utilidade das informações representa 60%, a precisão analítica representa 20% e a clareza de expressão representa 20%. Os critérios de pontuação para as questões objetivas são pontuados em 5 pontos, que são avaliados a partir das dimensões de precisão das informações e clareza de expressão, das quais a precisão das informações representa 80% e a clareza de expressão representa 20%. As questões objetivas são pontuadas em 5 pontos, avaliados em duas dimensões: precisão das informações e clareza de expressão, sendo que a precisão das informações representa 80% e a clareza de expressão representa 20%. 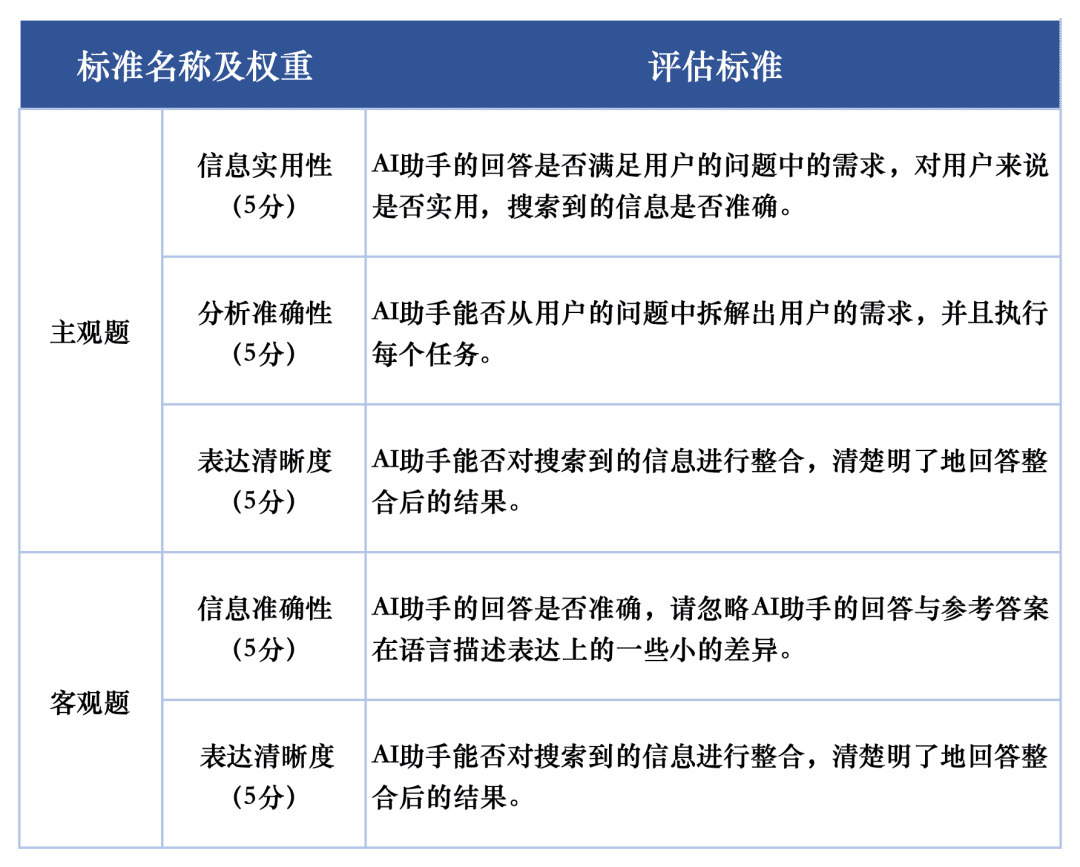
Exemplo de avaliação
Prompt word Prompt: quando e onde foi lançada a espaçonave tripulada Shenzhou 19 e quem eram os astronautas nessa ocasião?
Resposta: Na madrugada de 30 de outubro, o lançamento da espaçonave tripulada Shenzhou XIX do Centro de Lançamento de Satélites de Jiuquan foi um sucesso total. A tripulação da missão tripulada da Shenzhou-19 era composta por três astronautas, Cai Xuzhe, Song Lingdong e Wang Haize.
Resposta do modelo:
Árbitro de Supermodel (chatgpt-4o-latest):
Avalie essa resposta da seguinte forma:
A resposta do assistente de IA forneceu com precisão o horário e o local de lançamento da espaçonave tripulada Shenzhou XIX, bem como a lista de astronautas. No entanto, a resposta não mencionou os principais objetivos e o conteúdo da missão, não satisfazendo totalmente a necessidade do usuário de conhecer os detalhes da missão. Além disso, a seção sobre os perfis pessoais dos astronautas, embora detalhada, pode ter excedido o escopo de preocupação dos usuários. Portanto, recomenda-se que uma breve descrição dos objetivos e das principais tarefas da missão seja acrescentada à resposta para atender melhor às necessidades dos usuários.1. Utilidade das informações (5 pontos):
O assistente de IA forneceu o horário de lançamento, o local e a lista de astronautas da Shenzhou XIX, satisfazendo a necessidade do usuário por essas informações básicas. No entanto, os principais objetivos da missão e o conteúdo da missão não foram mencionados, não satisfazendo totalmente a necessidade do usuário de conhecer os detalhes da missão. Portanto, a pontuação para a utilidade das informações foi 4.
