



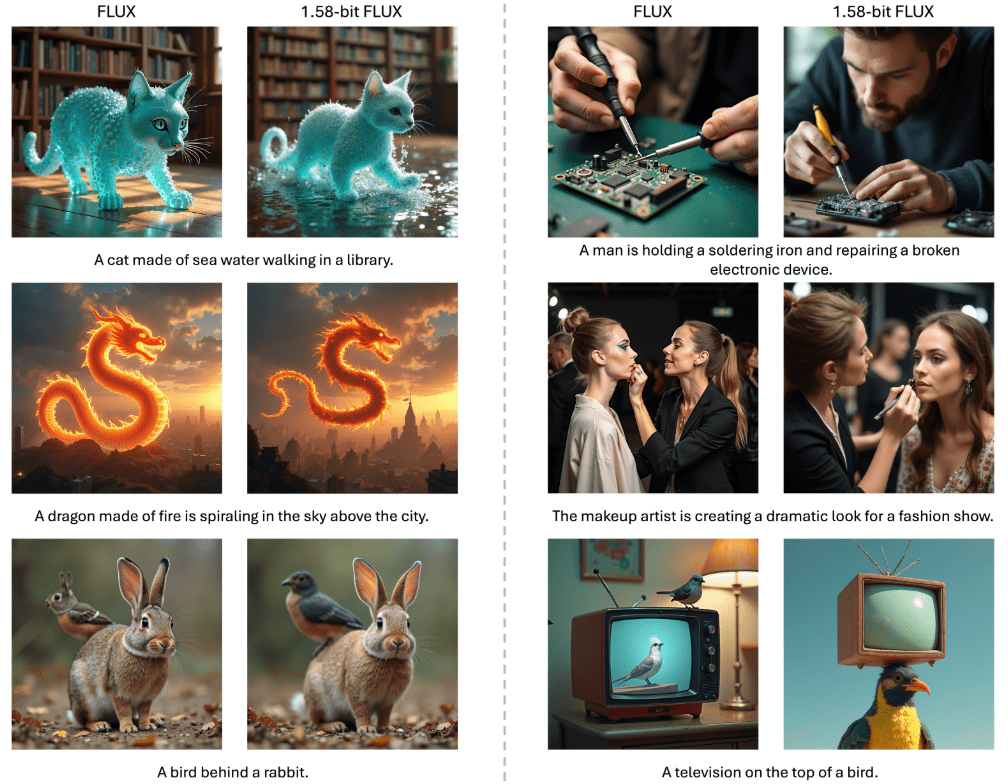
プロジェクトレベルのコード生成結果が出た! o3/Claude 3.7がリードし、R1がトップクラス!


2025年2月26日、SuperCLUEはプロジェクトレベルのコード生成(SuperCLUE-Project)測定ベンチマークの初回リストを発表した。
評価プログラムについては、プロジェクトレベルコード生成評価ベンチマークリリースをご覧ください。本評価は、ビッグモデルの「ジャッジパネル」の協力のもと、ゲーム開発、ツール、管理システムなど5つのアプリケーションシナリオを対象に、プロジェクトレベルのコード生成タスクにおける国内外のビッグモデル12機種の能力を評価するものです。以下に詳細な評価レポートを掲載する。
プロジェクトレベルのコード測定結果のまとめ
概要1: o3-ミニハイとクロード-3.7-ソネット-推論がリードしている
今回の評価では、OpenAIがリリースしたo3-mini-highが82.08、Anthropicが新たにリリースした推論モデルClaude-3.7-Sonnet-Reasoningが81.63の総合スコアを獲得し、両者が手を取り合って首位に立った。
概要2:DeepSeek-R1が国内モデルをリードし、業界トップクラスにランクイン
評価結果から、DeepSeek-R1と業界の最先端モデルであるo3-mini-high、Claude-3.5-Sonnet/3.7-Sonnet-Reasoning、Gemini-2.0-proとのスコア差は極めて小さく、アプリケーションのシナリオによっては一定の優位性を獲得している。
まとめ3:それぞれに強みがある。r1はゲーム開発、o3/Step Step Rはマルチメディア編集、そしていくつかはウェブアプリケーションに特化している。
例えば、DeepSeek-R1は「ゲーム開発」の分野で傑出しており、Claude-3.5-Sonnet、Beanbag 1.5pro、Tongyiqianqian Maxは「ウェブアプリケーション」の設計により特化しているなどである。Claude-3.5-Sonnet、Beanbag 1.5pro、Tongyiqianqian Maxは「ウェブアプリケーション」設計により特化しており、StepStar Step R-miniは「マルチメディア編集」ツールの開発などで独自の優位性を持っている。
要旨4:モデルによって、方法論の選択、インターフェースのスタイルが著しく異なる。
モデルの回答を比較すると、同じユーザー要件に直面しても、モデルによって選択するプログラミング言語、ライブラリ/モジュールの呼び出し方、インターフェイスの美観が大きく異なることがわかる。
リストの概要
SuperCLUE-プロジェクト評価システム
SuperCLUE-Projectは、ユーザーのプロジェクトレベルの要求をコード実装に変換する大規模モデルの能力を検証するために設計された、中国語ネイティブのプロジェクトレベルのコード評価ベンチマークです。 
SuperCLUE-Projectは、ノンプログラマーのユーザーグループの実際のニーズに焦点を当て、5つの第一レベルの次元と18の第二レベルの次元をカバーし、中国語の自然言語で質問セットを構築します。ノンプログラマコミュニティの特性を考慮し、トピック設計では要求記述の機能レベルのみを重視し、効率性、安全性、可読性などの指標を、評価セッションで評価される大規模モデルプレイヤーの独立した能力として位置づけています。
