
RAG(Retrieval Augmented Generation)を理解するための記事、理論的な導入+コード練習の概念

I. LLMはすでに強力な能力を持っているのに、なぜRAG(検索補強世代)が必要なのか?
LLMは大きな能力を発揮しているが、懸念される課題もいくつか残っている:
- イリュージョン問題:LLMは、統計学に基づく確率論的なアプローチでテキストを一語一語生成している;
- (a)適時性の問題:LLMの規模が大きくなるにつれて、トレーニングのコストとサイクルタイムが増大する。その結果、最新の情報を含むデータをモデル学習プロセスに組み込むことが難しくなり、LLMは「今一番好きな映画を提案してください」といった時間に敏感な問題に対応できなくなる;
- データセキュリティの問題:一般的なLLMは、企業内部のデータとユーザーデータを持っていないため、企業はセキュリティを保証する前提でLLMを使用したい場合、最善の方法は、すべてのデータをローカルに置くことであり、企業データのすべてのビジネス計算はローカルで行われる。そして、オンラインビッグモデルは一般化機能を完成するだけである;
II.RAGの導入?
RAG(Retrieval Augmented Generation)とは、LLMが質問に対する回答や文章作成というタスクに直面した際に、まず大規模な文書ライブラリを検索し、タスクに密接に関連する資料をフィルタリングし、その資料に基づいてその後の回答生成や文章作成プロセスを精密に導くという点に核心がある技術的フレームワークであり、このようにしてモデル出力の精度と信頼性を向上させることを目的としている。このようにしてモデル出力の精度と信頼性を向上させることを目的としている。
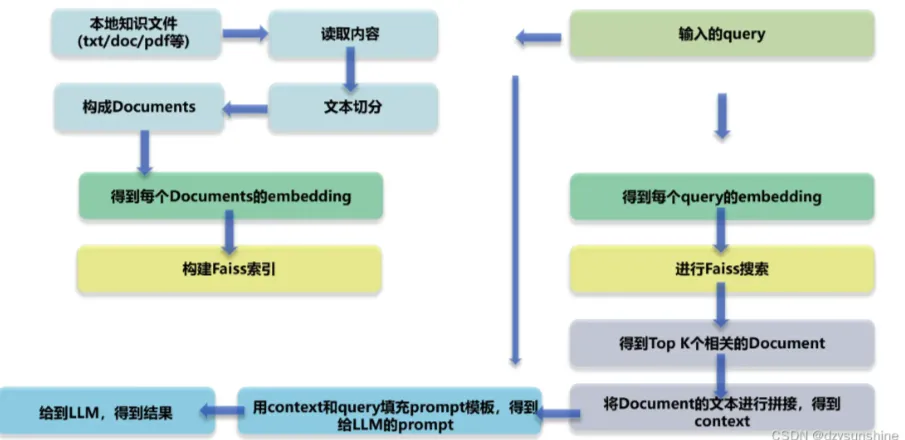
ラグ テクニカル・アーキテクチャ図
III.RAGの主なモジュールは何ですか?
- モジュール1:レイアウト分析
- ローカルナレッジファイルの読み込み(pdf、txt、html、doc、excel、png、jpg、voiceなど)
- ナレッジ・ドキュメントの回収
- モジュール II: 知識ベースの構築
- ナレッジテキストのセグメンテーションとドックテキストの構築
- テキスト埋め込み
- ドック・テキスト・ビルド・インデックス
- モジュール3:ビッグ・モデルの微調整
- モジュールIV:RAGベースの知識クイズ
- ユーザークエリの埋め込み
- クエリーリコール
- クエリーソート
- 関連する上位K個のドキュメントをつなぎ合わせて、コンテキストを構築した。
- クエリとコンテキストに基づくプロンプトの構築
- プロンプトをビッグモデルに送り、答えを生成する
LLMを直接クイズに使うのと比べて、RAGの利点は何ですか?
