マイクロソフトAIエージェント入門:AIエージェントフレームワークの探求

AIエージェントフレームワークは、AIエージェントの作成、展開、管理を簡素化するために設計されたソフトウェアプラットフォームです。これらのフレームワークは、複雑なAIシステムの開発を簡素化するために、あらかじめ構築されたコンポーネント、抽象化、およびツールを開発者に提供します。
これらのフレームワークは、AIエージェント開発における共通の課題に対する標準化されたアプローチを提供することで、開発者がアプリケーションのユニークな側面に集中できるよう支援します。これらのフレームワークは、AIシステム構築のスケーラビリティ、アクセシビリティ、効率性を向上させます。
簡単
このコースで扱うのは
- AIエージェント・フレームワークとは何か?
- Agentの機能を迅速にプロトタイプ化し、反復し、改善するために、チームはこれらのフレームワークをどのように利用できるでしょうか?
- Microsoft AutoGen、Semantic Kernel、Azure AI Agentが作成したフレームワークとツールの違いは何ですか?
- 既存のAzureエコシステムのツールと直接統合することは可能ですか、それともスタンドアロンのソリューションが必要ですか?
- Azure AI Agentsサービスとは何か?
学習目標
このコースの目標は、理解を深めることである:
- AI開発におけるAIエージェントフレームワークの役割。
- AIエージェントフレームワークでインテリジェントエージェントを構築する方法。
- AIエージェントフレームワークが実装する主な機能。
- AutoGen、Semantic Kernel、Azure AI Agent Serviceの違い。
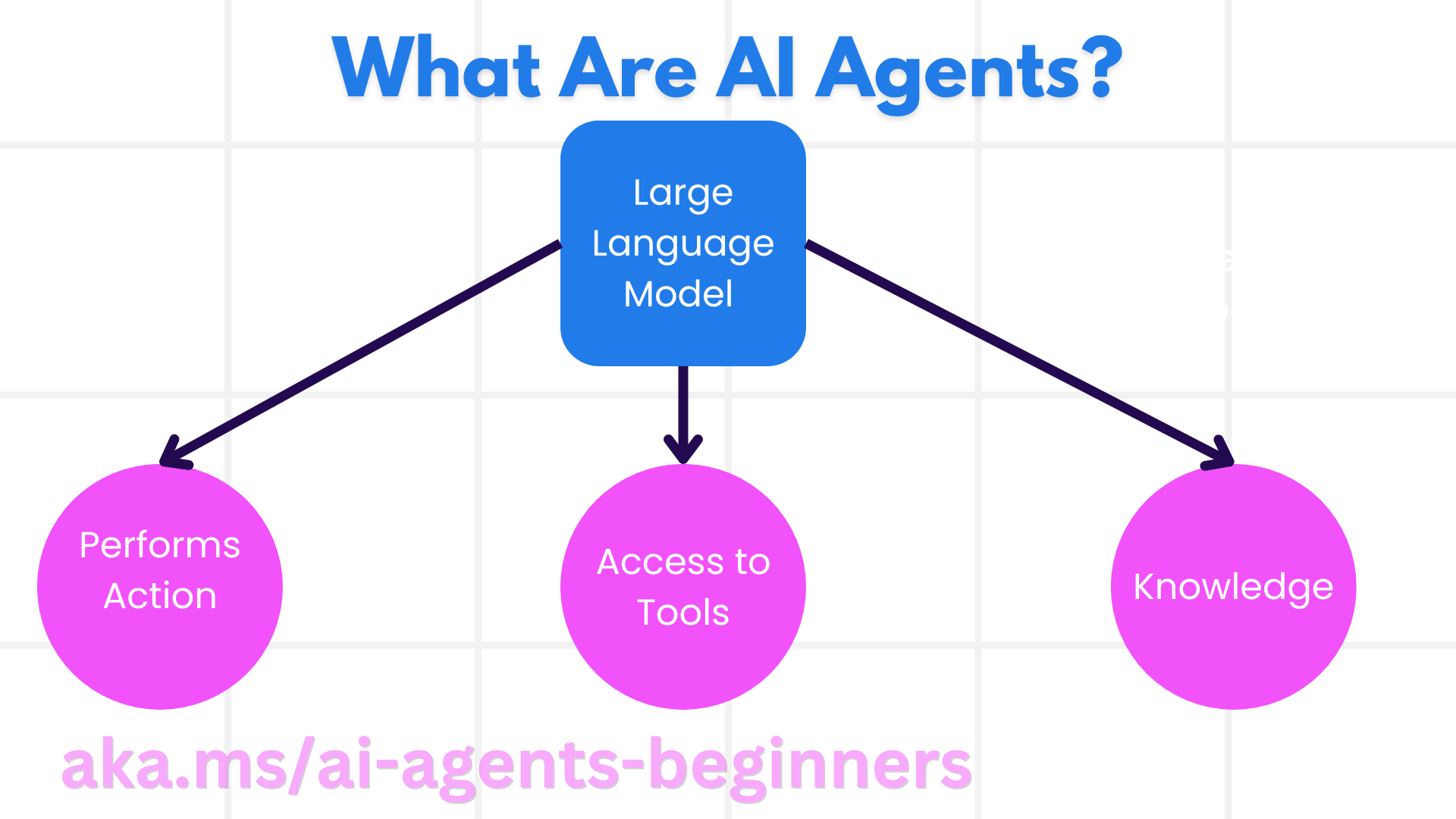
AIエージェント・フレームワークとは何か?
