小型モデル、ビッグパワー:QwQ-32B、1/20パラメータで本格派DeepSeek-R1と戦う

近年、AIの分野、特に大規模言語モデル(LLM)の推論能力の向上において、目覚ましい進歩が見られる。その中でも強化学習(RL)は、従来のモデルの性能ボトルネックを解消するための重要な技術になりつつある。多くの研究で、RLがモデルの推論能力を大幅に向上させることが確認されている。例えば、DeepSeek R1モデルは、コールドスタートデータと多段階学習を統合することで、深い思考と複雑な推論を実現し、当時のトップレベルに到達した。
こうした中、AliCloudはQwQ-32Bモデルを発表し、再び業界の注目を集めている。320億のパラメーターを持つこのモデルは、その性能において ディープシーク-R1 QwQ-32Bは、6,710億個のパラメータ(370億個の活性化パラメータ)を持つ。 QwQ-32Bの卓越した性能は、膨大な世界知識で事前に訓練された強力な基本モデルの知性を向上させる強化学習の有効性を強く示すものである。
さらに、アリユン社はQwQ-32Bの推論モデルにエージェント関連の機能も組み込んでおり、批判的に考えるだけでなく、ツールを活用し、環境からのフィードバックに基づいて推論プロセスを調整することも可能にしている。これらの技術的進歩は、RL技術の変革の可能性を示し、一般人工知能(AGI)への道を開くものである。
現在、QwQ-32Bは、Apache 2.0オープンソースプロトコルの下、Hugging FaceとModelScopeプラットフォーム上でリリースされており、ユーザーは以下の方法でアクセスできます。 Qwenチャット 経験。

はじめに
QwQは "Qwen "ファミリーの推論モデルであり、従来の命令微調整モデルと比較して、より強力な思考・推論能力を持ち、下流タスク、特に複雑なパズルを解く際に大きなパフォーマンス向上を示す。はDeepSeek-R1やo1-miniのような高度な推論モデルに匹敵する。
モデルの特徴
- 類型論因果言語モデル
- トレーニング段階教師ありの微調整と強化学習を含む、事前学習と事後学習。
- ビルドRoPE位置符号化、SwiGLU活性化関数、RMSNorm正規化、注意QKVバイアスを持つトランスフォーマー構造 注意メカニズムバイアス
- パラメータスケール325億ドル (32.5B)
- 非エンベデッドレイヤーのパラメータサイズ310億ドル (31.0B)
- 階: 64
