
インテリジェント・ドキュメンテーション: Dify Chatflowによる効率的な入札書類作成

自然言語対話型データベースの読み書き
年末になるとまた入札シーズンがやってくるが、入札書類のような大きな書類の作成には頭を悩ませることが多い。
正確で専門的な内容であることはもちろん、企業の強みを際立たせる必要があり、専門的な知識とコピーライティングのスキルの両方が試される。どちらも、一字一句書くのに多くの時間とエネルギーを費やす必要があるとはいえ、作業量は膨大で、難易度はかなり高い。

それで、これは ダイファイ フレームワークのインテリジェントな文書準備ワークフローは、効率的なソリューションとなりました。その中核は、Dify-Chatflowを使用して、自然言語駆動型のデータベースの読み取り/書き込み操作を実現することで、自動的に元の文書を読み取り、ユーザーのニーズに応じて内容を修正したり、新しい内容を書き込んだりすることができます。同時に、文書の概要を自動的に生成し、重要なポイントを抽出し、最終的に保存を完了します。

このワークフローは、Chatflowとも呼ばれるdifyのChat Assistantワークフロー・オーケストレーション・パターンを使用しています。
チャットフロー VS ワークフロー
チャットフローアプリケーションのシナリオ:
顧客サービス、セマンティック検索、および応答を構築する際にマルチステップロジックを必要とする他の会話アプリケーションを含む、対話タイプのシナリオを指向する。このタイプのアプリケーションは、生成された結果を調整するための複数ラウンドの対話をサポートすることで区別される。
一般的な相互作用の経路:指示を与える→コンテンツを生成する→コンテンツに関する複数の議論→結果を再生成する→終了
