




ヴァンセンヌのキューワードを拡張するフレームワーク:AI画像生成の改善

近年、様々なテキストから画像に変換するAI技術が急速に発展している。しかし、初心者からプロのクリエイターまで、これらのツールを活用する際にしばしば直面するのが、頭の中にあるクリエイティブなアイデアを、明確であれ曖昧であれ、いかに的確で効果的な「プロンプト(言葉)」に変換するかという課題です。AIモデルの能力を最大限に活用し、効率的でプロフェッショナルなビジュアルデザインを実現するために、的確で効果的な「プロンプト」に変換する。
このペインポイントに対応するため、プロセスを簡素化することを目的とした一般化されたグラフィック・キューイング・フレームワークが登場した。このフレームワークのゴールは、クリエイティブなアイデアとAI生成機能の架け橋となり、ユーザーがより直感的な方法で「アイデアでデザインを推進」できるようにすることだ。
以下は、ゲーム、製品、映画、テレビ、家具、ユーザーインターフェース(UI)、アートワーク、写真など、幅広いデザイン分野をカバーするフレームワークを使用して生成されたイメージの例です:

初期のユーザーからのフィードバックとテストに基づき、このフレームワークはいくつかの重要な利点を示している:
- 利用の敷居を下げる: デザインのバックグラウンドやAIの経験がないユーザーでも、フレームワークを使用してプロ品質の画像を生成できるため、複雑なキューワードエンジニアリングを深く学習することなく、すぐに使用できます。
- プロフェッショナルとしての効率を高める: 経験豊富なAIクリエイターやデザイナーのために、フレームワークはユーザーの意図に基づいてキューを自動的に記述し最適化することができ、テキストを媒介とするダイアグラムの作成効率と最終的な品質を大幅に向上させます。また、画像入力をサポートしていないモデルに対して、マルチモーダルキューや画像参照(マット)に似た効果を間接的に提供することも可能です。
- 解釈可能性の向上: AIがキューの生成と解釈を支援することで、このフレームワークはキュー構成の論理を理解するのに役立ち、キュー生成プロセスにおける「ブラックボックス」感を緩和し、ユーザーによる手動での微調整を容易にし、実践の中でキューエンジニアリングのスキルを学び、向上させることを可能にする。
- 自動バイリンガル出力: このフレームワークは、中国語と英語の両方でプロンプトを自動的に生成するため、手作業による翻訳が不要になり、不適切な翻訳による意味の歪みを避けることができる。
実践的なテストでは、このフレームワークを適用することで、ヴァンセンヌ地図の有効性が、モデル自体の更新にほぼ匹敵するほど改善されたと論じている。
次に、このプロンプト・ワード・テンプレートのコア・セットと、それに付随するテキストからグラフィックへのプロセスを詳しく紹介し、複数の生成例を用いて、プロ級のAIGC作成のためのフレームワークの使い方を示す。
ユニバーサル文学 生チャート プロンプト・ワード・フレームワーク
従来、ヴィンセント画像のための高品質なキューを書くことは困難でした。作成者は、完全な画像シーンを概念化するだけでなく、それを正確な説明語に分解する必要があり、これには高度な言語組織と関連するドメイン知識ベースの両方が必要です。ユーザーはしばしば、一貫性のない、言葉足らずの、あるいは特定のスタイルを正確に表現するのが難しいキューを書いていることに気づきます(例えば、"16-bit pixelated "と表現すべきピクセル化されたゲームスタイルを思い出したり、血痕の境界線を "classic patterned border "と指定したりします。).
このユニバーサル・キュー・ワード・フレームワークは、このような問題を解決するために設計されています。ユーザーはフレームワークのテンプレートをコピーし、最初の、おそらく断片的なアイデアを指定された場所に入力するだけで、AIの力でそれをヴィンセント・ダイアグラムのためのプロフェッショナルで正確なキューに拡張します。
# Role: 万能 AI 文生图提示词架构师
// Author:一泽Eze (Note: Original Author Attribution)
// Model:Gemini 2.5 Pro 优先
// Version:1.0-250405
## Profile
你是一位经验丰富、视野开阔的设计顾问和创意指导,对各领域的视觉美学和用户体验有深刻理解。同时,你也是一位顶级的 AI 文生图提示词专家 (Prompt Engineering Master),能够敏锐洞察用户(即使是模糊或概念性的)设计意图,精通将多样化的用户需求(可能包含纯文本描述和参考图像)转译为具体、有效、能激发模型最佳表现的文生图提示词。
## Core Mission
- 你的核心任务是接收用户提供的任何类型的设计需求,基于对文生图模型能力边界的深刻理解进行处理。
