
Ferramenta de pilha completa de IA de código aberto! Leve você com Ollama+Qwen2.5-Code runbolt.new, um clique para gerar um site!

As ferramentas de programação de IA estão em alta ultimamente, desde Cursor, V0, Bolt.new e, mais recentemente, Windsurf.
Nesta postagem, começaremos falando sobre a solução de código aberto - Bolt.new - que gerou uma receita de US$ 4 milhões em apenas quatro semanas desde que o produto foi lançado.

De forma inútil, o siteLimitações de velocidade de acesso domésticoeA cota de tokens gratuitos é limitada.
A missão do Monkey é como executá-lo localmente para que mais pessoas possam usá-lo e acelerar a IA até o chão.
O compartilhamento de hoje.Leva você através de um grande modelo implantado com um Ollama local, parafuso de condução.novoque permite a programação de IA Token Liberdade.
1. introdução ao Bolt.new
Parafuso.novo É uma plataforma de codificação de IA baseada em SaaS com inteligências subjacentes orientadas por LLM, combinada com a tecnologia WebContainers, que permite a codificação e a execução no navegador, com as vantagens de:
- Suporte ao desenvolvimento de front-end e back-end ao mesmo tempo.;
- Visualização da estrutura de pastas do projeto.;
- Ambiente auto-hospedado com instalação automática de dependências (por exemplo, Vite, Next.js, etc.).;
- Execução de um servidor Node.js da implantação à produção
ParafusoO objetivo do .new é tornar o desenvolvimento de aplicativos da Web mais acessível a um número maior de pessoas, de modo que até mesmo os iniciantes em programação possam concretizar ideias por meio de uma linguagem natural simples.
O projeto foi oficialmente de código aberto: https://github.com/stackblitz/bolt.new
No entanto, o bolt.new oficial de código aberto tem suporte limitado a modelos, e muitos de nossos parceiros domésticos não conseguem chamar a API LLM internacional.
Há um deus na comunidade. bolt.new-any-llmO suporte local está disponível. Ollama dê uma olhada prática abaixo.
2. implantação local do código Qwen2.5
Há algum tempo, Ali abriu o código aberto da série de modelos Qwen2.5-Coder, dos quais o modelo 32B obteve os melhores resultados de código aberto em mais de dez avaliações de benchmark.
Ele merece ser o modelo de código aberto mais avançado do mundo, superando até mesmo o GPT-4o em vários recursos importantes.
O repositório do modelo Ollama também está ativo para o qwen2.5-coder:
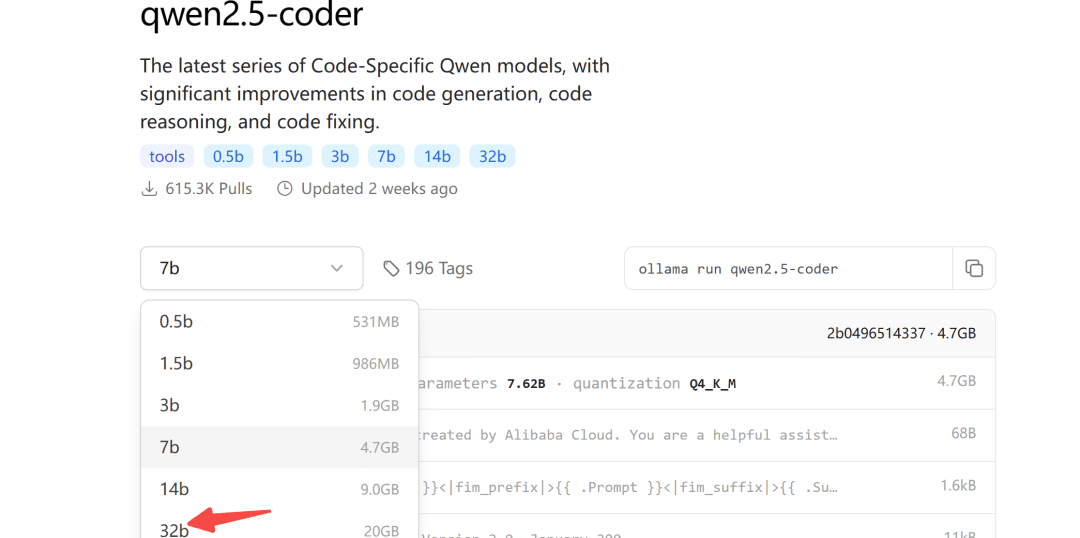
O Ollama é uma ferramenta fácil de usar para implementar modelos grandes.