- ヘッズ・オブ・アテンション(GQA)クエリー側が40、キー/バリュー側が8。
- コンテキストの長さフル131,072 トークン
銘記するを参照してください。 使用ガイドライン QwQモデルは後に展開される。
ユーザーは デモ 経験を積むか、あるいは クウェンチャット QwQモデルにアクセスするには、Thinking (QwQ)を開いてください。
より詳細な情報については GitHubリポジトリ も 公文書.
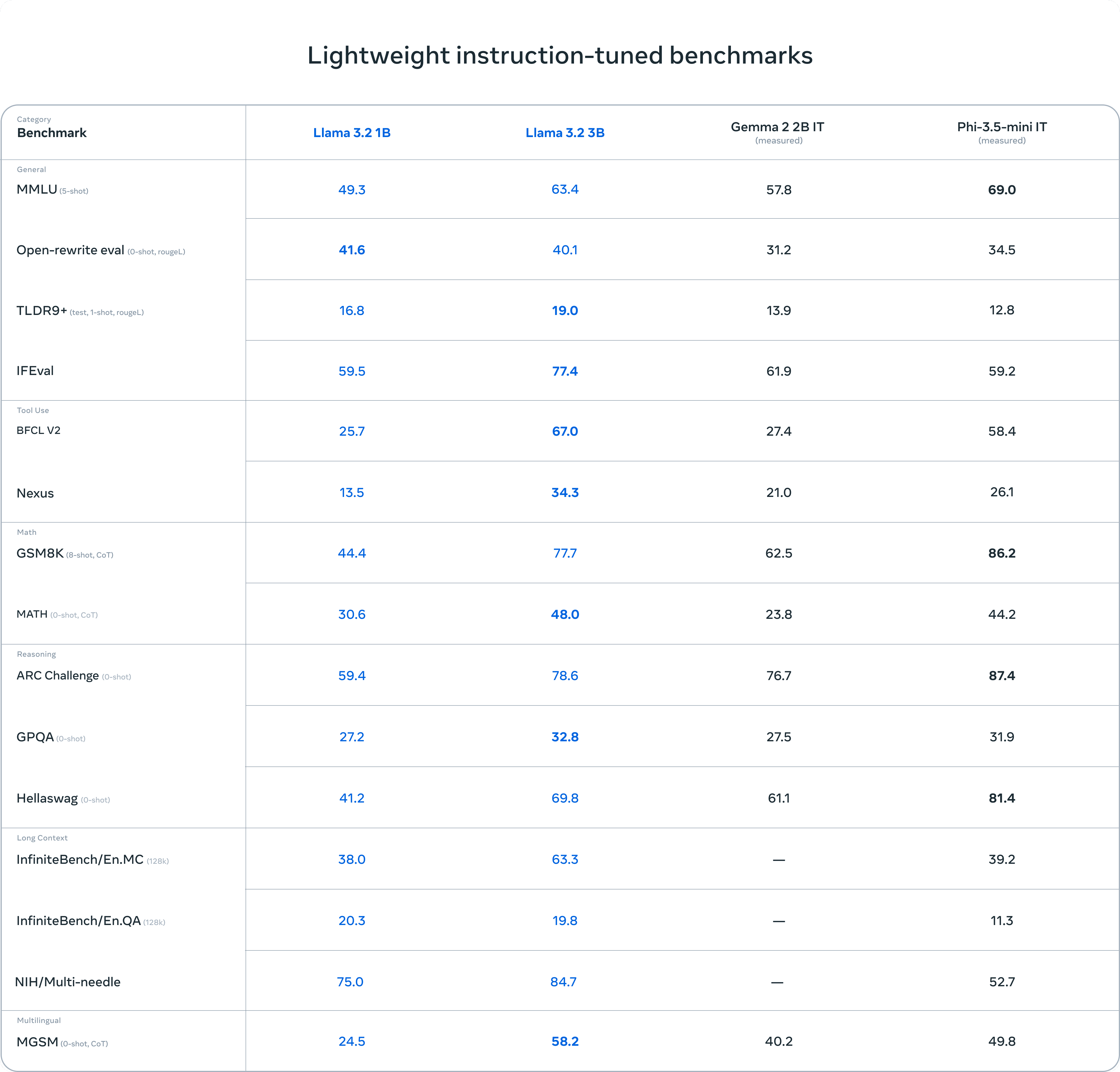
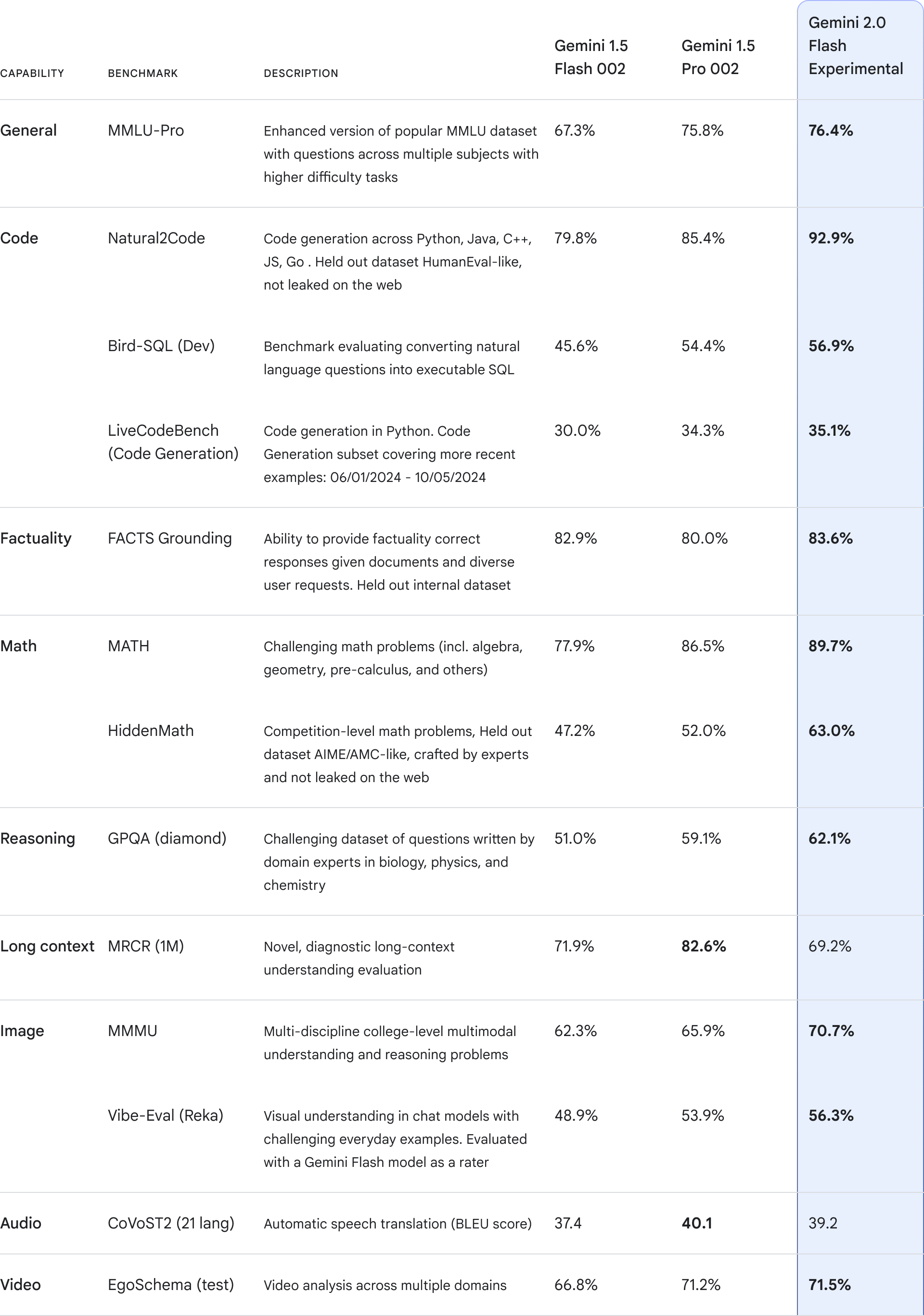
パフォーマンス
QwQ-32B モデルは、数学的推論、コード記述、一般的な問題解決における QwQ-32B の能力を総合的に評価す るために設計された一連のベンチマーク・テストで評価されました。以下のチャートは、DeepSeek-R1-Distilled-Qwen-32B、DeepSeek-R1-Distilled-Llama-70B、o1-mini、オリジナルの DeepSeek-R1 などの他の主要モデルに対する QwQ-32B のパフォーマンスを示しています。

その結果、QwQ-32Bはいくつかの主要ベンチマークにおいて上位モデルと同等か、それ以上の性能を示した。特に注目すべきは、QwQ-32Bが、QwQ-32Bよりもはるかに多くのパラメータを持つDeepSeek-R1に対して依然として競争力を維持していることであり、このことは、モデルの性能向上における強化学習の大きな可能性をさらに証明している。
強化学習
QwQ-32Bの卓越した性能は、その背後にある強化学習(RL)技術によるところが大きい。 簡単に言えば、強化学習とは、報酬や罰のメカニズムを通じて、与えられた環境で最適な決定を下すようモデルを学習させる手法である。 従来の教師あり学習とは異なり、強化学習はラベル付けされた大量のデータに頼るのではなく、環境と相互作用しながら試行錯誤で学習し、最終的にタスクを完了するために必要な戦略をマスターする。
QwQ-32Bのトレーニング中、アリユンの研究チームは、コールドスタートのチェックポイントから始めて、結果報酬に基づく強化学習拡張法を実施した。初期段階では、数学とコードタスクのRL拡張に焦点を当てた。従来の報酬モデルに依存する代わりに、研究チームは、最終的な解答の正しさを保証するために数学の問題に精度検証器を使用し、生成されたコードが事前に定義されたテストケースを正常に通過したかどうかを評価するためにコード実行サーバーを使用した。
