LLMベースのText-to-SQLの開発プロセスを整理する1万字の記事

OlaChat AI デジタル・インテリジェンス・アシスタント 10,000ワードに及ぶ詳細な分析により、Text-to-SQL技術の過去と現在を理解することができます。
論文:次世代データベース・インターフェース:LLMベースのText-to-SQLに関する研究
自然言語の問題から正確な SQL を生成すること(text-to-SQL)は、ユーザの問題理解、データベーススキーマの理解、SQL 生成が複雑であるため、長年の課題となっています。以下のような従来のテキストから SQL を生成するシステムは人工工学とディープ・ニューラル・ネットワーク実質的な進展があった。その後訓練済み言語モデル(PLM)が開発され、テキストからSQLへの変換タスクに使用され、有望な性能を達成しています。最新のデータベースがより複雑になるにつれて、対応するユーザの問題はより困難になり、その結果、パラメータ制約のあるPLM(事前学習済みモデル)が誤ったSQLを生成するようになります。このため、より高度なカスタマイズされた最適化手法が必要となり、PLMベースのシステムの適用が制限されます。
近年、大規模言語モデル(Large Language Models: LLM)は、モデルサイズの増大により、自然言語理解において大きな能力を発揮している。そのため、LLMベースの実装を統合することでは、text-to-SQL 研究にユニークな機会、改善、解決策をもたらす可能性があります。このサーベイでは、LLMベースのtext-to-SQLに関する包括的なレビューを行う。具体的には、著者らはtext-to-SQLの技術的課題と進化の過程を簡単に概観する。次に、text-to-SQLシステムを評価するために設計されたデータセットと評価指標について詳細に説明する。その後、LLMベースのtext-to-SQLにおける最近の進歩を体系的に分析する。最後に、この分野に残された課題について議論し、今後の研究の方向性への期待を示す。
本文中で特に「[xx]」で言及されている論文は、原著論文の参考文献セクションで参照できる。
紹介
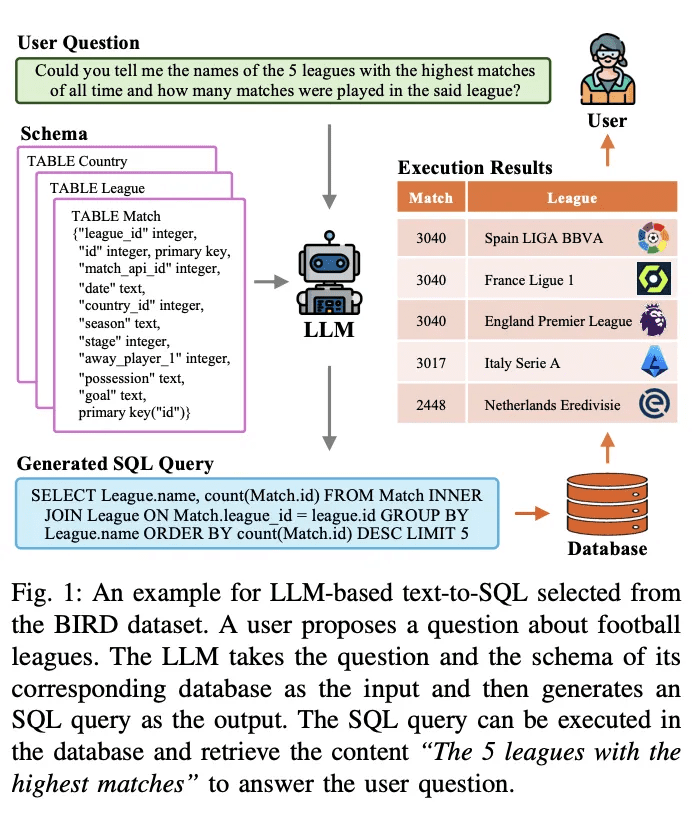
Text-to-SQLは、自然言語処理研究において長年の課題である。これは自然言語問題をデータベースで実行可能なSQLクエリに変換(翻訳)することを目的としている。図1は、大規模言語モデル(LLMベース)に基づくテキスト-to-SQLシステムの例である。例えば、「歴史上最も多くの試合が行われた5つのリーグの名前と、そのリーグで行われた試合数を教えてください」といったユーザの質問が与えられると、LLM は質問とそれに対応するクエリを実行可能な SQL クエリに変換します。LLMは質問とそれに対応するデータベーススキーマを入力として受け取り、それを分析します。そして出力としてSQLクエリを生成します。このSQLクエリをデータベースで実行することで、ユーザーの質問に答えるための関連コンテンツを検索することができる。上記のシステムは、LLMを使ってデータベースへの自然言語インターフェース(NLIDB)を構築している。
SQLは現在でも最も広く使われているプログラミング言語の一つであり、プロの開発者の半数(51.52%)がSQLを業務で使用している。また、人間とコンピュータのインタラクションを加速する[3]。さらに、LLM における研究ホットスポットの中でも、text-to-SQL は、データベースから実際のコンテンツを取り込むことで LLM における知識ギャップを埋めることができ、錯覚の蔓延する問題に対する潜在的な解決策を提供します[4, 5] [6]。text-to-SQLの大きな価値と可能性は、LLMとの統合と最適化に関する一連の研究を引き起こしました。
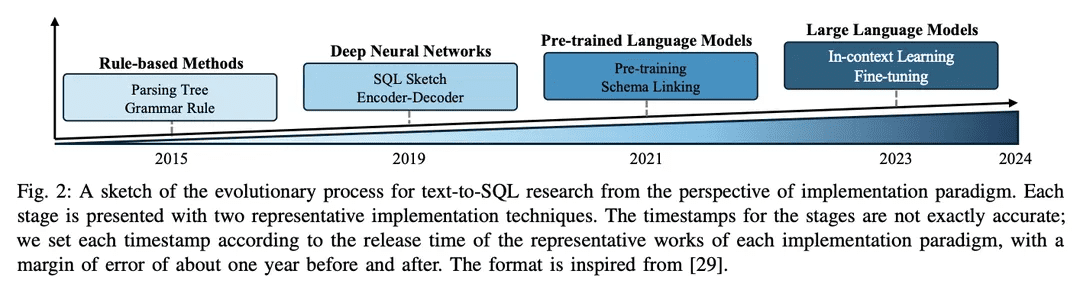
これまでの研究は、text-to-SQLの実装において大きな進歩を遂げ、長い進化の過程を経てきました。初期の研究のほとんどは、よく設計されたルールとテンプレート [11]に基づいており、これらは特に単純なデータベースシナリオに適していました。近年では、ルールベースのアプローチ[12]に関連する高い人件費とデータベース環境の複雑化[13 - 15]により、各シナリオに対してルールやテンプレートを設計することはますます困難かつ非現実的になってきています。Text-to-SQLの進歩は、ディープニューラルネットワーク[16, 17]の開発によって促進され、ユーザーの質問から対応するSQLへのマッピングを自動的に学習する[18, 19]。その後、強力な意味解析機能を持つ事前学習済み言語モデル(PLM)がテキスト-to-SQLシステムの新しいパラダイムとなり[20]、その性能は新たなレベルに達しました[21 - 23]。PLMベースの最適化(例えば、テーブルコンテンツエンコーディング[19 , 24 , 25]や事前学習[20 , 26])に関する進歩的な研究は、この分野をさらに発展させました。最近ではLLMベースのアプローチは、コンテキスト学習(ICL)[8]と微調整(FT)[10]のパラダイムを通じて、テキストからSQLへの変換を実装する。同社は、よく設計されたフレームワークとPLMよりも深い理解によって、最先端の精度を実現している。
LLMベースのtext-to-SQLの全体的な実装の詳細は、3つの領域に分けることができる:
1) 問題の理解NL質問はユーザーの意図を意味的に表現したものであり、対応する生成されたSQLクエリはそれらと一致する必要があります;
2) パターン理解スキーマはデータベースのテーブルとカラムの構造を提供し、text-to-SQLシステムはユーザの問題にマッチするターゲットコンポーネントを特定する必要があります;
3) SQL生成これは、上記の構文解析を組み合わせ、正しい構文を予測して実行可能な SQL クエリを生成し、目的の答えを取得するものです。LLMは、豊富な学習コーパス[28, 29]によって、より強力な意味解析能力を持つため、テキストからSQLへの機能をうまく実装できることが示されている[7, 27]。問題理解[8,9]、パターン理解[30,31]、SQL生成[32]のためにLLMを強化する研究がさらに進んでいる。