RAG(Retrieval Augmented Generation)アプローチは、開発者に、特定のタスクごとに大規模なモデルを再トレーニングすることなく、単に追加の情報リソースを注入できる外部の知識ベースに接続するだけで、回答の精度を大幅に向上させる能力を与える。このアプローチは、専門知識に大きく依存するタスクに特に適しています。以下はRAGモデルの主な利点です:
- スケーラビリティ:モデルのサイズとトレーニングのオーバーヘッドを削減し、知識ベースの拡張と更新のプロセスを簡素化。
- 正確性:ソースを引用することで、ユーザーは回答の信頼性を確認することができ、モデルの出力結果に対する信頼が高まります。
- 制御性:知識コンテンツの柔軟な更新とパーソナライズされた設定をサポート。
- 解釈可能性:モデルの予測が依存する検索エントリーを表示し、理解と透明性を向上させる。
- 汎用性:RAGは、Q&A、テキスト要約、対話システムなどの分野をカバーし、幅広いアプリケーションシナリオに合わせて微調整やカスタマイズが可能です。
- 適時性:検索技術を使用して最新の情報動向を把握することで、応答が即時かつ正確であることが保証され、固有の学習データのみに依存する言語モデルにはない明確な利点がある。
- ドメインのカスタマイズ:テキストデータセットを特定の業界やドメインにマッピングすることで、RAGは的を絞った専門知識サポートを提供することができます。
- セキュリティ:データベース・レベルでの役割分割とセキュリティ制御を実装することで、RAGはデータ利用管理を効果的に強化し、データ権限管理のためにモデルを微調整する潜在的な曖昧さよりも高いセキュリティを示す。
V. RAGとSFTを比較対照し、その違いを教えてください。
実際、SFTはLLMの上記の問題に対する最も一般的で基本的な解決策の一つであり、LLMの応用を実現するための基本的なステップでもある。そこで、2つのアプローチをいくつかの次元で比較する必要がある:
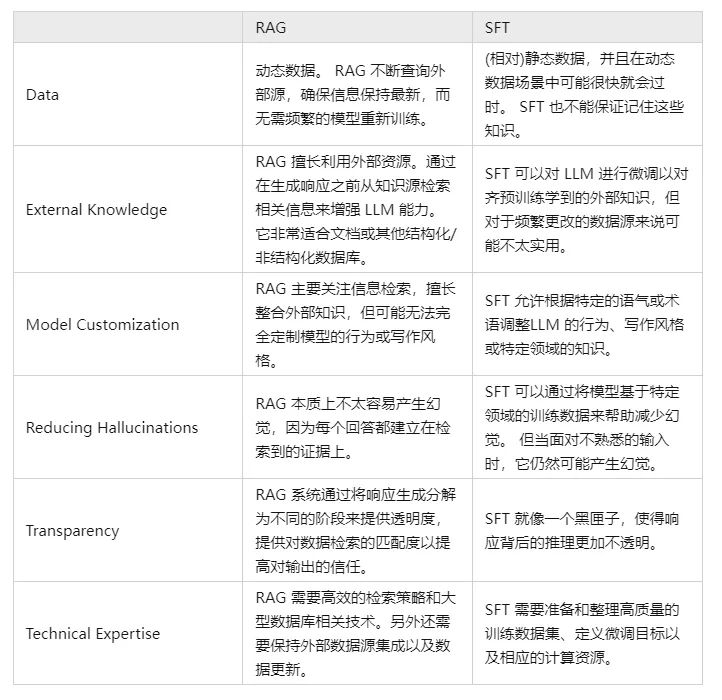
もちろん、この2つの方法はどちらか一方というわけではなく、ビジネス上のニーズと両方の方法の利点を組み合わせ、合理的に使い分けることが必要であり、合理的である。
モジュール1:レイアウト分析
なぜレイアウト解析が必要なのですか?
RAG(Retrieval Augmented Generation)技術の中核的価値は、テキストコンテンツの精度と一貫性を向上させるための検索と生成の組み合わせにあるが、その機能的境界は、特に構造化または半構造化された情報を処理する必要性に直面した場合、文書解析、インテリジェントオーサリング、対話の構築など、特定の応用領域におけるレイアウト分析を含むように拡張される可能性がある。
これは、この種の情報が特定のレイアウト構造に組み込まれていることが多く、ページ要素とその相互関係を深く理解する必要があるためだ。
さらに、RAGモデルが、ウェブページ、PDFファイル、リッチテキストレコード、Word文書、画像データ、音声クリップ、表形式データ、その他の複雑なコンテンツなど、豊富なマルチメディアまたはマルチモーダルコンポーネントを含むデータソースに直面した場合、このような非テキスト情報を効率的に取り込み、利用できるようにするために、基本的なレイアウト解析能力を持つことが極めて重要になります。この能力は、モデルがさまざまな情報ユニットを正確に解析し、意味のある全体的な解釈にうまく統合するのに役立ちます。
ステップ1:現地の知識資料の入手
Q1: ローカル・ナレッジ・ドキュメントの取得方法は?
ローカルナレッジファイルアクセスには、複数のデータソース(.txt、.pdf、.html、.doc、.xlsx、.png、.jpg、オーディオファイルなど)から情報を抽出するプロセスが含まれます。さまざまなタイプのファイルに対して、それらに含まれる知識を効果的に取得するためには、特定のアクセス戦略や構文解析戦略が必要です。以下では、さまざまなデータ・ソースに対するアクセス方法と難点を紹介する。
Q2: リッチテキストtxtの内容を取得する方法は?