さらに、ベンチマークには、モデルのプロジェクトレベルのコード実装能力をより深く理解するために、同じトピックセットに対して全体的にスケーリングされた3つの難易度、簡単 - 中 - 複雑がある。
方法論
SuperCLUEのきめ細かな評価アプローチを参考に、以下のプロセスで評価を行う:
1) 測定セットの構成
1.大規模なモデル支援によるローコード/ゼロコード開発分野のダイナミクスを懸念し、ノンプログラマー・グループのコード・プロジェクト要件を収集、照合する。
2.簡単な難易度のプロジェクトレベルのコード評価セットを書く
3.書式と語数の範囲を制御して、評価セットを中級/複雑な難易度レベルに拡張する。
4.テストと手動校正
2) 採点プロセス
1.評価ルールの作成(プロンプト) ---> 評価ルールの作成(プロンプト)
2.レフリーモデルの評価と人間の専門家の評価の整合性を手作業でチェックする小規模テスト ---> 。
3.一貫性フィードバックに基づく評価ルールの反復チューニング ---> 。
4.完全な評価を受けるために、テストされるモデルの応答と評価ルールの完全なセットを2つの審判モデルにそれぞれ渡す --->。
5.各次元における2つの裁定モデルの得点の平均を最終結果として算出する。
3)人間コヒーレンス分析
測定セットの層別サンプリングは、グループ内相関係数を計算し、そのパフォーマンスを報告することによって、レフリーモデルの評価と人間の専門家の評価の一貫性をテストするために行われた。
SuperCLUE-Projectでは、従来のベンチマークと比較して、評価の実施において初めて国産モデルと海外モデル(Gemini-2.0-flashとQwen-Max)の両方をレフェリーとして導入し、「レフェリーチーム」の協力により、大型モデルの偏りや選好の問題をさらに軽減している。(レフェリーチーム」の協力により、大型モデルの偏りや選好の問題はさらに軽減される)。
また、SuperCLUE-Projectでは、レフリーモデルの信頼性を検証するために、クラス内相関係数(ICC)を初めて導入し、人間の専門家の評価、Qwen-Max、Gemini-2.0-flash(ICC(3,k))指標を算出し、レフリーモデルが人間の評価と強く一致することを検証した。過去のパーセンテージ信頼性と比較して、この方法はランダムエラーの変動効果を効果的に克服している。
(グループ内相関係数(ICC)は、観察者間信頼性やテスト・リテスト信頼性を測定・評価するための信頼性係数指標の一つで、1966年にBartkoによって信頼性の大きさを測定・評価するために初めて用いられた。ICCは、個人のばらつきを全体のばらつきで割ったものに等しい。この実験では、選択されたレフェリー・モデルと人間の専門家の評価との間の一貫性だけを考慮すればよく、他の評価者に拡張する必要がないため、二元混合効果指数を一貫性指数として選択した)。
評価基準
- Functional Integrity(60%):コードがユーザー命令に記述されたすべての機能を完全に実装していることを保証する。
- コード品質(28%):効率性、可読性、セキュリティの観点からコードの性能を評価する。具体的には以下が含まれる:
a. 効率性(12%):リソースの使用、DOM操作、データベース/大規模データセットの処理、計算、API呼び出しの点でコードが十分に最適化されているかどうか。
