
AI Engineering Academy: 2.1 Implementando o RAG do zero
delineado
Este guia o orientará na criação de uma geração simples de aprimoramento de pesquisa usando Python puro (RAG). Usaremos um modelo de incorporação e um modelo de linguagem ampla (LLM) para recuperar documentos relevantes e gerar respostas com base nas consultas do usuário.
https://github.com/adithya-s-k/AI-Engineering.academy/tree/main/RAG/00_RAG_from_Scratch
Etapas envolvidas
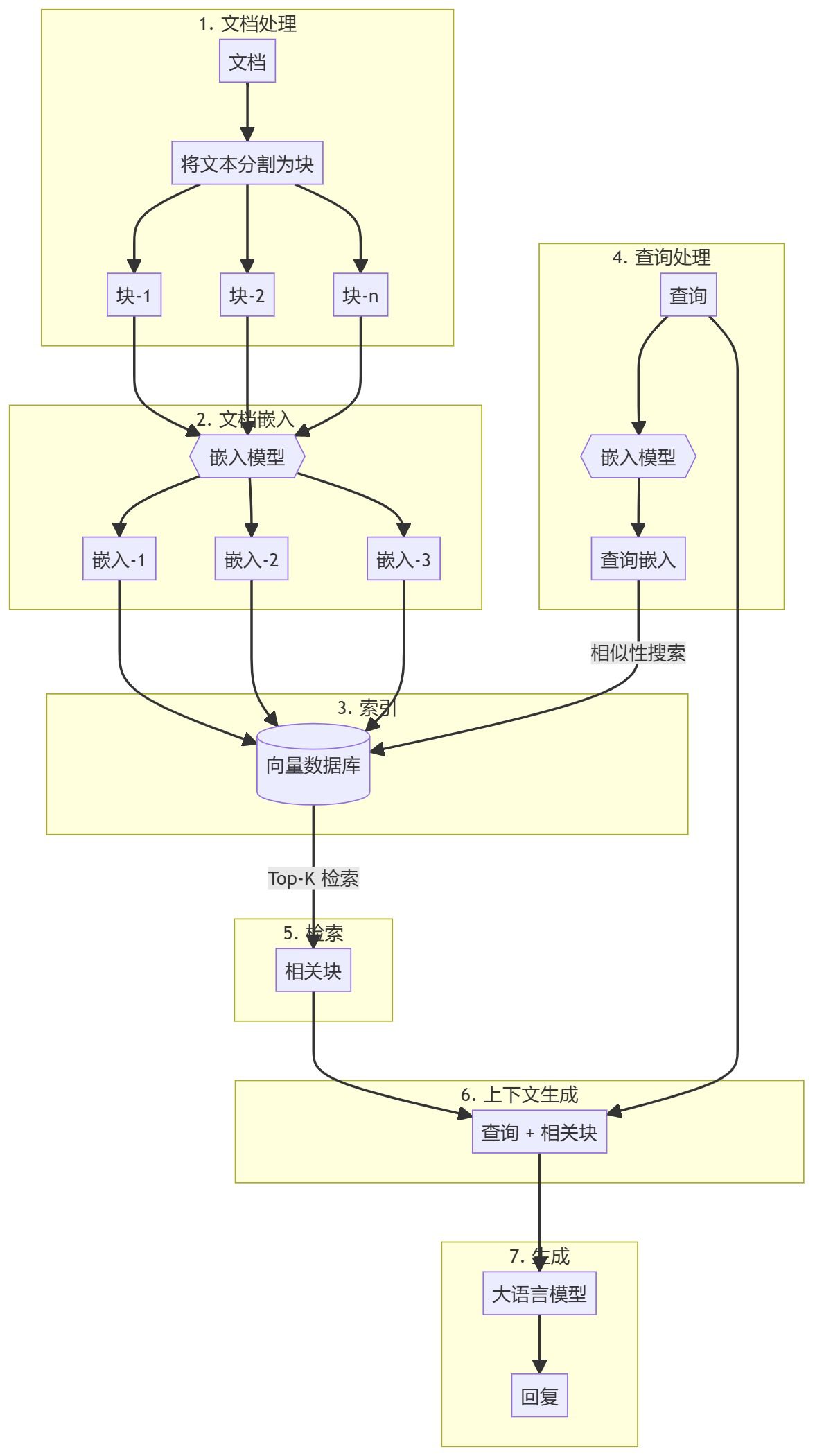
Todo o processo pode ser dividido em duas etapas principais:
- Criação da base de conhecimento
- parte gerada
Criação da base de conhecimento
Primeiro, você precisa preparar uma base de conhecimento (documentos, PDFs, páginas wiki). Esses são os dados básicos para o Modelo de Linguagem (LLM). O processo específico inclui:
- pedaçoQuebra de texto em pequenos pedaços de subdocumentos para simplificar o processamento.
