A palavra "agente" é deprimente, os modelos GPT-4 não são mais dignos de menção e os grandes programadores fazem um balanço do "The Big Model 2024".

Os especialistas geralmente concordam que 2024 é o ano da AGI. Esse é o ano em que o grande setor de modelagem mudará para sempre:
O GPT-4 da OpenAI não está mais fora de alcance; o trabalho em modelos de geração de imagens e vídeos está se tornando cada vez mais realista; foram feitos avanços em modelos multimodais de linguagem ampla, modelos de inferência e inteligências (agentes); e os seres humanos estão se preocupando cada vez mais com a IA ......
Então, para um especialista experiente do setor, como o setor de modelos grandes mudou ao longo do ano?
Há alguns dias, o renomado programador independente, cofundador do diretório de conferências sociais Lanyrd e cocriador da estrutura da Web Django Simon Willison no relatório intitulado O que aprendemos sobre os LLMs em 2024 O artigo analisa em detalhes os Mudanças, surpresas e deficiências no setor de modelos grandes em 2024.

Alguns dos pontos são apresentados a seguir:
- Em 2023, treinar um modelo classificado como GPT-4 é uma grande coisa. No entanto, em 2024, essa não é uma conquista particularmente digna de nota.
- No último ano, obtivemos ganhos incríveis de desempenho em treinamento e inferência.
- Há dois fatores que estão fazendo os preços caírem: aumento da concorrência e ganhos de eficiência.
- Aqueles que reclamam do progresso lento do LLM tendem a ignorar os grandes avanços na modelagem multimodal.
- A geração de aplicativos orientados por prompt tornou-se uma commodity.
- Já se foram os dias de acesso gratuito aos modelos SOTA.
- Intelligentsia, ainda não nasceu de fato.
- Escrever boas avaliações automatizadas para sistemas orientados por LLM é a habilidade mais necessária para criar aplicativos úteis com base nesses modelos.
- o1 Principais novas abordagens para modelos estendidos: resolver problemas mais difíceis gastando mais computação em inferência.
- As regulamentações dos EUA sobre as exportações de GPUs chinesas parecem ter inspirado algumas otimizações de treinamento muito eficazes.
- Nos últimos anos, o consumo de energia e o impacto ambiental do funcionamento de um prompt foram significativamente reduzidos.
- Conteúdo não solicitado e sem censura gerado por inteligência artificial é "lixo".
- O segredo para tirar o máximo proveito do LLM é aprender a usar técnicas não confiáveis, mas poderosas.
- O LLM tem valor real, mas perceber esse valor não é intuitivo e requer orientação.
Sem alterar a essência geral do texto original, o conteúdo geral foi condensado da seguinte forma:
Muita coisa está acontecendo no campo da Modelagem de Linguagem Grande (LLM) em 2024. Aqui está uma retrospectiva do que descobrimos sobre o campo nos últimos 12 meses, juntamente com minhas tentativas de identificar os principais temas e momentos importantes. Incluindo 19 Aspectos:
1. o fosso do GPT-4 foi "violado".
Em minha avaliação de dezembro de 2023, escrevi: "Ainda não sabemos como construir o GPT-4.-- Na época, o GPT-4 havia sido lançado há quase um ano, mas outros laboratórios de IA ainda não haviam criado um modelo melhor.
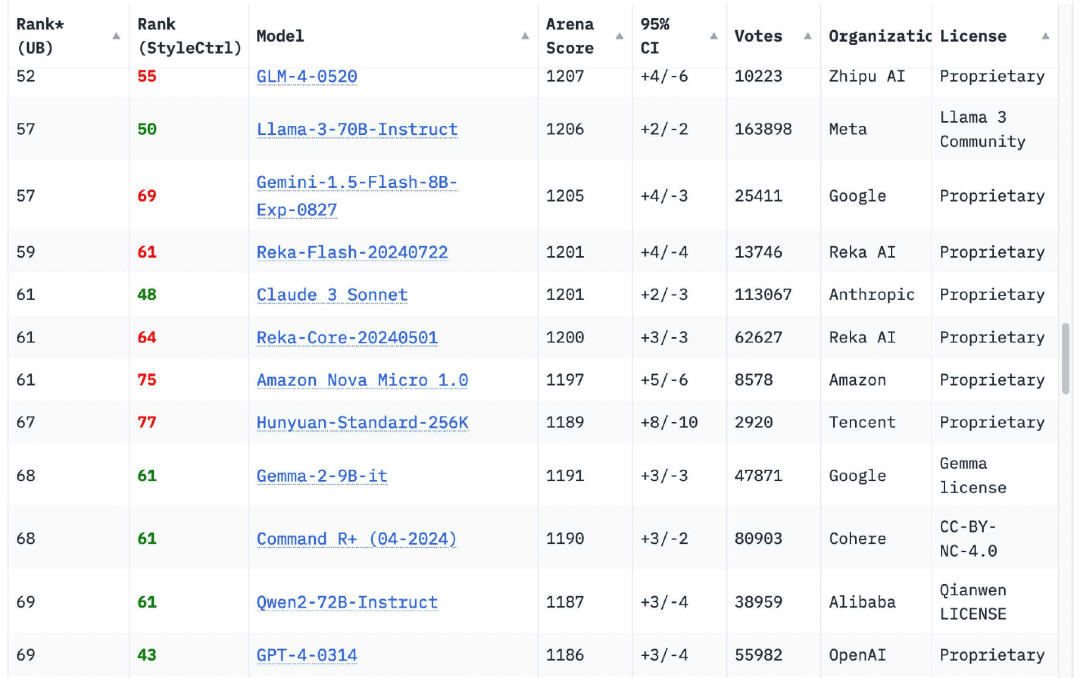
Para meu alívio, isso mudou completamente nos últimos 12 meses. A tabela de classificação do Chatbot Arena agora temModelos de 18 organizaçõesClassificado como superior à versão original do GPT-4 (GPT-4-0314) lançada em março de 2023, esse número chega a 70
O primeiro concorrente foi o lançamento do Google em fevereiro de 2024 do Gêmeos 1.5 Pro. Além de oferecer saída de nível GPT-4, ele traz vários novos recursos para o campo, entre eles oO mais notável é o comprimento do contexto de entrada de 1 milhão (posteriormente 2 milhões) de tokens e a capacidade de inserir vídeo.