Pontuação: 4/52 Precisão da análise (5 pontos):
O assistente de IA extraiu com precisão informações importantes, como o horário de lançamento, o local e a lista de astronautas da pergunta do usuário e forneceu um perfil pessoal detalhado. No entanto, ele não abordou os objetivos e o conteúdo principal da missão e não conseguiu atender totalmente às necessidades do usuário. Portanto, a pontuação de precisão da análise foi 4.
Pontuação: 4/53. clareza de expressão (5 pontos):
As respostas do assistente de IA são claramente estruturadas, com informações bem organizadas e fáceis de entender. A seção de perfil pessoal é detalhada, o que facilita aos usuários entender o histórico do astronauta. Portanto, a clareza de expressão é pontuada como 5.
Pontuação: 5/5 Combinado = 4*0,6 + 4*0,2 + 5*0,2 = 4,2 Combinado acima, a pontuação combinada para a resposta do assistente de IA é 4,2. (de 5 pontos)
Modelos participantes
Para medir de forma abrangente o nível de desenvolvimento atual dos grandes modelos nacionais e internacionais na capacidade de pesquisa de IA, foram selecionados para essa avaliação quatro modelos estrangeiros e dez modelos representativos nacionais.
Considerando o fato de que muitos modelos de grande escala no país e no exterior geralmente oferecem duas ou mais versões, incluindo a versão comum e a versão de exploração aprofundada, neste processo de seleção de modelos, adotamos um critério unificado: se um modelo estiver equipado com uma versão de pesquisa ou análise mais aprofundada, selecionaremos a versão com o recurso de pesquisa mais forte para uma avaliação abrangente. 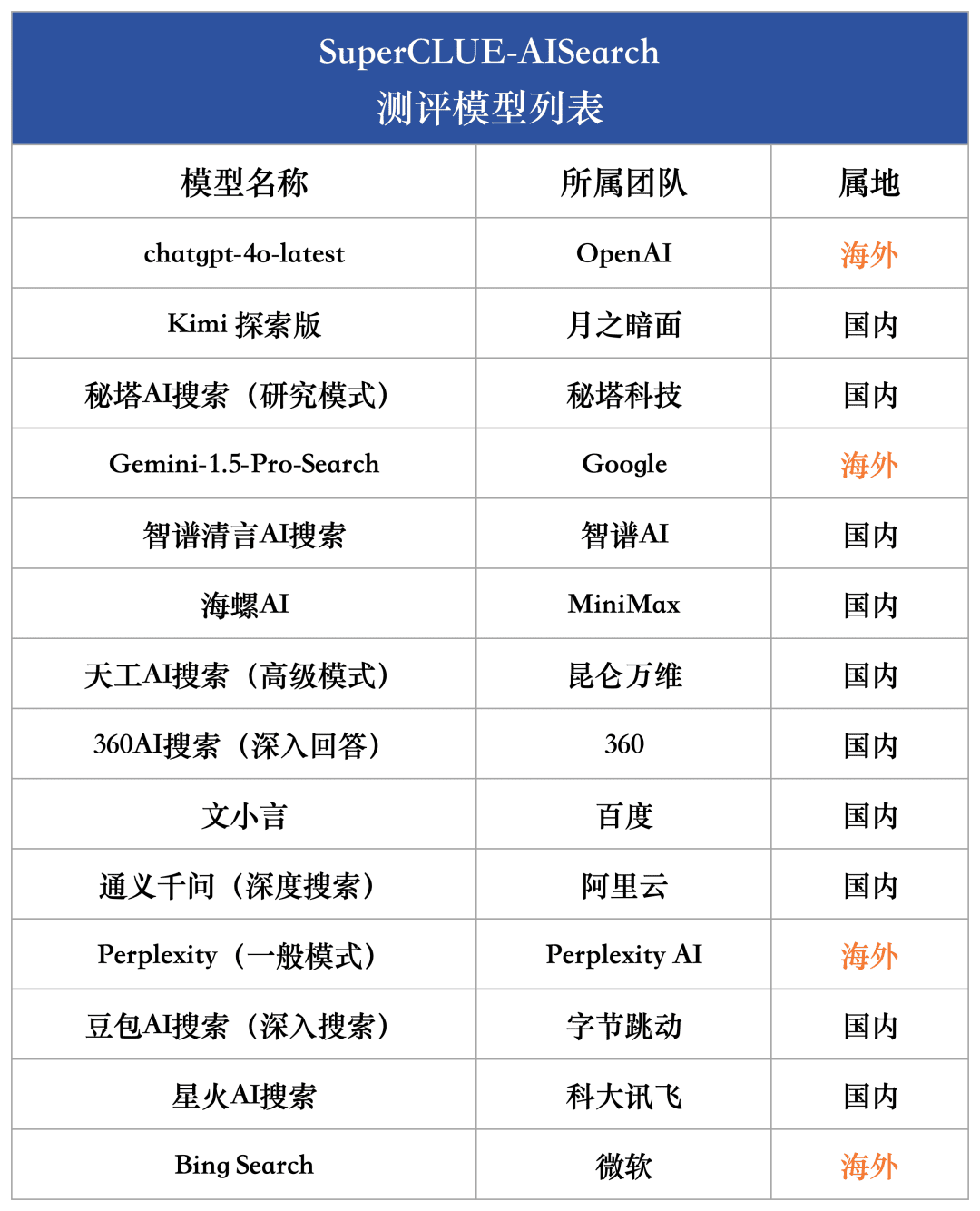
Resultados da avaliação
lista geral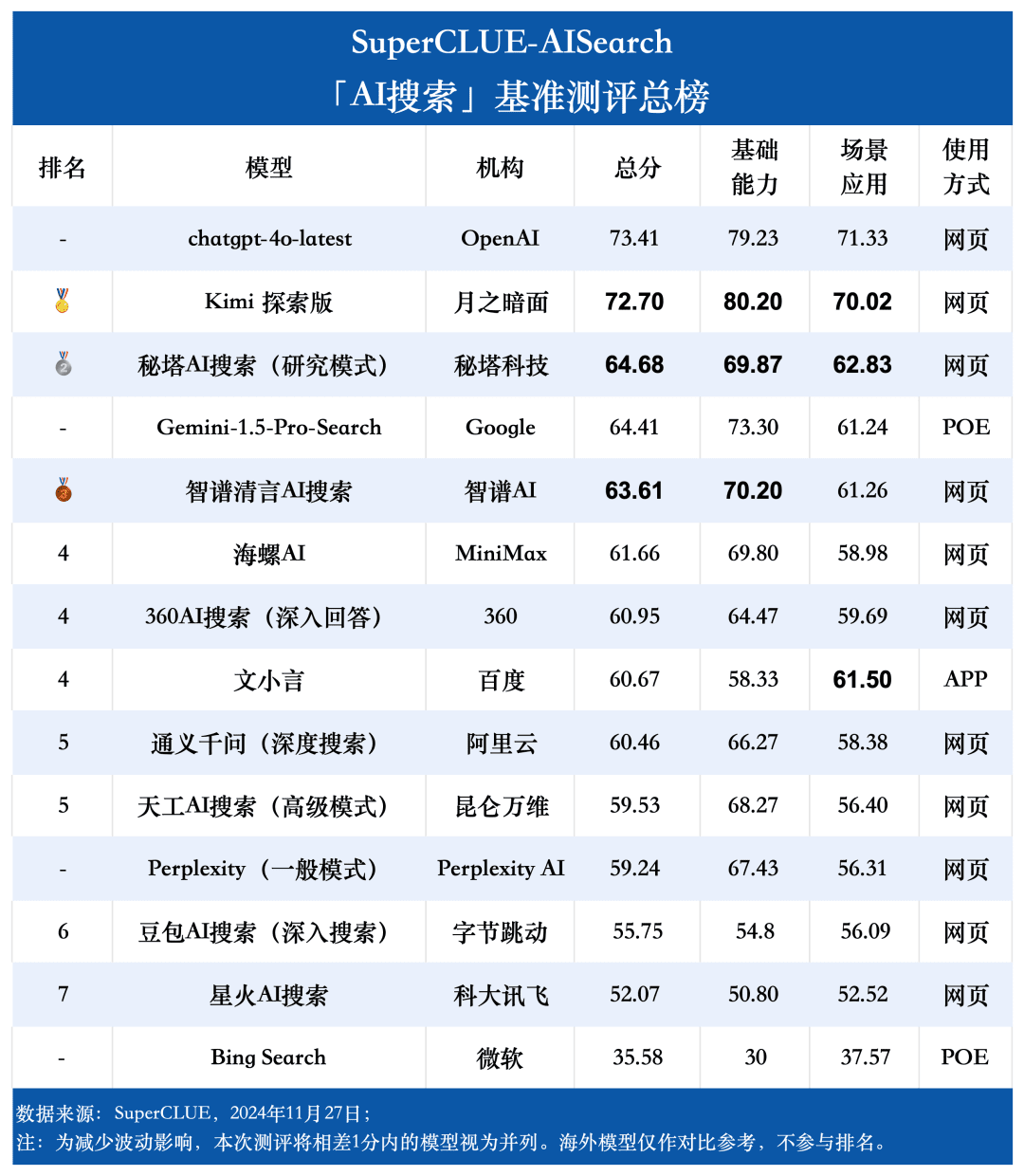
Lista de recursos básicos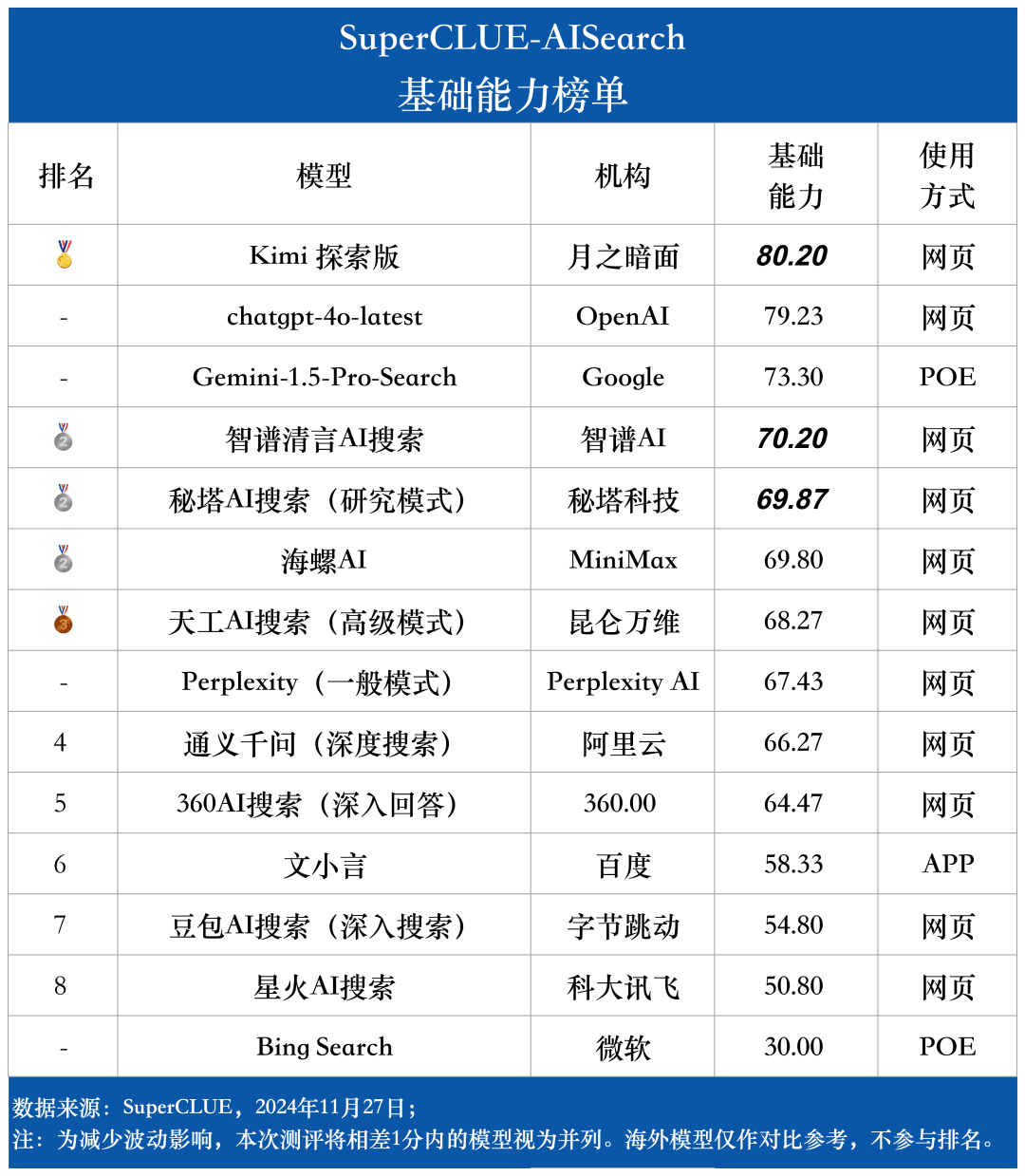
Lista de aplicativos de cenário