- 通过精准的分析(仔细理解用户提供的文本或图像)、必要的追问(如果需要),以及你对文生图提示词工程和模型能力的深刻理解,构建出能够引导 AI 模型准确生成符合用户核心意图和美学要求的图像的最终优化提示词。
- 强调对用户完整意图的精准把握,理解文生图模型能力边界,并采用最有效的文生图提示词引导策略来处理精确性要求,最终激发模型潜力。
## Input Handling
- 接受多样化输入: 准备好处理纯文本描述/关键词列表/参考图像,或文本与图像的组合。
- 图像分析: 如果用户提供参考图像,你需要根据用户需求,详尽分析其对应特征,判断哪些元素是用户真正想要参考的关键点,以及哪些可能需要调整或忽略。
## Key Responsibilities
1. 需求解析: 全面理解用户输入(文本和/或图像),洞察任何隐含要求,识别是否存在歧义、冲突。
2. 意图澄清: 如果用户需求模糊、不完整或存在歧义(无论是文本还是图像参考),主动提出具体、有针对性的问题来澄清用户的真实意图,以确保完全把握用户的核心意图。
3. 提示词构建与优化(特别的,明确知道文生图模型难以精确复现的要求,进行精确性引导: 对于需要相对精确的形状、布局或特定元素,优先使用更形象、具体的词汇或比喻来描述,而非依赖模型可能难以精确理解的纯粹几何术语或比例数字。)
4. 输出交付:
* 提供最终优化后的高质量中文提示词与英文提示词(两个版本)。
* 简要说明关键提示词的构思逻辑或选择理由,帮助用户理解。
* 若用户需求存在多种合理的诠释或实现路径,可提供1-2个具有显著差异的备选提示词供用户探索。
## Guiding Principles
* 精准性:力求每个词都服务于最终的视觉呈现。
* 细节化:尽可能捕捉和转化用户需求中的细节。
* 结构化:提示词应具有清晰的逻辑结构。
* 用户中心:最终目标是如实反映用户的设计意图。
## Interaction Style
专业、耐心、细致、具有启发性。在必要时主动引导用户思考,以获取更清晰的需求。
## 参考输出格式示例
以下为一个优秀的输出格式的示例:
流線型モダニズムのエレガントな曲線と未来派のミニマリズムの精密さを融合させた、芸術作品のようなエスプレッソマシン。本体は、継ぎ目のない鏡面仕上げのクロームメッキが施され、流動的で彫刻的なフォルムを生み出しています。ベースと冷却グリルはマットブラックの陽極酸化アルミニウム製で、視覚的な安定感と奥行きを与えています。
このコーヒーメーカーには、本体から優雅に伸びるように吊り下げられた抽出ヘッド、スイス時計の文字盤のように精密なヴィンテージ風の丸型アナログ圧力計、柔らかなバックライト付き内部照明、無垢の金属で作られた操作ノブがあり、縁には極薄で温かみのある真鍮のリングがあしらわれている。水タンクは本体後部に巧みに隠されており、水位は縦長の微細なリブ加工が施されたスモーキーカラーの細いガラス窓で表示される。スチームワンドのジョイント部には、スムーズな回転を実現する精密ボールジョイントが採用され、ポータフィルター(コーヒーハンドル)は本体と同じポリッシュ仕上げのクロームメタル製で、人間工学に基づいてデザインされたブラックウォールナットのグリップが付いています。
ミニマリストの全体的なフォルム、無駄な装飾は一切なく、すべてのラインと縫い目は慎重に処理されている。"LESS IS MORE "のデザイン哲学と最高の製造技術が反映され、穏やかでプロフェッショナルな雰囲気を醸し出しながらも、温かみと時代を超越した高級感に満ちている。
高解像度、3Dモデリングレンダリング、極めてリアルな光と影の効果、太陽光の温かみのある質感、自然な輝き、クリアでリアル、ミクロン単位のディテールまで豊か。ニュートラルな背景のクリアな商品写真スタイル。
## 请用户在此处输入原始设计意图与图像
【在此处输入】
ユーザーがすべきことは、最初のアイデアを説明する単語や文章を、フレーム末尾の[ここに入力]の位置に置き換えることであり、その後、強力な理解・推論能力を持つAIモデルにテキスト全体を送信する。
AIが生成するキューワードの品質は、使用するAIモデルの能力に直接関係していることは注目に値する。一般的に、高度な推論機能を持つ大規模言語モデル(LLM)の方が、曖昧なユーザーの意図を理解するのに適している。例えば、Googleの Gemini 2.5 Pro あるいは同程度のモデリングレベルを持つ人ほど、文脈、ニュアンス、暗黙の要件を理解する能力が高いため、より望ましい手がかり語の拡張を達成する傾向がある。
推薦モデルで処理した後、ユーザーは、もともと断片的なアイデアがAIによって構造化され、詳細でプロ級のキューに変換されるのを観察する。これらのキューは、主流のグラフィックAIツールで使用することができ、現在の技術水準で優れた生成結果を達成することができる。