従来のAIフレームワークは、AIをアプリケーションに統合し、アプリケーションをより良いものにするのに役立つ:
- パーソナルAIはユーザーの行動や嗜好を分析し、パーソナライズされたレコメンデーションやコンテンツ、体験を提供することができる。例えば、Netflixのようなストリーミング・サービスでは、AIを使って視聴履歴に基づいて映画や番組を推薦し、ユーザーのエンゲージメントと満足度を高めている。
- 自動化と効率化AIは反復作業を自動化し、ワークフローを合理化し、業務効率を向上させることができる。例えば、カスタマーサービス・アプリケーションでは、AIを活用したチャットボットが一般的な問い合わせに対応することで、応答時間を短縮し、人間のエージェントがより複雑な問題に対処できるようにしている。
- ユーザー・エクスペリエンスの向上AIは、音声認識、自然言語処理、予測テキストなどのインテリジェントな機能を提供することで、全体的なユーザー体験を向上させることができる。例えば、SiriやGoogleアシスタントのようなバーチャルアシスタントは、AIを使用して音声コマンドを理解し、それに応答することで、ユーザーがデバイスと対話することを容易にします。
これは素晴らしいことだと思うだろう?では、なぜAIエージェントのフレームワークが必要なのでしょうか?
AIエージェントフレームワークは、単なるAIフレームワークではない。それらは、特定の目標を達成するためにユーザー、他のエージェント、環境と相互作用することができ、自律的な行動を示し、意思決定を行い、変化する状況に適応することができるインテリジェントエージェントを作成するために設計されています。AIエージェントフレームワークによって実装される主な機能のいくつかを見てみよう:
- エージェント コラボレーションとコーディネーション複雑なタスクを解決するために協力し、コミュニケーションし、協調することができる複数のAIエージェントの作成をサポートします。
- タスクの自動化と管理マルチステップワークフローの自動化、タスクの委譲、エージェント間のダイナミックなタスク管理のメカニズムを提供します。
- 文脈の理解と適応エージェントは、コンテキストを理解し、変化する環境に適応し、リアルタイムの情報に基づいて意思決定を行うことができます。
要するに、エージェントによって、より多くのことができるようになり、自動化を次のレベルに引き上げ、環境に適応して学習できる、よりスマートなシステムを作ることができる。
Agentの機能を迅速に試作、反復、改善するにはどうすればよいですか?