Lista de perguntas subjetivas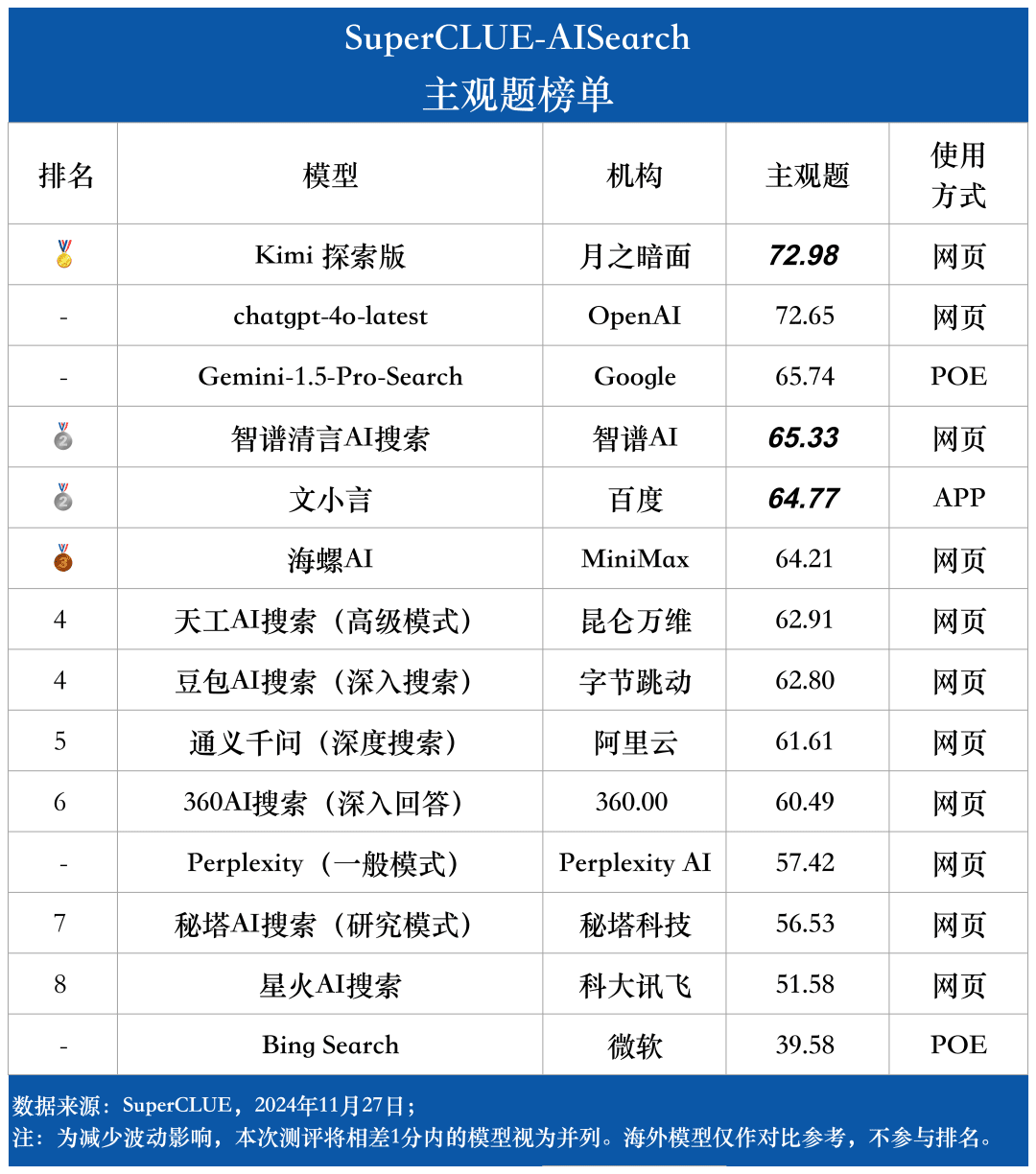
Lista de perguntas objetivas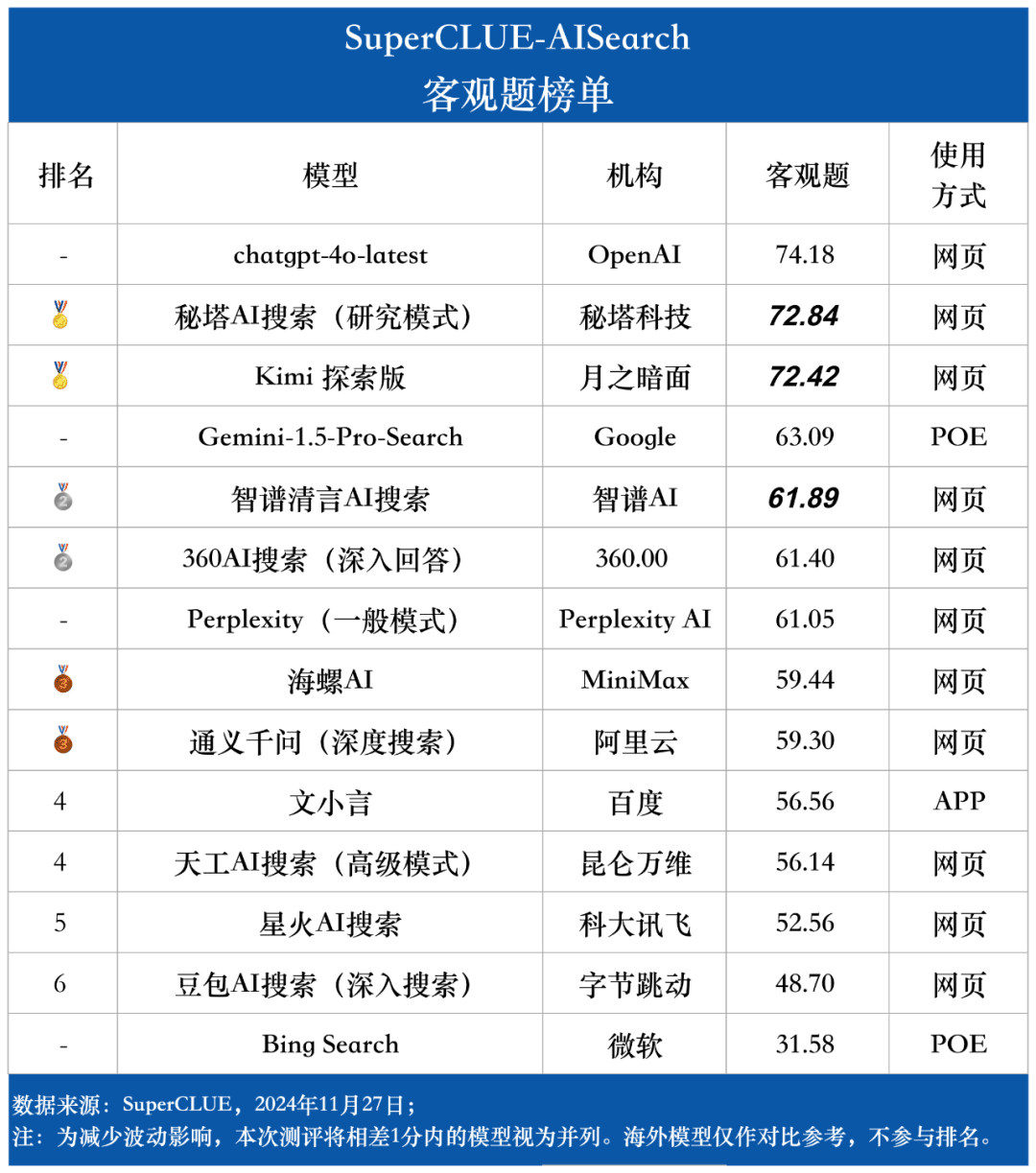
Exemplo de comparação de modelos
Exemplo 1 Habilidades básicas - habilidades de raciocínio e análise
Sugestão: "Por que a estrutura do modelo GPT-1 é usada? Transformador Em vez de LSTM?"
Comparação das respostas do modelo (de 5):
[Kimi Explorer]: 4 pontos 
[chatgpt-4o-latest]: 3,9 pontos 
[Skyworks AI Search (Modo Avançado)]: 3,4 pontos 
Exemplo 2 Competências básicas - vínculos transversais
PromptPrompt: "Por favor, ajude-me a descobrir quais são todas as aplicações da tecnologia de visão computacional na agricultura e selecione três delas e descreva brevemente cada uma delas".
Comparação das respostas do modelo (de 5):
[Pesquisa de IA da Torre Secreta (Modo de Pesquisa)]: 4 pontos 
[Wen Xiaoyan]: 3,4 pontos 
[Starfire AI Search]: 3 pontos 
Exemplo 3 Aplicação do cenário - Ações