- はじめに:リッチテキストは、主にtxtファイルに格納されているため、レイアウトが比較的整然としているので、比較的単純な取得する方法
- 実践的なスキル:
- [レイアウト分析 - リッチテキスト・テキスト・リーディング]。
q3: PDFドキュメントの内容を取得する方法は?
- はじめに:データのPDF文書は、テキスト、画像、表、およびデータの他のさまざまなスタイルを含む、より複雑なので、解析プロセスは、より複雑になります!
- 実践的なスキル:
- [レイアウト解析--PDF解析マジックpdfplumber
- レイアウト解析--PDFパーサーPyMuPDF
Q4: HTMLドキュメントのコンテンツを取得するには?
- はじめに:データのPDF文書は、テキスト、画像、表、およびデータの他のさまざまなスタイルを含む、より複雑なので、解析プロセスは、より複雑になります!
- 実践的なスキル:
- レイアウト分析 - HTML解析 BeautifulSoup
Q5: Docドキュメントの内容を取得する方法は?
- はじめに:Docドキュメントのデータは、テキスト、画像、表、その他のさまざまなスタイルのデータを含む、より複雑なものです!
- 実践的なスキル:
- レイアウト解析--Docx解析アーティファクト python-docx]。
Q6: OCRを使って画像の内容を取得する方法は?
- はじめに:光学式文字認識(OCR)。 キャラクター Recognition、OCR)とは、テキスト情報の画像ファイルを分析して認識し、テキスト情報とレイアウト情報を得るプロセスである。また、画像内のテキストを認識し、テキストの形で返すことを意味します。
- 感想だ:
- テキスト認識:よく配置されたテキスト領域の認識、主な問題は、各テキストが何であるかの問題を解決することである、文字情報の変換に画像のテキスト領域。
- テキスト検出:解決される問題は、どこにテキストがあり、どれだけのテキスト範囲があるかということだ;
- 現在のオープンソースOCRプロジェクト
- 四次元超立方体
- パドルOCR
- イージーオーシーアール
- チャイニーズソクロック
- チャイニーズオクライト
- TrWebOCR
- クノーク
- hn_ocr
- 理論的な研究:
- レイアウト分析 - 画像解析ツールOCR]のページです。
- 実践的なスキル:
- [レイアウト分析 - OCRテッセラクト]。
- [レイアウト分析 - OCR Magic PaddleOCR]。
- [レイアウト分析 - OCRアーティファクト hn_ocr].
Q7: ASRを使って音声コンテンツを取得する方法は?
- 別名:自動音声認識 AutomaTlc Speech RecogniTlon, (ASR)
- はじめに:音声信号を対応するテキストメッセージに変換することは、「機械の聴覚システム」のようなもので、認識と理解を通じて、機械が音声信号を対応するテキストやコマンドに変換することを可能にする。
- 目的:人間の音声の語彙内容をコンピュータが読み取り可能な入力(例:キーストローク、バイナリコード、文字列)に変換する。
- 感想だ:
- 音響信号の前処理:より効果的に特徴を抽出するために、多くの場合、音信号のフィルタリング、フレーミング、およびその他の前処理作業、元の信号抽出から分析される信号をキャプチャする必要があります;
- 特徴抽出:音響モデルに適した特徴ベクトルを提供するために、音響信号を時間領域から周波数領域に変換する。
- 音響モデリング:音響特性に基づいて、各特徴ベクトルのスコアを計算する。
- 言語モデリング:言語学的に関連する理論に基づいて、音信号が一連の可能なフレーズに対応する確率を計算する。
- 辞書とデコード:既存の辞書に基づいて、一連のフレーズをデコードし、最終的なテキスト表現を得る。
- 理論のチュートリアル:
- レイアウト分析のための音声認識
- 実践的なスキル:
- [音声テキストレイアウト分析]
- WeTextProcessingのレイアウト分析
- [レイアウト解析 - ASRツールWenet]。
- レイアウト解析 ASRトレーニング
ステップ2:ナレッジ・ドキュメントのリカバリー
Q1: なぜナレッジ・ドキュメントのリカバリーが必要なのですか?
ローカル知識文書取得は、複数ソースのデータ(txt、pdf、html、doc、excel、png、jpg、音声など)を読み取った後に含まれ、複数行の段落が複数の段落に分割されやすく、段落の出会いが分割につながるため、内容論理に従って段落を再整理する必要がある。
Q2: ナレッジ・ドキュメントはどのように復元できますか?