この分野は急速に進化しているが、ほとんどのAIエージェントフレームワークには、プロトタイプの作成と迅速な反復を支援するいくつかの共通点がある。これらについて掘り下げてみよう:
- モジュラー・コンポーネントの使用AIフレームワークは、ヒント、パーサー、メモリ管理などのあらかじめ組み込まれたコンポーネントを提供する。
- コラボレーション・ツールの使用特定の役割とタスクを持つデザイン・エージェントは、共同ワークフローをテストし、改善することができます。
- リアルタイム学習エージェントがインタラクションから学習し、その行動を動的に適応させるフィードバックループが達成されます。
モジュラー・コンポーネントの使用
LangChainやMicrosoft Semantic Kernelのようなフレームワークは、ヒント、パーサー、メモリ管理のようなビルド済みのコンポーネントを提供する。
チームはこれらをどのように活用しているのだろうか。チームは、これらのコンポーネントを素早く組み立てることで、ゼロから始めることなく機能的なプロトタイプを作成し、迅速な実験と反復を行うことができます。
実際の仕組みユーザー入力から情報を抽出するパーサー、データを保存・取得するインメモリーモジュール、ユーザーと対話するプロンプトジェネレーターなど、これらのコンポーネントをゼロから構築することなく、あらかじめ構築されたものを使用することができます。
サンプルコード.パーサーを使ってユーザー入力から情報を抽出する例を見てみよう:
// Semantic Kernel 示例
ChatHistory chatHistory = [];
chatHistory.AddUserMessage("I'd like to go To New York");
// 定义一个包含预订旅行功能的插件
public class BookTravelPlugin(
IPizzaService pizzaService,
IUserContext userContext,
IPaymentService paymentService)
{
[KernelFunction("book_flight")]
[Description("Book travel given location and date")]
public async Task<Booking> BookFlight(
DateTime date,
string location,
)
{
// 根据日期、地点预订旅行
}
}
IKernelBuilder kernelBuilder = new KernelBuilder();
kernelBuilder..AddAzureOpenAIChatCompletion(
deploymentName: "NAME_OF_YOUR_DEPLOYMENT",
apiKey: "YOUR_API_KEY",
endpoint: "YOUR_AZURE_ENDPOINT"
);
kernelBuilder.Plugins.AddFromType<BookTravelPlugin>("BookTravel");
Kernel kernel = kernelBuilder.Build();
/*
在后台,它识别要调用的工具、它已经具有的参数 (location) 和它需要的参数 (date)
{
"tool_calls": [
{
"id": "call_abc123",
"type": "function",
"function": {
"name": "BookTravelPlugin-book_flight",
"arguments": "{\n\"location\": \"New York\",\n\"date\": \"\"\n}"
}
}
]
*/
ChatResponse response = await chatCompletion.GetChatMessageContentAsync(
chatHistory,
executionSettings: openAIPromptExecutionSettings,
kernel: kernel)
Console.WriteLine(response);
chatHistory.AddAssistantMessage(response);
// AI 响应:"Before I can book your flight, I need to know your departure date. When are you planning to travel?"
// 也就是说,在前面的代码中,它找出了要调用的工具,它已经拥有的参数 (location) 以及它从用户输入中需要的参数 (date),此时它最终会向用户询问缺失的信息
この例から、事前構築されたパーサーを使用して、フライト予約リクエストの出発地、目的地、日付などのユーザー入力から重要な情報を抽出できることがわかります。このモジュラーアプローチにより、高レベルのロジックに集中することができます。
コラボレーション・ツールの使用
クルーAI およびマイクロソフト オートジェン このようなフレームワークは、連携可能な複数のエージェントの作成を容易にする。
チームはこれらをどのように活用しているのだろうか。チームは、特定の役割とタスクを持つエージェントを設計し、共同ワークフローのテストと改善を行い、システム全体の効率を高めることができます。
実際の仕組み各エージェントは、データ検索、分析、意思決定などの専門的な機能を持っています。これらのエージェントは、ユーザーからの問い合わせに答えたり、タスクを完了させるなど、共通の目標を達成するためにコミュニケーションをとり、情報を共有することができます。
サンプルコード(AutoGen)::
# 创建 Agent,然后创建一个循环调度,让他们可以协同工作,在本例中是按顺序
# 数据检索 Agent
# 数据分析 Agent
# 决策 Agent
agent_retrieve = AssistantAgent(
name="dataretrieval",
model_client=model_client,
tools=[retrieve_tool],
system_message="Use tools to solve tasks."
)
agent_analyze = AssistantAgent(
name="dataanalysis",
model_client=model_client,
tools=[analyze_tool],
system_message="Use tools to solve tasks."
