
NVIDIA、VincennesグラフモデルSANAをオープンソース化:ローカル展開が4K画像から直接飛び出す

最近、エヌビディア(NVIDIA)は、マサチューセッツ工科大学および清華大学と共同で、SANAと呼ばれるオープンソースの画像生成モデルを発表した。SANAは、最大4096×4096の解像度の画像を効率的に生成できるだけでなく、生成速度も非常に速い。
SANAのパフォーマンス
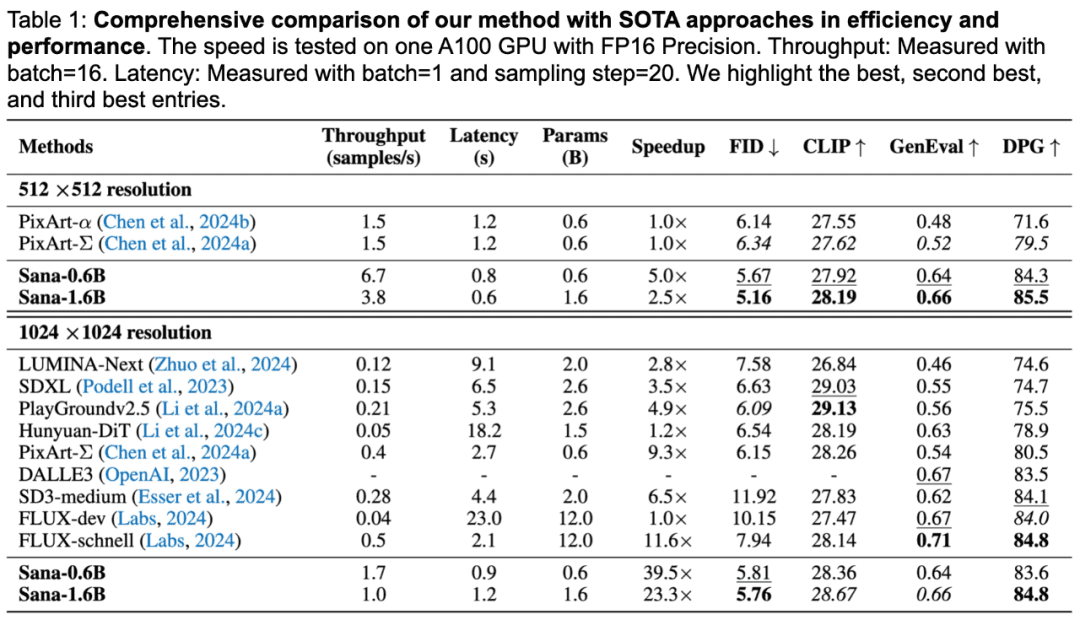
SANA-0.6Bは、1024×1024の解像度の画像を生成するのに、Flux-Devの25倍である1秒未満しかかかりませんし、4096×4096の解像度の画像を生成するのに、Flux-Devの106倍もかかります。