- 方法論I:ルールベースの知識文書復元
- 方法2:バートNSPに基づくコンテキスト・スプライス
ステップ3:レイアウト分析 - 最適化戦略
- 理論的な研究:
- [レイアウト分析 - 最適化戦略].
ステップ4:宿題
- タスクの説明: 上記の方法論を使って、[SMP 2023 ChatGLM Finance Big Model Challenge]の[ChatGLM Evaluation Challenge - Finance Track dataset]のレイアウトを分析する。
- 課題の有効性:様々な方法の有効性とパフォーマンスを分析する。
モジュール II: 知識ベースの構築
なぜナレッジベースの構築が必要なのか?
RAG(Retrieval-Augmented Generation)における知識ベースの構築は、以下に限定されないが、いくつかの理由から非常に重要である:
- モデル能力の拡張:GPTファミリーのような大規模な言語モデルは、強力な言語生成・理解能力を持っていますが、学習データセットのカバレッジによって制限され、特定の事実や詳細な背景情報に基づいて質問に正確に答えることができない場合があります。知識ベースを構築することで、RAGはモデル自身の知識の制限を補完し、モデルが最新の正確な情報を取得して回答を生成できるようにします。
- リアルタイムでの情報更新:知識ベースはリアルタイムで更新・拡張することができ、モデルが最新の知識コンテンツにアクセスできるようにする。
- 精度の向上:RAGは検索と生成の両方のプロセスを組み合わせ、回答を生成する前に関連文書を検索することで、質問に回答する際の精度を向上させる。このようにして、モデルによって生成された回答は、モデル内部のパラメータ化された知識だけでなく、信頼できるソースの外部知識ベースにも基づいています。
- 過剰適合と幻覚の低減:大規模なモデルは、時に内在するパターンに過度に依存し、幻覚に悩まされることがある。RAGは、知識ベースから決定的な証拠を引用することによって、そのようなエラーの可能性を減らすことができます。
- 解釈可能性の向上:RAGは答えを提供するだけでなく、答えの出典を指し示し、モデルによって生成された結果の透明性と信頼性を高めます。
- パーソナライゼーションやプライベート・ニーズのサポート:企業や個人ユーザーは、特定の分野やプライベートなカスタマイズのニーズに応えるために、専用の知識ベースを構築することができる。
まとめると、知識ベースを構築することは、RAGモデルが効率的で正確な検索と回答生成を実現するための中核的なメカニズムの一つであり、実用的なアプリケーションにおけるモデルの性能と信頼性を大幅に向上させる。
ステップ1:知識テキストのチャンキング
- なぜテキストをチャンクする必要があるのか?
- 情報が欠落するリスク:文書全体の埋め込みベクトルを一度に抽出しようとすると、全体的な文脈を把握する一方で、トピック固有の重要な情報が多く欠落する可能性があり、その結果、生成される情報の精度が低下したり、情報が欠落したりする可能性がある。
- チャンクサイズの制限:チャンクサイズは、OpenAIのようなモデルを使用する際の重要な制限要因です。例えば、GPT-4モデルのウィンドウサイズの制限は32Kです。この制限はほとんどの場合問題にはなりませんが、最初からチャンクサイズを考慮することが重要です。
- 考慮すべき主な要素は2つある:
- 埋め込みモデルのトークン制限ケース;
- 意味的完全性が検索効果全体に及ぼす影響;
- 実践的なスキル:
- [知識ベースの構築 - 知識テキストのチャンキング】。]
- [知識ベースの構築 - ドキュメントのスライシングとダイシングの最適化戦略].
ステップ2:ドキュメントのベクトル化(embdeeing)
Q1: Docsのベクトル化(embdeeing)とは何ですか?
各埋め込みは浮動小数点数のベクトルであり、ベクトル空間における2つの埋め込み間の距離は、元のフォーマットにおける2つの入力間の意味的類似性と相関する。例えば、2つのテキストが類似している場合、それらのベクトル表現も類似しているはずであり、ベクトル空間におけるこの配列表現のセットは、テキスト間の微妙な特徴の違いを記述する。簡単に言えば、埋め込みは、コンピュータが人間の情報の「意味」を理解するのに役立つ。 埋め込みは、テキスト、画像、ビデオ、その他の情報の特徴の「関連性」を得るために使用することができ、これは、検索、推薦、分類、その他のアプリケーションレベルで一般的に使用されている。このような相関関係は、検索、推薦、分類、クラスタリングなどでよく使われる。
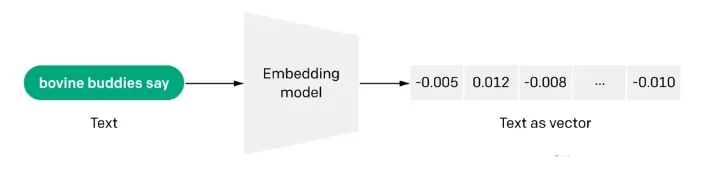
Q2: エンベディングはどのように機能するのですか?