- incorporaçãoCompute embeddings numéricos para cada bloco de subdocumento a fim de entender a similaridade semântica da consulta.
- estoqueArmazenamento: Armazene esses embeddings de forma a permitir uma recuperação rápida. Embora seja comum usar armazenamentos/bancos de dados de vetores, este tutorial mostra que isso não é necessário.
parte gerada
Quando uma consulta do usuário é inserida, uma incorporação é calculada para a consulta e os blocos de subdocumentos mais relevantes são recuperados da base de conhecimento. Esses blocos relevantes são anexados à consulta do usuário para formar um contexto e alimentam o LLM para gerar uma resposta.
1. configurações ambientais
Há alguns pacotes que precisam ser instalados antes que você possa começar.
sentence-transformersUsado para gerar embeddings para documentos e consultas.numpypara comparações de similaridade.scipy: para cálculos avançados de similaridade.wikipedia-apiUsado para carregar páginas da Wikipédia como bases de conhecimento.textwrapTexto de saída: Usado para formatar o texto de saída.
!pip install -q sentence-transformers
!pip install -q wikipedia-api
!pip install -q numpy
!pip install -q scipy
2. carregar o modelo de incorporação
Vamos carregar um modelo incorporado. Este tutorial usa o gte-base-en-v1.5.
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("Alibaba-NLP/gte-base-en-v1.5", trust_remote_code=True)
Sobre o modelo
gte-base-en-v1.5 Model é um modelo de inglês de código aberto fornecido pela equipe de NLP da Alibaba. Ele faz parte da família GTE (Generic Text Embedding), projetada para gerar embeddings de alta qualidade para uma variedade de tarefas de processamento de linguagem natural. O modelo é otimizado para capturar o significado semântico do texto em inglês e pode ser usado para tarefas como similaridade de frases, pesquisa semântica e agrupamento.trust_remote_code=True Os parâmetros permitem o uso de código personalizado associado ao modelo para garantir que ele funcione conforme o esperado.
3. obter conteúdo textual da Wikipedia e prepará-lo
- Um artigo da Wikipédia é carregado primeiro como uma base de conhecimento. O texto será dividido em partes gerenciáveis (subdocumentos), geralmente por parágrafos.
from wikipediaapi import Wikipedia wiki = Wikipedia('RAGBot/0.0', 'en') doc = wiki.page('Hayao_Miyazaki').text paragraphs = doc.split('\n\n') # 分块 - Embora existam muitas estratégias de fragmentação disponíveis, muitas delas podem não ser aplicáveis. É melhor verificar sua Base de Conhecimento (KB) para determinar a estratégia mais adequada. Neste exemplo, dividimos por parágrafo.
- Se quiser ver a aparência desses blocos, você pode importar o arquivo
textwrapbiblioteca e imprimi-lo parágrafo por parágrafo.import textwrap for i, p in enumerate(paragraphs): wrapped_text = textwrap.fill(p, width=100) print("-----------------------------------------------------------------") print(wrapped_text) print("-----------------------------------------------------------------") - Se o documento contiver imagens e tabelas, recomenda-se que elas sejam extraídas separadamente e incorporadas usando um modelo visual.
4. incorporação de documentos
- Em seguida, o modelo do modelo é criado chamando a função
encodeque recebe dados de texto (por exemploparagraphs) codificado como incorporado.docs_embed = model.encode(paragraphs, normalize_embeddings=True) - Esses embeddings são representações vetoriais densas do texto, capturando o significado semântico e permitindo que o modelo compreenda e processe o texto em uma forma matemática.
- Normalizamos a incorporação aqui.
- O que é normalização? A normalização é um processo de ajuste dos valores de incorporação para que tenham um paradigma de unidade (ou seja, um comprimento de vetor de 1).