PromptPrompt: "Fale-me sobre vários mercados em alta importantes de ações da categoria A nos últimos anos e seus dados relacionados (por exemplo, hora de início, duração, taxa de aumento, pontos mais altos e mais baixos, etc.)." Comparação das respostas do modelo (de 5 pontos): [Gemini-1.5-Pro-Search]: 3,2 pontos 
[Pesquisa de IA de fala clara do espectro inteligente]: 3,3 pontos 
Bing Search]: 2,6 pontos 
Exemplo 4 Aplicação de cena - Vida
Sugestão: "De janeiro a outubro deste ano, a produção e as vendas de automóveis na China atingiram quantos milhões de unidades, respectivamente, e em que porcentagem elas aumentaram em comparação com o mesmo período do ano passado?"
Comparação das respostas do modelo (de 5):
[Tongyi Thousand Questions (busca aprofundada)]: 4,2 pontos 
[Pesquisa 360AI (resposta aprofundada)]: 3,8 pontos 
Avaliação da consistência humana
Para garantir a validade científica da avaliação automatizada de modelos grandes, avaliamos a consistência humana do GPT-4o-0513 na tarefa de avaliação de pesquisa de IA.
O método de operação específico é o seguinte: cinco modelos são selecionados e cada modelo é pontuado independentemente por uma pessoa, respectivamente, para diferentes dimensões de perguntas subjetivas e objetivas e, em seguida, ponderado para calcular a média de acordo com os critérios de pontuação. Calculamos a diferença entre as pontuações humanas e as pontuações do modelo para cada pergunta e, em seguida, somamos e calculamos a média para obter a diferença média para cada pergunta como resultado da avaliação da consistência humana.
Os resultados médios finais obtidos foram os seguintes: O resultado da variação média foi (em porcentagem): 5,1 pontos
Devido à alta confiabilidade dessa avaliação automatizada.
Análise de avaliação e conclusão
1. capacidade abrangente de pesquisa de IA, o chatgpt-4o-latest mantém a liderança.