例として3つの文章を挙げよう:
- "猫は鼠を追う"
- 「子猫はネズミを狩る」。
- 「ハムサンドが好きなんだ。
人間がこの3つの文を分類するとすれば、文1と文2はほとんど同じ意味になり、文3はまったく違う意味になる。しかし、元の英文では、文1と文2で同じなのは「The」だけで、他の単語は同じではないことがわかる。コンピュータが最初の2つの文の関連性を理解するにはどうしたらよいだろうか? 埋め込みは、離散的な情報(単語や記号)を分散した連続値のデータ(ベクトル)に圧縮する。先ほどのフレーズをグラフにプロットすると、次のようになる:
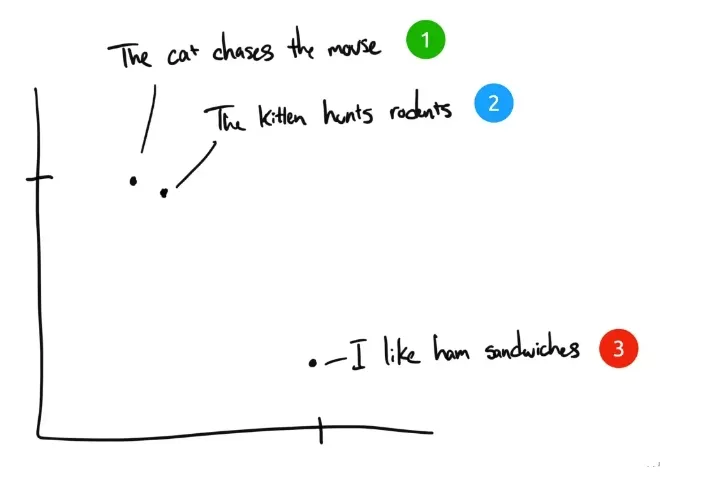
テキストがコンピュータで理解可能な多次元ベクトル化空間にエンベッディング圧縮された後、センテンス1と2は似たような意味を持っているため、互いに近くにプロットされる。センテンス3はそれらに関係がないため離れている。もし「サリーはスイスチーズを食べた」という第4のフレーズがあったとしたら、それはおそらく文3(チーズはサンドイッチに挟む)と文1(ネズミはスイスチーズが好き)の間のどこかに存在するだろう。
Q3: キーワード検索に対するエンベッディングの意味検索アプローチの利点は?
- 意味的理解:埋め込みベースの検索手法は、テキストを単語ベクトルで表現するため、単語間の意味的関連性を捉えることができる。
- エラー耐性:埋め込みベースの手法は単語間の関係を理解することができるため、スペルミス、同義語、同義語に近い単語などのケースに対応するのに有利である。一方、キーワードベースの検索手法は、このようなケースの処理に比較的弱い。
- 多言語サポート:多くの埋め込み方式は多言語に対応しており、言語横断的なテキスト検索を実現するのに役立つ。例えば、中国語入力を使って英語のテキストコンテンツを検索することができますが、キーワードベースの検索方法ではこれが困難です。
- 文脈理解:埋め込みベースの手法は、文脈に基づいて単語に異なるベクトル表現を割り当てることができるため、単語の意味が複数ある場合に有利である。一方、キーワードベースの検索手法は、異なる文脈における同じ単語の意味をうまく区別できない可能性がある。
Q4: 埋め込み検索の限界は何ですか?
- 入力単語数の制約:大規模モデルの参照用にEmbedding技術の助けを借りてクエリに最もマッチするテキストフラグメントが選択されたとしても、語彙数の制約は依然として存在する。検索が広範囲のテキストをカバーする場合、モデルに注入される文脈語彙の量を制御するために、通常、検索結果に対してTopK閾値Kが設定されるが、これは必然的に情報漏れの問題を引き起こす。
- テキストデータのみ:GPT-3.5や現段階の多くの大規模言語モデルは、画像認識機能をまだ持っていない。しかし、知識検索プロセスにおいて、多くの重要な情報を完全に理解するためには、多くの場合、グラフィックとテキストの組み合わせに依存する。例えば、学術論文の模式図や有価証券報告書のデータグラフの意味をテキストだけで正確に把握することは難しい。
- (b)大規模モデルの即興:検索された関連文献が、質問に正確に答えるための大規模モデルをサポートするには不十分な場合、モデルは、その能力を最大限に発揮して回答を完成させるために、ある程度の「即興」、つまり限られた情報に基づく推測や追加を行うことがある。
- 理論的な研究:
- [知識ベース構築 - ドキュメントのベクトル化]。
- 実践的なスキル:
- [ドキュメントのベクトル化 - テンセント・ワード・ベクター]。
- [Docs vectorisation - sbt].