O Gemini 1.5 Pro aciona um dos principais temas de 2024: aumentar a duração do contexto.Em 2023, a maioria dos modelos só poderá aceitar 4096 ou 8192 tokensJamahiriya Árabe Líbia Claude A exceção é o 2.1, que aceita 200.000 tokens. Atualmente, todos os provedores de modelos têm um modelo que aceita mais de 100.000 tokens. token modelo, a série Gemini do Google pode aceitar até 2 milhões de tokens.
Entradas mais longas aumentam muito a gama de problemas que podem ser resolvidos com o LLM: agora você pode digitar um livro inteiro e fazer perguntas sobre seu conteúdo, mas, mais importante, pode digitar uma grande quantidade de código de amostra para ajudar o modelo a resolver o problema de codificação corretamente. Para mim, os casos de uso de LLM que envolvem entradas longas são muito mais interessantes do que os prompts curtos que dependem puramente de informações sobre pesos de modelos. Muitas das minhas ferramentas são criadas usando esse modelo.
Passando para os modelos que "venceram" o GPT-4: a série Claude 3 da Anthropic foi lançada em março, e o Claude 3 Opus rapidamente se tornou meu modelo favorito. Em junho, eles lançaram o Claude 3.5 Sonnet e, seis meses depois, ele ainda é o meu favorito! Seis meses depois, ele ainda é o meu favorito.
É claro que há outros. Se você navegar pela tabela de classificação da Chatbot Arena hoje, verá que oGPT-4-0314 caiu para o 70º lugar.. As 18 organizações com altas pontuações de modelo são Google, OpenAI, Alibaba, Anthropic, Meta, Reka AI, Zero One Thing, Amazon, Cohere, DeepSeek, NVIDIA, Mistral, NexusFlow, Smart Spectrum, xAI, AI21 Labs, Princeton University e Tencent.
Treinar um modelo de nível GPT-4 em 2023 é uma grande coisa. No entanto, oEm 2024, essa não é nem mesmo uma conquista particularmente digna de notaMas eu, pessoalmente, ainda comemoro cada vez que uma nova organização entra na lista.
2. laptop, pronto para executar modelos de nível GPT-4
Meu laptop pessoal é um MacBook Pro 2023 M2 de 64 GB. É uma máquina potente, mas também tem quase dois anos de idade e, o que é mais importante, é o mesmo laptop que uso desde março de 2023, quando executei o LLM pela primeira vez em meu próprio computador.
Em março de 2023, esse laptop ainda será capaz de executar apenas um modelo de nível GPT-3O modelo GPT-4 agora é capaz de executar vários modelos de nível GPT-4!
Isso ainda me surpreende. Pensei que seria necessário um ou mais servidores de nível de datacenter com GPUs de mais de US$ 40.000 para alcançar a funcionalidade e a qualidade de saída do GPT-4.
Os modelos ocupam 64 GB de minha memória, portanto, não os executo com muita frequência, pois eles não deixam muito espaço para outras coisas.
O fato de eles funcionarem é uma prova dos incríveis ganhos de desempenho em treinamento e inferência que obtivemos no ano passado. Como se vê, colhemos muitos frutos visíveis em termos de eficiência do modelo. Espero que haja mais no futuro.
A série de modelos Llama 3.2 da Meta merece uma menção especial. Eles podem não ter a classificação GPT-4, mas nos tamanhos 1B e 3B, apresentam resultados que superam as expectativas.
3. os preços do LLM caíram significativamente devido à concorrência e aos ganhos de eficiência
Nos últimos doze meses, o custo de usar o LLM caiu drasticamente.
Dezembro de 2023, a OpenAI cobra US$ 30/milhão de tokens de entrada para o GPT-4(mTok) custosAlém disso, foi cobrada uma taxa de US$ 10/mTok para o então recém-introduzido GPT-4 Turbo e US$ 1/mTok para o GPT-3.5 Turbo.
Hoje, o modelo o1 mais caro da OpenAI está disponível por US$ 30/mTok!O GPT-4o custa US$ 2,50 (12 vezes mais barato que o GPT-4), e o GPT-4o mini custa US$ 0,15/mTok - quase sete vezes mais barato que o GPT-3.5 e mais potente.