- Por que normalizar? A incorporação normalizada garante que as distâncias entre os vetores reflitam principalmente as diferenças de direção e não de tamanho. Isso melhora o desempenho do modelo em tarefas de pesquisa de similaridade em que a "proximidade" ou "similaridade" entre os textos é comparada.
- no final
docs_embedé uma coleção de representações vetoriais de dados de texto, em que cada vetor corresponde aparagraphsUm parágrafo na lista. - fazer uso de
shapepara ver o número de blocos e a dimensão de cada vetor de incorporação (o tamanho do vetor de incorporação depende do tipo de modelo de incorporação).docs_embed.shape - Você também pode ver a aparência da incorporação real, que é um conjunto de valores normalizados.
docs_embed[0]
5. consultas de incorporação
Incorpore o exemplo de consulta do usuário de forma semelhante ao documento incorporado.
query = "What was Studio Ghibli's first film?"
query_embed = model.encode(query, normalize_embeddings=True)
Você pode verificar query_embed para confirmar a dimensão da consulta incorporada.
query_embed.shape
6. encontrar o parágrafo mais próximo da consulta
Uma das maneiras mais fáceis de recuperar as partes mais relevantes do conteúdo é calcular o produto escalar das incorporações de documentos e incorporações de consultas.
a. Cálculo do produto escalar
O produto escalar é uma operação matemática que multiplica e soma os elementos correspondentes de dois vetores (ou matrizes). Ele é frequentemente usado para medir a similaridade entre dois vetores.
(Observe que o produto escalar é calculado tomando-se o query_embed (transposição do vetor).
import numpy as np
similarities = np.dot(docs_embed, query_embed.T)
b. Compreender os produtos de pontos e suas formas
Matrizes NumPy de .shape retorna uma tupla que representa as dimensões da matriz.
similarities.shape
A forma esperada nesse código é a seguinte:
- no caso de
docs_embedtem a forma de (n_docs, n_dim):- n_docs é o número de documentos.
- n_dim é a dimensão incorporada em cada documento.
query_embed.Tterá a forma (n_dim, 1), pois estamos comparando com uma única consulta.- produto escalar
similaritiesA forma da matriz será (n_docs,), indicando que é uma matriz (vetor) unidimensional contendo n_docs elementos. Cada elemento representa a pontuação de similaridade entre a consulta e um determinado documento. - Por que verificar a forma? Garantir que a forma seja a esperada (n_docs,) confirma que o produto de pontos foi executado corretamente e que as pontuações de similaridade de cada documento foram calculadas corretamente.
Você pode imprimir similarities para verificar as pontuações de similaridade, em que cada valor corresponde a um resultado de produto de pontos:
print(similarities)
c. Interpretação do produto escalar
O produto escalar entre dois vetores (embeddings) mede sua similaridade: valores mais altos indicam maior similaridade entre a consulta e o documento. Se os embeddings forem normalizados, esses valores serão diretamente proporcionais à semelhança de cosseno entre os vetores. Se não forem normalizados, eles ainda indicarão a similaridade, mas também refletirão o tamanho da incorporação.
d. Identifique os 3 documentos mais semelhantes
Para encontrar os 3 documentos mais semelhantes com base em suas pontuações de similaridade, você pode usar o seguinte código:
top_3_idx = np.argsort(similarities, axis=0)[-3:][::-1].tolist()
- np.argsort(similarities, axis=0). Essa função emparelha o
similaritiesO índice da matriz é classificado. Por exemplo, sesimilarities = [0.1, 0.7, 0.4](matemática) gêneronp.argsortretornará[0, 2, 1]Os índices dos valores mínimo e máximo são 0 e 1, respectivamente. - [-3:]: Essa operação de divisão seleciona os 3 índices com as pontuações de similaridade mais altas (os últimos 3 elementos após a classificação).
- [::-1]: Essa operação inverte a ordem, de modo que o índice é classificado em ordem decrescente de similaridade.