- [ドキュメント ベクトル化 - SimCSE].
- [Docs vectorisation - text2vec]。
- [ドキュメントのベクトル化 - SGPT]。
- [Docs vectorisation -- BGE -- スマートソース オープンソース 最強のセマンティック・ベクターモデル].
- [Docs vectorisation - M3E: large-scale hybrid embedding].
step 3: インデックス作成
- 挙げる
- 実践的なスキル:
- [Docsビルドインデックス - Faiss]
- [Docsビルドインデックス - milvus].
- [ドキュメント インデックスの構築 - Elasticsearch].
モジュール3:ビッグ・モデルの微調整
なぜ大きなモデルを微調整する必要があるのか?
通常、大きなモデルを微調整する理由はいくつかある:
- 第一の理由は、大規模なモデルはパラメータの数が非常に多いため、それをトレーニングするコストが非常に高く、各企業は自社で大規模なモデルを一からトレーニングする必要があり、非常に費用対効果が高いことである;
- 2つ目の理由は、プロンプト・エンジニアリング・アプローチはビッグ・モデルを始めるには比較的簡単な方法ですが、明らかな欠点もあるからです。通常、ビッグ・モデルの実装原理には入力シーケンスの長さに制限があるため、プロンプト・エンジニアリング・アプローチではプロンプトが非常に長くなってしまいます。
推論コストはプロンプトの長さの2乗と正の相関があるため、プロンプトが長いほどビッグモデルの推論コストは高くなる。また、プロンプトが長すぎると、プロンプトの長さが限界を超えてしまうため、プロンプトが切り捨てられ、ビッグモデルの出力品質が低下してしまいます。個人ユーザーにとっては、日常生活や仕事の中で何らかの問題を解決するのであれば、プロンプトエンジニアリングを直接利用しても大きな問題にはなりません。しかし、外部にサービスを提供する企業にとっては、自社のサービスでビッグモデルの能力を利用するために、推論コストは考慮しなければならない要素であり、微調整は比較的良い解決策である。
- 3つ目の理由は、プロンプト・エンジニアリングの効果が要求水準に達していないこと、そして、企業がより優れた独自のデータを持っており、それを使って特定領域におけるビッグモデルの能力をより高めることができることである。このような場合には、微調整が非常に有効である。
- 第4の理由は、パーソナライズされたサービスにおいてビッグモデルのパワーを活用することである。各ユーザーのデータに対して軽量で微調整されたモデルをトレーニングすることが良い解決策となる。
- 5つ目の理由は、データのセキュリティだ。データをサードパーティのビッグモデル・サービスに渡さないのであれば、独自のビッグモデルを構築することが非常に必要だ。通常、これらのオープンソースのビッグモデルは、ビジネスのニーズを満たすために、独自のデータで微調整する必要がある。
大きなモデルをどのように微調整するのか?
Q1:大型モデルの技術的なルート微調整の問題
パラメータ・スケールの観点から大規模モデルの微調整を行うには、2つの技術的ルートに分かれる:
- 技術的なルート1:完全な量のパラメータ、完全な量のトレーニングに対して、このパスは完全な微調整FFT(Full Fine Tuning)と呼ばれる。
- テクニカル・ルートII:パラメータの一部だけをトレーニングする。この経路はPEFT(Parameter-Efficient Fine Tuning)と呼ばれる。
Q2: 大規模モデルに対するフルボリュームの微調整FFT技術の問題点は何ですか?
FFTはまた、いくつかの問題をもたらす:
- 問題1:微調整のためのパラメータ数が事前学習と同じ数であるため、学習コストが高くなる;
- 問題2:壊滅的な忘却(Catastrophic Forgetting)。特定の訓練データで微調整を行うと、その領域での成績は良くなるかもしれないが、うまくいっていた他の領域での能力も悪くなる可能性がある。
Q3: 大規模モデルのPEFT(Parameter-Efficient Fine Tuning)はどのような問題を解決するのですか?