b. 読みやすさ(8%):コードが、(1) 明確な命名と一貫した書式の使用、(2) コードベースのモジュールへの論理的な分割、(3) 明確なプロジェクト構造の維持を実施しているかどうか。
c. セキュリティ(8%): コードに(1)明らかなセキュリティホールがないか、(2)基本的な例外を効果的に処理できるか。
- ユーザー・エクスペリエンス(12%):インタラクティブな要素(ボタンやフォームなど)の適切な機能や、インターフェイス全体の基本的な美しさなど、ユーザー・インターフェイスのデザインと美観の質を評価する。
SuperCLUE-Projectは、これまでの評価基準の設計と比較して、比較的バランスの取れた採点メカニズムを変更し、一般ユーザーが最も気にする能力でもある機能的な実装面の採点ウェイトを大幅に強調しました。
さらに、SuperCLUE-Projectの評価基準では、減点方式の採点モードが規定されている。つまり、デフォルトの満点をベースに、設問と対応するコード実装の比較に基づいて、設問の要件を満たしていない部分を減点する。このような一問一答の個別評価方式では、減点方式は、複数の回答の相対的な質を調べるという大型模範解答の欠点をある程度補い、大型模範解答の評価を緩和します。確率論.
参加モデル
プロジェクトレベルのコード要件を解決するための国内外の大型モデルの現在の能力レベルを総合的に測定するため、今回の評価では、代表性の高い国内モデル7機種と海外モデル5機種を選定した。

評価結果
全体リスト
アプリケーション・シナリオ一覧 
レビューと人間整合性分析
SuperCLUE-Projectベンチマークの人間の専門家との整合性を科学的に評価するために、評価結果から総合的なパフォーマンスが良い、平均的、悪い3つのモデルを選択し、33の質問と答えのペアを層別化し、2つのレフェリーモデルによる手動独立採点と質問ごとの採点を実施し、3つのスコアの合計の整合性の割合、グループの相関係数を報告し、大きなモデルの専門性を科学的に検証した。レフェリー・パネル」採点のプロフェッショナリズムを科学的に検証した。

注:ICC-3kの値が0.75以上であれば、一般的に評価者間の一致度が高いことを示すと考えられている。
評価事例
例1 ゲーム開発(パズル、難易度)
プロンプト点つなぎゲームを実装するコードを書き、ランダムに多色で間隔が狭いm * n個の小さな立方体(ゲームを始める前にユーザーが指定したm, nは5以上の整数)を出現させ、ユーザーが2つの立方体をクリックし、色が同じで、接続されたパス(水平方向と垂直方向のみ許可)が2ターン以上なければ、2つの立方体を消去する。まばたきを3回する。プレイヤーは既存のマスの配置を崩すチャンスが3回ある。3秒以内に2つのマスを連続して消すことに成功すると、画面に「コンボ!」と表示される。
ビッグモデルRef1(Gemini-2.0-flash):
用户指令中包含的需求 (基于独立分析) 1.创建游戏界面: 创建一个m*n的方块网格,m和n由用户指定(大于5的整数)。 2.方块颜色随机化: 随机生成多种颜色的方块,并确保每种颜色出现偶数次,以便可以两两消除。 3.消除规则: 当用户点击两个颜色相同的方块,且它们之间可以通过不多于两次转弯的路径连接时,消除这两个方块。 4.错误提示: 如果用户点击的两个方块不满足消除规则,则点击的方块闪烁三次。 5.打乱功能: 允许玩家打乱方块排列,总共有三次机会。 6.连击奖励: 如果用户在3秒内连续成功消除两次,则显示 "Combo!"。 对代码缺陷的总体点评 该代码实现了一个基本的连连看游戏,实现了方块的随机生成、消除规则、错误提示、打乱功能和连击奖励。