)
# 当用户说 "APPROVE" 时,对话结束
termination = TextMentionTermination("APPROVE")
user_proxy = UserProxyAgent("user_proxy", input_func=input)
team = RoundRobinGroupChat([agent_retrieve, agent_analyze, user_proxy], termination_condition=termination)
stream = team.run_stream(task="Analyze data", max_turns=10)
# 在脚本中运行时使用 asyncio.run(...)。
await Console(stream)
前のコードで見たのは、複数の Agent が協力してデータを分析するタスクを作成する方法です。各Agentは特定の機能を実行し、タスクを実行するAgentを調整し、望ましい結果を達成します。特別な役割を持つ専用のAgentを作成することで、タスクの効率とパフォーマンスを向上させることができます。
リアルタイム学習
アドバンスド・フレームワークは、リアルタイムの文脈理解と適応を提供する。
チームはこれらのフレームワークをどのように使うかチームは、エージェントが相互作用から学び、その行動を動的に調整することを可能にするフィードバックループを実装することができます。
実用エージェントは、ユーザーのフィードバック、環境データ、タスクの結果を分析し、知識ベースを更新し、意思決定アルゴリズムを適応させ、時間の経過とともにパフォーマンスを向上させることができます。この反復学習プロセスにより、エージェントは変化する状況やユーザーの好みに適応し、システム全体の効率を向上させることができます。
AutoGen、Semantic Kernel、Azure AI Agent Serviceフレームワークの違いは何ですか?
これらのフレームワークを比較する方法はたくさんあるが、デザイン、機能、ターゲットとするユースケースの観点から、いくつかの重要な違いを見てみよう:
オートジェン
Microsoft ResearchのAI Frontiers Labが開発したオープンソースのフレームワーク。イベントドリブン、分散型にフォーカス。 エージェント的 複数の大規模言語モデル(LLM)やSLM、ツール、高度なマルチエージェント設計パターンをサポートするアプリケーション。
AutoGenのコアコンセプトはエージェントであり、環境を感知し、意思決定を行い、特定の目標を達成するために行動を起こすことができる自律的なエンティティである。エージェントは非同期メッセージングを通じて通信し、独立して並行して作業できるため、システムのスケーラビリティと応答性が向上します。
エージェントはアクターモデルに基づく.ウィキペディアによると、俳優とは 並行計算の基本的な構成要素。受信メッセージに応答して、アクターは次のことができます:ローカルな決定を行い、より多くのアクターを作成し、より多くのメッセージを送信し、次の受信メッセージへの応答方法を決定します。.
ユースケースコード生成、データ分析タスクを自動化し、プランニングやリサーチ機能のためのカスタム・インテリジェンス(エージェント)を構築します。
AutoGenの重要な核となるコンセプトをいくつか紹介しよう:
- 代理店.知的身体(エージェント)とは、次のようなソフトウェアの実体である:
- メッセージによるコミュニケーションこれらのメッセージは同期または非同期である。
- 地位の維持この状態は、入ってくるメッセージによって変更することができる。
- 実行操作 を実行します。これらのアクションは、エージェントの状態を変更し、メッセージログの更新、新しいメッセージの送信、コードの実行、APIコールの実行など、外部に影響を与える可能性があります。
以下は、チャット機能を持つエージェントを作成するための簡単なコードです:
from autogen_agentchat.agents import AssistantAgent from autogen_agentchat.messages import TextMessage from autogen_ext.models.openai import OpenAIChatCompletionClient class MyAssistant(RoutedAgent): def __init__(self, name: str) -> None: super().__init__(name) model_client = OpenAIChatCompletionClient(model="gpt-4o") self._delegate = AssistantAgent(name, model_client=model_client) @message_handler async def handle_my_message_type(self, message: MyMessageType, ctx: MessageContext) -> None: print(f"{self.id.type} received message: {message.content}") response = await self._delegate.on_messages( [TextMessage(content=message.content, source="user")], ctx.cancellation_token ) print(f"{self.id.type} responded: {response.chat_message.content}")先のコードでは
MyAssistantから継承された。RoutedAgent.これは、メッセージの内容を表示するメッセージ・ハンドラを持っています。AssistantAgentレスポンスの送信を委任する。どのようにAssistantAgentのインスタンスはself._delegate属AssistantAgentは、チャットの補完を処理できる事前構築されたインテリジェンス(エージェント)です。
次に、AutoGenにエージェントの種類を知らせ、プログラムを開始します:# main.py runtime = SingleThreadedAgentRuntime() await MyAgent.register(runtime, "my_agent", lambda: MyAgent()) runtime.start() # Start processing messages in the background. await runtime.send_message(MyMessageType("Hello, World!"), AgentId("my_agent", "default"))先のコードでは、Agentがランタイムに登録され、次にメッセージがAgentに送信され、以下の出力が生成される:
# Output from the console: my_agent received message: Hello, World! my_assistant received message: Hello, World! my_assistant responded: Hello! How can I assist you today? - マルチエージェントAutoGenは、複雑なタスクを達成するために連携できる複数のエージェントの作成をサポートします。エージェントは、より効果的に問題を解決するために、通信し、情報を共有し、行動を調整することができます。マルチエージェント・システムを作成するには、データ検索、分析、意思決定、ユーザーとの対話など、特殊な機能と役割を持つさまざまなタイプのエージェントを定義します。このようなシステムがどのようなものかを見てみましょう:
editor_description = "Editor for planning and reviewing the content."