PEFTが解決したい主な問題は、FFTの上記2つの問題であり、PEFTは現在、より主流な微調整プログラムでもある。学習データのソースや学習方法の観点から、大規模モデルのファインチューニングには以下のような技術的ルートがある:
- 技術的なルート1:教師ありファインチューニング SFT(Supervised Fine Tuning)は、機械学習における伝統的な教師あり学習アプローチを使って、手作業でラベル付けされたデータを使って大規模なモデルを微調整することに重点を置いた方式である;
- 技術的なルートII:人間のフィードバックを伴う強化学習(RLHF)、このスキームの主な特徴は、強化学習によって人間のフィードバックをビッグモデルの微調整に導入することで、ビッグモデルによって生成される結果をより人間の期待に沿うものにすることである;
- 技術ルートIII:AIフィードバックによる強化学習(RLAIF)、原理はRLHFにほぼ似ているが、フィードバックのソースはAIである。ここでは、フィードバックシステムの効率性の問題を解決しようとしている、人間のフィードバックを収集すると、相対的に言えば、コストが高くなり、効率が悪くなるからである。
分類の観点の違いは単に強調点の違いであり、同じ大きなモデルの微調整は特定のシナリオに限定されるものではなく、複数のシナリオを一緒に行うことも可能である。ファインチューニングの最終的な目標は、コストを抑えながら、特定のドメインで大型モデルの能力を可能な限り強化できるようにすることである。
ビッグモデルのLLMは、SFTオペレーションを行う際に何を学んでいるのだろうか?
- 事前学習→教師なしデータで大量に事前学習してベースモデルを得る→事前学習したモデルをSFTとRLHFの出発点として使用する。
- SFT --> 教師ありデータセットでSFTトレーニングを実施し、コンテキスト情報などの教師ありシグナルを使用してモデルをさらに最適化 --> SFTでトレーニングしたモデルをRLHFの出発点として使用。
- RLHF→人間のフィードバックを利用した強化学習により、人間の意図や嗜好によりフィットするようモデルを最適化→RLHFで学習したモデルを評価・検証し、必要な調整を行う。
ステップ1:大規模モデルの微調整トレーニングデータの構築
- はじめに:トレーニング・データの作り方
- 実践的なスキル:
- [大規模モデル(LLM) SFTデータ生成のためのLLM手法】。]
ステップ2:大規模モデル命令の微調整
- はじめに:トレーニング・データの作り方
- 実践的なスキル:
- [大規模モデル(LLM)の事前学習の継続]。
- [LLM命令の微調整】。]
- [LLMs報酬モデルトレーニング】のご案内]
- 大規模モデル(LLM)の強化学習 - PPOトレーニング編
- 大規模モデル(LLM)の強化学習 - DPOトレーニング編
モジュール4:文書検索
なぜ文書検索が必要なのか?
文書検索 RAGの中核をなす作業として、その有効性は下流の作業にとって極めて重要である。ユーザーの質問に関連する文書断片をベクトル想起によって文書リポジトリから想起し、同時にLLMに入力することで、モデルの回答品質を向上させることは可能であるが。文書想起を行う一般的な方法は、ユーザーの質問を直接使用することである。しかし、ユーザの質問が非常に口語的で曖昧に記述されていることが非常に多く、ベクトル想起の質、ひいてはモデルの応答に影響を与える。本章では、主に文書検索の過程におけるいくつかの問題点と、それに対応する解決策を紹介する。
ステップ1:文書検索 否定サンプル サンプルマイニング
- はじめに:あらゆる種類の検索タスクにおいて、良質な検索モデルを学習するためには、多くの候補サンプル集合から良質なネガティブ例をポジティブ例とともにサンプリングすることがしばしば必要となる。
- 実践的なスキル:
- [文書検索-ネガティブ・サンプル・マイニングの章]。
ステップ2:文書検索の最適化戦略
- はじめに:文書検索の最適化戦略
- 実践的なスキル:
- 文書検索 - 文書検索の最適化戦略
モジュールV:リランカー
なぜRerankerが必要なのか?
基本的なRAGアプリケーションは、4つの主要な技術コンポーネントで構成されている:
- 埋め込みモデル:外部文書やユーザークエリを埋め込みベクトルに変換するために使用されます。
- ベクトルデータベース埋め込みベクトルを保存し、ベクトルの類似性検索(最も関連性の高いTop-Kの情報を取り出す)を実行するために使用されます。
- プロンプトエンジニアリング:ユーザーの質問と検索されたコンテキストをより大きなモデルに組み合わせるためのインプット
- 大規模言語モデリング(LLM):回答生成用
上述した基本的なRAGアーキテクチャは、LLMが「幻想」を生み出し、信頼性の低いコンテンツを生成するという問題に効果的に対処している。しかし、企業ユーザーの中には、文脈の関連性とQ&Aの正確性のために、より洗練されたアーキテクチャを必要とする人もいる。実績のある一般的なアプローチは、RerankerをRAGアプリケーションに統合することです。
リランカーとは?
