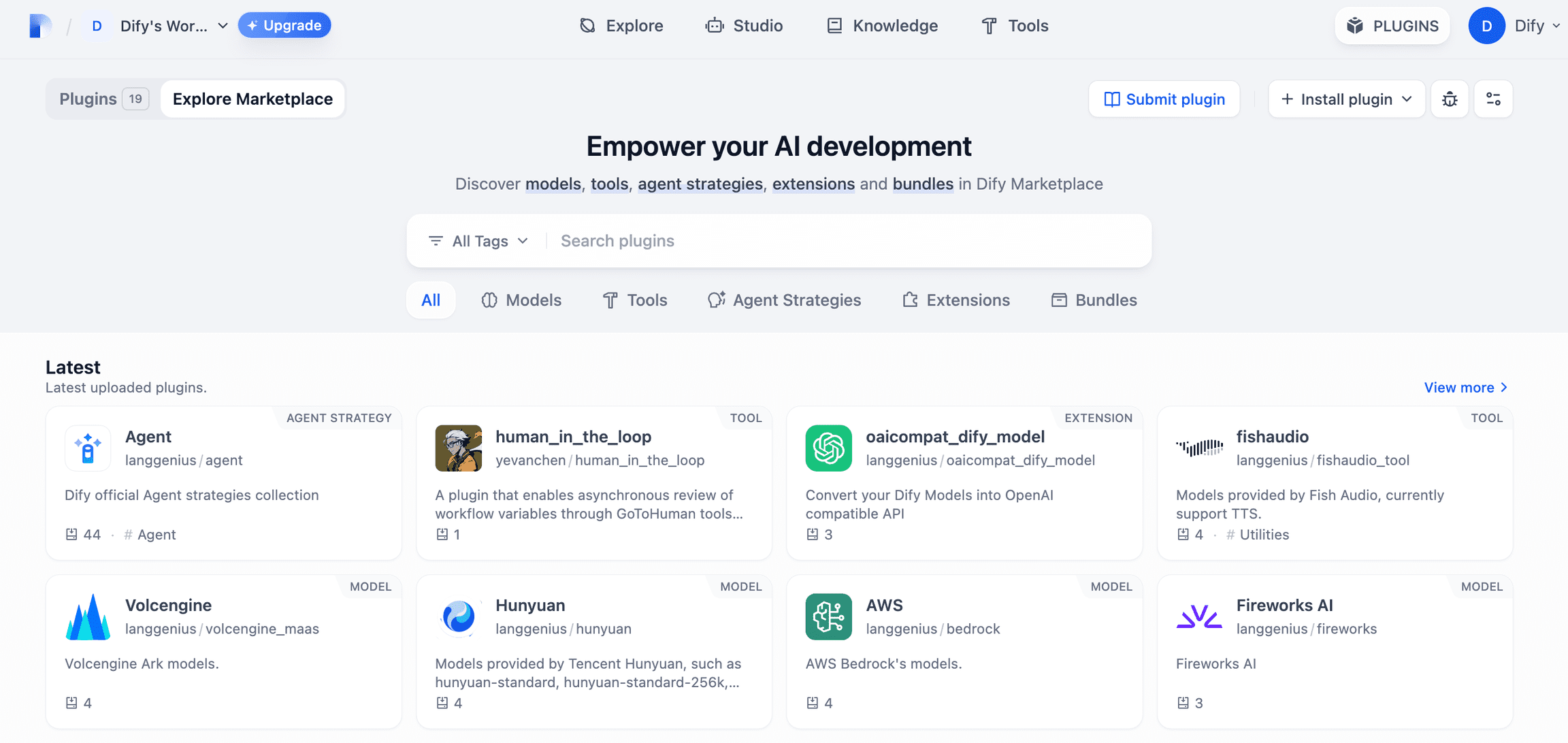
Relatório de benchmarking de modelos grandes chineses de 2024 (SuperCLUE)

contextos
Desde 2023, os Grandes Modelos de IA têm criado a maior onda de IA já vista em escala global. À medida que entramos em 2024, a dinâmica competitiva do Big Model global está aumentando eCom o lançamento do Sora, do GPT-4o e do o1, os modelos grandes nacionais tiveram uma grande perseguição de modelos grandes em 2024.

O benchmark de avaliação de grandes modelos chineses, SuperCLUE, tem monitorado continuamente a tendência de desenvolvimento e o efeito abrangente de grandes modelos no país e no exterior em tempo real, e foi oficialmente lançado.Relatório anual do Benchmarking de modelos grandes chineses 2024.
O relatório completo tem 89 páginas, este artigo mostra apenas o conteúdo principal do relatório, o endereço on-line do relatório completo (para download):
www.cluebenchmarks.com/superclue_2024
Endereço do SuperCLUE Leaderboard:
www.superclueai.com
Principais elementos do relatório
Componente-chave 1: Panorama dos grandes modelos mais notáveis para 2024

Componente-chave 2: Classificação geral anual e quadrante de modelagem
Introdução à avaliação
Este relatório anual se concentra na Avaliação de Competência Geral, que consiste em três dimensões: Ciências, Artes e Hard.As perguntas são todas novas e originaiscom um total de 1.325 perguntas de resposta curta em várias rodadas.
[Tarefas científicas] é dividido em conjuntos de computação, raciocínio lógico e avaliação de código; [Tarefas artísticas] é dividido em conjuntos de compreensão de linguagem, criação generativa e avaliação de segurança; e [Tarefas difíceis] é dividido em conjuntos de acompanhamento de instruções, raciocínio profundo e avaliação de agentes.

