Xiaomi-MiMo-Audio-シャオミ・オープンソース初のネイティブ・エンド・トゥ・エンド・スピーチ・ビッグモデル

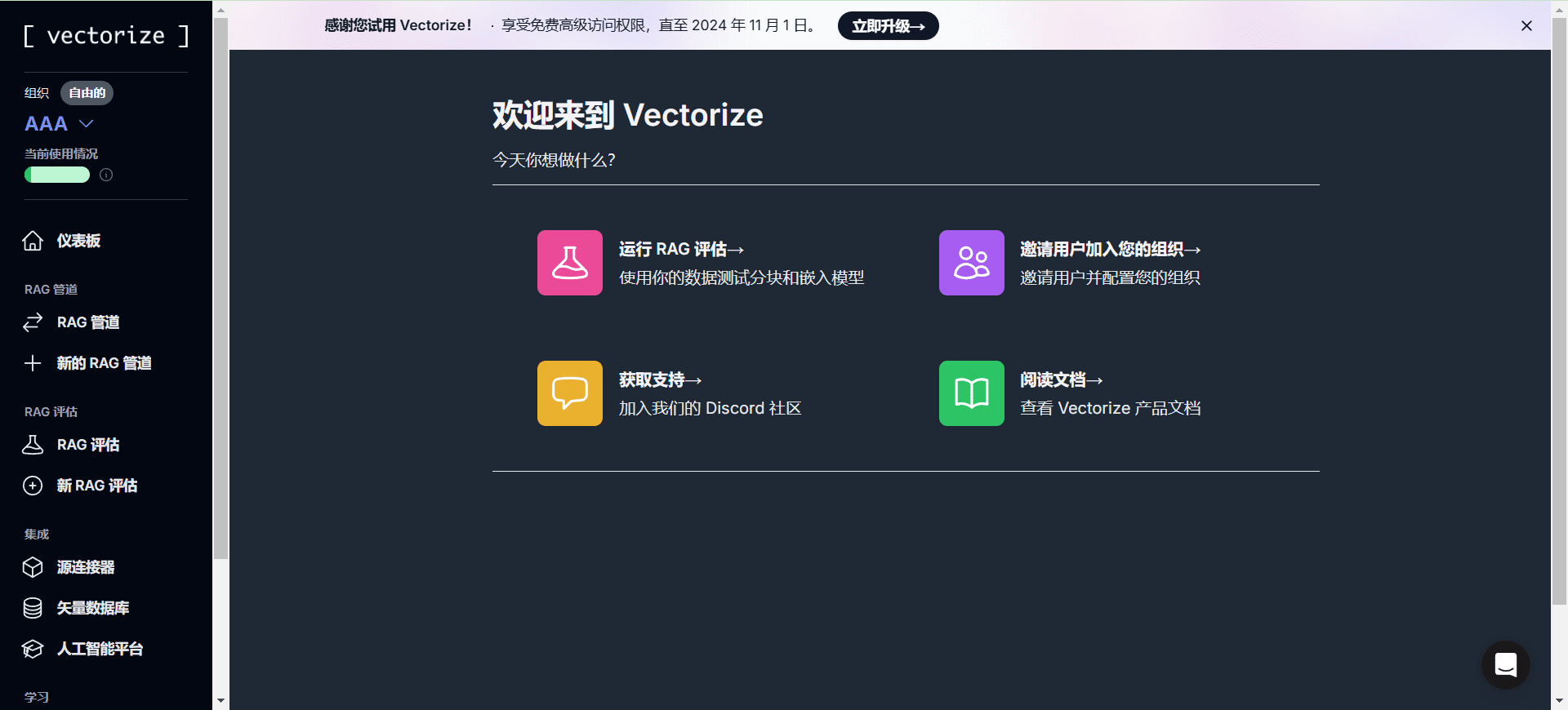
Xiaomi-MiMo-Audioとは?