- tolist(). Converte uma matriz indexada em uma lista Python. Resultado:
top_3_idxUm índice que contém os 3 documentos mais semelhantes, em ordem decrescente de semelhança.
e. Extração dos documentos mais semelhantes
most_similar_documents = [paragraphs[idx] for idx in top_3_idx]
- Derivativo de lista: Essa linha cria um arquivo chamado
most_similar_documentsA lista deparagraphsA lista correspondente aotop_3_idxO parágrafo real do índice. - parágrafos[idx]. com relação a
top_3_idxEssa operação recupera o parágrafo correspondente para cada índice no
f. Formatação e exibição dos documentos mais semelhantes
CONTEXT A variável é inicialmente inicializada com uma cadeia de caracteres vazia e, em seguida, será anexada ao texto de nova linha do documento mais semelhante em um loop de enumeração.
CONTEXT = ""
for i, p in enumerate(most_similar_documents):
wrapped_text = textwrap.fill(p, width=100)
print("-----------------------------------------------------------------")
print(wrapped_text)
print("-----------------------------------------------------------------")
CONTEXT += wrapped_text + "\n\n"
7. gerar uma resposta
Agora temos uma consulta e blocos de conteúdo relacionados que serão passados juntos para o Modelo de Linguagem Grande (LLM).
a. Declaração de busca
query = "What was Studio Ghibli's first film?"
b. Criar um prompt
prompt = f"""
use the following CONTEXT to answer the QUESTION at the end.
If you don't know the answer, just say that you don't know, don't try to make up an answer.
CONTEXT: {CONTEXT}
QUESTION: {query}
"""
c. Configurando o OpenAI
- Instale o OpenAI para acessar e usar o Modelo de Linguagem Grande (LLM).
!pip install -q openai - Habilite o acesso às chaves da API da OpenAI (pode ser definido em segredos no Google Colab).
from google.colab import userdata userdata.get('openai') import openai - Crie um cliente OpenAI.
from openai import OpenAI client = OpenAI(api_key=userdata.get('openai'))
d. Chamar a API para gerar uma resposta
response = client.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "user", "content": prompt},
]
)
- client.chat.completions.create. Esse método invoca um grande modelo de linguagem baseado em bate-papo para criar uma nova resposta (gerar).
- cliente. Representa um objeto cliente de API que se conecta a um serviço (neste caso, o OpenAI).
- chat.completions.create. Especifique que você está solicitando a criação de uma geração baseada em bate-papo.
Para obter mais informações sobre os parâmetros passados para o método
- model="gpt-4o". Especifica o modelo usado para gerar a resposta." gpt-4o" é uma variante específica do modelo GPT-4. Modelos diferentes podem ter comportamentos, métodos de ajuste fino ou recursos diferentes, portanto, especificar o modelo é importante para garantir que o resultado desejado seja obtido.
- mensagens. Esse parâmetro é uma lista de objetos de mensagem para representar o histórico do diálogo. Isso permite que o modelo compreenda o contexto do bate-papo. Neste exemplo, fornecemos apenas uma mensagem na lista:
{"role": "user", "content": prompt}. - função. "usuário" indica a função do remetente da mensagem, ou seja, o usuário que interage com o modelo.
- conteúdo. Contém o texto real da mensagem enviada pelo usuário. A variável prompt contém esse texto, que o modelo usará como entrada para gerar a resposta.
e. Com relação às respostas recebidas
Quando você faz uma solicitação a uma API como o modelo GPT da OpenAI para gerar uma resposta de bate-papo, a resposta geralmente é retornada em um formato estruturado, normalmente um dicionário.
Essa estrutura geralmente inclui:
- escolhas. Uma lista (matriz) que contém várias respostas possíveis geradas pelo modelo. Cada item dessa lista representa uma possível resposta ou conclusão.
- mensagem. Um objeto ou dicionário em cada seleção que contém o conteúdo real da mensagem gerada pelo modelo.
- conteúdo. O conteúdo textual da mensagem, ou seja, a resposta real ou a conclusão gerada pelo modelo.
f. Respostas impressas
print(response.choices[0].message.content)
Escolhemos choices O primeiro item da lista e, em seguida, acessando um dos message objeto. Por fim, acessamos o objeto message acertou em cheio content que contém o texto real gerado pelo modelo.
chegar a um veredicto
Isso completa nossa explicação sobre a criação de sistemas RAG a partir do zero. É altamente recomendável que você primeiro crie sua configuração inicial do RAG em Python puro para entender melhor como esses sistemas funcionam.
© declaração de direitos autorais
Direitos autorais do artigo Círculo de compartilhamento de IA A todos, favor não reproduzir sem permissão.
Artigos relacionados




Nenhum comentário...