但是,代码在用户体验和效率方面存在一些不足。例如,方块闪烁效果不够流畅,消除方块后的界面更新不够及时。 各项标准的评分 -- 功能完整性:[[15]] 分 (实现了所有功能,包括随机生成方块、消除规则、打乱功能和连击奖励。所有核心功能均已实现,因此不扣分。) -- 代码质量:[[5]] 分,其中: 效率:[[2]] 分 (代码在生成棋盘时,先创建了一个包含所有颜色的列表,然后进行随机打乱。这种做法在m和n较大时,可能会影响效率。此外,在判断两个方块是否可以消除时,使用了广度优先搜索算法。虽然该算法可以找到最短路径,但在大规模棋盘上,可能会比较耗时。因此,扣1分。) 可读性:[[2]] 分 (代码的命名基本清晰,但部分代码块的注释不足,例如,对于广度优先搜索算法的解释不够详细。代码的整体结构良好,但可以进一步模块化,例如,将游戏逻辑和界面绘制分离。因此,不扣分。) 安全性:[[1]] 分 (代码没有明显的安全漏洞,但是,对于用户输入的m和n,只做了简单的数值范围检查,没有考虑其他异常情况,例如,用户输入非整数。因此,扣1分。) -- 用户体验:[[1]] 分 (游戏界面基本可以运行,但是,方块闪烁效果不够流畅,消除方块后的界面更新不够及时。此外,游戏缺少音效和动画效果,用户体验有待提升。因此扣2分。) 综上所述,该代码实现的总体得分为 <<21>> 分。
ビッグモデルのレフェリー2(Qwen-Max):
用户指令中包含的需求 (基于独立分析) 1. 游戏界面应随机出现多种颜色的、紧密排列的m*n个小方块,其中m和n由用户指定且均为大于5的整数。 2. 用户点击两个方块,如果颜色相同且相连接路径(仅允许水平和垂直两个方向)不多于两次转弯,则消除两方块。 3. 如果不满足消除规则,则点击的两个方块闪烁三下。 4. 玩家有三次机会可以打乱现有方块的排列。 5. 如果用户在3秒内连续成功消除两次,则在屏幕上显示"Combo!"。 对代码缺陷的总体点评 代码实现了基本的游戏逻辑,包括生成游戏板、检测方块是否相连以及处理玩家输入等。 代码结构较为清晰,但部分地方可以进一步优化以提高可读性和效率。 各项标准的评分 -- 功能完整性:[[15]] 分 该代码实现完全符合用户指令中的所有功能要求: 生成了m*n的小方块,且m和n由用户指定且均为大于5的整数。 用户点击两个方块,如果颜色相同且相连接路径不多于两次转弯,则消除两方块。 不满足消除规则时,点击的两个方块闪烁三下。 玩家有三次机会可以打乱现有方块的排列。 用户在3秒内连续成功消除两次时,在屏幕上显示"Combo!"。 -- 代码质量:[[5]] 分,其中: 效率:[[3]] 分 代码整体上对资源利用合理,没有明显的性能瓶颈。但由于未考虑极端情况下可能出现的问题,故保持满分。 可读性:[[1]] 分 虽然变量命名较清晰,但函数is_connected中的逻辑稍显复杂,不易理解。此外,主循环内的逻辑也可以通过更合理的模块化来改善。 安全性:[[1]] 分 代码缺乏对用户输入的有效验证,比如确保输入的是正整数。同时,对于某些潜在错误(如文件操作失败)也没有相应的处理机制。 -- 用户体验:[[2]] 分 游戏界面基本美观,交互元素工作正常。但是,由于方块闪烁次数符合要求,用户体验的一致性较好。 综上所述,该代码实现的总体得分为 <<22>> 分。
総合評価:[21.5/25]