トレーニングが進むにつれ、数学とコードの両領域におけるモデルの性能は一貫して向上した。第一段階の後、研究チームは汎用的な能力に対するRLトレーニング段階を追加した。 この訓練フェーズでは、一般的な報酬モデルからの報酬信号と、多数のルールベースのバリデータが使用された。実験結果は、少数のステップのRL訓練により、数学およびコード能力において著しい性能劣化を引き起こすことなく、指示の順守、人間の嗜好の整合、およびエージェントの性能の観点から、モデルの汎用能力を効果的に向上させることができることを示している。
クウェン2.5-3Bが優れた推理力を持つ理由についての記事を紹介しよう:ビッグモデルはいかにして "賢く "なるのか?スタンフォード大学が自己改善のカギを明かす:4つの認知行動
使用ガイドライン
最適なパフォーマンスを得るためには、以下の設定を推奨します:
- モデルにアウトプットを考えさせる:モデルが以下の方法でモデリングされていることを確認する。
<think>\nを使用する場合は、出力の質を低下させる可能性がある空の思考コンテンツを生成することを避けるために、開始する必要があります。もしapply_chat_templateそしてadd_generation_prompt=Trueこれは自動的に実装される。ただし、この場合、レスポンスが<think>ラベリング。 - サンプリング・パラメーター:
- 利用する
Temperature=0.6歌で応えるTopP=0.95貪欲な解読の代わりに、終わりのない繰り返しを避ける。 - 利用する
TopKレアなものを除外するために20から40の間 トークン 生成されるアウトプットの多様性を維持しながら。
- 利用する
- 標準化された出力フォーマットベンチマークの際には、プロンプト・プロンプトを使用してモデル出力を標準化することをお勧めします。
- 数学の問題プロンプトに「ステップバイステップで推論し、最終的な答えを"☑"内に記入してください。 「を追加してください。
- たくいつもんだいプロンプトに以下のJSON構造を追加し、レスポンスを標準化する。
answerフィールドに選択肢の文字だけを入力する。\"answer\": \"C\". "(以下の項目をanswerフィールドには選択した文字だけが表示されます。\"answer\": \"C\").