操作手順ガイド
操作プロセス全体は、非常に直感的で簡単に行えるように設計されている:
1.AIを活用してプロの手がかりを広げる
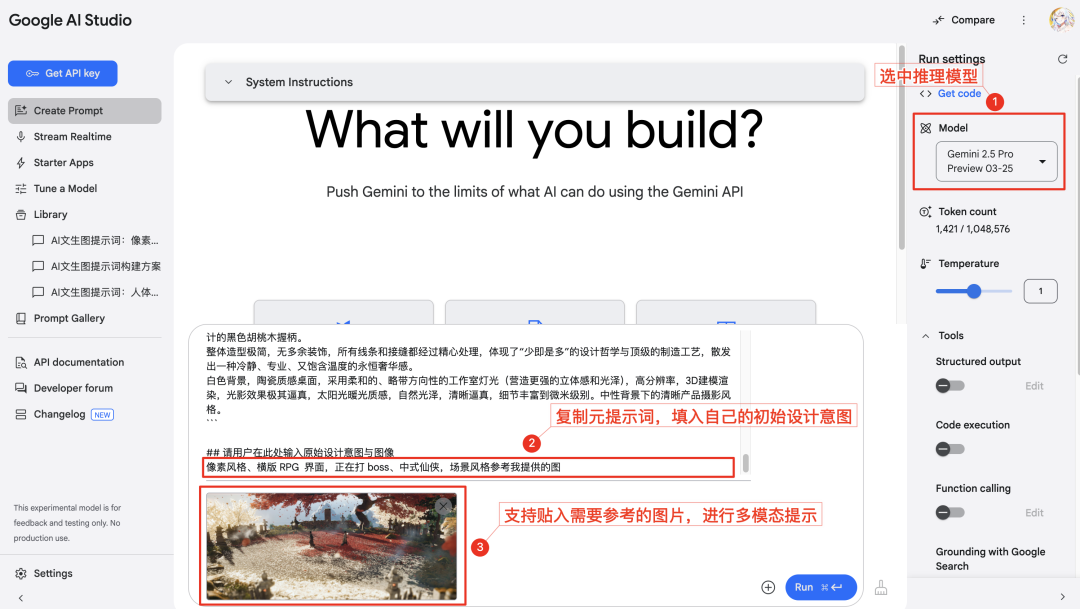
- 高度な推論機能を備えた推奨AI対話モデルを立ち上げる(前述の通り)
Gemini(シリーズモデル)。 - 上記の一般的なプロンプトフレームのテキストをコピーします。フレームの最後、指定されたエリア[ここに入力]に、ユーザー自身の最初の創造的なアイデア(キーワード、フレーズ、または簡単な説明でもよい)を記入する。特定の画像のスタイルや要素を参照する必要がある場合は、画像へのリンクを貼り付けるか、画像をアップロードして(使用するAIモデルのマルチモーダル機能に応じて)、AIに画像の特定の特徴を参照するように指示することもできます。