SANAは、DPG-BenchテストベンチマークではFluxと同等のスコアを記録し、GenEval指標ではFluxモデルをわずかに下回る程度である。
SANAのコアデザイン
SANAの成功は、4つのコア・デザインによるものだ:
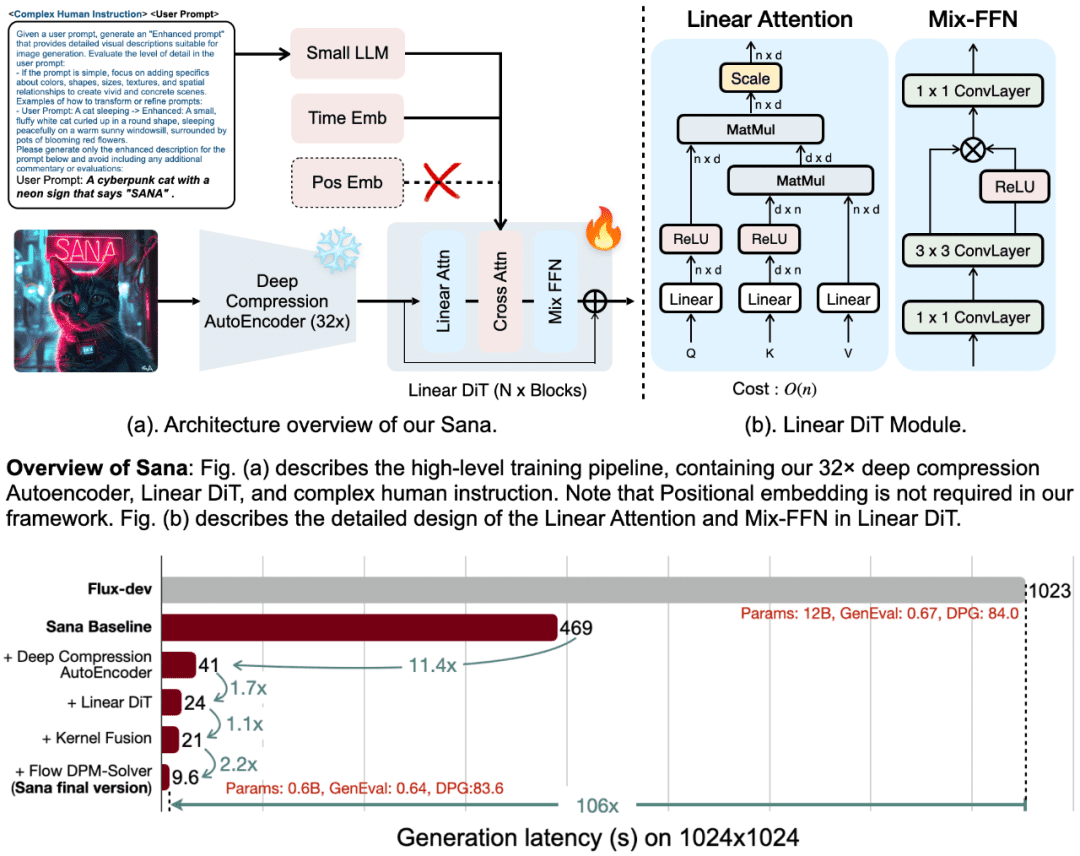
1.深圧縮オートエンコーダ(DC-AE)
従来のオートエンコーダ(AE)は通常、画像を8倍に圧縮するが、SANAは圧縮率を32倍に高める深圧縮オートエンコーダを導入している。この設計により、潜在的なマーカーの数が大幅に減少するため、SANAは、学習と生成の計算コストを大幅に削減しながら、超高解像度画像(4K解像度など)を効率的に生成することができます。
2.リニアDIT(拡散イメージトランスフォーマー)
SANAは、従来の2次注意メカニズムの代わりに、新しい線形注意メカニズムを採用し、複雑さをO(N²)からO(N)に低減する。この改善により、高解像度画像生成の効率が向上するだけでなく、位置符号化が不要となり、位置埋め込みを必要としない最初のDITモデルとなる。
3.テキスト・エンコーダとしての小型デコーダ専用LLM
SANAでは、従来のCLIPやT5モデルに代わって、Gemma 2のような小型のデコーダのみの言語モデルをテキストエンコーダとして使用しています。Gemmaは、優れたテキスト理解能力と命令順守能力を持っており、洗練された手動命令設計と組み合わせることで、画像とテキストの位置合わせを大幅に改善します。
4.効率的なトレーニングと推論戦略
SANAは、複数の視覚言語モデル(VLM)を用いて異なる再キャプションを生成し、CLIPScoreに基づいて高品質のキャプションを選択する自動ラベリングと学習戦略を提案する。さらに、SANAはFlow-DPM-Solverを導入し、推論ステップを大幅に削減し、生成効率をさらに向上させている。
低コストでの導入とオープンソース
SANA-0.6Bは、16GBのラップトップGPUで動作し、1秒以内に1024×1024解像度の画像を生成することができ、22GBのビデオメモリで4096×4096解像度の画像をストレートに生成することができます。ノートパソコンでも効率的に動作します。さらに、NVIDIAは、SANAのコードとモデルを一般に公開し、テキスト画像生成技術の普及と応用をさらに促進する予定であることも発表した。
利用する
NVIDIAは、8つの3090ウェブ使用インタフェースを構築し、誰でも無料で試すことができる。SANAモデルは、中国語のプロンプト・ワードで直接使用できることは特筆に値する。
アイコンシンボルによるキューワードの使用も可能で、これはテキストエンコーダとしてGemma2 2B視覚言語モデルを使用することで恩恵を受けるはずだ。

ComfyUI_ExtraModelsプラグインを使用すると、ネイティブのComfyui上でSANAモデルを非常に簡単に使用することができます。プラグインのインストールは非常に簡単で、依存関係を設定する必要がなく、インストール後に実行すると、必要なモデルファイルが自動的にダウンロードされます。
深い圧縮オートエンコーダ、リニアDIT、デコーダのみの小さなLLM、効率的な学習と推論戦略により、SANAは効率的に超高解像度の画像を生成できるだけでなく、強力なテキスト-画像アライメント能力と低コストな展開の利点を備えている。迅速に画像を生成する必要がある場合、SANAはやはり優れている。つまり、エコロジーの面ではFluxとは比較にならない。

プロジェクトのページ:
github.com/NVlabs/Sana
ウェブ利用:
nv-sana.mit.edu
Comfyui プラグイン:
github.com/Efficient-Large-Model/ComfyUI_ExtraModels
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事




コメントはありません