- 長い入力の処理トークンが32,768個を超える入力の場合は、以下を有効にしてください。 YaRN のテクニックを使って、長いシーケンス情報を効果的に捉えるモデルの能力を向上させた。
サポートされているフレームワークでは、以下を config.json ファイルでYaRNを有効にする:
{
...,
"rope_scaling": {
"factor": 4.0,
"original_max_position_embeddings": 32768,
"type": "yarn"
}
}
デプロイメントには、vLLMを推奨します。vLLMに慣れていない場合は、以下を参照してください。 公文書 で使用量を取得できる。現在のところ、vLLMは静的なYARNしかサポートしていない。つまり、入力の長さが変わってもスケーリング係数は一定である。これは、短いテキストを扱うときのモデルのパフォーマンスに影響する可能性があります。.したがって、長いコンテキストは、処理が必要な場合にのみ追加することをお勧めします。 rope_scaling コンフィギュレーション。
QwQ-32Bの使い方(QwQ-32Bを使う)
以下の簡単な例では、Hugging Face TransformersとAliCloud DashScope APIを介してQwQ-32Bモデルを使用する方法を示しています。
via ハグする顔のトランスフォーマー。
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/QwQ-32B"
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
prompt = "How many r's are in the word \"strawberry\""
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(
**model_inputs,
max_new_tokens=32768
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(response)
AliCloud DashScope API経由。
from openai import OpenAI
import os
# Initialize OpenAI client
client = OpenAI(
# If the environment variable is not configured, replace with your API Key: api_key="sk-xxx"
# How to get an API Key:https://help.aliyun.com/zh/model-studio/developer-reference/get-api-key
api_key=os.getenv("DASHSCOPE_API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1"
)
reasoning_content = ""
content = ""
is_answering = False
completion = client.chat.completions.create(
model="qwq-32b",
messages=[
{"role": "user", "content": "Which is larger, 9.9 or 9.11?"}
],
stream=True,
# Uncomment the following line to return token usage in the last chunk
# stream_options={
# "include_usage": True
# }
)
print("\n" + "=" * 20 + "reasoning content" + "=" * 20 + "\n")
for chunk in completion:
# If chunk.choices is empty, print usage
if not chunk.choices:
print("\nUsage:")
print(chunk.usage)
else:
delta = chunk.choices[0].delta
# Print reasoning content
if hasattr(delta, 'reasoning_content') and delta.reasoning_content is not None:
print(delta.reasoning_content, end='', flush=True)
reasoning_content += delta.reasoning_content
else:
if delta.content != "" and is_answering is False:
print("\n" + "=" * 20 + "content" + "=" * 20 + "\n")
is_answering = True
# Print content
print(delta.content, end='', flush=True)
content += delta.content
今後の課題
QwQ-32Bのリリースは、強化学習(RL)をQwenファミリーのモデルで拡張し、推論を強化するための初期段階であるが、重要なステップである。 この探求を通じて、Aliyunは強化学習の拡張アプリケーションの大きな可能性を目の当たりにしただけでなく、事前に学習された言語モデルの未開発の可能性も認識しました。
次世代の「千の質問」モデルの開発を見据えて、アリユンは自信を持っている。よりロバストなベースモデルと、スケーラブルな計算リソースを活用した強化学習技術を組み合わせることで、一般人工知能(AGI)の最終的な目標を加速させることができると考えている。さらに、アリクラウドは、より長距離の推論能力を可能にするために、RLとエージェントのより深い統合を積極的に模索しており、推論の時点でスケーリングすることにより、より大きな知性を引き出すことに全力を注いでいる。
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事


コメントはありません