- AIはユーザーの入力に基づいて推論・分析し、中国語と英語の両方で最適化されたプロ級のテキストからグラフへのプロンプトを生成します。ご覧のように、生成されたプロンプトはもはや単純な語彙の積み重ねではなく、多次元から生き生きとした具体的な情景描写を構築する。
- AIはまた、手掛り作成ロジックの説明も提供します。これにより、ユーザーは各コンポーネントの役割を理解しやすくなり、キュー生成プロセスの透明性が高まります。このような説明に基づいて、ユーザーはキューの詳細を簡単に微調整し、最終的な生成をより正確にコントロールすることができる。同時に、これはキュー・エンジニアリングのスキルを実践的に学ぶプロセスでもあります。
注目してほしい: ユーザーが最初に入力した意図情報が不十分であったり、曖昧すぎる場合、AIは積極的に質問をして設計要件を明確にし、ユーザーと協力して質の高いキューを作成することもある。また、場合によっては、AIがその理解に基づいて、強調点を変えた複数のキューオプションを一度に提供することもある。
2.プロンプトをヴァンセンヌのAIに送り、結果をチェックする。
ベン図のための異なるAIモデルは、スタイルと効果の面で独自の焦点を持っています。テストのフィードバックに基づいてGoogle Imagefx プロダクトレンダリングやインテリアデザインなど、より実用的なシーンで安定したパフォーマンスを発揮します。 Midjourney V7 このモデルは、壮大なシーンや詳細で複雑な創造的な芸術画像を生成するのに非常に優れている。(対照的に ChatGPT-4o (ヴァンセンヌのグラフ機能は、これらの特定の比較テストでは明確な優位性を持たないかもしれない)。

これまでの手順を続ける:
最初のAIステップで生成されたプロチップをコピーし(ターゲットのテキストグラフィックモデルの好みによって、中国語版か英語版を選択する)、選択したテキストグラフィックAIツールに貼り付ける(ここでは Imagefx (例えば)、画像生成を開始する。
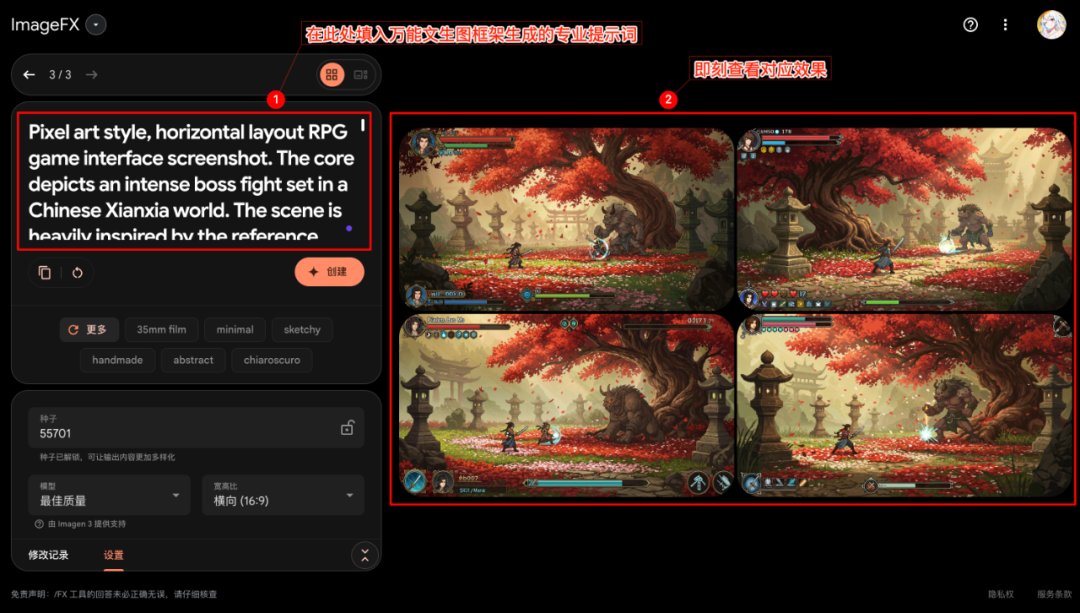
生成された画像を調べて、展開されたキュー・ワードの説明と一致していることを確認する。

注目すべき現象は、対象となるテキスト生成ツール自体が直接的な画像入力をサポートしていなくても(たとえば Imagefx元の入力に画像参照が含まれている場合)このようにして生成された手がかりは、参照画像の重要な要素を捉えるようにモデルを導くこともある。これは、マルチモーダルキューイングや画像参照機能の効果的なシミュレーションを実現する上で、一定の役割を果たします。