テキストからSQLへの研究が大きく進展しているにもかかわらず、堅牢で汎用的なテキストからSQLへのシステムの開発を妨げているいくつかの課題が残っています[ 73 ]。近年の関連研究では、深層学習アプローチにおけるテキスト-to-SQLシステムを調査し、以前の深層学習アプローチとPLMベースの研究に対する洞察を提供しています。本調査の目的は、最新の進歩をキャッチアップし、LLMベースのtext-to-SQLの現在の最新モデルとアプローチの包括的なレビューを提供することです。まず、text-to-SQLに関連する基本的な概念と課題を紹介し、様々なドメインにおけるこのタスクの重要性を強調する。次に、text-to-SQLシステムの実装パラダイムの進化を詳細に見て、この分野における主な進歩とブレークスルーを議論する。この概要に続いて、LLM統合のためのテキストからSQLへの変換における最新の進歩の詳細な説明と分析が行われます。具体的には、このサーベイ・ペーパーはLLMベースのtext-to-SQLに関連する以下のようなトピックを取り上げています:
● データセットとベンチマークLLMベースのtext-to-SQLシステムを評価するために一般的に使用されるデータセットとベンチマークについて詳述。その特徴、複雑さ、そしてテキストからSQLの開発・評価における課題について論じる。
● 指標の評価LLM ベースの text-to-SQL システムの性能を評価するために使用される評価指標について、内容マッチングベースと実行ベースの例を含めて紹介する。その後、各評価指標の特徴を簡単に説明する。
● 方法とモデル本稿では、LLMに基づくテキストからSQLへの変換に使用される様々なアプローチとモデルを、文脈学習と微調整に基づく例を含めて体系的に分析する。それらの実装の詳細、利点、そしてテキストからSQLへのタスクへの適応について、様々な実装の観点から議論する。
● 期待と今後の方向性本稿では、LLMベースのtext-to-SQLに残された課題と限界について議論する。また、将来的な研究の方向性や改善・最適化の機会についても概説する。
中抜き
Text-to-SQLは、自然言語の質問をリレーショナルデータベースで実行可能な対応するSQLクエリに変換することを目的としたタスクです。形式的には、ユーザの質問 Q(ユーザクエリ、自然言語質問などとも呼ばれる)とデータベーススキーマ S が与えられた場合、タスクの目標は、ユーザの質問に答えるために必要なコンテンツをデータベースから取得する SQL クエリ Y を生成することです。Text-to-SQLは、SQLプログラミングの専門知識を必要とせずに、ユーザが自然言語を使ってデータベースと対話できるようにすることで、データアクセスを民主化する可能性を秘めています[75]。熟練していないユーザがデータベースから目的のコンテンツを簡単に取得できるようになり、より効果的なデータ分析が容易になることで、ビジネスインテリジェンス、カスタマーサポート、科学研究など多様な分野に利益をもたらすことができる。
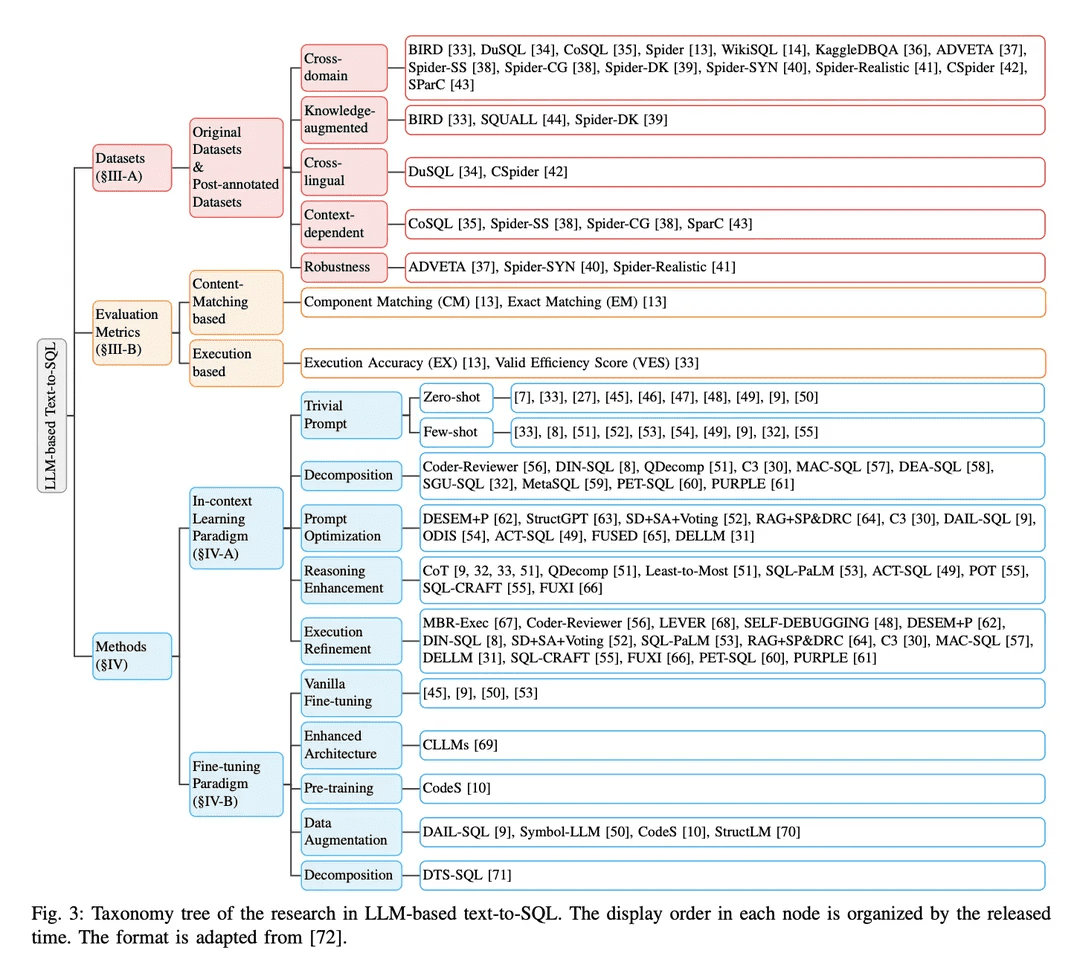
A. Text-to-SQL における課題
text-to-SQL 実装の技術的課題は以下のように要約できる:
1)言語の複雑さと曖昧さ自然言語の問題には、入れ子になった句、共参照、省略記号などの複雑な言語表現が含まれることが多く、SQLクエリの対応する部分に正確にマッピングすることは困難です[41]。さらに、自然言語は本質的に曖昧であり、与えられたユーザーの問題に対して複数の表現が可能である [76, 77]。このような曖昧さを解決し、ユーザーの問題の背後にある意図を理解するには、自然言語を深く理解し、コンテキストとドメインの知識を統合する能力が必要です[33]。
2)パターンの理解と表現正確なSQLクエリを生成するために、text-to-SQLシステムは、テーブル名、カラム名、各テーブル間のリレーションシップを含むデータベーススキーマを完全に理解する必要があります。しかし、データベースのスキーマは複雑で、ドメインによって大きく異なることがあります[13]。スキーマ情報をテキストから SQL へ の変換モデルで効果的に利用できるように表現し、符号化することは困難な作業です。
3)稀で複雑なSQL操作SQL クエリの中には、ネストされたサブクエリ、外部結合、ウィンドウ関数など、難易度の高いシ ナリオでは珍しい、あるいは複雑な操作や構文を含むものがあります。これらの操作は学習データではあまり一般的ではなく、テキストからSQLへの変換システムを正確に生成するための課題となる。稀で複雑なシナリオを含む様々なSQL操作に汎化するモデルを設計することは、重要な検討事項である。
4)領域横断的一般化テキストからSQLへ変換するシステムは、様々なデータベースシナリオやドメインで一般化することが難しい場合が多い。語彙、データベーススキーマ構造、問題パターンが多様であるため、特定のドメインで訓練されたモデルは、他のドメインで提起された問題をうまく扱えない可能性がある。最小限のドメイン固有の訓練データまたは微調整された適応を使用して、新しいドメインに効果的に汎化できるシステムを開発することは、大きな課題である[78]。
B. 進化のプロセス
テキストから SQL の研究分野は、ルールベースからディープラーニングベースのアプローチに進化し、最近では事前学習済み言語モデル (PLM)と大規模言語モデル(LLM)の統合へと、長年にわたって NLP コミュニティで大きな進歩を遂げてきました。
1) ルール・ベース・アプローチ初期のtext-to-SQLシステムは、ルールベースのアプローチ[11, 12, 26]に大きく依存していました。このようなアプローチには、一般的に重要なフィーチャーエンジニアリングとドメイン固有の知識が含まれます。ルールベースのアプローチは、特定の単純なドメインでは成功を収めているが、幅広い複雑な問題を扱うために必要な柔軟性と汎用性に欠けている。
2)ディープラーニングに基づくアプローチディープ・ニューラル・ネットワークの台頭シーケンス間モデリングとエンコーダ・デコーダ・アーキテクチャ(自然言語入力からSQLクエリを生成するために、LSTM[79]やコンバータ[17]などが使用されている[19 , 80 ]。一般的に、RYANSQL[19]は、複雑な問題を処理し、領域横断的な一般性を向上させるために、中間表現やスケッチベースのスロット充填などの技術を導入している。最近では、スキーマに依存したグラフはデータベース要素間の関係を表す最初のステップは、新しいtext-to-SQLタスクであるグラフ・ニューラル・ネットワーク(GNN)[18,81].
