
AI Engineering Academy: 2.10 Recuperador de mesclagem automatizado
breve
O pesquisador de mesclagem automatizado éEstrutura de geração de recuperação aprimorada (RAG)Uma implementação de alto nível da abordagem A abordagem visa aprimorar a consciência do contexto e a coerência das respostas geradas pela IA, mesclando contextos potencialmente fragmentados e menores em contextos maiores e mais abrangentes.
https://github.com/adithya-s-k/AI-Engineering.academy/tree/main/RAG/05_Auto_Merging_RAG
Motivação de fundo
Os sistemas tradicionais de geração de recuperação aumentada geralmente têm dificuldades para manter a coerência em contextos maiores ou apresentam um desempenho ruim ao lidar com informações que abrangem vários segmentos de texto. Os recuperadores de mesclagem automática abordam essa limitação mesclando recursivamente conjuntos de nós filhos que fazem referência a um nó pai que excede um limite específico, fornecendo assim um contexto mais abrangente e coerente no processo de recuperação e geração.
Detalhes metodológicos
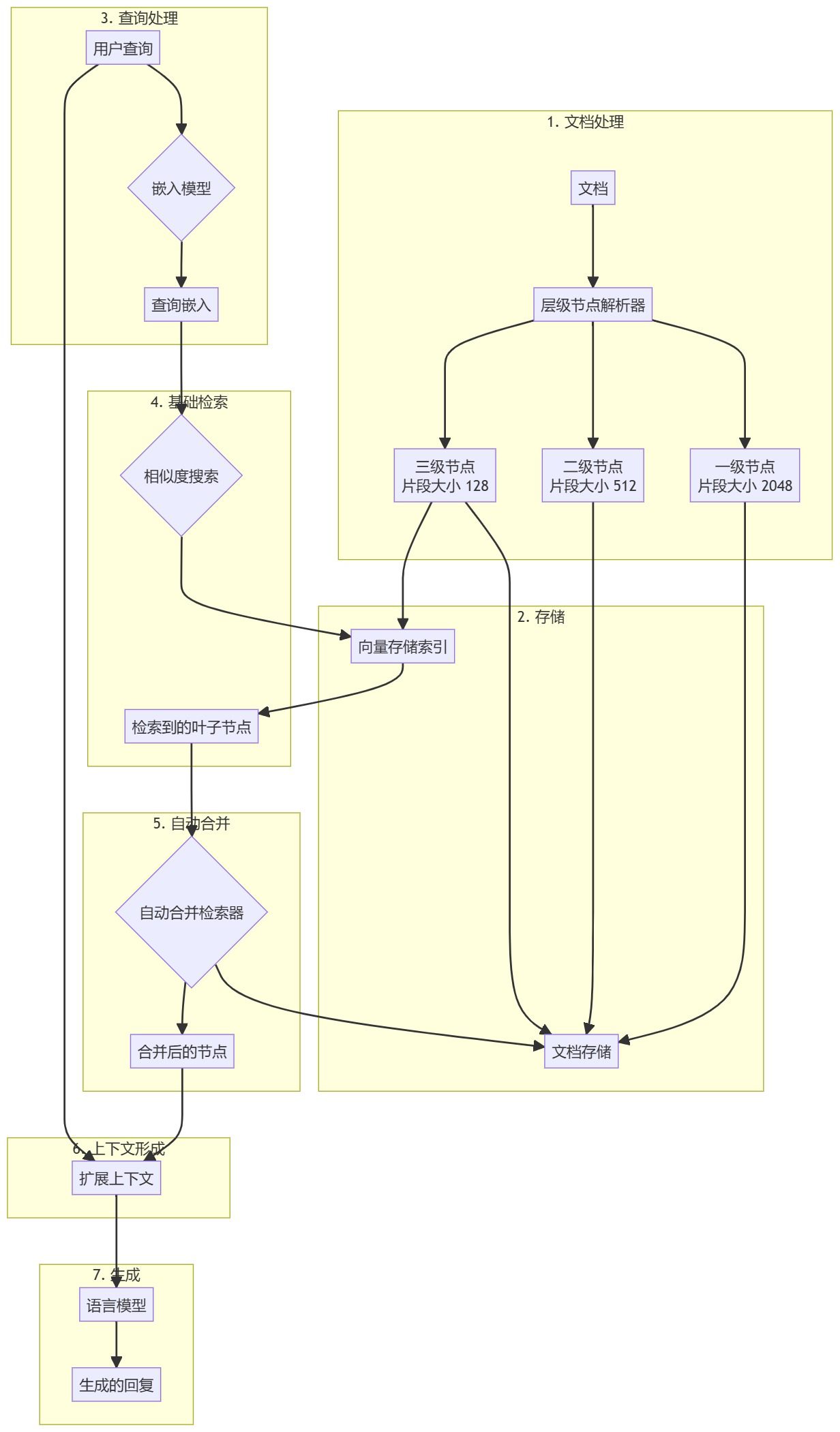
Pré-processamento de documentos e criação de hierarquias
- Carregamento de documentosCarregamento e processamento de documentos de entrada (por exemplo, arquivos PDF).