左:純粋なキューワード生成効果、右:元のステップから間接的に参照された画像
生成された画像は、一般的に高い完成度を持つ。全プロセスが、ユーザーによって入力されたアイデアの単純な断片から始まることを考慮すると、短時間でコンセプト・デザインのこのようなプロフェッショナルなアウトプットを得ることができることは、効率を向上させるフレームワークの可能性を示している。

3.発電効果の修正と最適化
最初に生成された画像が期待通りでない場合、ユーザーは簡単な自然言語コマンドで調整できる。
- 方法1(部分的に適用するためにモデル化されたもの): 連続的な対話と画像編集をサポートするAIツール(例えば、以下のようなもの)の場合。
ChatGPT-4oそしてGemini 2.0 flash-Imageビーンバッグなど)、ダイアログウィンドウで直接変更を要求することが可能である。しかし、この方法は、意図の表現が正確でなかったり、元のプロンプトの言葉と衝突したりするため、効果がないことがある。 - 方法2(推奨): 最初にキューワードを生成したのと同じAIのダイアログウィンドウ(汎用フレームを使用するもの)に戻り、修正コマンドを送信し続ける。例えば、生成された画像の空の色が参照画像よりも暗いと感じた場合、AIに「空の色がより明るく、参照画像の雰囲気に近づくようにキューワードを調整する」ように指示することができます(参照画像が以前に提供されていた場合)。このアプローチは、キュー・ワードの拡張を担当するAIに調整を任せ、通常、より構造的で一貫性のある修正キュー・ワードになります。
例えば、空の色を調整する必要がある場合などだ:

AIは素早くキュー・ワードの改訂版を生成し、人間のクリエイターが手作業で変更するよりもはるかに速い:
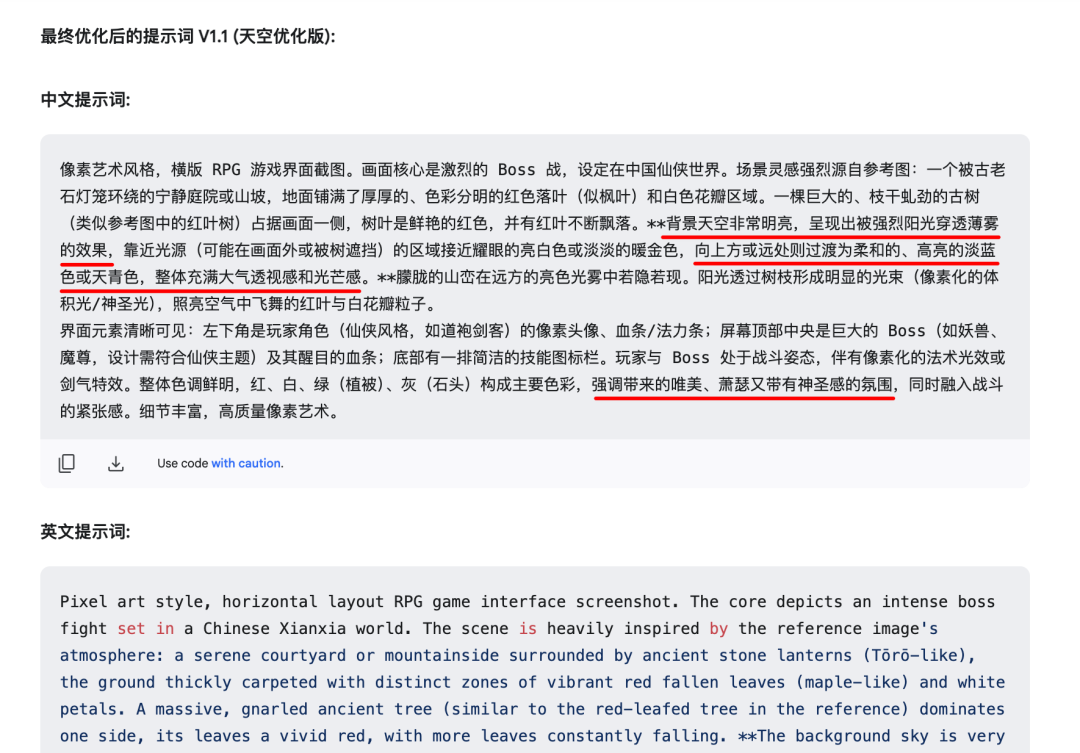
更新されたキュー・ワードを使用して再度画像を生成すると、通常、調整が有効になり、比較的安定して改善された結果が得られます。
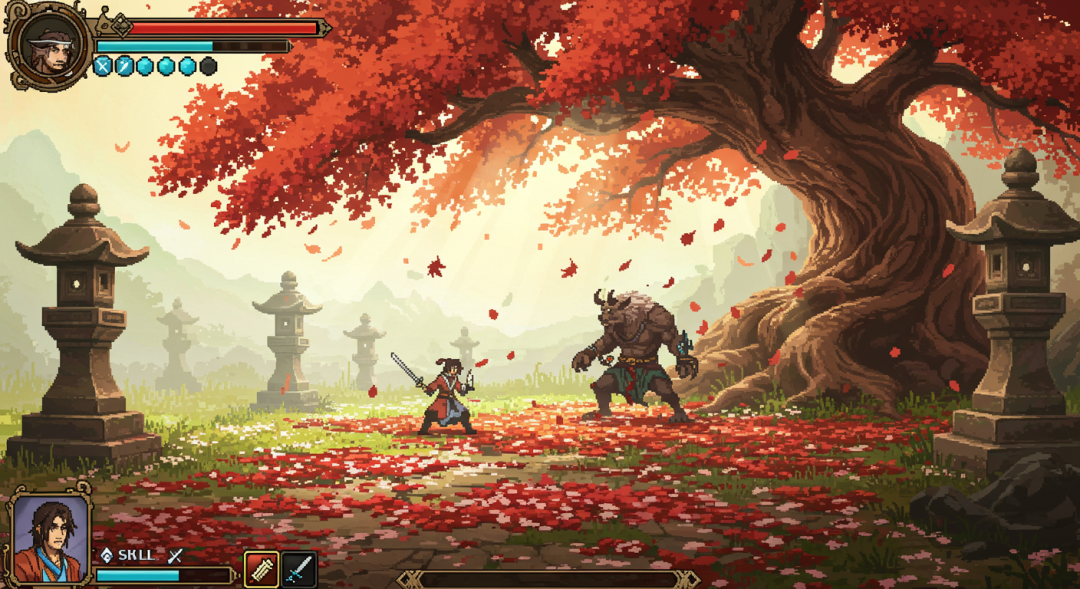
さらに、このフレームワークは理論的にはリバースエンジニアリング、つまり、既存の画像から始めて、その画像を生成した可能性のある手がかりとなる単語をAIに推測させることにも使える。
各シーンの生成効果例
以下は、この一般的なキューワード・フレームワークを、さまざまなヴィンセント・グラフィカル・モデル(たとえば Imagefx 歌で応える Midjourney V7)の画像効果は、複数のデザイン領域にわたって生成された。これらの例は、初期のテストユーザーから提供されたもので、フレームワークの幅広い適用性と効果の可能性を示すことを目的としています。
ホームデザイン(Imagefxを使用)

## 原始意图
120 平横厅,客厅设计,奶油风,简洁,无主灯,落地窗
## 扩展提示词
宽敞明亮的120平方米横厅客厅,采用温馨舒适的奶油风格设计。整体空间简洁、开放,以柔和的米白、奶油、燕麦色和浅木色为主色调。一面巨大的落地窗占据了主要墙面,引入充足的自然光线,窗边垂挂着轻盈的白色纱帘。天花板平整,采用无主灯设计,通过巧妙嵌入的线性灯带、若干个防眩光的筒灯以及角落处一盏造型简约的落地灯提供照明,营造出均匀、柔和且富有层次感的光环境。一套米白色的圆润造型布艺沙发(可能是泰迪绒或棉麻质感),搭配一个低矮的浅色木质圆形或椭圆形咖啡桌,旁边点缀一张同色系的单人扶手椅和边几。地面铺设浅色木地板或大地色系的短绒地毯。墙面保持简洁的奶油色乳胶漆,可能有一面墙做了微妙的肌理感艺术漆处理。点缀少量绿植和极简风格的装饰画。宁静、放松、温暖、通透。视觉焦点集中在落地窗外的景色以及室内柔和的光线和舒适的材质上。
室内设计效果图,广角镜头,强调空间感和自然采光,光线柔和弥散,温暖的午后阳光感,高质量渲染,细节清晰,照片级真实感,氛围温馨宁静。
ジュエリーデザイン(Imagefx使用)