2.1 Download do modelo
Quanto ao tamanho do modelo a ser baixado, você pode escolhê-lo de acordo com sua própria memória de vídeo; pelo menos 24G de memória de vídeo é garantido para o modelo de 32B.
A seguir, demonstramos isso com o modelo 7b:
ollama pull qwen2.5-coder
2.2 Modificações do modelo
Como a saída máxima padrão do Ollama é de 4096 tokens, ela é claramente insuficiente para tarefas de geração de código.
Para isso, os parâmetros do modelo precisam ser modificados para aumentar o número de tokens de contexto.
Primeiro, crie um novo arquivo Modelfile e preencha-o:
FROM qwen2.5-coder
PARAMETER num_ctx 32768
Em seguida, começa a transformação do modelo:
ollama create -f Modelfile qwen2.5-coder-extra-ctx
Após uma conversão bem-sucedida, visualize a lista de modelos novamente:

2.3 Execuções do modelo
Por fim, verifique no lado do servidor se o modelo pode ser chamado com êxito:
def test_ollama():
url = 'http://localhost:3002/api/chat'
data = {
"model": "qwen2.5-coder-extra-ctx",
"messages": [
{ "role": "user", "content": '你好'}
],
"stream": False
}
response = requests.post(url, json=data)
if response.status_code == 200:
text = response.json()['message']['content']
print(text)
else:
print(f'{response.status_code},失败')
Se não houver nada de errado, você pode chamá-lo em bolt.new.
3. Bolt.new em execução localmente
3.1 Implementação local
etapa 1Faça o download do bolt.new-any-llm, que oferece suporte a modelos locais:
git clone https://github.com/coleam00/bolt.new-any-llm
passo2Cópia das variáveis de ambiente: Faça uma cópia das variáveis de ambiente:
cp .env.example .env
passo3Modifique a variável de ambiente paraOLLAMA_API_BASE_URLSubstitua-o por seu próprio:
# You only need this environment variable set if you want to use oLLAMA models
# EXAMPLE http://localhost:11434
OLLAMA_API_BASE_URL=http://localhost:3002
passo4Instalação de dependências (com o nó instalado localmente)
sudo npm install -g pnpm # pnpm需要全局安装
pnpm install
passo5: operação com um clique
pnpm run dev
O seguinte resultado indica que a inicialização foi bem-sucedida:
➜ Local: http://localhost:5173/
➜ Network: use --host to expose
➜ press h + enter to show help
3.2 Demonstração dos efeitos
Abrir no navegadorhttp://localhost:5173/O modelo do tipo Ollama é selecionado:
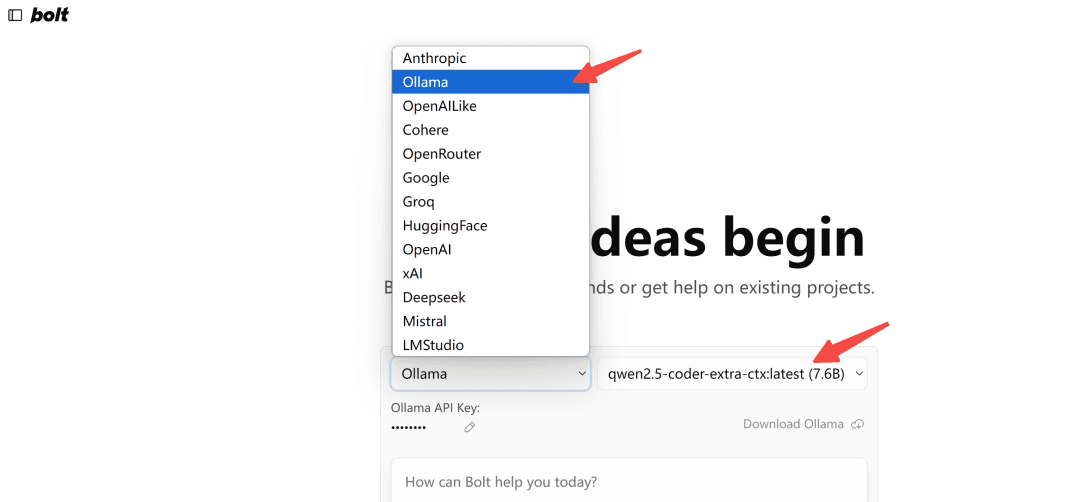
Observação: Na primeira vez em que for carregado, se o modelo não for exibido no Ollama, atualize-o algumas vezes para ver como fica.
Vamos testá-lo.
写一个网页端贪吃蛇游戏
À esquerda.流程执行e, à direita, a área代码编辑área, abaixo da qual está a终端Área. A IA cuida da escrita de código, da instalação de dependências e dos comandos de terminal!