Rerankerは、検索結果を評価し、クエリの関連性を改善するために並び替えるための、情報検索(IR)エコシステムの重要な部分である。RAGアプリケーションでは、Rerankerは主にベクトル・クエリ(ANN)の結果を取得した後に使用され、文書とクエリ間の意味的関連性をより効果的に決定し、結果をよりきめ細かく再順位付けし、最終的に検索の質を向上させる。
step 1: パート・リランカー
- 理論的な研究:
- RAG ドキュメント検索 - リランカーセクション
- 実践的なスキル:
- [リランカー - bge-rerankerの章]。
モジュール6:RAG評価サーフェス
なぜRAGを見直す必要があるのですか?
RAG(Retrieval Augmentation Generators:検索機能拡張ジェネレータ)の探索と最適化において、その性能をいかに効果的に評価するかが重要な課題となっている。
ステップ1:RAGレビュー
- 理論的な研究:
- [RAGレビュー]
モジュール7:RAGオープン・ソース・プロジェクト 推奨学習内容
なぜRAGオープンソースプロジェクト推奨学習が必要なのか?
RAGの様々なプロセスを紹介したところで、大物たちが消化し学ぶのに役立つ、お勧めのRAGオープンソースプロジェクトをいくつか紹介しよう。
RAGオープンソースプロジェクトの推奨 - RAGFlowの記事
- はじめに: RAGFlowは、深い文書理解に基づいて構築されたオープンソースのRAG(Retrieval-Augmented Generation)エンジンです。 RAGFlowは、あらゆる規模の企業や個人向けに、信頼性の高い質問、回答、正当な引用を提供するための大規模言語モデル(Large Language Model:LLM)と組み合わせた合理化されたRAGワークフローを提供します。RAGFlowは、幅広い複雑なデータ形式に対して信頼性の高い質問、回答、正当な引用を提供する大規模言語モデル(LLM)と組み合わせて、あらゆる規模の企業や個人向けに合理化されたRAGワークフローを提供します。
- プロジェクト学習:
- RAGプロジェクトのススメ - RagFlow Part I - RagFlowのdockerデプロイメント
- RAGプロジェクトのススメ - RagFlow Part (II) - RagFlow知識ベース構築].
- RAGプロジェクトのススメ - RagFlow Part III - RagFlowモデルのベンダー選定
- RAGプロジェクトのススメ~RagFlow編(4)~RagFlow対談】のページです。]
- RAGプロジェクトのススメ - RagFlow Part (V) - RAGFlow Apiへのアクセス(へ) オラマ (例えば)]。
- RAGプロジェクトのススメ - RagFlow編(VI) - RAGFlowソースコードの学習
RAGオープンソースプロジェクトの推奨 - QAnything
- はじめに:QAnything(Question and Answer based on Anything)は、幅広いファイル形式とデータベースをサポートし、オフラインでのインストールと使用を可能にするために設計された、ローカルナレッジベースの質問と回答システムです。QAnythingを使用すると、ローカルに保存されている任意の形式のファイルを削除するだけで、正確、迅速かつ信頼性の高い回答を得ることができます。QAnythingは現在、次のようなナレッジベースのファイル形式をサポートしています:PDF(pdf)、Word(docx)、PPT(pptx)、XLS(xlsx)、Markdown(md)、電子メール(eml)、TXT(txt)、画像(jpg、jpeg、png)、CSV(csv)、ウェブリンク(html)などです。
- プロジェクト学習:
- [RAGオープンソース・プロジェクトのススメ -- QAnything [文章の一部]
RAGオープンソースプロジェクトの推奨 -- ElasticSearch-Langchainの記事
- はじめに:langchain-ChatGLMプロジェクトに触発され、Elasticsearchはテキストとベクトルの両方の方法で混合クエリを達成することができ、ビジネスシナリオでより広く使用されているため、このプロジェクトは知識リポジトリとしてFaissをElasticsearchに置き換え、Langchain+Chatglm2を使用して、知識ベースに基づいてインテリジェントなクイズを実装します。Langchain+Chatglm2を使った、独自の知識ベースに基づいたインテリジェントなQ&A。
- プロジェクト学習:
- [LLM入門】効率的な🤖ローカル知識ベースベースのElasticSearch-Langchain-Chatglm2]
RAGオープンソースプロジェクトの提言 - ラングチェーン=チャチャットの記事
- はじめに:Langchain-Chatchat(旧Langchain-ChatGLM)(ChatGLMのような)ローカル知識ベースのLLMによるQAアプリ|Langchain-Chatchat(旧langchain-ChatGLM)、ローカル知識ベースのLLMによるQAアプリ。(ChatGLMのような)知識ベースのLLM、langchainを使ったQAアプリ
- プロジェクト学習:
- [LLM入門】効率的🤖地域知識ベースに基づくラングチェーン・チャチャット]
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事


コメントはありません