- resolução hierárquica: Uso
HierarchicalNodeParserCria uma hierarquia de nós a partir de um documento:- Nível 1: tamanho do bloco 2048
- Nível 2: tamanho do bloco 512
- Nível 3: Tamanho do bloco 128
- Armazenamento de nósArmazenamento de documentos: armazena todos os nós no armazenamento de documentos e os nós de folhas também são indexados no armazenamento de vetores.
Fluxo de trabalho de geração de pesquisa aprimorado
- Pré-processamento de consultasUse o mesmo modelo de incorporação dos blocos de documentos para processar as consultas dos usuários.
- Pesquisa básicaPesquisa de similaridade: O pesquisador de base realiza uma pesquisa de similaridade inicial para encontrar nós de folha relevantes.
- Mesclagem automática::
AutoMergingRetrieverO conjunto recuperado de nós folha é analisado e o subconjunto de nós folha que se refere ao nó pai além de um determinado limite é recursivamente "mesclado". - extensão de contexto (computação)Os nós mesclados formam um contexto estendido e são mesclados com a consulta original.
- Geração de uma respostaGerar respostas alimentando contextos de extensão e consultas no Large Language Model (LLM).
Principais recursos do pesquisador de mesclagem automatizado
- Representação hierárquica de documentosManter uma hierarquia de vários níveis de blocos de documentos.
- Pesquisa básica eficiente: Obtenção de recuperação de informações preliminares rápida e precisa usando pesquisas de similaridade de vetores.
- Extensão de contexto dinâmicoCombinação automática de blocos de texto relacionados em contextos maiores e mais coerentes.
- Realização flexívelPode ser usado para uma ampla variedade de tipos de documentos e modelos de linguagem.
Vantagens desse método
- Aumentar a coerência contextualFornecimento de um contexto mais coerente e completo para o modelo de linguagem mais amplo, mesclando partes relacionadas do texto.
- Adaptabilidade de pesquisa flexívelO processo de mesclagem se ajusta automaticamente à consulta e aos resultados da pesquisa para fornecer informações contextualmente relevantes.
- Estrutura de armazenamento eficienteImplementação rápida da recuperação básica de nós de folha, mantendo uma estrutura hierárquica.
- Possibilidade de melhorar a qualidade da respostaO contexto ampliado deve levar a respostas mais precisas e detalhadas do modelo de linguagem.
Resultados
Os resultados experimentais mostram que, comparando o pesquisador de mesclagem automática com o pesquisador de base:
- Desempenho semelhante nas métricas de correção, relevância, precisão e similaridade semântica.
- Nas comparações entre pares, 52,51 usuários doTP3T preferiram a resposta do pesquisador de mesclagem automática.
Esses resultados mostram que o desempenho do pesquisador de mesclagem automatizado é comparável aos métodos de pesquisa tradicionais, ou até ligeiramente superior a eles.
chegar a um veredicto
O pesquisador de mesclagem automatizado oferece um método avançado para aprimorar a RAG processo de recuperação no sistema. Ao mesclar dinamicamente blocos de texto relevantes em contextos maiores e mais coerentes, ele aborda algumas das limitações dos métodos tradicionais de recuperação baseados em blocos de texto. Embora os resultados iniciais mostrem perspectivas positivas, espera-se que mais pesquisas e otimizações melhorem significativamente a qualidade e a coerência das respostas.
pré-condições
Para implementar esse sistema, você precisará de:
- Um modelo de linguagem grande capaz de gerar texto (por exemplo, GPT-3.5-turbo, GPT-4).
- Um modelo de incorporação para converter blocos de texto e consultas em representações vetoriais.
- Bancos de dados vetoriais para pesquisa eficiente de similaridade (por exemplo, FAISS).
- Um armazenamento de documentos para armazenar a hierarquia de nós completa.
- oferta
LlamaIndexbiblioteca, que contémHierarchicalNodeParserresponder cantandoAutoMergingRetrieverRealização. - Recursos de computação suficientes para processar e armazenar grandes coleções de documentos.
- Familiaridade com a linguagem de programação Python para implementação e testes.
exemplo de uso
from llama_index.core import StorageContext, VectorStoreIndex
from llama_index.core.node_parser import HierarchicalNodeParser
from llama_index.core.retrievers import AutoMergingRetriever
# 将文档解析为节点层级
node_parser = HierarchicalNodeParser.from_defaults()
nodes = node_parser.get_nodes_from_documents(docs)
# 设置存储上下文
storage_context = StorageContext.from_defaults()
storage_context.docstore.add_documents(nodes)
# 创建基础索引和检索器
leaf_nodes = get_leaf_nodes(nodes)
base_index = VectorStoreIndex(leaf_nodes, storage_context=storage_context)
base_retriever = base_index.as_retriever(similarity_top_k=6)
# 创建自动合并检索器
retriever = AutoMergingRetriever(base_retriever, storage_context, verbose=True)
# 在查询引擎中使用自动合并检索器
query_engine = RetrieverQueryEngine.from_args(retriever)
response = query_engine.query(query_str)© declaração de direitos autorais
Direitos autorais do artigo Círculo de compartilhamento de IA A todos, favor não reproduzir sem permissão.
Artigos relacionados


Nenhum comentário...