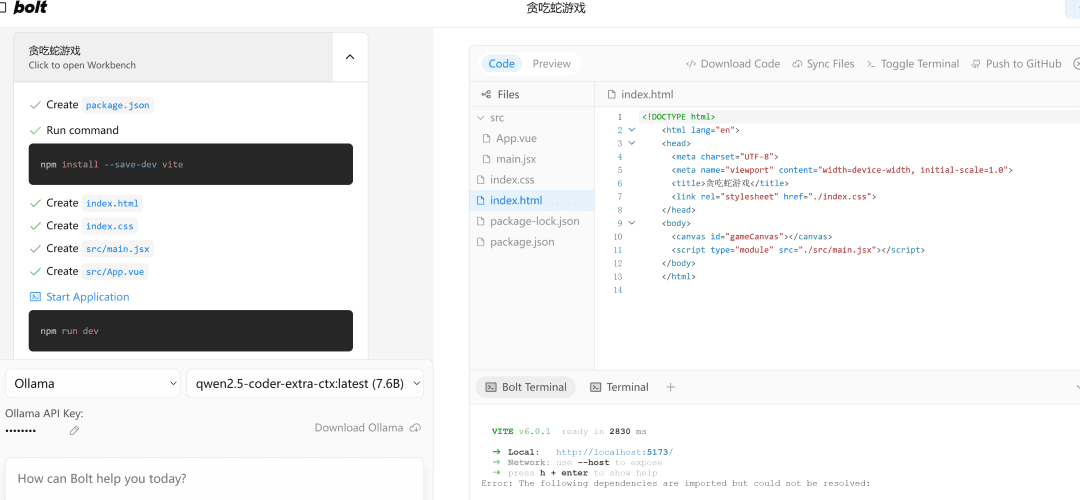
Se ele encontrar um erro, basta lançar o erro nele, executá-lo novamente e, se não houver nada de errado, o lado direitoPreviewA página será aberta com êxito.
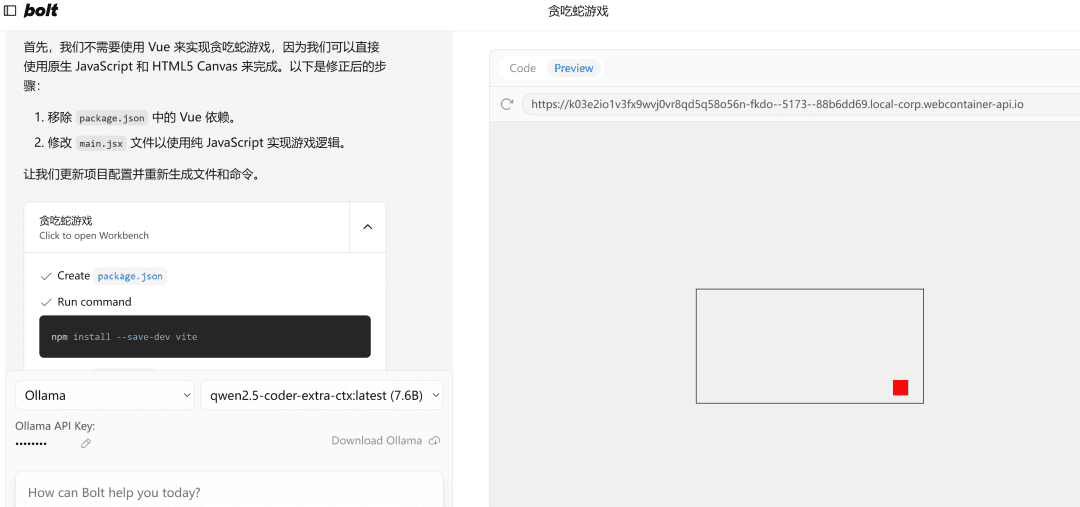
Observação: Como o exemplo usa um modelo pequeno de 7b, se for necessário, você pode tentar usar um modelo de 32b, pois o efeito será significativamente melhor.
escrever no final
Este artigo o orienta em uma implantação local do modelo de código qwen2.5 e conduz com êxito a ferramenta de programação de IA bolt.new.
Usá-lo para desenvolver o projeto de front-end ainda é bastante eficiente, mas é claro que, para usá-lo bem, conhecer alguns conceitos básicos de front-end e back-end será duas vezes mais eficaz.
© declaração de direitos autorais
Direitos autorais do artigo Círculo de compartilhamento de IA A todos, favor não reproduzir sem permissão.
Publicações relacionadas




Nenhum comentário...