3) PLMベースの導入テキスト-to-SQLにおけるPLMの初期のアプリケーションは、BERT [24]やRoBERTa [82][13,14]などの標準的なテキスト-to-SQLデータセット上で既製のPLMを微調整することに重点を置いていました。これらのPLMは大規模な訓練コーパスで事前に訓練されており、豊富な意味表現と言語理解能力を備えています。テキストからSQLへの変換タスクでPLMを微調整することで、研究者はPLMの意味的・言語的理解能力を活用し、正確なSQLクエリを生成することを目指しています[20, 80, 83]。もう一つの研究方向は、ユーザがデータベース構造を理解し、より実行可能なSQLクエリを生成できるようにするために、スキーマ情報をPLMに組み込むことです。スキーマ対応PLMは、データベース構造に存在する関係や制約を把握するように設計されています[21]。
4) LLMベースの実装大規模言語モデル(LLM)はGPTファミリー[84 -86 ]などのように、首尾一貫した流暢なテキストを生成する能力で近年注目されています。研究者は、LLMの広範な知識ベースと優れた生成能力を利用することで、テキストからSQLへの可能性を模索し始めています[7, 9]。これらのアプローチでは、SQL生成時に独自のLLMのヒントエンジニアリングを指示したり[47]、text-to-SQLデータセット上でオープンソースのLLMを微調整したり[9]しています。
テキストからSQLへのLLMの統合は、さらなる探求と改善の大きな可能性を秘めた、まだ新しい研究分野です。研究者たちは、LLMの知識と推論能力をより良く利用する方法、ドメイン固有の知識を取り入れる方法[31, 33]、そしてより効率的な微調整戦略を開発する方法を研究しています[10]。この分野が発展し続けるにつれて、より高度で優れたLLMベースの実装が開発され、テキストからSQLへの性能と汎化が新たな高みに到達することが期待されます。
ベンチマークと評価
このセクションでは、よく知られたデータセットや評価指標を含むテキストからSQLへのベンチマークを紹介します。
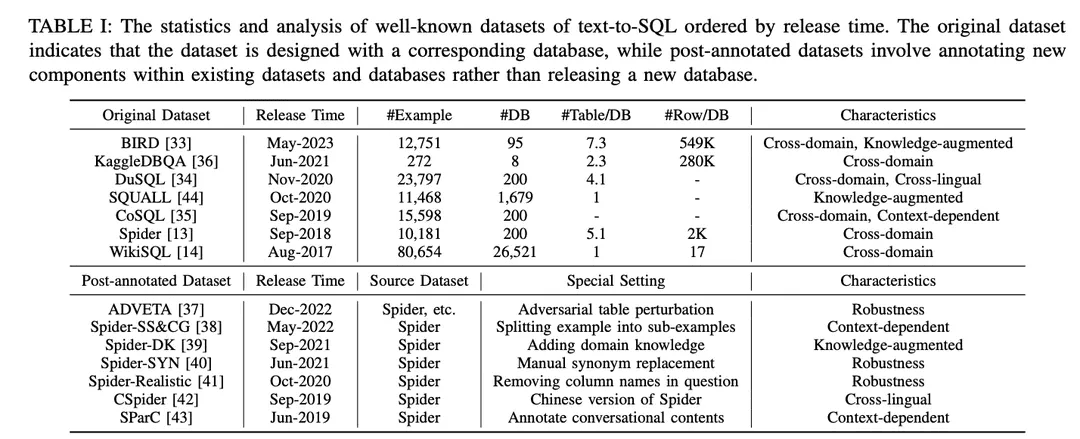
A. データセット
表Iに示すように,データセットは「オリジナルデータセット」と「ポストアノテーションデータセット」に分類される.オリジナルデータセット」と「ポストアノテーションデータセット」は、オリジナルのデータセットやデータベースとともに公開されているデータセットか、既存のデータセットやデータベースに特別な設定を施して作成されたデータセットかによって分類されている。オリジナルのデータセットについては,例数,データベース数,データベースあたりのテーブル数,データベースあたりの行数など,詳細な分析が行われている.注釈付きデータセットについては、ソースデータセットを特定し、それらに適用された特定の設定について説明する。各データセットの潜在的な可能性を説明するために、そのデータセットはその特徴に従って注釈を付けられた。注釈は表Iの右端に列挙されている。以下、さらに詳しく説明する。
1) クロス・ドメイン・データセットこれは、異なるデータベースの背景情報が異なるドメインから来たデータセットを指します。現実のtext-to-SQLアプリケーションは通常複数のドメインのデータベースを含むので、オリジナルのtext-to-SQLデータセット[13,14,33 - 36]やアノテーション後のデータセット[37 - 43]のほとんどはクロスドメインの設定になっている。
2) 知識強化データセットBIRD [ 33 ] は、人間のデータベース専門家を利用して、テキストからSQLへの各サンプルに、数値推論知識、ドメイン知識、同義語知識、および値文に分類された外部知識を注釈します。同様に、Spider-DK [ 39 ] はSpiderデータセット[13]を人間の編集者のために手動で編集しています。SELECT列が省略され、単純な推論が要求され、セル値の単語で同義語置換が行われ、セル値でない単語が条件を生成し、他のドメインと衝突しやすくなっています。どちらの研究でも、手動で注釈を付けた知識は、外部ドメイン知識を必要とするサンプルの SQL 生成パフォーマンスを大幅に向上させることがわかった。さらに、SQUALL[44]は、NL問題の単語とSQLのエンティティの間のアライメントを手動で注釈し、他のデータセットよりもきめ細かい監視を提供している。
3) コンテキストに関連したデータセットSParC[43]とCoSQL[35]は、セッションデータベース用のクエリシステムを構築することで、コンテキスト依存のSQL生成を探求しています。SParC は、Spider データセットの質問 SQL 例を複数のサブ質問 SQL ペアに分解し、SQL 生成に寄与する相互に関連するサブ質問や、データの多様性を高める関連しないサブ質問を含む、シミュレートされた意味のある対話を構築します。対照的に、CoSQLは実世界のシナリオをシミュレートする自然言語対話インタラクションを含み、複雑性と多様性を高めます。さらに、Spider-SS&CG[38]はSpiderデータセット[13]のNL問題を複数のサブ問題とサブSQLに分割し、これらのサブサンプルに対する学習がテキストからSQLへのシステムの汎化能力のサンプル分布を改善することを実証しています。
4) ロバストネス・データセットSpider-Realistic[41]はNL質問からスキーマに関連する用語を明示的に削除し、Spider-SYN[40]はそれらの用語を手動で選択した同義語に置き換えます。ADVETA [ 37 ]は敵対的テーブル摂動(ATP)を導入し、元のカラム名を誤解を招く置換で置き換えたり、意味的関連性は高いが意味的等価性が低い新しいカラムを挿入したりすることで、テーブルを摂動する。このような摂動は、精度の大幅な低下につながる可能性がある。ロバストでないテキストからSQLへのシステムは、NL問題におけるトークンとデータベースエンティティのミスマッチに惑わされる可能性があるからである。
5) 異言語データセットCSpider[42]はSpiderデータセットを中国語に翻訳し、単語のセグメンテーションと中国語の質問と英語のデータベースコンテンツ間の言語間マッチングにおける新たな課題を発見しました。DuSQL[34]は、中国語の質問と英語・中国語のデータベースコンテンツを含む実用的なテキストからSQLへのデータセットを紹介している。
B. 評価指標
テキストをSQLに変換するタスクの評価指標として、SQLの内容マッチングに基づく "Component Matching "と "Exact Matching"、および実行結果に基づく "Execution Accuracy "の4つの評価指標を紹介する。"と "実効効率スコア "である。
1) コンテンツ・マッチングに基づく指標SQLコンテンツ・マッチング指標は主に、予測されたSQLクエリと実際のSQLクエリの構造的・構文的類似性に基づいています。
コンポーネント・マッチング(CM)[13] テキストからSQLへの変換システムの性能は、予測されたSQLコンポーネント(SELECT、WHERE、GROUP BY、ORDER BY、KEYWORDS)と実際のSQLコンポーネント(GROUP BY、ORDER BY、KEYWORDS)の完全一致をF1スコアを用いて測定することで評価される。各コンポーネントはサブコンポーネントの集合に分解され、順序制約のない SQL コンポーネントを考慮して完全一致を比較する。
完全一致(EM))[ 13]は、予測されたSQLクエリがグランドトゥルースのSQLクエリと完全に一致する例のパーセンテージを測定します。予測されたSQLクエリは、その全ての構成要素(CMに記述されている)が、グランドトゥルースのクエリの構成要素と完全に一致する場合にのみ正しいとみなされます。
2)実施ベースの指標実行結果メトリクスは、ターゲット・データベース上でクエリを実行した結果と期待される結果を比較することで、生成されたSQLクエリの正しさを評価します。
実行精度(EX)[13] 予測されたSQLクエリの正しさは、対応するデータベースでクエリを実行し、グランドトゥルースのクエリから得られた結果と比較することで測定される。