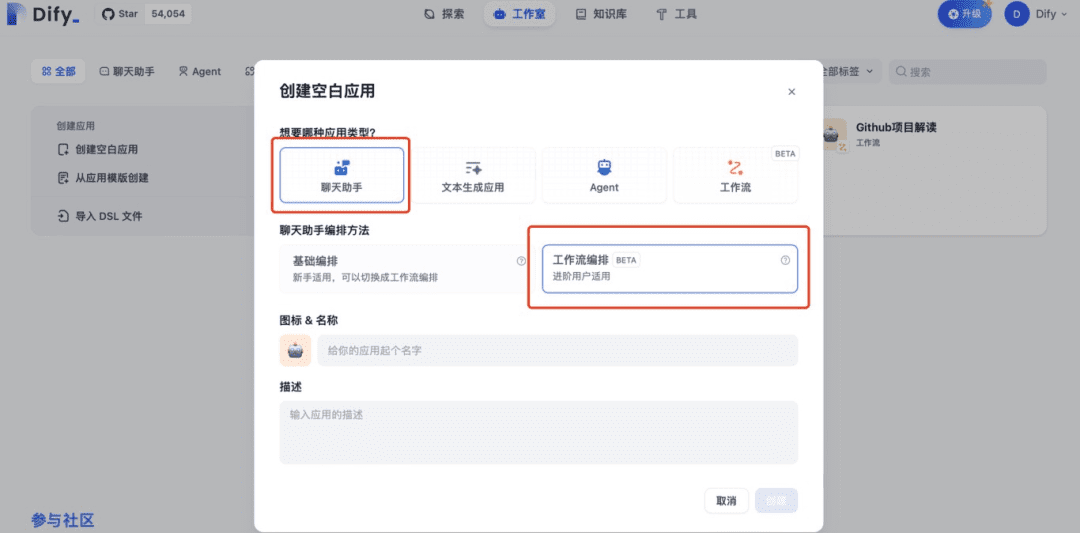
ワークフロー応用シナリオ:
自動化およびバッチ処理シナリオ向けで、高品質翻訳、データ分析、コンテンツ生成、電子メール自動化などのアプリケーションに適しています。このタイプのアプリケーションでは、生成された結果と何度も対話することはできません。
一般的なインタラクション経路:コマンドを与える→コンテンツを生成する→終了する
インテリジェント・ドキュメンテーション チャットフロー実装ロジック
ステップ1
大きな文書を複数のテキストブロックに分割します。例えば、入札書の共通内容である会社概要、品質保証対策、技術開発力、アフターサービス保証などを別のテキストブロックに分割します。
ステップ2
これらのテキスト・ブロックをデータベースに保存する。ローカルファイルではなくデータベース保存を選択する主な理由は、データベースは共有しやすく、文書内容を構造化することで後処理が容易になり、多様な需要シナリオに対応しやすくなるからである。私たちのデータテーブルには、ID、タイトル、カテゴリー、概要、キーポイント、コンテンツ、記録時間などのフィールドがあり、概要とキーポイントは、修正されたコンテンツに基づいてビッグモデルによって自動的に生成される。オーバービューはコンテンツのハイレベルな要約を提供し、キーポイントは項目化された要約であり、その後のPPT作成などに簡単に利用できる。
ステップ3
DifyのChatflowビルディングアプリケーションを使用すると、ユーザーは自然言語対話を通じて2つのタスクを完了することができます:1つは、既存のドキュメントブロックを修正・改善することであり、もう1つは、真新しいコンテンツを書くことです。タスクが完了すると、変更されたコンテンツと新しいコンテンツは、更新と保存のために自然言語を通じて自動的にデータベースに送信されます。