# Example of declaring an Agent
editor_agent_type = await EditorAgent.register(
runtime,
editor_topic_type, # Using topic type as the agent type.
lambda: EditorAgent(
description=editor_description,
group_chat_topic_type=group_chat_topic_type,
model_client=OpenAIChatCompletionClient(
model="gpt-4o-2024-08-06",
# api_key="YOUR_API_KEY",
),
),
)
# remaining declarations shortened for brevity
# Group chat
group_chat_manager_type = await GroupChatManager.register(
runtime,
"group_chat_manager",
lambda: GroupChatManager(
participant_topic_types=[writer_topic_type, illustrator_topic_type, editor_topic_type, user_topic_type],
model_client=OpenAIChatCompletionClient(
model="gpt-4o-2024-08-06",
# api_key="YOUR_API_KEY",
),
participant_descriptions=[
writer_description,
illustrator_description,
editor_description,
user_description
],
),
)
前のコードでは GroupChatManagerランタイムに登録される。このマネージャーは、ライター、イラストレーター、エディター、ユーザーのような異なるタイプのエージェント間のやりとりを調整する責任を負う。
- エージェント・ランタイムフレームワークは、エージェント間のコミュニケーションをサポートし、セキュリティとプライバシーの境界を強制するランタイム環境を提供する。フレームワークは、エージェント間のコミュニケーションをサポートし、そのアイデンティティとライフサイクルを管理し、セキュリティとプライバシーの境界を強制するランタイム環境を提供します。つまり、安全かつ制御された環境でAgentを実行し、安全かつ効率的に対話できるようにします。興味のあるランタイムは2つあります:
- スタンドアローン・ランタイムこれは、すべてのエージェントが同じプログラミング言語で実装され、同じプロセスで実行されるシングルプロセスのアプリケーションに適した選択です。これは、すべてのエージェントが同じプログラミング言語で実装され、同じプロセスで実行されるシングルプロセスのアプリケーションに適しています。以下はその仕組みの図です:
スタンドアローン・ランタイム
アプリケーションスタック
エージェントは、エージェントのライフサイクルを管理するランタイムを介してメッセージを介して通信する。 - 分散エージェント・ランタイムこれは、エージェントが異なるプログラミング言語で実装され、異なるマシン上で実行されるマルチプロセス・アプリケーションに適用できます。どのように動作するかの例を示します:
分散ランタイム
- スタンドアローン・ランタイムこれは、すべてのエージェントが同じプログラミング言語で実装され、同じプロセスで実行されるシングルプロセスのアプリケーションに適した選択です。これは、すべてのエージェントが同じプログラミング言語で実装され、同じプロセスで実行されるシングルプロセスのアプリケーションに適しています。以下はその仕組みの図です:
セマンティック・カーネル+エージェント・フレームワーク
セマンティック・カーネルは、セマンティック・カーネル・エージェント・フレームワークとセマンティック・カーネルの2つの部分から構成される。
セマンティック・カーネルについて少し説明しよう。セマンティック・カーネルには次のようなコア・コンセプトがある:
- コネクションこれは外部のAIサービスやデータソースとのインターフェイスだ。
using Microsoft.SemanticKernel;
// Create kernel
var builder = Kernel.CreateBuilder();
// Add a chat completion service:
builder.Services.AddAzureOpenAIChatCompletion(
"your-resource-name",
"your-endpoint",
"your-resource-key",
"deployment-model");
var kernel = builder.Build();
Semantic Kernelは外部のAIサービス(この場合はAzure OpenAI Chat Completion)への接続を作成します。
- プラグインアプリケーションが使用できる関数をカプセル化します。既成のプラグインと自分で作るプラグインがある。セマンティック関数と呼ばれる概念があります。セマンティックである理由は、セマンティックカーネルが関数を呼び出す必要があると判断できるように、セマンティック情報を提供するからです。以下はその例です:
var userInput = Console.ReadLine();
// Define semantic function inline.
string skPrompt = @"Summarize the provided unstructured text in a sentence that is easy to understand.
