接客クイズのための知識グラフ検索機能強化の生成

論文アドレス:https://arxiv.org/abs/2404.17723
知識グラフは、的を絞った方法でしか実体関係を抽出することができず、そのような安定的に抽出可能な実体関係は、次のように理解することができる。構造化データへのアプローチ.
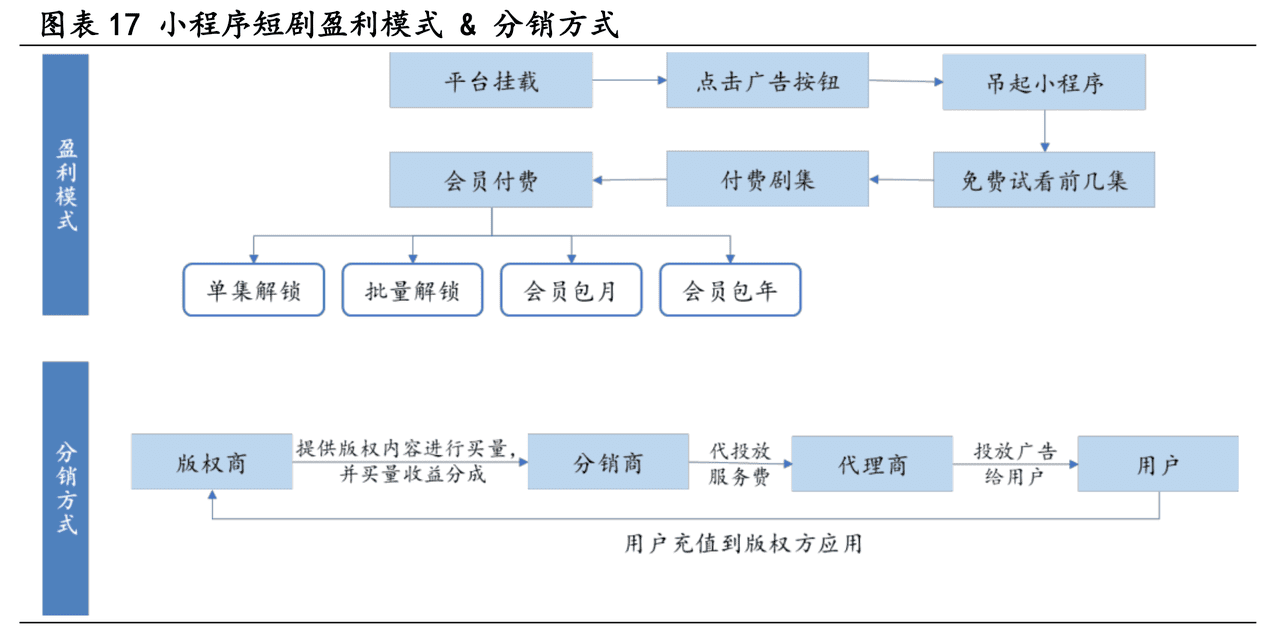
図1は、知識グラフ(KG)と検索拡張世代(RAG)を組み合わせた顧客サービスQ&Aシステムのワークフローを示している。プロセスを以下に要約する:
1.ナレッジマッピング:このシステムは、2つの主要なステップを含む、過去の顧客サービスの問題チケットから包括的なナレッジマップを構築します:
- インナーチケットのツリー表現:各イシューチケットは、チケットのさまざまな部分(サマリー、説明、優先度など)を表すノードを持つツリー構造として解析されます。
- チケット間リンク:課題追跡チケットの明示的なリンクと、意味的類似性によって推測される暗黙的なリンクに基づいて、個々のチケットツリーを完全なグラフに接続する。
2.埋め込み生成:事前に訓練されたテキスト埋め込みモデル(BERTやE5など)を使用して、グラフ内のノードの埋め込みベクトルを生成し、これらの埋め込みをベクトルデータベースに格納する。
3.検索と質疑応答のプロセス:
- 質問意図の埋め込み:名前付きエンティティと意図を識別するためのユーザークエリの解析。
- エンベッディングに基づく検索:エンティティの使用により、最も関連性の高いチケットを検索し、関連性の高いサブグラフをフィルタリングする。
- フィルタリング:さらにスクリーニングを行い、最も関連性の高い情報を特定する。
4.検索されたチケット: ENT-22970、PORT-133061、ENT-1744、ENT-3547など、ユーザのクエリに関連する特定のチケットを検索し、それらの間のクローン(CLONE_FROM/CLONE_TO)と類似性(SIMILAR_TO)の関係を表示します。
5.回答生成:最終的に、システムは検索された情報と元のユーザーのクエリを合成し、大規模言語モデル(LLM)を通じて回答を生成する。
6.グラフデータベースとベクトルデータベース:プロセス全体を通して、グラフデータベースはアトラス内のノードとリンクを保存・管理するために使用され、ベクトルデータベースはノードのテキスト埋め込みベクトルを保存・管理するために使用される。
7.LLMの使用ステップ:複数のステップで、大規模な言語モデルを使用して、テキストを解析し、クエリを生成し、サブグラフを抽出し、回答を生成する。
このフローチャートは、知識グラフと検索強化生成技術を組み合わせることによって、顧客サービスのための自動Q&Aシステムの効率と精度をどのように向上させることができるかのハイレベルなビューを提供する。

この図の左側は知識グラフの構築、右側は検索と質疑応答のプロセスを示している。
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事



コメントはありません