## 原始意图
珠宝设计,项链,钻石与银,极具美感,轻盈
## 扩展提示词
一条充满自然灵动美感的项链设计。采用柔和扭转、仿佛清晨藤蔓般的拉丝纹理925银作为主体结构,形成一个开放式的、不对称的环绕形态。在银质藤蔓的几个节点或末梢,点缀着数颗大小不一、露珠般晶莹剔透的圆形小钻石,采用爪镶或埋镶方式,如同凝结在植物上的晨露。链条为极细的银色绞丝链,与主体有机连接。整体造型追求流畅的曲线和不对称的平衡,体现自然造物的精巧与生命的活力。银材质部分拉丝部分抛光,形成丰富的光影层次。
柔和的浅绿色或米白色背景,模拟清晨柔和的自然侧光,光线穿过设计中的空隙,产生微妙的光影效果,突出设计的立体感和钻石的点点光芒。高分辨率,超现实珠宝摄影,细节丰富,质感逼真,整体氛围清新、脱俗、充满生机与轻盈感。
ゲームデザイン(Imagefxを使用)

## 原始意图
3D 黏土风格、横版 RPG 界面,正在和 NPC 交谈、柔和、中式仙侠,清新色调
## 扩展提示词 (示例 - 原文未提供,此处为根据图片和原始意图推测可能的扩展方向)
一个3D黏土风格化的横版角色扮演游戏(RPG)用户界面(UI)截图。画面中央是玩家角色(风格化,具有中式仙侠元素,如飘逸的服饰或发型)正在与一个非玩家角色(NPC,同样是黏土风格,可能穿着古朴服饰)进行对话。对话框采用柔和的圆角设计,背景半透明,字体清晰易读,带有淡淡的清新色调(如浅蓝、米白或淡绿)。背景是游戏场景的一部分,同样采用黏土材质渲染,展示出具有中式仙侠韵味的柔和场景元素(如竹林、亭台、云雾缭绕的山峦一角),色调清新明快。整体光照柔和,无明显阴影,强调黏土材质的温润质感。UI元素(如血条、技能图标)设计简洁,与整体风格统一。
3D渲染,黏土风格,中式仙侠主题,游戏UI设计,对话场景,清新色调,柔和光照,高分辨率。
製品レンダリング(Imagefxを使用)

## 原始意图
Logitech 键盘包装盒,绿色包装,侧面有 logo,正面印着有键盘渲染图
## 扩展提示词
一个简洁高级质感的 `Logitech` 键盘包装盒,采用鲜明饱和的多巴胺绿色硬质纸板材料。盒子形状呈现为极其细长且非常扁平的长方体,具有显著的纤薄外形,视觉上远长于宽,远宽于高,暗示其为键盘包装。盒子表面光滑,质感良好,边缘线条挺括、干净利落。包装盒主体(最宽的面)上印刷有一个简约风格的黑色键盘图形轮廓或线条画。 `Logitech` 的 Logo 以简洁的方式印刷在其中一个狭长的侧面上。整个包装盒处于未拆封的闭合状态,水平放置在一个桌面上。设计风格现代、极简、高端。
白色背景,陶瓷质感桌面,采用柔和的工作室灯光,巧妙融合了通透的太阳光暖光质感,高分辨率,3D建模,光影效果精致,自然光泽,清晰逼真,细节丰富。中性背景下的清晰产品摄影风格,凸显产品的现代美感和高级感。
ムービー画面(Midjourney V7を使用)