# 事例2 ゲーム開発(シューティング、難易度高)
プロンプト: シンプルな空戦ゲームを実装するコードを書いてください。プレイヤーはインターフェイスの下部にある飛行機を左右の矢印キーで操作して、上から飛んでくる障害物を避け、スペースバーを押して上空から敵機を撃ちます。敵機はランダムに左右に移動して発砲します。ライフの初期値は3で、障害物に当たったり敵機に当たったりするたびにライフが1減り、ライフが0になるとゲームが終了する。敵機は最初のレベルで3機、その後の各レベルでさらに3機登場する。モードA(デフォルト)は敵機の正面にしか撃てず、1発で破壊します。モードBは多方向に発射し、敵機を破壊するには2発当てる必要があります。モードAとモードBの切り替えは "Q "キーで行う。
[O3-ミニハイ・コード・エフェクト・デモ]:
総合評価:[22/25]
# クイックツール3例(デイリーオフィス・中)
プロンプト英文テキスト処理ツールを実装するためのコードを記述し、ユーザーがテキストを入力すると、ツールは単語数の統計、単語の頻度の並べ替え、大文字と小文字の変換、スペースと改行の削除、行番号の追加、およびその他の操作を迅速に実行することができます。さらに、このツールは、複数のユーザー定義置換ルールを保存し、それらを統一的に実行することができます。ユーザーは、テキストをお気に入りに保存し、タイトルをカスタマイズすることができます。
総合評価:【20.5/25
例4 ウェブアプリケーション(ウェブビジョン、難しい)
プロンプト複数の画像(ユーザーがアップロードしたもの)が自動的に回転し、サムネイルがページ下部に表示されるファッションショーケースのウェブサイトを実装するコードを書いてください。画像はカードフリップの視覚効果を使って切り替わります。画像にカーソルを合わせると、虫眼鏡で詳細が表示されます。ページの右上には「ライトを消す」ボタンがあり、デフォルトでは背景が白で、「ライトを消す」をクリックすると背景が黒になり、ボタンは「ライトをつける」になります。ページの背景は花びらがゆっくりと落ちていくような効果があります。左上には写真の回転の開始と一時停止をコントロールするスタート/ポーズアイコンボタンがあり、回転する写真の右下には白いハートアイコンがあり、クリックするとピンクに変わり、右側にはハートをクリックした回数が表示されます。
総合評価:[23/25]
例5 ウェブアプリケーション(教育学習、難易度)
プロンプトユーザーが正しい選択肢を選ぶと次の単語にジャンプし、間違った選択肢を選ぶとジャンプする前に正しい選択肢を入力するよう促される。各グループには5つの単語、合計3つのグループがあり、各グループの終了後、ユーザーは学習を終了するか、別の単語セットを学習するかを選択できる。学習終了後、この学習全体の正解率が表示される。ユーザーは、インターフェースの上部にある「復習モードに切り替える」をクリックすることで、不正解だった問題に再度答えることができます。問題の順番はランダムです。つまり、サイトに入るたびに問題の順番は通常異なります。
[Qwen-Maxコード効果デモ]:
総合評価:[19/25]
評価分析と結論
1. o3-ミニハイ、クロード-3.7-ソネット-リーズニングがリード
今回の評価では、OpenAIがリリースしたo3-mini-highが82.08の総合スコアを獲得したのに対し、Anthropicが新たにリリースした推論モデルClaude-3.7-Sonnet-Reasoningは81.63の総合スコアを獲得し、両者が並んで首位に立った。
2.DeepSeek-R1は国内モデルをリードし、業界トップクラスに位置する。