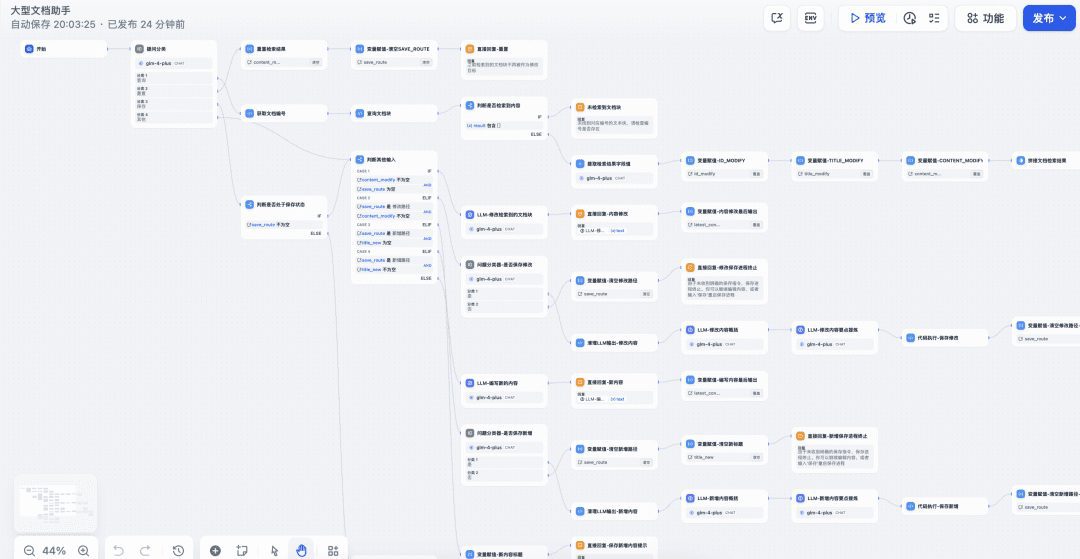
チャットフローノード全体は複雑で数が多いので、全体の概要を簡単に説明します。
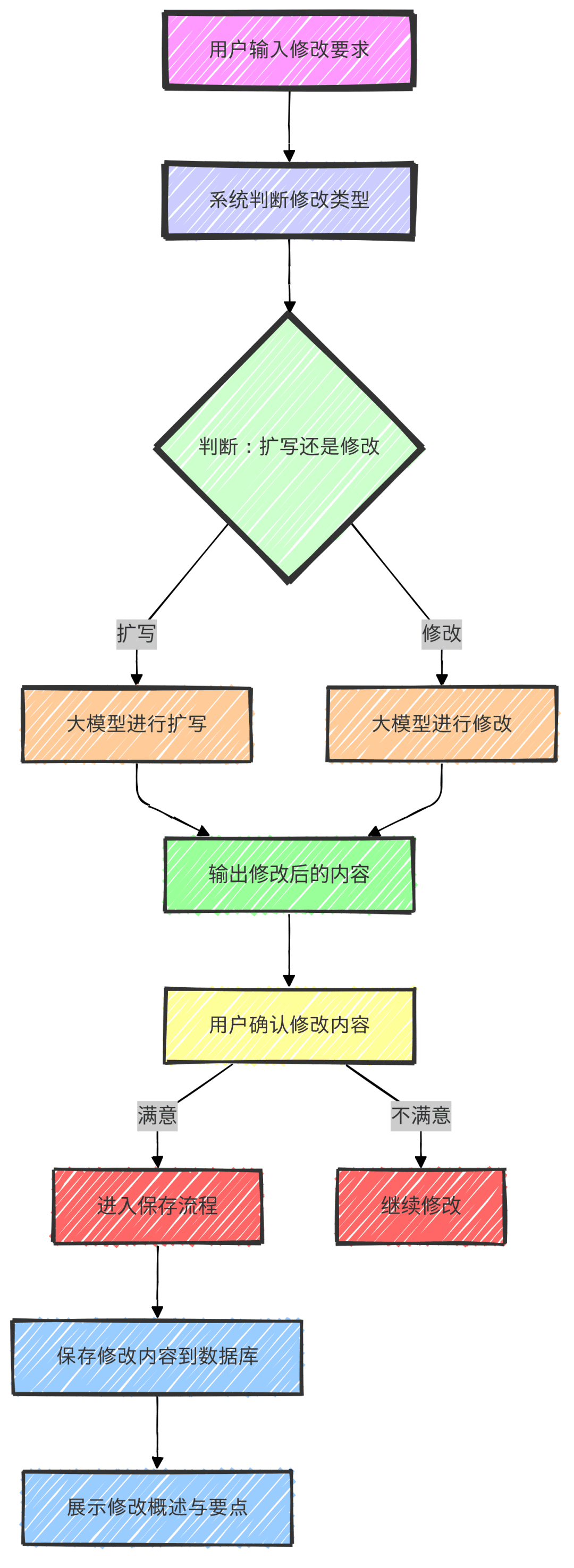
タスク 1: 既存の文書ブロックの修正と改善
- ドキュメントのクエリ・ブランチ:
- ユーザーは、テキストブロックID(例:井戸番号+番号)を入力することで、クエリーリクエストを開始する。
- クエリーブランチは、データベースから対応するドキュメントブロックを取得し、ID、タイトル、コンテンツを抽出して表示します。
- クエリの結果はコード実行ノードを通じて処理され、有効なドキュメントブロックが存在するかどうかを判断する。

- 文書修正ブランチ:
- ユーザーが修正要求を入力した後、システムは内容に基づいて文書ブロックを展開するか修正するかを決定する。
- modifyブランチでは、ビッグモデルがユーザーの要求に従ってクエリされたドキュメントを修正し、修正された内容はコピーしやすいようにコードブロック形式で出力される。
- ユーザーは修正した内容を確認し、満足すれば保存プロセスに入ることができ、満足しなければ修正を続ける。
- ユーザーが変更の保存を確認した後、システムは変更されたテキストをデータベースに保存し、変更の概要とポイントを表示します。

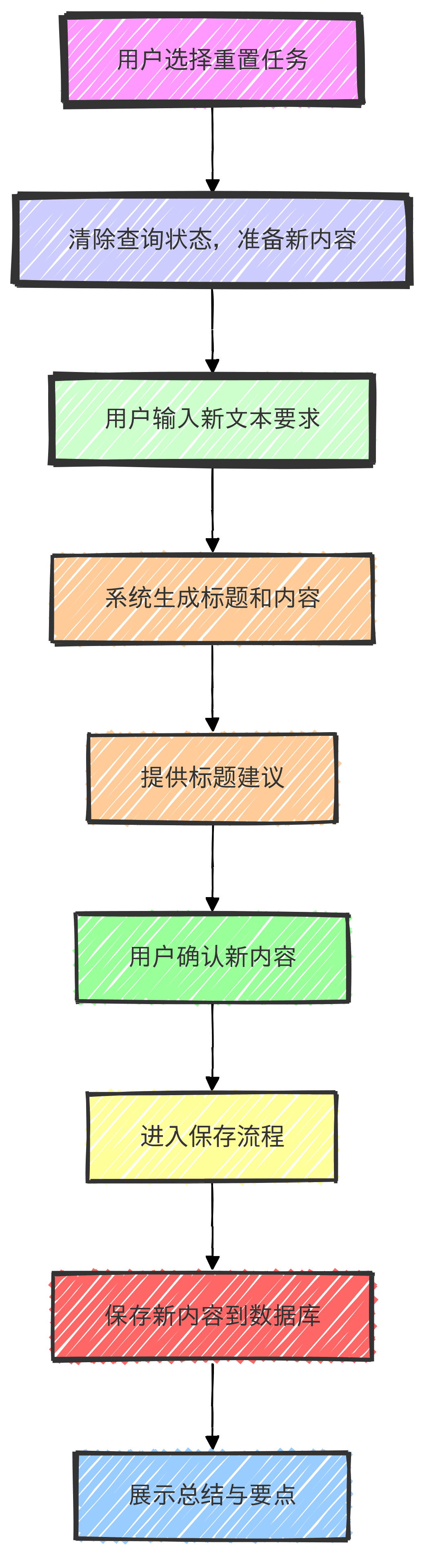
タスクII:まったく新しいコンテンツの準備
- タスク分岐のリセット:ユーザーがリセットを選択した場合、システムは新しいコンテンツを書く準備として、以前に照会されたドキュメントのステータスをクリアします。