有効効率スコア(VES)33]の定義は、効果的なSQLクエリの効率を測定することです。有効なSQLクエリとは、その実行結果が基本的な真の結果と同一である予測SQLクエリである。具体的には、VESは同時にSQLクエリの効率と精度の予測.N個の例を含むテキストデータセットに対して、VESは次のように計算される:

R(Y_n, Y_n)は、実際のクエリと比較した予測SQLクエリの相対的な実行効率を示す。
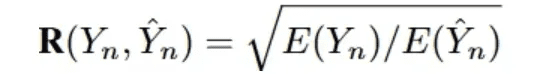
最近のLLMベースのtext-to-SQL研究は、Spider[13]、Spider-Realistic[41]、Spider-SYN[40]、BIRD[33]の4つのデータセットと、EM、EX、VESの3つの評価手法に焦点を当てています。
方法論
LLMベースのアプリケーションの現在の実装は、ICL(In-Context Learning)(Just-in-Time Engineering)[87-89]とFT(Fine-Tuning)[90,91]のパラダイムに大きく依存しており、強力なプロプライエタリモデルとよく設計されたオープンソースモデルが大量にリリースされています[45,86,92-95]。LLMベースのtext-to-SQLシステムは、これらのパラダイムに従って実装されています。本調査では、これらについて説明します。
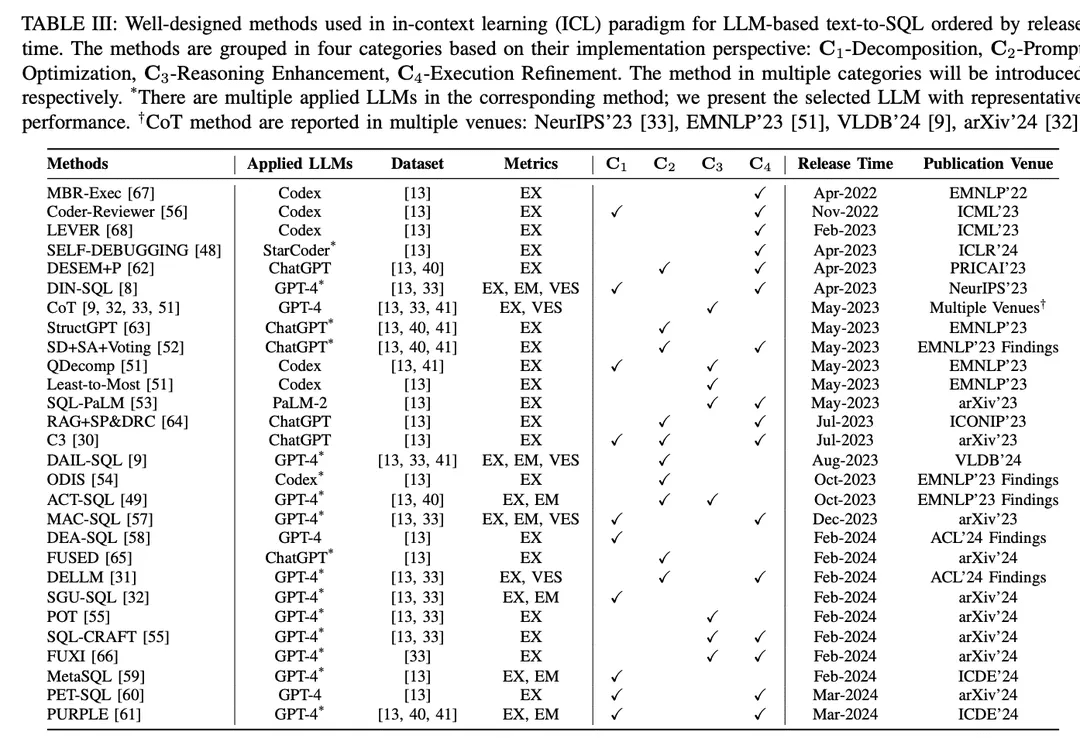
A. 文脈学習
ヒント工学はLLMの性能[28 , 96 ]に決定的な役割を果たすだけでなく、異なるヒントスタイル[9 , 46]の下でのSQL生成にも影響を与えることが、広範でよく知られた研究によって示されている。従って、文脈学習(ICL)パラダイムにおけるテキストからSQLへの手法の開発は、有望な改善を達成するために貴重である。実行可能なSQLクエリYを生成するLLMベースのtext-to-SQLプロセスの実装は以下のように定式化できる:

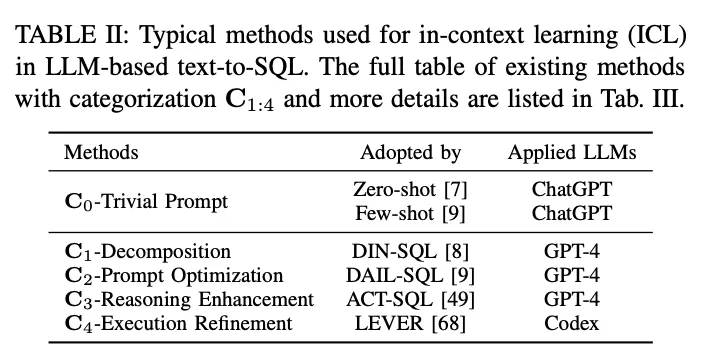
文脈学習(ICL)パラダイムでは、既製のテキストからSQLへのモデル(すなわち、モデルのパラメータθは凍結されている)を使用して、予測SQLクエリを生成する。LLMベースのtext-to-SQLタスクは、ICLパラダイムにおいて設計された様々な手法を採用している。これらはC0-単純ヒンティング、C1-分解、C2-ヒント最適化、C3-推論強化、C4-実行洗練の5つのカテゴリーC0:4に分類される。表IIに各カテゴリの代表を示す。
C0-トリビアル・プロンプトLLMは膨大なデータで訓練され、ゼロサンプルや少数のキューを使用する様々なダウンストリームタスクにおいて強い総合的な熟練度を持っており[90 , 97, 98 ]、これは広く認識され、実用的なアプリケーションに適用されている。本調査では、精緻なフレーミングを伴わない前述のプロンプト 方法をトリビアルプロンプト(偽プロンプト工学)として分類した。上述したように、式3はLLMベースのテキストからSQLへのプロセスを記述しており、これはゼロサンプルプロンプトを示すこともできる。全体的な入力 P0 は I、S、Q を接続することで得られる:
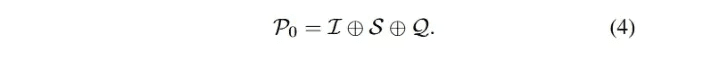
プロンプトプロセスを標準化するために、OpenAI demo2は、テキストからSQLへの標準的な(単純な)プロンプトとして設定された[30]。
ゼロサンプル多くの研究[7,27,46]がゼロサンプルヒンティングを利用し、ヒント作成スタイルと様々なLLMがtext-to-SQLのゼロサンプル性能に与える影響に焦点を当てています。実証的評価として、[7]はベースラインのtext-to-SQL機能と異なるヒンティングスタイルについて、初期に開発された異なるLLM[85, 99, 100]の性能を評価しました。その結果、オンザフライ設計が性能にとって重要であることが示され、エラー分析を通じて、[7]はデータベースの内容が多くなると全体的な精度が損なわれる可能性があることを示唆しています。また チャットGPT ChatGPTは、対話シナリオとコード生成において優れた能力を持ち[101]、[27]ではテキストからSQLへの変換性能を評価しました。ゼロサンプル設定により、ChatGPTは最新のPLMベースのシステムと比較して、テキストからSQLへの変換性能が優れていることが示されました。公正な比較のために、[47]はLLMベースのtext-to-SQLに効果的なプロンプトの構成を明らかにしました。
主キーと外部キーは異なるテーブルの継続的な知識を保持する。[49]は、異なるデータベース内容に対する様々なヒントスタイルにこれらのキーを組み込み、ゼロサンプルのヒンティング結果を分析することにより、これらのキーの影響を調査した。外部キーの影響はベンチマーク評価[9]でも調査され、ディレクティブ、ルールの意味、外部キーの順列とみなせる5つの異なるヒント表現スタイルが含まれた。外部キーに加え、本研究では、簡潔な出力を収集するために、ゼロサンプルヒントと「解釈なし」ルールインプリケーションの組み合わせも検討した。人間の専門家の外部知識のアノテーションに支えられた[33 ]は、標準的なヒントを踏襲し、提供されたアノテーションされたオラクル知識を組み合わせることで改善を達成した。
オープンソースのLLMの爆発的な増加に伴い、これらのモデルも同様の評価[45, 46, 50]、特にコード生成モデル[46, 48]によれば、ゼロサンプルのテキストからSQLへのタスクが可能である。ゼロサンプルのヒンティング最適化のために、[46]はLLMのための効果的なヒンティングテンプレートを設計するという課題を提示した。以前のヒンティング構成は構造的な統一性を欠いており、LLMの性能に影響を与えるヒンティング構成テンプレート内の特定の要素を特定することが困難であった。この課題に対処するため、彼らは、異なる接頭辞、接尾辞、接頭辞-接尾辞で調整された、より均一な一連の手がかりテンプレートを調査した。
いくつかのヒントヒント数の少ないヒンティング手法は、実用的なアプリケーションとよく設計された研究の両方で広く使用されており、LLMの性能を向上させるのに効果的であることが示されています[ 28 , 102 ]。ヒント数が少ない場合のLLMベースのtext-to-SQLヒンティング法の全体的な入力ヒンティングは式3の拡張として定式化することができる:

実証研究として、テキストからSQLへの数発ヒンティングが複数のデータセットと様々なLLMで評価され[8 , 32]、ゼロサンプルヒンティングと比較して良好な性能を示しました。[33]は、正確なSQLを生成するためのtext-to-SQLモデルのワンショットトリガーの詳細な例を提供しています。[55]は少数の例の影響を調査している。[52]はサンプリング戦略に焦点を当て、異なる例間の類似性と多様性を調査し、ランダムサンプリングのベンチマークを行い、比較のために異なる戦略8とその組み合わせを評価しています。さらに、[9]では、類似度に基づく選択に加えて、マスキング問題に対する類似度選択の上限と、様々な数の少ないサンプル模範を用いた類似度方法を評価している。難易度レベルでのサンプル選択に関する研究[51]では、難易度カテゴリカルデータセット[13, 41]において、小サンプルCodex[100]の性能と、小サンプルインスタンスのランダム選択と難易度ベース選択を比較した。異なる難易度で選択されたサンプル数に基づいて、3つの難易度ベースの選択戦略が設計された。[49]は、少数の手がかりに対して、静的な例と類似度に基づく動的な例を組み合わせたハイブリッド戦略を利用してサンプルを選択した。彼らのセットアップでは、異なる入力パターンスタイルと様々な静的・動的サンプルサイズの効果も評価されている。
ドメイン間の少数の例の影響も調査されている[54 ]。異なる数のドメイン内とドメイン外の例を含めると、ドメイン内の例は0次とドメイン外の例を上回った。例の数が増えるにつれて、ドメイン内の例のパフォーマンスが良くなる.入力ヒントの詳細な構造を調べるために、[53]は簡潔なヒントと冗長なヒントの設計アプローチを比較した。前者はスキーマ、カラム名、主キー、外部キーを項目ごとに分割し、後者はそれらを自然言語記述に整理する。