評価結果から、DeepSeek-R1 は、o3-mini-high、Claude-3.5-Sonnet/3.7-Sonnet-Reasoning、Gemini-2.0-pro などの業界最先端モデルとのスコア差が非常に小さく、特に「ゲーム開発」と「ネットワークアプリケーショ ン」のアプリケーションシナリオで卓越した性能を発揮している。特に "ゲーム開発 "と "Webアプリケーション "のアプリケーション・シナリオにおいて、その性能は卓越しており、Claude-3.5-Sonnet、Gemini-2.0-proやその他のモデルを凌ぐか、あるいはそのレベルに達している。
3.それぞれに強みがあり、R1はゲーム開発、o3/Step Rはマルチメディア編集、そしていくつかはウェブアプリケーションに特化している。
評価に参加した12機種は、さまざまな応用シーンにおける能力の違いを示している。その中で、DeepSeek-R1は「ゲーム開発」の分野で傑出しており、Claude-3.5-Sonnet、Beanbag 1.5pro、Smart Spectrum GLM-Zero-preview、Tongyi Qianqian Maxは「ウェブアプリケーション」の設計に長けており、o3-mini-highとStep Star Step R-miniは「ウェブアプリケーション」の設計に長けている。Claude-3.5-Sonnet、Beanbag 1.5pro、GLM-Zero-preview、Maxは「ウェブアプリケーション」デザインにより特化しており、o3-mini-highとStep R-miniは「マルチメディア編集」ツールの開発において独自の優位性を持っている。
4.異なるモデルの間には、方法論の選択やインターフェースのスタイルに大きな違いがある。
モデルの回答を比較すると、同じユーザー要件に直面しても、モデルによって選択するプログラミング言語、ライブラリ/モジュールの呼び出し方、インターフェイスの美的センスなどが大きく異なっており、モデルの能力、好み、コンセプトの違いがある程度反映されていることがわかる。全体的に、海外モデルの方がユーザー・インターフェース・デザインにおいて優れたパフォーマンスを発揮している。
関連する例を以下に挙げる:
質問1:
シンプルなオンライン料理注文サイトを実装するためのコードを書く。「+」と「-」で料理の数を変更し、ショッピング・カートに料理を追加することをサポートし、ショッピング・カート内の料理の合計価格をリアルタイムで表示し、注文するためにクリックする機能をサポートする。注文後、ショッピングカートは空になり、客は料理を詰めるかどうか尋ねられる。合計金額100ドルごとに、10ドルの割引があるはずだ。
質問2:
バスケットボールのシュートゲームを実装するためのコードを記述し、マウスの動きは、バスケットボールの方向を制御するために、電力を蓄積するためにマウスを押して、バスケットボールにバスケットボールが得点に、連続バスケットは、バスケットに3回ではなく、追加のポイントを持っている、その後、ゲームの終了。バスケットボールを投げた後、その飛行経路を明確に示す必要があります。シュートする前に、左右の矢印キーでバスケットボールの初期位置を移動することができ、近距離のシュートは2点、一定距離以上のシュートは3点になります。リムに当たってボールにバウンドする可能性があります。
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事

コメントはありません