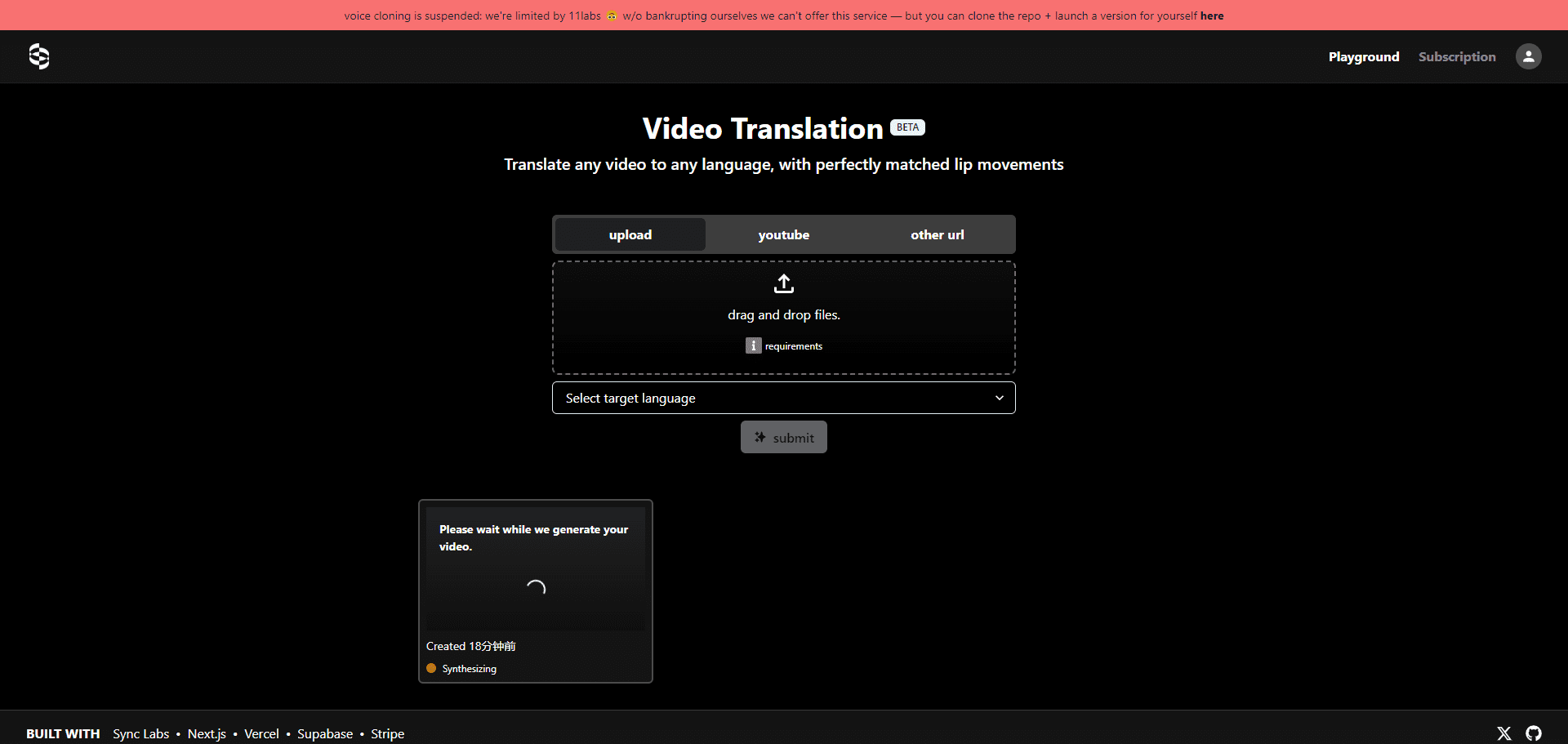
Zonos: 高品質音声合成と音声クローニングツール

はじめに
Zonosは、Zyphra社によって開発されたオープンソースの音声合成および音声クローニングツールです。 変圧器 Zonosのスピーチクローン機能は、わずか数秒のリファレンス音声を提供するだけで、高品質な音声出力を生成します。このツールは、英語、日本語、中国語、フランス語、ドイツ語を含む多言語をサポートし、音質や感情をきめ細かく制御することができます。Zonosのスピーチクローン機能は、わずか数秒の参照音声を提供するだけで、非常に自然な音声を生成します。ユーザーはGitHub経由でモデルの重みとサンプルコードを入手し、Huggingfaceで試すことができる。

機能一覧
- ゼロサンプルTTS音声クローニングテキストと10-30秒の音声サンプルを入力し、高品質な音声出力を生成します。
- 音声プリフィックス入力テキストと音声の接頭辞を追加して、より豊かな話者マッチングを実現。
- 多言語サポート英語、日本語、中国語、フランス語、ドイツ語に対応。
- 音質と感情のコントロール話すスピード、ピッチの変化、音質、感情(喜び、恐れ、悲しみ、怒りなど)など、生成される音声のさまざまな側面をきめ細かくコントロールできます。
- リアルタイム音声生成忠実度の高い音声のリアルタイム生成に対応。
ヘルプの使用
設置プロセス
- クローンプロジェクトターミナルで以下のコマンドを実行し、Zonosプロジェクトをクローンします:
bash
git clone https://github.com/Zyphra/Zonos.git
cd Zonos - 依存関係のインストール必要なPythonの依存関係をインストールするには、以下のコマンドを使用します:
bash
pip install -r requirements.txt - モデルウェイトのダウンロードHuggingfaceから必要なモデルウェイトをダウンロードし、プロジェクトディレクトリに置く。
使用方法
- 積載モデルPython環境にZonosモデルをロードします:
import torch import torchaudio from zonos.model import Zonos from zonos.conditioning import make_cond_dict model = Zonos.from_pretrained("Zyphra/Zonos-v0.1-transformer", device="cuda") - スピーチの生成音声出力を生成するために、テキストと話者のサンプルを提供します:
python
wav, sampling_rate = torchaudio.load("assets/exampleaudio.mp3")
speaker = model.make_speaker_embedding(wav, sampling_rate)
cond_dict = make_cond_dict(text="Hello, world!", speaker=speaker, language="en-us")
conditioning = model.prepare_conditioning(cond_dict)
codes = model.generate(conditioning)
wavs = model.autoencoder.decode(codes).cpu()
torchaudio.save("sample.wav", wavs[0], model.autoencoder.sampling_rate) - グラディオ・インターフェースの使用スピーチの生成には、Gradioインターフェイスをお勧めします:
bashこれにより
uv run gradio_interface.py
# 或者
python gradio_interface.pysample.wavファイルをプロジェクトのルート・ディレクトリに保存する。
詳細な機能操作の流れ
- ゼロサンプルTTS音声クローニング::
- 希望するテキストと話者の10~30秒のサンプルを入力すると、このモデルは高品質の音声出力を生成する。
- 音声プリフィックス入力::
- テキストや音声の接頭辞を追加して、より豊かな話者マッチングを実現。たとえば、ウィスパーオーディオの接頭辞は、ウィスパー効果を生成するために使用できます。
- 多言語サポート::
- 希望の言語(英語、日本語、中国語、フランス語、ドイツ語など)を選択すると、対応する言語の音声出力が生成されます。
- 音質と感情のコントロール::
- このモデルの条件設定機能を使えば、話すスピード、ピッチの変化、音質、感情(喜び、恐れ、悲しみ、怒りなど)など、生成される音声のあらゆる側面をきめ細かくコントロールできます。
- リアルタイム音声生成::
- Gradioインターフェースやその他のリアルタイム生成方法を使用して、忠実度の高い音声を素早く生成します。
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事



コメントはありません