Outros fornecedores de modelos cobram ainda menos, com o Claude 3 Haiku da Anthropic a US$ 0,25/mTok, o Gemini 1.5 Flash do Google a US$ 0,075/mTok e o Gemini 1.5 Flash 8B a US$ 0,0375/mTok, 27 vezes mais barato que o GPT-3.5 Turbo em 2023. Turbo em 2023.
Há dois fatores que estão fazendo os preços caírem: aumento da concorrência e ganhos de eficiência. As melhorias de eficiência são importantes para todos os que se preocupam com o impacto ambiental do LLM. Essas reduções de preço estão diretamente relacionadas à energia consumida para operar o equipamento.
Ainda há muito com que se preocupar em relação ao impacto ambiental da construção de data centers com IA, mas as preocupações com os custos de energia de prompts individuais não são mais confiáveis.
Vamos fazer um cálculo interessante: quanto custaria gerar descrições curtas para cada uma das 68.000 fotos em minha biblioteca pessoal de fotos usando o Gemini 1.5 Flash 8B mais barato do Google?
Cada foto requer 260 tokens de entrada e cerca de 100 tokens de saída.
260 * 68000 = 17680000 Digite o token
17680000 * $0,0375/milhão = $0,66
100 * 68000 = 6800.000 Token de saída
6800000 * US$ 0,15/milhão = US$ 1,02
O custo total para processar 68.000 imagens é de US$ 1,68. Foi tão barato que até fiz as contas três vezes para ter certeza de que estava certo.
Qual é a qualidade dessas descrições? Obtive as informações deste comando:
llm -m gemini-1.5-flash-8b-latest describe -a IMG_1825.jpeg
Esta é uma foto de uma borboleta da Academia de Ciências da Califórnia:

Há um prato raso vermelho na foto que pode ser um alimentador de beija-flor ou borboleta. O prato tem uma fatia de fruta laranja.
Há duas borboletas no comedouro, uma delas é marrom-escura/preta com marcas brancas/creme. A outra era uma borboleta marrom maior com marcas marrom-claro, bege e preto, incluindo manchas proeminentes nos olhos. Essa borboleta marrom maior parece estar comendo frutas de um prato.
260 tokens de entrada, 92 tokens de saída, a um custo de cerca de 0,0024 centavos (menos de 400 de um centavo).
O aumento da eficiência e os preços mais baixos são minhas tendências favoritas para 2024.Quero a utilidade do LLM com uma fração do custo de energia, e é exatamente isso que estamos conseguindo.
4. a visão multimodal se tornou comum, o áudio e o vídeo estão começando a "emergir
Meu exemplo de borboleta acima também ilustra outra tendência importante para 2024: o surgimento do MLLM (Multimodal Large Language Model).
O GPT-4 Vision, lançado há um ano no DevDay da OpenAI em novembro de 2023, é o exemplo mais notável disso. O Google, por outro lado, lançou o Gemini 1.0 multimodal em 7 de dezembro de 2023.
Em 2024, quase todos os fornecedores de modelos lançaram modelos multimodais.Nós o vimos em março. Antrópica s Claude 3 series, viu o Gemini 1.5 Pro (imagem, áudio e vídeo) em abril e, em setembro, viu o Mistral e os modelos visuais Llama 3.2 11B e 90B da Meta. Obtivemos entradas e saídas de áudio da OpenAI em outubro, SmolVLM da Hugging Face em novembro e modelos de imagem e vídeo da Amazon Nova em dezembro.
Acho que sim.Aqueles que reclamam do progresso lento dos LLMs tendem a ignorar os grandes avanços desses modelos multimodais. A capacidade de executar prompts em imagens (bem como em áudio e vídeo) é uma nova e fascinante maneira de aplicar esses modelos.
5. modos de voz e vídeo em tempo real para trazer a ficção científica para a realidade
Os modelos de áudio e vídeo em tempo real estão começando a surgir.
junto com ChatGPT O recurso de diálogo estreia em setembro de 2023, mas isso é em grande parte uma ilusão: a OpenAI usa seu excelente Sussurro modelo de conversão de fala em texto e um novo modelo de conversão de texto em fala (denominado tts-1) para permitir o diálogo com o ChatGPT, mas o modelo real só pode ver texto.
O GPT-4o da OpenAI, lançado em 13 de maio, inclui uma demonstração de um novo modelo de fala, o modelo GPT-4o ("o" significa "omni") verdadeiramente multimodal, que pode receber entrada de áudio e produzir uma fala incrivelmente e produzir uma fala incrivelmente realista sem a necessidade de um modelo TTS ou STT separado.
Quando o ChatGPT Advanced Voice Mode foi finalmente introduzido, os resultados foram surpreendentes.Costumo usar esse modo ao passear com meu cachorro e o tom melhorou tanto que é incrível!. Também me diverti muito usando a API de áudio OpenAI.
A OpenAI não é a única equipe com um modelo de áudio multimodal. O Gemini do Google também aceita entrada de áudio e também pode falar de maneira semelhante ao ChatGPT. A Amazon também anunciou um modelo de voz para o Amazon Nova antes do previsto, mas esse modelo estará disponível no primeiro trimestre de 2025.
Google NotebookLM Lançado em setembro, ele levou a saída de áudio a um novo patamar, com dois "apresentadores de podcast" que podiam ter conversas realistas sobre qualquer coisa que você digitasse e, posteriormente, adicionou comandos personalizados.