Como pode ser visto nos resultados da avaliação, o chatgpt-4o-latest (73,41 pontos) tem uma excelente capacidade geral e lidera o benchmark SuperCLUE-AISearch. Ele é apenas 0,71 pontos mais alto que o melhor modelo doméstico, o Kimi Explorer.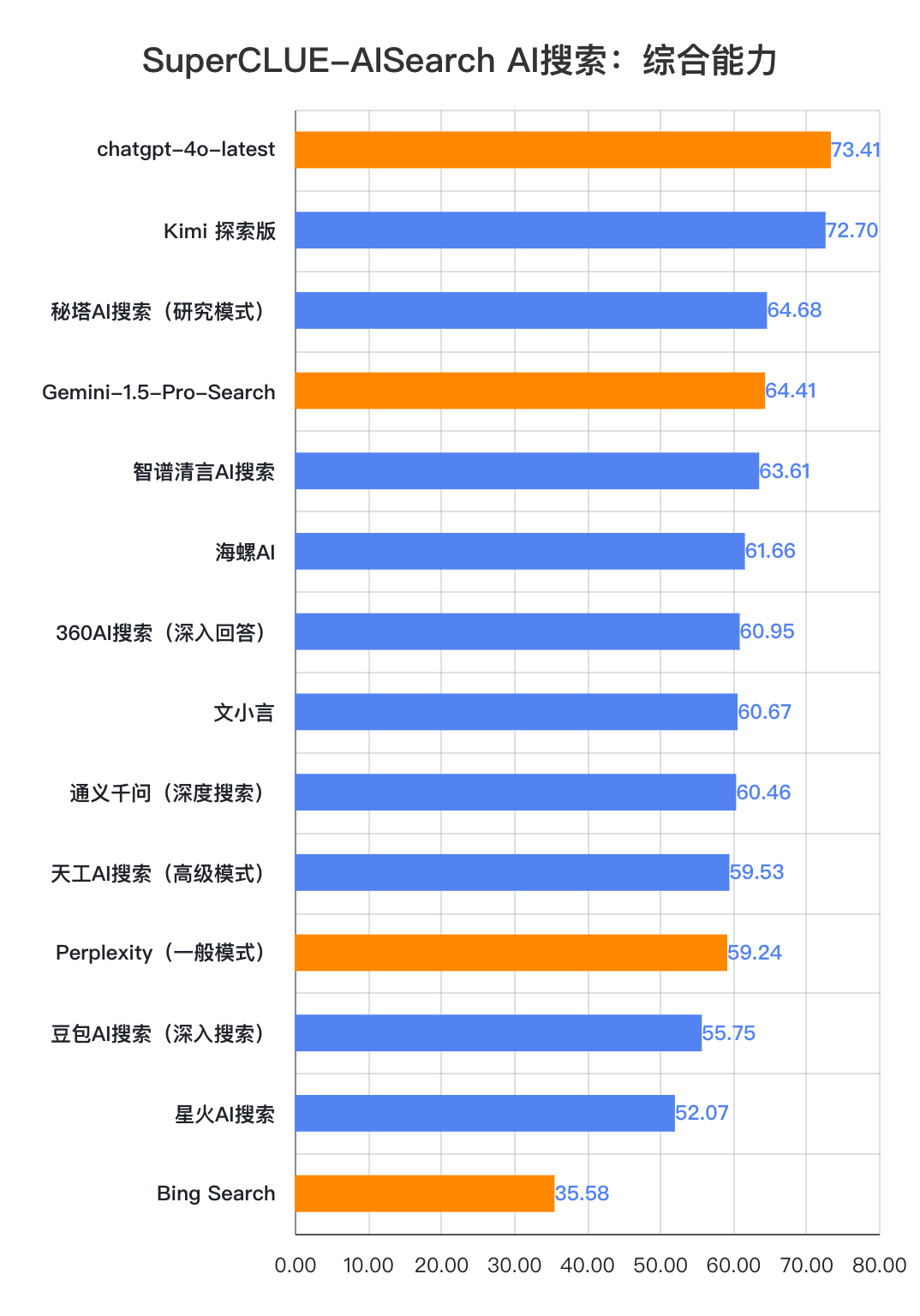
2. o desempenho geral dos modelos domésticos de grande porte é bastante impressionante, com diferenças relativamente pequenas entre os modelos
Com base nos resultados da avaliação, os modelos nacionais, como o Secret Tower AI Search (modelo de pesquisa), o Wisdom Spectrum Clear Speech AI Search e o Conch AI, apresentam um desempenho relativamente bom em termos de recursos básicos e têm o ímpeto de alcançar o grande modelo estrangeiro Gemini-1.5-Pro-Search. De modo geral, o desempenho de vários modelos nacionais no meio dos resultados gerais, como Conch AI, Wen Xiaoyin e Tongyi Qianqian (pesquisa profunda), não é comparável entre os modelos, apresentando uma pequena diferença.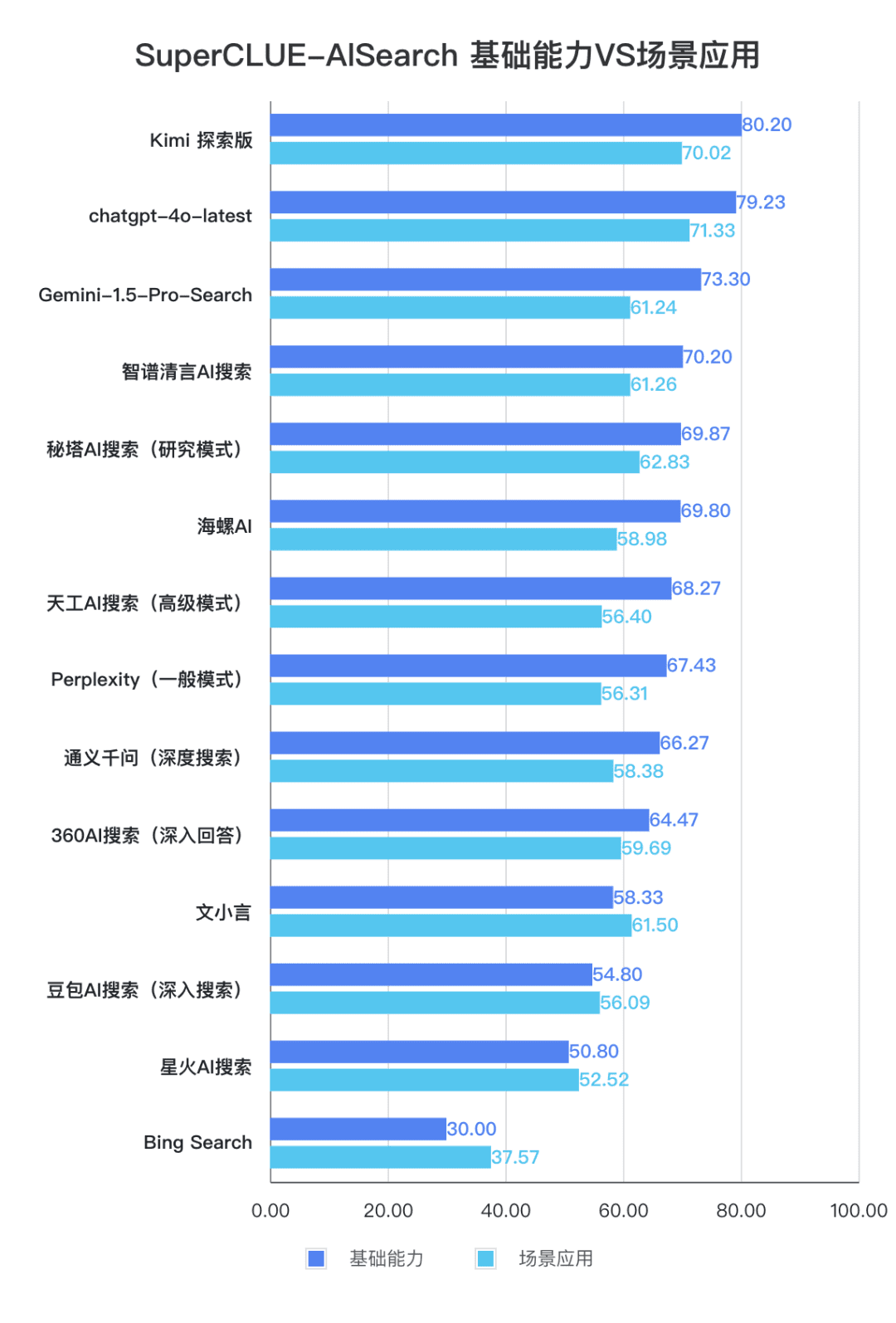
3) O modelo mostra diferentes níveis de desempenho em diferentes cenários de aplicativos.