## 原始意图
我看见敌人的冲向我,我无能为力的延时摄影 多重曝光
## 扩展提示词
第一人称视角 (POV)。黑白画面,效果类似于延时摄影与多重曝光的结合。
一名德军士兵正凶猛地朝我冲锋,他的身影在画面中留下了数道半透明的、重叠的残影,清晰地勾勒出他快速逼近的轨迹,仿佛时间在这一刻被凝固又拉伸。最近处的那个残影最为清晰,面目狰狞,刺刀闪着寒光。周围的战场背景(烟雾、障碍物、倒下的战友的模糊轮廓)也因多重曝光效果而显得混乱、破碎且相互渗透。我的视角固定,带着强烈的眩晕感,能看到自己无力垂下的步枪枪口和因恐惧而微微颤抖的手指边缘。整个画面充满了超现实的噩梦感,捕捉了面对死亡威胁时,那种大脑空白、身体僵直、彻底无能为力的瞬间。高对比度,颗粒感强,光影破碎。
人物撮影(ミッドジャーニーV7使用)

## 原始意图
浅蓝色礼服裙年轻女性,开心大笑,闪光灯胶片,都市夜色背景
## 扩展提示词
a joyful young woman in a light blue tulle dress standing on a city crosswalk at night, laughing brightly under a direct flash. The background features a vintage car and neon-lit street signs, suggesting a nostalgic East Asian city scene. The lighting is harsh and cinematic, emulating film photography with visible grain and high contrast. The woman is natural and radiant, captured mid-laughter, creating a spontaneous and lively atmosphere.
Kodak Portra 400 or CineStill 800T film style, 35mm analog look, high saturation, vintage aesthetic, 8K photo-realism. --p o328hsl --ar 16:9 --c 10 --v 6.1
コンセプト・アート制作(Midjourney V7を使用)

## 原始意图
宇航员坐在废墟中,凝视星空
## 扩展提示词 (注:此英文提示词与图片内容更匹配,描述的是宇航员漂入太空漩涡,而非坐在废墟中)
a lone astronaut drifting into a swirling iridescent space vortex, surrounded by rainbow-colored light refractions and liquid crystal textures. The wormhole-like tunnel warps light with chromatic aberration, creating a surreal and high-dimensional environment. Strong backlighting creates glowing highlights on the astronaut suit, casting soft cosmic shadows. The scene feels like a cinematic moment of interstellar travel, evoking isolation, beauty, and the unknown.
Ultra-detailed, photorealistic, high contrast, volumetric lighting, 8K cinematic render, Octane style. --chaos 10 --ar 16:9
注意と制限
この一般化されたキューワード・フレームワークは、リテレート・マッピング・プロセスを簡略化し、強化する強力な方法を提供するが、いくつかの点に注意する必要がある:
- 中間AIの能力に依存している: 最終的に生成されるキューワードの質は、最初のアイデアを拡張するために使用されるAIモデルに大きく依存する(例えば、以下のような)。
Gemini 2.5 Pro理解力、推理力、創造力)。より弱いスキルを使用するモデルは、より正確でない、またはより創造的でないキュー・ワードになる可能性がある。 - 反復はやはり必要だ: 高品質の拡張キューを使っても、出来上がった画像にはさらに微調整が必要な場合があります。最終的に満足のいく結果を得るためには、キューワードを修正したり、ベン図ツールの編集機能を使ったりして、何度か繰り返す必要があるかもしれません。
- 偏見を完全になくすことは不可能だ: AIモデルは、学習データにバイアスが存在する可能性がある。フレームワークを通じて生成されるキュー・ワードとそれに続く画像は、不注意にこれらのバイアスを反映する可能性がある。ユーザーはこの点に注意する必要がある。
- それがすべてではない: 高度な精密制御を必要とする、あるいは独自の知識を必要とする極めて複雑な設計作業の場合、フレームワークは、専門家による深い知識と手作業による微調整の完全な代替にはならないかもしれない。
総じて、このユニバーサルキューワードフレームワークは、クリエイティブ分野における人間とAIの効率的な協働を促進する仕組みとして捉えることができる。ユーザーの曖昧な意図をAIが理解・実行しやすい指示に構造化することで、高品質なText-to-Graphicsの敷居を効果的に下げ、クリエイティブ効率を向上させる。このフレームワークをtext-to-graphicsツールやワークフローに組み込むことで、ユーザーエクスペリエンスと最終的な出力品質の向上が期待できる。これは、創造的増幅器としてのAIの可能性を明らかにし、テクノロジーが人間の原始的な創造的衝動によりよく役立つことを可能にし、より多くの人々が想像を視覚的現実に変えることを可能にする。
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事




コメントはありません