A nova alteração mais recente, também de dezembro, é o vídeo em tempo real. O modo de voz do ChatGPT agora oferece a opção de compartilhar imagens da câmera com modelos e falar sobre o que você está vendo em tempo real. O Gemini do Google também lançou uma versão prévia com os mesmos recursos.
6. geração de aplicativos orientados por prompt, que se tornou uma commodity
O GPT-4 já pode atingir esse objetivo em 2023, mas seu valor só se torna evidente em 2024.
O LLM é conhecido por ter um talento incrível para escrever códigos. Se você conseguir escrever um prompt corretamente, eles poderão criar um aplicativo interativo completo usando HTML, CSS e JavaScript, geralmente em um único prompt.
A Anthropic levou essa ideia para o próximo nível com o lançamento de Claude ArtifactsO Artifacts é um recurso novo e inovador. Com o Artifacts, o Claude pode escrever um aplicativo interativo sob demanda para você e, em seguida, permitir que você o use diretamente na interface do Claude.
Este é um aplicativo para extrair URLs, gerado inteiramente pelo Claude:
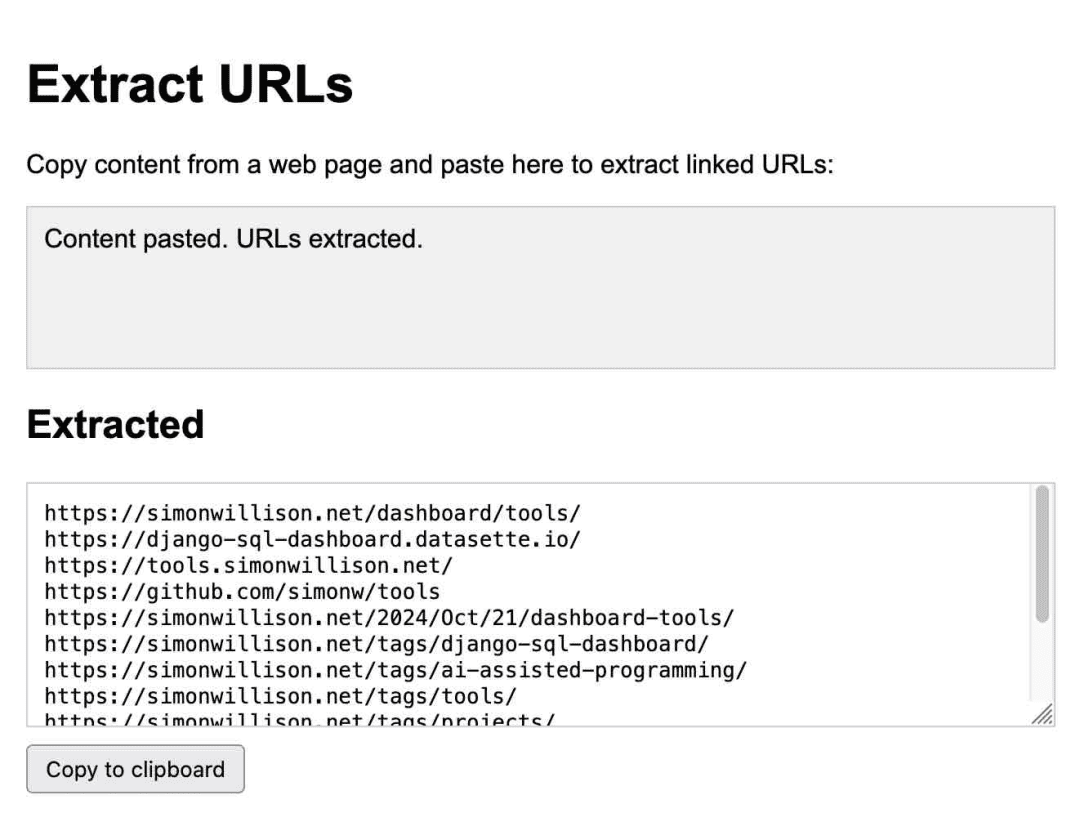
Eu o uso regularmente. Em outubro, percebi o quanto eu estava confiando nele, oCriei 14 gadgets em sete dias usando Artifacts!.

Desde então, várias outras equipes criaram sistemas semelhantes e, em outubro, o GitHub lançou sua versão, o GitHub Spark, e, em novembro, o Mistral Chat o adicionou como um recurso chamado Canvas.
Steve Krause, de Val Town, respondeu a Cerebras Uma versão foi criada para mostrar como o LLM com 2.000 tokens por segundo pode iterar o aplicativo e ver as alterações em menos de um segundo.
Em dezembro, a equipe do Chatbot Arena lançou uma nova tabela de classificação para esse recurso, em que os usuários criam o mesmo aplicativo interativo duas vezes usando dois modelos diferentes e votam nas respostas. Seria difícil apresentar um argumento mais convincente de que esse recurso agora é uma commodity que pode competir efetivamente com todos os modelos líderes.
Estive pensando nessa versão para o meu projeto Datasette, com o objetivo de permitir que os usuários usem o prompt para criar e iterar em gadgets personalizados e visualizar dados com base em seus próprios dados. Também encontrei um padrão semelhante para escrever programas Python únicos via uv.
Esse tipo de interface personalizada orientada por prompts é tão avançada e fácil de criar (depois que você descobre os meandros do sandboxing do navegador) que eu espero que ela apareça como um recurso em uma variedade de produtos até 2025.