Xiaomi-MiMo-Audioは、多言語対話、音声継続、サンプル数の少ない汎化、音声理解などの強力な機能を備えたXiaomiのオープンソース70億パラメータエンドツーエンド音声マクロモデルであり、音声インテリジェンスおよび音声理解ベンチマークにおいてSOTAレベルに達することができ、Google Gemini-2.5-Flashなどのモデルを凌駕しています。このモデルの革新的な音声ロスレス圧縮事前学習と音声生成事前学習技術により、音声変換やスタイル移行などのタスクで優れた性能を発揮することができます。Xiaomiは、音声ビッグモデルの研究と音声AGIの開発を支援するために、事前学習モデルMiMo-Audio-7B-Base、コマンド微調整モデルMiMo-Audio-7B-Instruct、MiMo-Audio Tokenizerモデル、技術レポート、評価フレームワークをオープンソースとして提供しています。
Xiaomi-MiMo-Audioの特徴
- 多言語対話哲学や人生の理想など、幅広いトピックをカバーし、ユーザーとの円滑なコミュニケーションをサポートします。
- 音韻続編スタンドアップコメディ、朗読、生放送、ディベートなどにおいて、話者の同一性、リズム、環境音などの主要な音響特性を保持しながら、非常にリアルなスピーチコンテンツを生成します。
- サンプルの少ない一般化訓練データに特定のタスク(例えば、音声変換、スタイル移行、音声編集)がない場合でも、容易に対応することができ、強力な汎化能力を示しています。
- 音声理解音声キャプション、音声推論、長時間の音声理解により、長時間の音声シーケンスを処理・分析し、詳細な説明と詳細な分析を提供します。
MiMo-Audioの核となる利点
- 超大規模な事前学習データ1億時間を超える音声データに基づく事前トレーニングにより、モデルに強力な汎化能力を与え、トレーニングデータにない複雑なタスクに優れた能力を発揮します。
- 独自のロスレス音声圧縮プリトレーニング技術低サンプル学習でモデルが「創発的」な振る舞いを示し、学習効率を向上させる。
- 初のオープンソース音声継続機能オープンソース初の発話継続機能搭載モデルとして、漫才や朗読などリアルな発話コンテンツを生成し、新たな創作の可能性をもたらします。
- パワフルな音声理解音声キャプション、推論、長時間の音声理解、長時間の音声シーケンスの処理、音声コンテンツの注釈と分析を自動化するための正確な分析を得意としています。
- 思考モデルの導入これは、音声対話においてより柔軟で自然なモデルとなり、さまざまなシナリオやニーズに適応します。
Xiaomi-MiMo-Audioの公式ウェブサイトは?
- プロジェクトのウェブサイト:: https://xiaomimimo.github.io/MiMo-Audio-Demo/
- GitHubリポジトリ:: https://github.com/XiaomiMiMo/MiMo-Audio
- HuggingFaceモデルライブラリ:: https://huggingface.co/collections/XiaomiMiMo/mimo-audio-68cc7202692c27dae881cce0
- 技術論文:: https://github.com/XiaomiMiMo/MiMo-Audio/blob/main/MiMo-Audio-Technical-Report.pdf
Xiaomi-MiMo-Audioは誰のためのものですか?
- 音声技術開発者音声アシスタント、音声対話アプリケーションなどの開発に使用する強力な音声モデルを開発者に提供し、音声技術製品の開発と革新を加速する。
- ボイス・コンテンツ・クリエーターオーディオブック、ポッドキャスト、トーク番組などの音声コンテンツを効率的に制作し、制作の効率と質を向上させる。
- 語学学習者言語学習ツールとして、口頭練習や言語コミュニケーションのための疑似環境を学習者に提供することで、言語学習を促進する。
- ゲーム開発者ゲーム内のキャラクターを生き生きとした声で演じ、ゲームへの没入感を高める。
- 教育者教育内容を音声講義に変換し、音声講座やオンライン講義を制作し、教育形態を充実させ、教育効果を向上させる。
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事


コメントはありません