Os dados dessa avaliação são selecionados a partir dos resultados da avaliação de dezembro da SuperCLUE, e o modelo é selecionado a partir dos 42 modelos representativos de grande porte no país e no exterior na versão de dezembro.

tabela de classificação

Quadrante do modelo anual

Elemento-chave 3: Distribuição de zonas com boa relação custo-benefício

Os modelos domésticos de grande porte têm uma grande vantagem em termos de relação preço/desempenho (preço + eficácia)
Os modelos nacionais de grande porte, como o DeepSeek-V3, o Qwen2.5-72B-Instruct e o Qwen2.5-32B-Instruct, demonstram grande competitividade em termos de relação preço/desempenho. Com base em um nível relativamente alto de capacidade, é possível manter um custo de aplicação muito baixo, na aplicação de aterrissagem para mostrar uma usabilidade amigável.
A maioria dos modelos está na faixa de custo-benefício médio
A maioria dos modelos ainda está em um ponto de preço alto para manter um alto nível de capacidade. Por exemplo, o GLM-4-Plus, o Qwen-Max-latest, o Claude 3.5 Sonnet e o Grok-2-1212 têm preços acima de US$ 30 por milhão de tokens.
o1 e outros modelos de inferência a relação custo-benefício ainda tem muito espaço para otimização
Embora o o1 e o1-preview apresentem um alto nível de capacidade, eles são várias vezes mais caros do que outros modelos em termos de preço. Como reduzir o custo pode se tornar um pré-requisito para o uso generalizado de modelos de inferência.
Componente-chave 4: raciocínio sobre a distribuição dos intervalos de eficiência

Alguns modelos domésticos são competitivos em termos de eficácia geral
Entre os modelos nacionais, o DeepSeek-V3 e o Qwen2.5-32B-Instruct têm excelentes velocidades de inferência, com um tempo médio de inferência de menos de 10s por pergunta e, ao mesmo tempo, as pontuações de benchmark estão acima de 60, o que está de acordo com a "zona de alto desempenho" e mostra uma eficácia muito forte do aplicativo.
Gemini-2.0-Flash-Exp é líder mundial em desempenho de aplicativos de modelo grande
Os modelos estrangeiros Gemini-2.0-Flash-Exp, Claude 3.5 Sonnet (20241022), Grok-2-1212 e GPT-4o-mini se qualificam para a "zona de alto desempenho", sendo que o Gemini-2.0-Flash-Exp tem o melhor desempenho em termos de eficácia combinada em termos de tempo de inferência e pontuação de benchmark. O GPT-4o-mini tem o melhor desempenho em termos de velocidade de inferência.
modelo de inferênciaHá muito espaço para otimização em termos de desempenho.
Embora o modelo de inferência representado pelo o1-preview tenha um bom desempenho na pontuação do benchmark, o tempo médio de inferência por pergunta é de cerca de 40s, e o desempenho geral está na "zona de baixo desempenho". Para ter uma ampla gama de cenários de aplicativos, o modelo de inferência precisa se concentrar em melhorar sua velocidade de inferência.
Componente-chave 5: Lacunas e tendências de modelagem nacionais e internacionais de grande porte, 2024

A tendência geral é que a lacuna entre os recursos genéricos da primeira camada de grandes modelos nacionais e estrangeiros no domínio chinês esteja aumentando.
De maio de 2023 até o presente, os recursos de modelos grandes nacionais e internacionais continuaram a evoluir. Entre eles, os melhores modelos estrangeiros representados pela série de modelos GPT passaram por várias iterações do GPT3 . 5, GPT4, GPT4 - Turbo, GPT4o, o1 de várias versões de atualizações iterativas.
O modelo doméstico também passou por um ciclo de iteração de 18 meses, diminuindo a diferença de 0,121 TP3T em maio de 2023 para 1,291 TP3T em agosto de 2024, mas com o lançamento do o1, a diferença aumentou novamente para 15,051 TP3T.

Os modelos domésticos representados pelo DeepSeek-V3 estão ficando extremamente próximos do GPT-4o-latest
Nos últimos dois anos, os modelos representativos domésticos foram iterados em várias versões, DeepSeek-V3, Doubao-pro, GLM-4-Plus e Qwen2.5 estiveram próximos do GPT-4o em tarefas chinesas, entre as quais o DeepSeek-V3 teve um bom desempenho, superando o desempenho do Claude 3.5 Sonnet na avaliação de dezembro.
o1 Modelos de raciocínio baseados no novo paradigma de aprendizado por reforço, ultrapassando 80 pontos para aumentar a diferença entre os principais modelos nacionais e internacionais
Na avaliação da SuperCLUE em dezembro, os principais modelos de referência no país e no exterior nas pontuações de benchmark da SuperCLUE se concentraram em 60-70 pontos. A o1 e a o1-preview, baseadas no novo paradigma do modelo de inferência de aprendizado por reforço, tornaram-se uma importante tecnologia representativa do rompimento do gargalo de 70 pontos, especialmente a versão formal da o1 do rompimento da marca de 80 pontos, mostrando uma grande vantagem de liderança.
Elemento-chave 6: Outras listas de subdimensões
Lista rígida

Lista de assuntos científicos

Lista de Artes Liberais

Os 3 principais na China para cada dimensão

Lista de modelos de código aberto

Lista de modelos até 10B

Lista de modelos de extremidades até 5B

Lista de pontuações secundárias de granulação fina

Devido à limitação de espaço, este documento mostra apenas parte do relatório. O conteúdo completo inclui a metodologia de avaliação, exemplos de avaliação, listas de subtarefas, multimodalidade, aplicativos e introdução aos benchmarks de inferência.
© declaração de direitos autorais
Direitos autorais do artigo Círculo de compartilhamento de IA A todos, favor não reproduzir sem permissão.
Artigos relacionados


Nenhum comentário...