C1-分解直感的な解決策として、困難なユーザ問題をより単純なサブ問題に分解したり、複数のコンポーネントを使用して実装することで、テキストからSQLへの変換タスク全体の複雑さを軽減することができます[8, 51]。LLMベースのテキストからSQLへの分解手法は2つのパラダイムに分類されます:(1) サブタスクの内訳さらに、テキストからSQLへのタスク全体を、より管理しやすく効率的なサブタスク(スキーマリンク[71]、ドメイン分類[54]など)に分解することで、最終的なSQL生成を支援する追加の構文解析が提供される。(2) 部分問題の分解問題の複雑さと難易度を軽減するために、ユーザー問題をサブ問題に分解し、これらの問題を解いてサブSQLを生成することで、最終的なSQLクエリを導きます。
ディンエスキューエル[DIN-SQLはまず、ユーザー問題とターゲットデータベース間のスキーマリンクを生成する。続くモジュールは、ユーザー問題を関連するサブ問題に分解し、難易度を分類する。上記の情報に基づいてSQL生成モジュールが対応するSQLを生成し、自己修正モジュールが予測されたSQLの潜在的なエラーを特定し修正する。Coder-Reviewer[56]フレームワークは、命令を生成するCoderモデルと、命令の尤度を評価するReviewerモデルを組み合わせた並べ替えアプローチを提案している。
Chain-of-Thought[103]とLeast-to-Mostヒント[104]を参照すると、次のようになる。Qデコンプ[51]は問題分解キューを導入した。このキューは最後から最 後までのキューから問題削減フェーズに続き、LLMに中間推論ステップとし て元の複雑な問題の分解を実行するよう指示する。
C3 [これらのコンポーネントはChatGPTに異なるタスクを割り当てることで実装されます。まず、明快さのヒントコンポーネントが明快さのヒントとしてスキーマリンクと洗練された質問関連スキーマを生成します。次に、テキストからSQLへのヒントに関する複数ラウンドの対話が校正バイアスヒントとして使用され、これが明瞭ヒントと組み合わされてSQL生成をガイドします。生成されたSQLクエリは一貫性と実行ベースの投票によってフィルタリングされ、最終的なSQLが得られる。
マックエスキューエル[57]はマルチエージェント協調フレームワークを提案した。テキストからSQLへの変換処理は、セレクタ、デコンポーザ、リファイナーといったエージェントの協調によって行われる。セレクタはユーザの問題に関連するテーブルを保持し、デコンポーザはユーザの問題をサブ問題に分割して解決策を提供し、最後にリファイナーは欠陥のあるSQLを検証して最適化する。
DEA- SQL [58]は、LLMベースのtext-to-SQLの注意力と問題解決範囲を分解によって改善することを目的としたワークフローパラダイムを導入している。このアプローチは、SQL生成モジュールが対応する前提条件(情報決定、問題分類)と後続(自己修正、能動学習)のサブタスクを持つように、タスク全体を分解する。このワークフローパラダイムにより、LLMはより正確なSQLクエリを生成することができる。
エスジーユーエスキューエル [32 ]は構造からSQLへのフレームワークであり、SQL生成を支援するために固有の構造情報を使用します。具体的には、このフレームワークはユーザの質問と対応するデータベースのグラフ構造をそれぞれ構築し、次に符号化されたグラフを使用して構造リンクを構築する[105 , 106]。メタオペレータはシンタックスツリーを使用してユーザの問題を分解するために使用され、最後にSQLのメタオペレータは入力プロンプトを設計するために使用される。
メタエスキューエル [59 ]は、SQL生成のための3段階のアプローチ(分解、生成、ソート)を紹介している。分解フェーズでは、意味分解とメタデータを組み合わせて、ユーザの問題に対処する。以前に処理されたデータを入力として、メタデータの条件から生成されたテキストからSQLへのモデルを用いて、いくつかのSQLクエリの候補が生成される。最後に、大域的な最適SQLクエリを得るために、2段階のソートパイプラインが適用される。
ペットSQL [60 ]は手がかりを強化した2段階のフレームワークを提示している。まず、適切に設計されたヒントがLLMに予備SQL(PreSQL)の生成を指示し、類似性に基づいていくつかの小さなデモが選択される。次に、スキーマリンクがPreSQLに基づいて発見され、LLMに最終SQL(FinSQL)の生成を促すために組み合わされる。最後に、FinSQL は複数の LLM を使用して生成され、実行結果に基づく一貫性が確保される。
C2-プロンプト最適化LLMをキューイングするための数分学習は広く研究されている[85]。LLMベースのテキストからSQL(text-to-SQL)およびコンテキストの学習では、些細な数分法が有望な結果をもたらしており[8, 9, 33]、数分ヒンティングのさらなる最適化により、性能が向上する可能性がある。既製のLLMでSQLを生成する精度は、対応する入力ヒントの品質に大きく依存するため[107]、ヒントの品質に影響する多くの決定要因が現在の研究の焦点となっている[9](例:オリゴヒントの組織の質と量、ユーザ9の問題とオリゴヒントのインスタンスの類似性、外部の知識/ヒント)。
デゼム [62 ]は、意味除去およびスケルトン検索を備えたキューエンジニアリングフレームワークである。このフレームワークはまず、ドメイン固有のワードマスキングモジュールを採用し、ユーザーの質問の意図を保持する意味的トークンを削除する。次に、調整可能なヒンティングモジュールを利用して、質問と同じ意図を持つ少数の例を検索し、これをパターン関連性フィルタリングと組み合わせて、LLMのSQL生成をガイドする。
Qデコンプ [このフレームワークでは、分解された部分問題を関連する表と列の名前でインクリメンタルに結合する InterCOL メカニズムが導入されている。難易度に基づく選択を通じて、QDecompの少数の例が難易度についてサンプリングされる。類似度多様性サンプリングに加えて、[ 52 ]はSD+SA+投票(類似度多様性+パターン拡張+投票)サンプリング戦略を提案した。彼らはまず、意味的類似性とk-Meansクラスタリングの多様性を用いて少数の例をサンプリングし、次にパターン知識を用いて手がかりを補強する(意味的補強または構造的補強)。
C3 30]のフレームワークは、質問とスキーマをLLMへの入力とするクリアヒントコンポーネントと、ヒントを提供するキャリブレーションコンポーネントから構成され、ユーザの質問と関係のない冗長な情報を除去したスキーマとスキーマリンクを含むクリアヒントを生成する。LLMはその構成をSQL生成のためのコンテキスト拡張ヒントとして使用する。検索強化フレームワークは、サンプルを意識したヒント[64]を導入し、元の問題を単純化し、単純化された問題から問題のスケルトンを抽出し、スケルトンの類似性に基づいてリポジトリ内のサンプル検索を完了する。検索されたサンプルは、少数のヒントに対して元の問題と組み合わされる。
オーディス [54]は、領域外のプレゼンテーションと領域内の合成デー タを使用したサンプル選択を導入しており、これは、キューの特徴 付けを強化するために、混合ソースから少数のプレゼンテーションを検索 する。
DAIL- SQL[DAIL Selectionは、まずユーザのドメイン固有の語彙と少数の例題をマスクし、次に埋め込みユークリッド距離に基づいて候補例題をランク付けする。同時に、事前に予測されたSQLクエリ間の類似度が計算される。最後に、選択機構は事前に定義された基準に基づいて類似度によってソートされた候補例を得る。このアプローチにより、少数の例が問題とSQLクエリの両方と良い類似性を持つことが保証される。
アクトエスキューエル[49]は、類似性スコアに基づく選択の動的な例を提示した。