No exame da pesquisa de IA, concentramo-nos no desempenho dos modelos em diferentes cenários de aplicação. O modelo doméstico de grande porte tem um desempenho relativamente bom em cenários de ciência e tecnologia, cultura, negócios e entretenimento, e consegue captar com precisão a atualidade das informações, além de demonstrar boa capacidade de recuperar e integrar informações. No entanto, em cenários de ações e esportes, ainda há espaço óbvio para melhorias nos modelos domésticos de grande porte.
Por exemplo, no processo de pesquisa de IA, o modelo precisa desmontar com precisão as necessidades de pesquisa do usuário, pesquisar as páginas da Web relevantes corretas com informações precisas e sensíveis ao tempo e, por fim, integrar as informações para formar uma cópia dos resultados da resposta que seja útil para o usuário. De acordo com a observação atual, os modelos domésticos de grande porte às vezes não conseguem analisar com precisão as necessidades de pesquisa e, às vezes, referem-se a conteúdo irrelevante da Web no processo de integração de informações, o que leva a um desempenho ruim dos modelos domésticos de grande porte em determinados cenários.
© declaração de direitos autorais
Direitos autorais do artigo Círculo de compartilhamento de IA A todos, favor não reproduzir sem permissão.
Artigos relacionados


Nenhum comentário...