7) Em apenas alguns meses, modelos poderosos foram popularizados
Em apenas alguns meses, em 2024, modelos avançados estarão disponíveis gratuitamente na maioria dos países do mundo.
A OpenAI disponibilizou o GPT-4o gratuitamente para todos os usuários em maio, enquanto o Claude 3.5 Sonnet foi disponibilizado gratuitamente com seu lançamento em junho. Essa é uma mudança significativa, já que, no ano passado, os usuários gratuitos só puderam usar modelos no nível GPT-3.5, o que, no passado, teria levado a uma falta de clareza para os novos usuários sobre os recursos reais do LLM.
Com o lançamento do ChatGPT Pro da OpenAI, essa era parece ter acabado, provavelmente de forma permanente!Essa assinatura de US$ 200/mês é a única maneira de acessar seu modelo mais potente, o o1 Pro. Esse serviço de assinatura de US$ 200/mês é a única maneira de acessar seu modelo mais potente, o o1 Pro.
A chave por trás da série o1 (e dos futuros modelos que, sem dúvida, a inspirarão) é gastar mais tempo de computação para obter melhores resultados. Sendo assim, acho que os dias de acesso gratuito aos modelos SOTA já se foram.
8. corpos inteligentes, ainda não nascidos de fato
Pessoalmente, acredito queA palavra "agente" é muito frustrante.. Ele não tem um significado único, claro e amplamente compreendido ...... Mas aqueles que usam o termo nunca parecem reconhecer isso.
Se você me disser que está construindo um "agente", então não está comunicando nada para mim. Sem ler sua mente, não tenho como saber de qual das dezenas de definições possíveis você está falando.
Há dois tipos principais de pessoas que eu vejoUm grupo pensa em um agente como obviamente algo que age em seu nome - um agente de viagem - e o outro pensa em um agente como um LLM com acesso a ferramentas que podem ser executadas em um loop como parte de um problema. O termo "autonomia" também é muito usado, mas, mais uma vez, não há uma definição clara. (Há alguns meses, cheguei a postar no Twitter uma coleção de 211 definições de agente, e pedi a gemini-exp-1206 que tentasse resumi-las).
Qualquer que seja o significado do termo.Agente, ainda há uma sensação perpétua de "em breve".. Terminologia à parte.Ainda estou cético quanto à sua praticidadeEsse é um desafio baseado na credulidade: os LLMs acreditarão em tudo o que você disser a eles. Qualquer sistema que tente tomar decisões significativas em seu nome esbarra no mesmo obstáculo: qual é a utilidade de um agente de viagens, de um assistente digital ou até mesmo de uma ferramenta de pesquisa se ele não consegue distinguir entre o que é verdadeiro e o que é falso?
Há poucos dias, foi encontrada em uma pesquisa do Google uma descrição completamente falsa do filme inexistente Encanto 2.
A injeção oportuna é uma consequência natural dessa ingenuidade. Vejo muito pouco progresso em 2024 na abordagem dessa questão, que estamos discutindo desde setembro de 2022
Os ataques de injeção imediata são uma consequência natural dessa "ingenuidade". Vejo pouco progresso no setor em 2024 para tratar desse problema, que estamos discutindo desde setembro de 2022.
Estou começando a pensar que o conceito de agente mais popular dependerá da AGI.Criar modelos resistentes à "credulidade" é, de fato, uma tarefa difícil!.
9. avaliação, muito importante
Amanda Askell, da Anthropic (para a Claude's). Caráter a maior parte do trabalho por trás dele) havia dito:
Há um segredo chato, mas vital, por trás de um bom prompt do sistema: o desenvolvimento orientado por testes. Você não escreve um prompt do sistema e depois descobre como testá-lo. Você escreve testes e depois encontra um prompt do sistema que passa nesses testes. Você escreve testes e, em seguida, encontra um prompt do sistema que passa nesses testes.
No decorrer de 2024, ficou bastante claro que aEscreva excelentes avaliações automáticas para sistemas orientados por LLMA avaliação de desempenho é a habilidade mais necessária para criar aplicativos úteis com base nesses modelos. Se você tiver um conjunto de avaliação sólido, poderá adotar novos modelos mais rapidamente do que seus concorrentes, iterar melhor e criar recursos de produto mais confiáveis e úteis.
Malte Ubl, diretor de tecnologia da Vercel, acredita que:
Quando a v0 (um agente de desenvolvimento da Web) foi apresentada pela primeira vez, estávamos paranoicos quanto à proteção de prompts com todos os tipos de pré-processamento e pós-processamento complexos.
Nós nos voltamos completamente para deixá-lo correr livremente. Nenhuma avaliação, modelagem e, principalmente, as solicitações de UX são como uma máquina ASML quebrada sem instruções.
Ainda estou tentando encontrar um modelo melhor para o meu próprio trabalho. Todo mundo sabe que as avaliações são importantes, mas para oAinda não há uma boa orientação sobre a melhor forma de realizar a avaliação.
10. O Apple Intelligence é péssimo, mas o MLX é ótimo!
Como usuário de Mac, sinto-me muito melhor em relação à plataforma que escolhi.
Em 2023, sinto que não tenho uma máquina Linux/Windows com uma GPU NVIDIA, o que é uma grande desvantagem para eu experimentar novos modelos.