Text to summarize: {{$userInput}}";
// Register the function
kernel.CreateSemanticFunction(
promptTemplate: skPrompt,
functionName: "SummarizeText",
pluginName: "SemanticFunctions"
);
テンプレートのヒントから始めよう skPromptユーザーにテキストを入力させる $userInput プラグインのスペースを使用します。その後、プラグイン SemanticFunctions 登録機能 SummarizeText.これはセマンティック・カーネルがその関数が何をするのか、いつ呼び出されるべきなのかを理解するのに役立ちます。
- ネイティブ機能フレームワークがタスクを実行するために直接呼び出すことができるネイティブ関数もあります。以下は、ファイルからコンテンツを取得するそのような関数の例です:
public class NativeFunctions {
[SKFunction, Description("Retrieve content from local file")]
public async Task<string> RetrieveLocalFile(string fileName, int maxSize = 5000)
{
string content = await File.ReadAllTextAsync(fileName);
if (content.Length <= maxSize) return content;
return content.Substring(0, maxSize);
}
}
//Import native function
string plugInName = "NativeFunction";
string functionName = "RetrieveLocalFile";
var nativeFunctions = new NativeFunctions();
kernel.ImportFunctions(nativeFunctions, plugInName);
- プランナープランナーはユーザー入力に基づいて実行プランとポリシーを編成する。どのように実行されるべきかを表現し、セマンティック・カーネルがそれに従うように指示します。そして、タスクを実行するために必要な関数を呼び出す。以下はそのような計画の例である:
string planDefinition = "Read content from a local file and summarize the content.";
SequentialPlanner sequentialPlanner = new SequentialPlanner(kernel);
string assetsFolder = @"../../assets";
string fileName = Path.Combine(assetsFolder,"docs","06_SemanticKernel", "aci_documentation.txt");
ContextVariables contextVariables = new ContextVariables();
contextVariables.Add("fileName", fileName);
var customPlan = await sequentialPlanner.CreatePlanAsync(planDefinition);
// Execute the plan
KernelResult kernelResult = await kernel.RunAsync(contextVariables, customPlan);
Console.WriteLine($"Summarization: {kernelResult.GetValue<string>()}");
特筆 planDefinitionこれはプランナーが従う単純な命令である。そして、この計画に従って適切な関数が呼び出される。 SummarizeText およびネイティブ関数 RetrieveLocalFile.
- メモリーAIアプリケーションのコンテキスト管理を抽象化・単純化。メモリーの考え方は、これはラージ・ランゲージ・モデル(LLM)が知っておくべきことだ。この情報はベクターストアに保存することができ、最終的にはインメモリデータベースやベクターデータベースなどになる。以下は、非常に単純化したシナリオの例です。 事実 がメモリに追加される:
var facts = new Dictionary<string,string>();
facts.Add(
"Azure Machine Learning; https://learn.microsoft.com/azure/machine-learning/",
@"Azure Machine Learning is a cloud service for accelerating and
managing the machine learning project lifecycle. Machine learning professionals,
data scientists, and engineers can use it in their day-to-day workflows"
);
facts.Add(
"Azure SQL Service; https://learn.microsoft.com/azure/azure-sql/",
@"Azure SQL is a family of managed, secure, and intelligent products
that use the SQL Server database engine in the Azure cloud."
);
string memoryCollectionName = "SummarizedAzureDocs";
foreach (var fact in facts) {
await memoryBuilder.SaveReferenceAsync(
collection: memoryCollectionName,
description: fact.Key.Split(";")[1].Trim(),
text: fact.Value,
externalId: fact.Key.Split(";")[2].Trim(),
externalSourceName: "Azure Documentation"
);
}
その後、ファクトはメモリ・コレクションに格納される。 SummarizedAzureDocs をメモリに保存します。これは非常に単純化された例だが、ラージ・ランゲージ・モデル(LLM)で使用するために、情報がどのようにメモリに保存されるかがわかるだろう。
これがセマンティック・カーネル・フレームワークの基本ですが、エージェント・フレームワークについてはどうでしょうか?