- 新しいコンテンツブランチを構成する:ユーザーが新しいテキストブロックのリクエストを入力すると、システムが新しいタスクに構成し、タイトルとコンテンツを生成します。
- 新しいコンテンツタイトルのヒントブランチ:コンテンツの整理や編集に役立つ新しいタイトル候補をユーザーに提供します。
- 保存ブランチの確認:ユーザーは書き込まれた新しいコンテンツを確認し、最終的に保存プロセスに入ります。
- 保存ブランチの送信:新しいコンテンツがデータベースに保存され、要約と要点が出力されます。
主要機能とノードの説明
- 分類器ノード:ユーザー入力を分類し、照会、修正、保存の必要性を識別する。
- 条件分岐ノード:さまざまな状況(コンテンツが空かどうかなど)に基づいて、ワークフローの方向を決定します。
- コード実行ノード:データベースクエリ、テキスト処理、その他の処理を実行する。
- ラージモデルノード:ユーザーの要求に従って出力を提供するために、テキストを生成または修正する役割を担う。
- ダイレクト・レスポンス・ノード:結果を表示したり、ユーザーにアクションを促したりする。
- Variable Assignment Node:セッション内の変数を管理し、プロセスのロジックをスムーズにする。
 上記は、タスク1とタスク2の全体的なプロセスと主要な機能ノードである。明確な設計により、システムはユーザーのニーズに柔軟に対応し、文書の照会、変更、作成をスムーズに行うことができます。
上記は、タスク1とタスク2の全体的なプロセスと主要な機能ノードである。明確な設計により、システムはユーザーのニーズに柔軟に対応し、文書の照会、変更、作成をスムーズに行うことができます。
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事



コメントはありません