Em teoria, um Mac de 64 GB deve ser uma boa máquina para executar modelos porque a CPU e a GPU podem compartilhar a mesma quantidade de memória. Na prática, muitos modelos são publicados como pesos e bibliotecas de modelos, sendo que o CUDA da NVIDIA é preferido em relação a outras plataformas.
llama.cpp O ecossistema ajudou muito com isso, mas o verdadeiro avanço foi a biblioteca MLX da Apple, que é fantástica.
O suporte a Python mlx-lm da Apple executa uma variedade de modelos compatíveis com mlx no meu Mac com excelente desempenho. A comunidade mlx no Hugging Face fornece mais de 1.000 modelos que foram convertidos para os formatos necessários. O projeto mlx-vlm do príncipe Canuma é excelente e está avançando rapidamente, além de trazer LLMs visuais para a Apple O projeto mlx-vlm do príncipe Canuma é excelente e está progredindo rapidamente, além de trazer o LLM visual para o Apple Silicon.
Embora o MLX tenha sido um divisor de águas, os recursos do Apple Intelligence da Apple foram, em sua maioria, decepcionantes. Escrevi um artigo sobre seu lançamento inicial em junho e, na época, estava otimista quanto ao fato de a Apple ter se concentrado em proteger a privacidade do usuário e minimizar a possibilidade de os usuários serem enganados sobre os aplicativos LLM.
Agora que esses recursos estão disponíveis, eles ainda são relativamente ineficazes. Como um grande usuário do LLM, sei do que esses modelos são capazes, e os recursos do LLM da Apple são apenas uma pálida imitação dos recursos de ponta do LLM. Em vez disso, recebemos resumos de notificações que distorcem as manchetes das notícias, e nem sequer acho que a ferramenta Assistente de Redação seja útil. Ainda assim, o Genmoji é muito divertido.
11. escala de inferência, o surgimento de modelos de "raciocínio"
O desenvolvimento mais interessante no último trimestre de 2024 foi o surgimento de uma nova morfologia LLM, exemplificada pelos modelos o1 da OpenAI - o1-preview e o1-mini foram lançados em 12 de setembro. Uma maneira de pensar sobre esses modelos é como uma extensão da técnica de prompt de cadeia de pensamento.
O truque é principalmente queSe você fizer com que um modelo pense bastante (fale em voz alta) sobre o problema que está resolvendo, geralmente obterá um resultado que o modelo não conseguiria obter de outra forma.
A o1 incorpora esse processo ainda mais no modelo. Os detalhes são um pouco confusos: o modelo o1 gasta "tokens de raciocínio" para pensar sobre o problema, o que o usuário não pode ver diretamente (embora a interface do usuário do ChatGPT mostre um resumo) e, em seguida, produz o resultado final.
A maior inovação aqui é o fato de abrir uma nova maneira de estender o modelo: os modelos agora podem resolver problemas mais difíceis gastando mais esforço computacional na inferência, oEm vez de melhorar o desempenho do modelo apenas aumentando a quantidade de computação no momento do treinamento.
O sucessor do o1, o o3, foi lançado em 20 de dezembro e obteve resultados impressionantes nos benchmarks ARC-AGI, apesar do fato de que pode ter havido mais de US$ 1 milhão em custos de tempo computacional envolvidos!
Espera-se que o o3 seja lançado em janeiro. Duvido que haja muitas pessoas com problemas reais que se beneficiariam desse nível de gasto com computação, eu certamente não tenho! Mas parece ser um próximo passo real na arquitetura do LLM para resolver problemas mais difíceis.
A OpenAI não é a única participante; em 19 de dezembro, o Google lançou seu primeiro participante nesse espaço, o gemini-2.0-flash-thinking-exp.
A equipe Qwen da Alibaba lançou o modelo QwQ em 28 de novembro sob a licença Apache 2.0. Em seguida, eles lançaram um modelo de inferência visual chamado QvQ em 24 de dezembro.
DeepSeek O modelo DeepSeek-R1-Lite-Preview foi disponibilizado para teste por meio da interface de bate-papo em 20 de novembro.
Nota do editor: O Wisdom Spectrum também foi lançado no último dia de 2024Modelos de raciocínio profundo GLM-Zero.
O Anthropic e o Meta ainda não fizeram nenhum progresso, mas eu ficaria muito surpreso se eles não tivessem seu próprio modelo de extensão de inferência.
12) O melhor LLM atualmente é formado na China??
Não exatamente, mas quase! É um ótimo título que chama a atenção.
O DeepSeek v3 é um modelo paramétrico enorme de 685 B - um dos maiores modelos licenciados publicamente disponíveis e muito maior do que o maior da família Llama da Meta, o Llama 3.1 405 B.
Os benchmarks mostram que ele está no mesmo nível do Claude 3.5 Sonnet, e os benchmarks do Vibe o classificam atualmente em 7º lugar, atrás dos modelos Gemini 2.0 e OpenAI 4o/o1. Esse é o modelo licenciado publicamente mais bem classificado até o momento.
O que é realmente impressionante é queDeepSeek v3Custos de treinamentoO modelo foi treinado em 2788000 horas de GPU H800 a um custo estimado de US$ 5576000. O modelo foi treinado em 2788.000 horas de GPU H800 a um custo estimado de US$ 5576.000. O Llama 3.1 405B foi treinado em 30840000 horas de GPU, 11 vezes mais do que o DeepSeek v3, mas o desempenho de linha de base do modelo foi um pouco pior.