Azure AIエージェントサービス
Azure AI Agent Serviceは、Microsoft Ignite 2024で発表された新しいメンバーだ。Llama 3、Mistral、Cohereのようなオープンソースの大規模言語モデル(LLM)を直接呼び出すなど、より柔軟なモデルでAIエージェントを開発・展開できる。
Azure AI Agent Serviceは、エンタープライズアプリケーションに適した、より強力なエンタープライズセキュリティメカニズムとデータストレージ方法を提供する。
AutoGenやSemantic KernelのようなMulti-Agentオーケストレーション・フレームワークとすぐに連動する。
このサービスは現在パブリックプレビュー中で、エージェントを構築するためにPythonとC#をサポートしています。
コア・コンセプト
Azure AI Agent Serviceには、以下のコアコンセプトがある:
- 代理店Azure AI Agent Serviceは、Azure AI Foundryと統合されている。AI Foundryでは、AIインテリジェンス(エージェント)は、質問に答えるために使用できる「スマート」なマイクロサービスとして機能する(ラグ)、操作の実行、またはワークフローの完全な自動化を可能にする。これは、生成AIモデルの機能と、実世界のデータソースにアクセスし、相互作用することを可能にするツールを組み合わせることによって実現されます。以下はエージェントの例です:
agent = project_client.agents.create_agent(
model="gpt-4o-mini",
name="my-agent",
instructions="You are helpful agent",
tools=code_interpreter.definitions,
tool_resources=code_interpreter.resources,
)
この例では、モデル gpt-4o-mini名称 my-agent と指令 You are helpful agent エージェントはコード解釈タスクを実行するためのツールとリソースを備えている。エージェントは、コード解釈タスクを実行するためのツールとリソースを備えています。
- スレッドとメッセージ.スレッドはもう一つの重要な概念である。これは、エージェントとユーザー間のダイアログやインタラクションを表します。スレッドは、ダイアログの進行状況を追跡し、コンテキスト情報を保存し、インタラクションの状態を管理するために使用できます。以下はスレッドの例です:
thread = project_client.agents.create_thread()
message = project_client.agents.create_message(
thread_id=thread.id,
role="user",
content="Could you please create a bar chart for the operating profit using the following data and provide the file to me? Company A: $1.2 million, Company B: $2.5 million, Company C: $3.0 million, Company D: $1.8 million",
)
# Ask the agent to perform work on the thread
run = project_client.agents.create_and_process_run(thread_id=thread.id, agent_id=agent.id)
# Fetch and log all messages to see the agent's response
messages = project_client.agents.list_messages(thread_id=thread.id)
print(f"Messages: {messages}")
前のコードでは、スレッドが作成された。その後、スレッドにメッセージが送信される。メッセージは create_and_process_runその後、エージェントはスレッド上で作業を実行するように要求されます。最後に、メッセージがキャプチャされ、エージェントからの応答を見るためにログに記録されます。メッセージは、ユーザとエージェント間の対話の進行状況を示します。メッセージには、テキスト、画像、ファイルなど様々なタイプがあり、Agent の作業によって、例えば画像やテキストのレスポンスが得られることを理解することも重要です。開発者としては、この情報を使ってレスポンスをさらに処理したり、ユーザに提示したりすることができます。
- 他のAIフレームワークとの統合Azure AI Agent Serviceは、AutoGenやSemantic Kernelなどの他のフレームワークと相互作用することができます。つまり、Agent Serviceをオーケストレーターとして使用するなど、アプリケーションの一部をいずれかのフレームワークで構築することもできますし、すべてをAgent Serviceで構築することもできます。
ユースケースAzure AI Agent Service:Azure AI Agent Serviceは、AIインテリジェンス(エージェント)のセキュアでスケーラブルかつ柔軟なデプロイメントを必要とするエンタープライズアプリケーション向けに設計されている。
これらのフレームワークの違いは何ですか?
これらのフレームワークには多くの重複点があるように聞こえるが、設計、機能、ターゲットとするユースケースにはいくつかの重要な違いがある:
- オートジェン複数のラージ・ランゲージ・モデル(LLM)やSLM、ツール、先進的なマルチエージェント・デザイン・パターンをサポートする、イベント駆動型の分散エージェント・アプリケーションに重点を置いています。
- セマンティック・カーネルより深い意味を理解し、人間のようなテキストコンテンツを生成することに重点を置いています。複雑なワークフローを自動化し、プロジェクト目標に基づいてタスクを開始するように設計されています。
- Azure AIエージェントサービスLlama 3、Mistral、Cohereなどのオープンソースの大規模言語モデル(LLM)を直接呼び出すことができるなど、より柔軟なモデルを提供します。
まだどれを選べばいいかわからない?