FUSED[FUSEDのパイプラインは、クラスタリングによって融合するプレゼンテーションをサンプリングし、サンプリングされたプレゼンテーションを融合してプレゼンテーションのプールを構築することで、少数ショット学習の有効性を向上させる。
知識からSQLへ [31] このフレームワークは、SQL生成のための知識を提供するデータエキスパートLLM(DELLM)を構築することを目的としている。
デルム DELLMは4種類の知識を生成し、よく設計された手法(DAIL-SQL [9]、MAC-SQL [57 ]など)は文脈学習によってLLMベースのtext-to-SQLのパフォーマンスを向上させるために、生成された知識を組み込んでいる。
C3-推論の強化:LLMは常識的推論、記号的推論、算術的推論を含むタスクで優れた能力を示しています[108]。テキストからSQLへのタスクでは、数値推論や同義語推論が現実的なシナリオでしばしば登場します[33 , 41 ]。LLMを使った推論のためのヒント戦略は、SQL生成を改善する可能性を秘めています。最近の研究では、テキストからSQLへの適応のための適切に設計された推論強化手法の統合、高度な推論3 を必要とする複雑な問題の課題に対処するためのLLMの改善、SQL生成における自己整合性に焦点が当てられています。
Chain-of-Thoughts (CoT) ヒンティング技法[103]は、LLMを的確な推論に導き、LLMの推論能力を刺激する包括的な推論プロセスから構成される。LLMのテキストからSQLをベースとした研究では、CoTヒントをルールヒントとして利用し[9]、ヒントの構成に「ステップバイステップで考えよう」という指示を設定している[9, 32, 33, 51]。しかし、テキストからSQLへのタスクのためのストレートな(原始的な)CoT戦略は、他の推論タスクのための可能性を示していない; CoTの適応に関する研究はまだ進行中である[51]。CoTのヒントは常に手動注釈付きの静的な例を用いて実証されるため、手動注釈が不可欠な少数の例を効果的に選択するためには経験的な判断が必要となります。
解決策として。アクトエスキューエル [49]はCoT例を自動的に生成する方法を提案している。具体的には、ACT-SQLは問題が与えられると、問題のスライスのセットを切り捨て、対応するSQLクエリに現れる各カラムを列挙する。各列は類似性関数により最も関連性の高いスライスと関連付けられ、CoTヒントに付加される。
Qデコンプ [51]CoTヒントと連携してLLMのSQL生成を強化する体系的な研究を通じて、CoTがSQLクエリを予測するための推論ステップをどのように提案するかという課題に対処するための新しいフレームワークが提案された。このフレームワークは、CoT推論の論理ステップを構築するためにSQLクエリの各フラグメントを使用し、次に自然言語テンプレートを使用してSQLクエリの各フラグメントを精緻化し、論理的な実行順序に並べる。
最少から最多まで [104 ]はもう一つのヒンティング手法で、問題を部分問題に分割し、それらを逐次的に解くものです。反復的なヒントとして、パイロット実験[51]では、この手法はテキストからSQLへの構文解析には必要ないことが示唆されています。詳細な推論ステップを使用すると、より多くのエラー伝播問題が発生する傾向があります。
CoTのバリエーションとして思考プログラム(PoT)LLMの算術推論を強化するために、ヒンティング戦略[109]が提案されている。
55]を評価すると、PoTは特に複雑なデータセット[33]において、SQLが生成するLLMを強化する。
SQL-CRAFT [PoT戦略は、モデルがPythonコードとSQLクエリの両方を生成することを要求し、推論プロセスにPythonコードを組み込むことを強制する。
自己一貫性[110]は、LLM推論を改善するためのヒンティング戦略であり、複雑な推論問題では通常、一意に正しい答えを導き出すために複数の異なる考え方が可能であるという直観を利用する。テキストからSQLを作成するタスクでは、自己無撞着性は、異なるSQLのセットをサンプリングし、実行フィードバックを通じて一貫性のあるSQLに投票することに適用される[30 , 53 ]。
同様に。SD+SA+投票 [52] このフレームワークは、決定論的データベース管理システム(DBMS)によって特定された実行エラーを拒否し、過半数の票を獲得した予測を選択する。
加えて、LLMの機能を拡張するツールの使用に関する最近の研究に後押しされた。不況 [66]は、適切に設計されたツールを効率的に呼び出すことによって、LLMのためのSQL生成を強化することを提案している。
C4-実行リファインメント正確なSQL生成のための標準を設計する場合、常に優先されるのは、生成されたSQLが正常に実行され、ユーザの質問に正しく答えるための内容を取り出すことができるかどうかです[13]。複雑なプログラミングタスクであるため、正しいSQLを一度に生成することは非常に困難です。直感的には、SQL生成中に実行のフィードバックや結果を考慮することは、対応するデータベース環境と整合させるのに役立ち、その結果、LLMは生成されたSQLを改良するか多数決を取るために潜在的な実行エラーや結果を収集することができます[30]。Text-to-SQLの実行を考慮したアプローチでは、主に2つの方法で実行フィードバックを組み込んでいます:
1) 第2ラウンドのプロンプトでフィードバックを再作成する最初の応答で生成された各 SQL クエリについて、適切なデータベースで実行され、データベースからフィードバックが返される。このフィードバックはエラーであったり、2回目のプロンプトに追加される結果であったりする。このフィードバックを文脈に沿って学習することで、LLMは元のSQLを改良または再生成し、精度を向上させることができる。
2) 生成SQLに実行ベースの選択ポリシーを使用するLLMから生成された複数のSQLクエリをサンプリングし、データベース内で各クエリを実行する。各SQLクエリの実行結果に基づいて、選択戦略(自己無撞着、多数決[60]など)を用いて、SQLセットから条件を満たすSQLクエリを最終的な予測SQLとして定義する。
MRC-EXEC [67]は、サンプリングされた各SQLクエリをランク付けし、ベイズリスク[111]に基づいて最小の実行結果を持つ例を選択する実行を伴う自然言語コード変換フレームワーク(NL2Code)を提案した。レバー [68]は、NL2Codeを実行によって検証する方法を提案している。生成モジュールと実行モジュールを用いて、それぞれSQLセットとその実行結果のサンプルを収集し、学習検証器を用いて正しさの確率を出力する。
同じようなことだ。セルフデバッグ [このフレームワークはまた、LLMが予測したSQLを少数のデモでデバッグすることも教えている。モデルは、実行結果を調査し、生成されたSQLを自然言語で解釈することで、人間の介入なしにエラーを修正することができる。
前述したように、よく設計されたフレームワークと実施へのフィードバックを組み合わせるために、2段階のインプリケーションが多用された:1.SQLクエリのセットをサンプリングする。 2.多数決(自己一貫性)。具体的にはC3[30] このフレームワークはエラーを排除し、最も一貫性のあるSQLを特定する;検索機能強化フレームワーク[64]は、動的なリビジョンチェーンを導入している。LLMは意味的なギャップを特定し、生成されたSQLを修正するよう求められました。スキーマフィルタリング手法はSQL生成を強化しますが、生成されたSQLは実行できない可能性があります。DIN-SQL[8]は自己修正モジュールにジェネリックヒントとジェントルヒントを考案した。ジェネリックヒントはLLMにエラーを特定し修正することを要求し、ジェントルヒントはモデルに潜在的な問題をチェックすることを要求する。
マルチエージェントフレームワークマックエスキューエル[57]には、SQLエラーを検出して自動的に修正する洗練化エージェントが含まれており、SQLiteのエラー・クラスと例外クラスを使用して修正されたSQLを再生成する。SQL-CRAFT [55]このフレームワークは、過補正や過少補正を避けるために、対話型キャリブレーションと判定プロセスの自動制御を導入している。 不況 [66]は、SQL生成のためのツールベースの推論におけるエラー・フィードバックを考察している。 知識からSQLへ [31]は、提案されたDELLMを改善するために、データベース実行フィードバックと直接プリファレンス最適化[112]を組み合わせたプリファレンス学習フレームワークを導入した。ペットSQL[1)プレーン投票:複数のLLMにSQLクエリを生成させ、異なる実行結果に基づいて多数決で最終SQLを決定する。