As regulamentações dos EUA sobre as exportações de GPUs chinesas parecem ter inspirado algumas otimizações de treinamento muito eficazes.
13. os impactos ambientais dos prompts operacionais foram aprimorados.
Quer seja um modelo hospedado ou um que eu execute localmente, um dos resultados bem-vindos do aumento da eficiência é que o consumo de energia e o impacto ambiental da execução do prompt foram bastante reduzidos nos últimos anos.
As cobranças imediatas da OpenAI são 100 vezes menores do que as da GPT-3 na época.Sei de fonte segura que nem o Google Gemini nem o Amazon Nova (os dois provedores de modelos mais baratos) estão operando prontamente com prejuízo.
Isso significa que, como usuários individuais, não precisamos nos sentir culpados pela energia consumida pela grande maioria dos prompts. Em comparação com dirigir pela rua ou até mesmo assistir a um vídeo no YouTube, o impacto pode ser insignificante.
O mesmo vale para o treinamento. O deepSeek v3 custa menos de US$ 6 milhões para ser treinado, o que é um ótimo sinal de que os custos de treinamento podem e devem continuar a cair.
14. novos data centers, eles ainda são necessários?
E a questão mais importante é que haverá uma pressão competitiva significativa para construir a infraestrutura de que esses modelos precisarão no futuro.
Empresas como Google, Meta, Microsoft e Amazon estão gastando bilhões de dólares em novos data centers, o que está causando um enorme impacto na rede elétrica e no meio ambiente. Fala-se até mesmo na construção de novas usinas nucleares, mas isso levará décadas.
A infraestrutura é necessária? O custo de treinamento de US$ 6 milhões do DeepSeek v3 e a redução contínua dos preços do LLM podem ser suficientes para justificar esse argumento. Mas você gostaria de ser o grande executivo da área de tecnologia que argumentou contra essa infraestrutura e que, alguns anos depois, provou estar errado?
Um contraste interessante é o desenvolvimento de ferrovias em todo o mundo no século XIX. A construção dessas ferrovias exigiu grandes investimentos, causou um enorme impacto no meio ambiente e muitas das linhas construídas se mostraram desnecessárias.
As bolhas resultantes levaram a vários colapsos financeiros e nos deixaram com uma grande quantidade de infraestrutura útil, bem como uma grande quantidade de falência e destruição ambiental.
15.2024, o ano do "slop"
2024 é o ano em que a palavra "slop" se tornará um termo de arte. @deepfates escreveu no Twitter:
Assim como "spam" se tornou o nome próprio para e-mails indesejados, "slop" aparecerá no dicionário como o nome próprio para conteúdo indesejado gerado por IA.
Escrevi uma postagem em maio que expandia um pouco essa definição:
"Slop" refere-se a conteúdo não solicitado e sem censura gerado por inteligência artificial.
Gosto da palavra "slop" porque ela resume de forma sucinta uma maneira pela qual não devemos usar a IA generativa!
16. dados de treinamento sintéticos, muito eficazes
Surpreendentemente, a noção de "colapso do modelo", ou seja, de que os modelos de IA quebram quando treinados em dados gerados recursivamente, parece estar profundamente enraizada na consciência pública. .
A ideia é sedutora: à medida que o "lixo" gerado pela IA inunda a Internet, os próprios modelos se degradarão, alimentando-se de sua própria produção e levando ao seu inevitável fim!
Obviamente, isso não aconteceu. Em vez disso, estamos vendo os laboratórios de IA treinarem cada vez mais com conteúdo sintético, criando dados artificiais que ajudam a orientar seus modelos na direção certa.
Uma das melhores descrições que já vi vem do relatório técnico do Phi-4A seguir, alguns dos elementos do programa:
Os dados sintéticos estão se tornando mais comuns como uma parte importante do pré-treinamento, e a família de modelos Phi sempre enfatizou a importância dos dados sintéticos. Em vez de ser uma alternativa barata aos dados reais, os dados sintéticos têm várias vantagens diretas sobre os dados reais.
Aprendizagem progressiva estruturada. Em conjuntos de dados reais, as relações entre tokens geralmente são complexas e indiretas. Muitas etapas de inferência podem ser necessárias para associar o token atual ao próximo token, dificultando que o modelo aprenda efetivamente com a previsão do próximo token. Em contrapartida, cada token gerado por um modelo de linguagem é previsto pelo token anterior, o que facilita para o modelo seguir o padrão de inferência resultante.
Outra técnica comum é usar modelos maiores para ajudar a criar dados de treinamento para modelos menores e mais baratos, e cada vez mais laboratórios estão usando essa técnica.
O DeepSeek v3 usa DeepSeek-R1 Dados de "inferência" criados. O ajuste fino do Meta Llama 3.3 70B usa mais de 25 milhões de exemplos gerados sinteticamente.
O design cuidadoso dos dados de treinamento usados para o LLM parece ser a chave para a criação desses modelos. Já se foram os dias em que se pegava todos os dados da Web e os alimentava indiscriminadamente nas execuções de treinamento.
17. usar o LLM corretamente não é fácil!
Sempre enfatizei que os LLMs são ferramentas poderosas para o usuário - são motosserras disfarçadas de helicópteros. Eles parecem fáceis de usar - quão difícil pode ser digitar uma mensagem para um chatbot? Mas na realidade.Para aproveitá-las ao máximo e evitar suas muitas armadilhas, você precisa ter um conhecimento profundo e muita experiência com elas.