ユースケース
一般的な使用例を見て、私たちがお役に立てるかどうか考えてみましょう:
Q: 私のチームは、自動コード生成とデータ分析タスクを含むプロジェクトを開発しています。どのフレームワークを使うべきでしょうか?
A: AutoGenは、イベント駆動型の分散エージェント型アプリケーションに重点を置いており、高度なマルチエージェント設計パターンをサポートしているため、このような場合に適しています。
Q: このユースケースにおいて、AutoGenがSemantic KernelやAzure AI Agent Serviceよりも優れている点は何ですか?
A: AutoGenは、イベント駆動型の分散エージェント型アプリケーション向けに設計されており、コード生成やデータ分析作業の自動化に最適です。複雑なマルチエージェントシステムを効率的に構築するために必要なツールと機能を提供します。
Q:Azure AI Agent Serviceはここでも機能し、コード生成などのツールもあるようですね?
A: はい、Azure AI Agent Serviceもコード生成とデータ分析タスクをサポートしていますが、安全でスケーラブルかつ柔軟なAIエージェントのデプロイメントを必要とするエンタープライズアプリケーションには、こちらの方が適しているかもしれません。AutoGenは、イベント駆動型の分散エージェント型アプリケーションと高度なマルチエージェント設計パターンに重点を置いている。
Q: つまり、エンタープライズに参入したいのであれば、Azure AI Agent Serviceを使うべきだということですか?
A: はい、Azure AI Agent Serviceは、AIインテリジェンス(エージェント)のセキュアでスケーラブルかつ柔軟なデプロイメントを必要とするエンタープライズアプリケーション向けに設計されています。より強力なエンタープライズセキュリティメカニズムとデータストレージ方法を提供し、エンタープライズユースケースに適しています。
主な違いを表にまとめてみよう:
| 図案 | 再集計 | コア・コンセプト | ユースケース |
|---|---|---|---|
| オートジェン | イベント駆動、分散エージェント型アプリケーション | エージェント、ペルソナ、機能、データ | コード生成、データ分析作業 |
| セマンティック・カーネル | ヒューマノイド・テキストコンテンツの理解と生成 | エージェント、モジュラー・コンポーネント、コラボレーション | 自然言語理解、コンテンツ生成 |
| Azure AIエージェントサービス | 柔軟なモデリング、エンタープライズ・セキュリティ、コード生成、ツール呼び出し | モジュール化、コラボレーション、プロセスオーケストレーション | AIインテリジェンス(エージェント)の安全でスケーラブルかつ柔軟な展開 |
それぞれのフレームワークの理想的な使用例とは?
- オートジェンイベント駆動、分散エージェント型アプリケーション、高度なマルチエージェント設計パターン。自動コード生成、データ分析タスクに最適。
- セマンティック・カーネル人間のようなテキストコンテンツの理解と生成、複雑なワークフローの自動化、プロジェクト目標に基づいたタスクの開始。自然言語理解、コンテンツ生成に最適です。
- Azure AIエージェントサービス柔軟なモデル、エンタープライズ・セキュリティ・メカニズム、データ保存方法。セキュアでスケーラブル、かつ柔軟なAIインテリジェンス(エージェント)のエンタープライズ・アプリケーションへの導入に最適です。
既存のAzureエコシステムツールと直接統合できますか、それともスタンドアローンのソリューションが必要ですか?
答えはイエスで、特に他のAzureサービスとシームレスに動作するように設計されているため、既存のAzureエコシステムのツールをAzure AI Agent Serviceと直接統合することができます。例えば、Bing、Azure AI Search、Azure Functionsを統合することができます。また、Azure AI Foundryとの深い統合もあります。
AutoGenとSemantic Kernelについては、Azureサービスと統合することもできますが、この場合、コードからAzureサービスを呼び出す必要があるかもしれません。別の統合方法としては、Azure SDKを使用してAgentからAzureサービスとやり取りする方法があります。さらに、前述のように、AutoGenやSemantic Kernelで構築されたAgentのオーケストレーターとしてAzure AI Agent Serviceを使用することができ、Azureエコシステムへのアクセスが容易になります。
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事




コメントはありません