B. 微調整
教師あり微調整(SFT)は、LLMを訓練するための支配的なアプローチであるため[29, 91]、オープンソースのLLM(例えば、LLaMA-2[94 ]、Gemma[113])では、モデルを特定のドメインに迅速に適応させる最も簡単な方法は、収集したドメインラベルを使用してモデルに対してSFTを実行することである。SFTフェーズは、通常、よく設計された訓練フレームワーク[112, 114]の初期フェーズであり、テキストからSQLへの微調整フェーズである。114]と同様に、テキストからSQLへの微調整フェーズである。SQLクエリYの自動回帰生成プロセスは以下のように定式化できる:

SFT アプローチはテキスト-to-SQL のための架空の微調整手法でもあり、テキスト-to-SQL 研究において様々なオープンソース LLM によって広く採用されています[9, 10 , 46 ]。ファインチューニングパラダイムは、文脈学習(ICL)アプローチよりもLLMベースのtext-to-SQL開始点を好みます。より良いファインチューニング手法を探求する研究がいくつか発表されている。よく設計された微調整手法は、表IVに示すように、そのメカニズムに従って異なるグループに分類される:
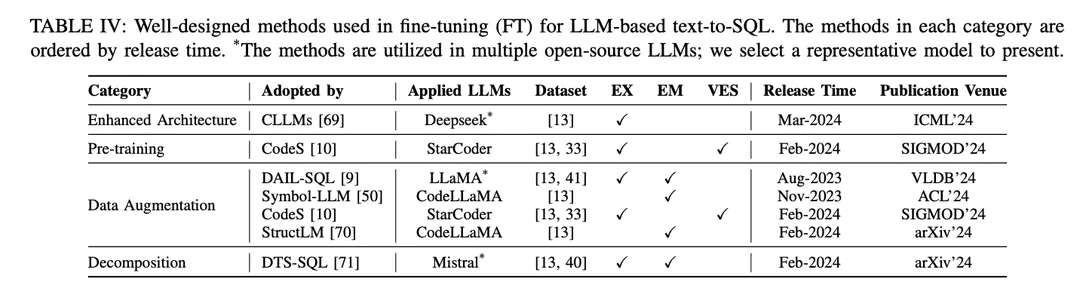
強化されたアーキテクチャGPTフレームワークは、デコーダのみのトランスフォーマアーキテクチャと、テキストを生成するための伝統的な自己回帰的デエンコーディングを利用している。LLMの効率に関する最近の研究では、自己回帰パターンを使用して長いシーケンスを生成する際に注意メカニズムを組み込む必要があるため、LLMの待ち時間が長いという共通の課題が明らかになっている[115 , 116 ]。LLMベースのtext-to-SQLでは、SQLクエリの生成は従来の言語モデリング [21 , 28 ]と比較して著しく遅く、効率的なローカルNLIDBを構築する上での課題となる。その解決策の一つとして、CLLM [ 69 ]は上記の課題を解決し、強化されたモデル・アーキテクチャによってSQL生成の高速化を目指している。
データ強化ファインチューニング・プロセスにおいて、モデルの性能に最も直接的な影響を与える要因は、トレーニング・ラベルの品質である[117]。低品質またはトレーニングラベルの欠如によるファインチューニングは「間違いない」ものであり、高品質または増強されたデータによるファインチューニングは、低品質または未加工データに対するよく設計されたファインチューニング手法よりも常に優れている[29, 74]。テキストからSQLへのデータエンハンスド・ファインチューニングでは、SFTプロセスにおけるデータ品質の向上に重点を置き、大きな進展があった。
[117] "Learning from noisy labels with deep neural networks: a survey", "ディープ・ニューラル・ネットワークによるノイズの多いラベルからの学習:サーベイ".[74]テキストからSQLへの最近の進歩:私たちが持っているものと私たちが期待しているものの調査[29] "大規模言語モデルのサーベイ"DAIL-SQL[9]は、より少ないサンプルインスタンスでより良い結果を得るためにサンプリング戦略を利用するコンテキスト学習フレームワークとして設計されている。Symbol-LLM[50]は、注入フェーズと注入フェーズに調整されたデータ増強命令を提案する。CodeS[10]は、ChatGPTの助けを借りて双方向生成により学習データを強化する。StructLM[70]は、全体的な能力を向上させるために複数の構造知識タスクで学習される。
事前トレーニング事前学習は、全体の微調整プロセスの基本的な段階であり、大量のデー タに対する自動回帰学習によってテキスト生成能力を得ることを目的としている [118]。伝統的に、現在の強力なプロプライエタリLLM(ChatGPT [119]、GPT-4 [86]、Claude [120]など)は、主にテキスト生成能力を表示する対話シナリオから恩恵を受けるハイブリッドコーパスで事前訓練される[85]。コードに特化したLLM(例えば、CodeLLaMA [ 121 ]、StarCoder [ 122 ])は、コードデータで事前学習され[100 ]、様々なプログラミング言語の混合により、LLMはユーザーの指示に適合するコードを生成することができる[123 ]。コード生成のサブタスクとしてSQLを対象とした事前学習技術の主な課題は、SQL/データベース関連のコンテンツが事前学習されたコーパス全体のごく一部に過ぎないことである。
その結果、(ChatGPTやGPT-4と比較して)合成機能が比較的限定的なオープンソースのLLMは、事前学習中にNL問題をSQLに変換する方法をよく理解していない。CodeS [10]モデルの事前学習フェーズは、3段階のインクリメンタルな事前学習から構成される。基本的なコード固有のLLM [122 ]から始まり、CodeSは混合学習コーパス(SQL関連データ、NL-to-Codeデータ、NL関連データを含む)に対して漸進的な事前学習を行う。その結果、Text-to-SQLの理解度と性能が大幅に向上した。
分解IV-A章で紹介したICLパラダイムが示すように、タスクを複数のステップに分解したり、複数のモデルを使ってタスクを解決したりすることは、複雑なシナリオを解決するための直感的なソリューションである。ICLベースのアプローチで使用されるプロプライエタリなモデルは、ファインチューニングアプローチで使用されるオープンソースのモデルとはパラメータレベルが異なり、多数のパラメータを持つ。これらのモデルは本来、(少ないサンプル数で学習するなどのメカニズムにより)割り当てられたサブタスクをうまく実行する能力がある[30, 57]。したがって、このパラダイムの成功を ICL アプローチで再現するためには、オープンソースモデルに適切なサブタスク(外部知識の生成、スキーマのリンク、スキーマの洗練など)を合理的に割り当てて、特定のサブタスクの微調整を行い、微調整に使用する適切なデータを構築して最終的な SQL の生成を支援することが重要です。
DTS-SQL [71]は、テキストからSQLへの微調整フレームワークの2段階分解を提案し、最終的なSQL生成の前にスキーマリンク12の事前生成タスクを設計する。
謀る
Text-to-SQL の研究は大きく進展していますが、まだいくつかの課題が残っています。本節では、今後の研究で克服されることが期待される残された課題について議論します。
A. 実用的なアプリケーションにおけるロバスト性
LLMによって実装されたText-to-SQLは、実際の複雑なアプリケーションシナリオにおける汎用性と頑健性が期待できます。最近、頑健性に特化したデータセット[ 37 , 41]が大幅に進歩したにもかかわらず、その性能は実世界のアプリケーションにはまだ十分ではありません[ 33]。今後の研究で克服すべき課題はまだいくつかある。ユーザー側から見ると、ユーザーは必ずしも明確な質問者ではないという現象がある。つまり、ユーザーの質問は正確なデータベース値を持たないかもしれないし、同義語、スペルミス、あいまいな表現が含まれる可能性があり、標準的なデータセットとは異なるかもしれない[40]。
例えば、fine-tuningパラダイムでは、モデルは具体的な表現で明示的に指示された問題で学習される。モデルは実世界の問題と対応するデータベースとの対応付けを学習しないため、実世界のシナリオに適用する際には知識のギャップが生じる[33]。同義語と不完全な命令を持つデータセット[7 , 51]の対応する評価で報告されているように、ChatGPTによって生成されたSQLクエリは、10%低い10%の不正実行を含む。同時に、SQLデータセットへのネイティブテキストを使ったファインチューニングは、標準化されていないサンプルやラベルを含む可能性があります。例えば、テーブルやカラムの名前が必ずしもその内容を正確に表しているとは限らないため、学習データの構築に矛盾が生じる。