Esse problema se torna ainda pior em 2024.
Criamos sistemas de computador com os quais é possível falar em linguagem humana e que podem responder às suas perguntas, e geralmente acertam! ...... Depende de qual é a pergunta, como ela é feita e se ela pode ser refletida com precisão em um conjunto de treinamento secreto não registrado.
Atualmente, o número de sistemas disponíveis está se proliferando. Sistemas diferentes têm ferramentas diferentes que podem ser usadas para resolver seu problema, como Python, JavaScript, pesquisa na Web, geração de imagens e até mesmo consultas a bancos de dados ...... Portanto, é melhor você entender o que são essas ferramentas, o que elas podem fazer e como saber se o LLM as está usando.
Você sabia que o ChatGPT agora tem duas maneiras completamente diferentes de executar o Python?
Se você quiser criar um artefato do Claude que se comunique com uma API externa, é uma boa ideia aprender sobre os cabeçalhos HTTP CSP e CORS.
Os recursos desses modelos podem ter melhorado, mas a maioria das limitações permanece. O o1 da OpenAI pode finalmente ser capaz de computar (em grande parte) o "r" em strawberry, mas seus recursos ainda são limitados por sua natureza de LLM e por seus recursos de tempo de execução. o1 não pode fazer pesquisas na Web nem usar um interpretador de código, mas o GPT-4o pode - ambos estão na mesma interface do usuário do ChatGPT. GPT-4o pode - ambos estão na mesma UI do ChatGPT.
O que fizemos a respeito? Nada. A maioria dos usuários são "novatos". A interface padrão de bate-papo do LLM é como jogar usuários de computador novatos em um terminal Linux e esperar que eles cuidem de tudo sozinhos.
Ao mesmo tempo, está se tornando cada vez mais comum que os usuários finais desenvolvam modelos mentais imprecisos de como esses dispositivos funcionam e operam. Já vi muitos exemplos disso, com pessoas tentando ganhar discussões com capturas de tela do ChatGPT - o que é uma proposta inerentemente ridícula, dada a falta de confiabilidade inerente a esses modelos, juntamente com o fato de que é possível fazer com que eles digam qualquer coisa se você der o comando certo.
Há um outro lado: muitos "veteranos" desistiram completamente do LLM porque não veem como alguém pode se beneficiar de uma ferramenta que tem tantas falhas. A chave para obter o máximo do LLM é aprender a usar essa técnica não confiável, mas poderosa. É claro que essa não é uma habilidade óbvia!
Embora exista muito conteúdo educacional útil por aí, precisamos fazer um trabalho melhor do que terceirizar tudo isso para os representantes de IA que tuitam furiosamente.
18. cognição deficiente, ainda presente
Agora.A maioria das pessoas já ouviu falar do ChatGPT, mas quantas já ouviram falar do Claude?
Entre os que se preocupam ativamente com essas questões e os que não se preocupam, há umaA grande divisão do conhecimento.
No mês passado, vimos a popularidade das interfaces em tempo real, nas quais é possível apontar a câmera do telefone para algo e falar sobre isso com sua voz ...... Há também a opção de fazer com que ele finja ser o Papai Noel. A maioria das pessoas autocertificadas (sic "nerd") ainda não experimentou.
Considerando o impacto contínuo (e potencial) dessa tecnologia na sociedade, acho que a atualEssa divisão não é saudável. Eu gostaria de ver mais esforços para melhorar a situação.
19.LLM, é preciso uma crítica melhor
Muitas pessoas realmente odeiam o LLM. Em alguns dos sites que frequento, até mesmo a sugestão de que "o LLM é muito útil" é suficiente para iniciar uma guerra.
Eu entendo. Há muitos motivos pelos quais as pessoas não gostam dessa tecnologia: impacto ambiental, falta de confiabilidade dos dados de treinamento, aplicações não positivas, impacto potencial no trabalho das pessoas.
O LLM definitivamente merece críticas.Precisamos discutir essas questões, encontrar maneiras de atenuá-las e ajudar as pessoas a aprender a usar essas ferramentas de forma responsável para que suas aplicações positivas superem seus impactos negativos.
Adoro pessoas que são céticas em relação a essa tecnologia. Há mais de dois anos, o hype tem crescido e muita desinformação tem inundado as ondas de rádio. Muitas decisões ruins foram tomadas com base nesse hype.A crítica é uma virtude.
Se quisermos que as pessoas com poder de decisão tomem as decisões corretas sobre como aplicar essas ferramentas, primeiro precisamos reconhecer que existem, de fato, boas aplicações e, em seguida, ajudar a explicar como colocá-las em prática, evitando muitas das armadilhas não práticas.
Acho que sim.Dizer às pessoas que todo o campo é uma máquina de plágio ambientalmente desastrosa que constantemente inventa coisas, não importa o quanto isso represente de verdade, é um desserviço a essas pessoas.. Há um valor real aqui, mas perceber esse valor não é intuitivo e requer orientação.
Aqueles de nós que entendem desse assunto têm a responsabilidade de ajudar os outros a entender.
© declaração de direitos autorais
Direitos autorais do artigo Círculo de compartilhamento de IA A todos, favor não reproduzir sem permissão.
Artigos relacionados




Nenhum comentário...