B. 計算効率
計算効率は推論の速度と計算資源のコストによって決定され、これはアプリケーションと研究努力の両方において考慮する価値があります[49, 69]。最新の text-to-SQL ベンチマーク[15, 33]におけるデータベースの複雑化に伴い、データベースはより多くの情報(より多くのテーブルとカラムを含む)を運ぶようになり、データベーススキーマのトークン長もそれに応じて長くなり、多くの課題を提示することになります。超複雑なデータベースを扱う場合、対応するスキーマを入力として使用すると、独自のLLMを呼び出すコストが大幅に増加し、特にコンテキスト長が短いオープンソースのモデルを実装する場合、モデルの最大トークン長を超える可能性があるという課題に遭遇する可能性があります。
一方、もう1つの明らかな課題は、ほとんどの研究がモデル入力として完全なパターンを使用していることであり、これは大量の冗長性をもたらす[57]。コストと冗長性を削減するために、問題に関連する正確なフィルタリングされたパターンをユーザー側から直接LLMに提供することは、計算効率を向上させる潜在的な解決策である[30]。正確なパターンフィルタリング法を設計することは、依然として将来の方向性である。コンテキスト学習パラダイムは有望な精度を達成しているが、うまく設計された多段フレームワークや拡張コンテキストメソッドは、API呼び出しの回数を増やし、計算効率の観点からは性能を向上させるが、コストの大幅な増加にもつながる[8]。
関連するアプローチ[49]では、性能と計算効率のトレードオフを注意深く考慮する必要があり、より低いアプリケーション・プログラミング・インターフェース・コストで同等の(あるいはそれ以上の)コンテキスト学習アプローチを設計することは、現在も検討されている実用的な実装であろう。PLMベースのアプローチと比較して、LLMベースのアプローチは推論が著しく遅い[21, 28]。入力の長さを短くし、実装プロセスのステージ数を減らすことによって推論を高速化することは、文脈学習パラダイムにとって直感的である。ローカルLLMについては、出発点[69]から、将来の探索でモデルのアーキテクチャを強化するために、より多くの高速化戦略を調査することができる。
この課題に対処するために、LLMを意図的なバイアスに調整し、ノイズの多いシナリオに対応する訓練戦略を設計することは、最近の進歩に有益であろう。一方、実世界のアプリケーションのデータ量は、研究ベースのベンチマークに比べて相対的に少ない。手作業によるアノテーションによって大量のデータをスケーリングするには高い人件費がかかるため、より多くの質問とSQLのペアを得るためのデータ拡張方法を設計することで、データが乏しい場合のLLMをサポートすることができる。さらに、小規模データセットでの局所適応研究のためにオープンソースのLLMを微調整することは有益である可能性がある。さらに、多言語[ 42 , 124 ]およびマルチモーダルシナリオ[ 125 ]のための拡張は、今後の研究で包括的に調査されるべきであり、より多くの言語コミュニティに利益をもたらし、より一般的なデータベースインターフェイスの構築に役立つであろう。
C. データのプライバシーと解釈可能性
LLM研究の一部として、LLMベースのtext-to-SQLもLLM研究に存在するいくつかの一般的な課題に直面しています[4 , 126 , 127 ]。テキスト-to-SQLの観点からは、これらの課題はLLM研究に大きな利益をもたらす潜在的な改善にもつながります。IV-A章で前述したように、文脈学習パラダイムは量的にも性能的にも最近の研究を支配しており、ほとんどの研究は独自のモデルを用いて実装されている[8, 9]。ローカル・データベースの機密性を処理するために独自のAPIを呼び出すことは、データ漏洩のリスクをもたらす可能性があるため、データ・プライバシーの観点から直接的な課題が提起されている。ローカルのファインチューニング・パラダイムを使用することで、この問題に部分的に対処することができる。
それにもかかわらず、バニラ微調整の性能は現在のところ最適とは言えず[9]、高度な微調整フレームワークはデータ増強のために独自のLLMに依存している可能性があります[10]。このような現状を踏まえると、text-to-SQLのローカル微調整パラダイムにおいて、よりカスタマイズされたフレームワークが広く注目されるに値する。全体として、ディープラーニングの開発は、解釈可能性という点で常に課題に直面している[127 , 128 ]。
長年の課題として、この問題を解決するために多くの研究が行われてきました[ 129 , 130 ]。しかし、LLMベースの実装の解釈可能性については、文脈学習や微調整パラダイムのいずれにおいても、text-to-SQL研究ではまだ議論されていません。分解段階を持つアプローチは、段階的生成の観点からテキストからSQLへの実装を説明します[8, 51]。これに基づいて、解釈可能性[131, 132]の先進的な研究を組み合わせてtext-to-SQLの性能を向上させ、データベースの知識という観点から局所的なモデルアーキテクチャを説明することは、将来の方向性として残っています。
D. 拡張
LLMと自然言語理解研究のサブフィールドとして、これらの分野の研究の多くは、text-to-SQLタスク[103 , 110 ]の使用によって促進されてきました。しかし、text-to-SQLの研究は、これらの分野のより広範な研究に拡張することもできます。例えば、SQL生成はコード生成の一部です。うまく設計されたコード生成手法は、text-to-SQLにおいても良好な性能を達成することができ[48, 68]、幅広いプログラミング言語にわたって一般化することができます。いくつかのカスタマイズされたtext-to-SQLフレームワークをNL-to-code研究に拡張する可能性についても議論することができる。
例えば、NL-to-codeにおいて実行出力を統合するフレームワークは、SQL生成においても優れた性能を達成している[8]。text-to-SQLにおける実行を意識したアプローチを、他の先進モジュール[30, 31]を用いてコード生成に拡張する試みは、議論する価値がある。別の観点から、text-to-SQLは、事実情報を提供することにより、LLMベースの質問応答(QA)を強化することができると以前に議論されました。データベースは関係知識を構造情報として格納することができ、構造ベースのQAはテキスト-to-SQLから恩恵を受ける可能性があります(例えば、知識ベースの質問応答、KBQA [ 133 , 134 ])。データベース構造を利用して事実知識を構築し、それをテキスト-to-SQL システムと組み合わせて情報検索を可能にすることは、より正確な事実知識を得るための更なる QA を支援する可能性を秘めている[ 135 ]。今後の研究において、より拡張されたテキストからSQLへの研究が行われることが期待される。
OlaChatデジタル・インテリジェンス・アシスタント製品紹介

OlaChatデジタルインテリジェンスアシスタントは、テンセントのPCGビッグデータプラットフォーム部門がデータ分析分野のビッグモデルを着地実務に応用して発表した新しいインテリジェントデータ分析製品で、DataTalk、OlaIDEなどテンセント社内の主流データプラットフォームに統合され、データ分析シナリオの全プロセスをインテリジェントにサポートする。OlaChatは、text2sql、指標分析、SQLインテリジェント最適化などの一連の機能を備えており、データ分析(ドラッグ&ドロップ分析、SQLクエリ)、データ可視化、結果の解釈と帰属に至るまで、データ分析作業の簡素化と効率化を総合的に支援する!
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事



コメントはありません