
VTP - MiniMaxコンク・ビデオ・チームのオープンソース視覚的生成モデリング技術

VTPとは?
VTP(Visual Tokenizer Pre-training)は、MiniMax Conch Videoチームが提唱するビジュアル生成モデルのキーテクノロジーで、ビジュアル・トークナイザー(トークナイザー)の事前学習方法を改善することで、生成システムのパフォーマンスを向上させます。従来の手法では、トークナイザーは画像の再構成にのみ焦点を当てていたが、VTPは革新的に意味理解能力を生成品質のコアドライバーとして導入している。このフレームワークはVision Transformerアーキテクチャを採用し、2段階の学習戦略(表現学習を最適化するための事前学習段階と、画質を向上させるための微調整段階)とマルチタスク目的(再構成、自己監視、図形比較)を通じて、初めてトークナイザーのスケールアップ、すなわち計算能力とデータ量が増加したときに生成効果が同時に向上することを実現した。実験によると、VTPは同じ計算予算で従来のVAEを大幅に上回り、拡散モデルやマルチモーダル・マクロモデルにより効率的な視覚的ペデスタルを提供する。
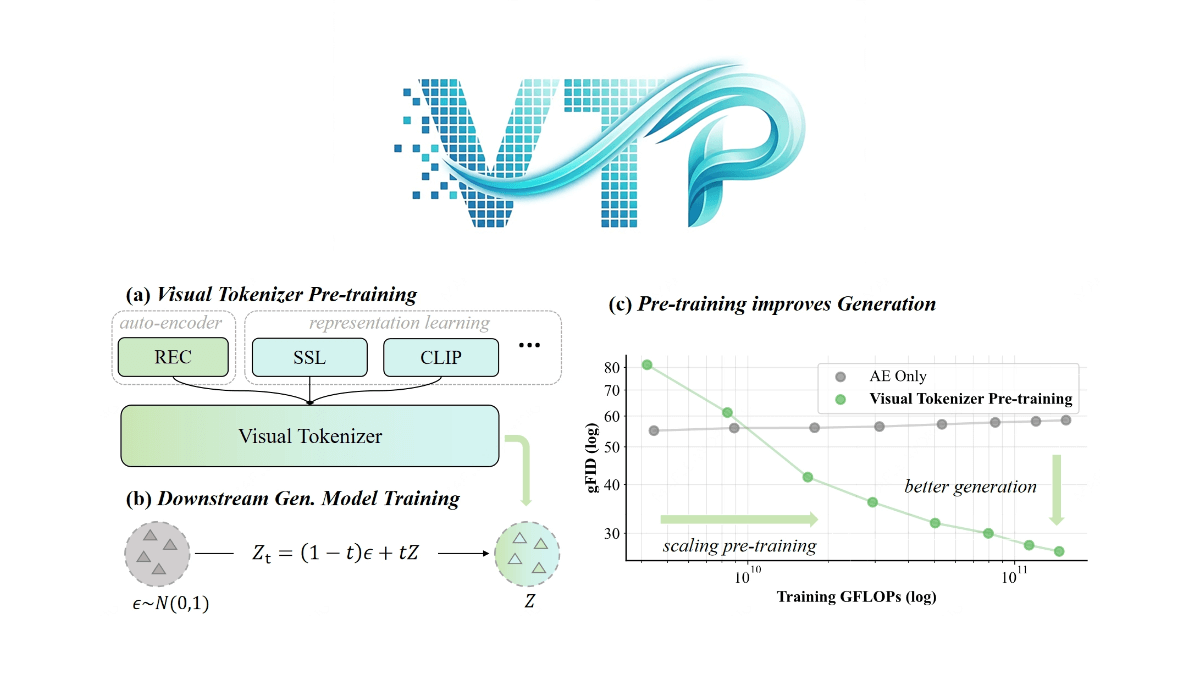
VTPの特徴
- マルチタスク協調最適化VTPは、画像-テキストコントラスト学習、自己教師付き学習(例えば、自己蒸留やマスク画像モデリング)、およびモデルの意味理解と空間知覚を向上させるためのピクセルレベルの再構成目標を組み合わせることにより、共同マルチタスク学習を可能にする。
- 効率的なスケーラビリティVTPは優れたスケーラビリティを示し、その生成性能は学習計算量(FLOPs)、モデルパラメータ、データセットサイズが増加するにつれて着実に向上し、大規模な事前学習における従来の自己符号化器の性能ボトルネックを打破します。
- 優れた発電性能VTPは、ImageNetにおいて、ゼロサンプル分類精度78.21 TP3T、rFID 0.36を達成し、他の手法を大幅に上回り、事前学習計算量を増やすだけで生成の質を大幅に改善できる、下流の生成タスクで優れた性能を発揮する。
- 高速コンバージェンスVTPは事前学習段階から再設計され、蒸留ベースモデルに基づく手法と比較して、高い上限性能と4.1倍の収束速度を達成し、学習効率を大幅に向上させた。
- オープンソースと使いやすさVTPは、研究者や開発者がすぐに使い始め、実際のプロジェクトに適用できるように、事前に訓練された重みやクイックスタート・スクリプトのダウンロードを含む、詳細なインストールと使用に関するガイドラインを提供しています。
VTPの主な利点
- マルチタスク学習の統合VTPは、画像とテキストのコントラスト学習、自己教師付き学習、ピクセルレベルの再構成目標を統合し、マルチタスクの協調最適化により、意味理解と生成能力を大幅に向上させる。
- 強力なスケーラビリティVTPは事前学習段階で優れたスケーラビリティを発揮し、計算量、モデルパラメータ、データセットサイズの増加とともに生成性能が着実に向上し、従来のセルフエンコーダの限界を打ち破る。
- 優れた発電品質VTPは、ImageNetなどのベンチマークにおいて、ゼロサンプルの分類精度78.21 TP3T、rFID 0.36を達成し、生成品質の点で他の手法を大きく上回り、下流の生成タスクで良好なパフォーマンスを発揮します。
- 迅速なコンバージェンス能力VTPは事前学習段階から再設計され、従来の手法に比べて高い上限性能と4.1倍の収束速度を達成し、学習効率を大幅に向上させた。
- オープンソースと使いやすさVTPは、詳細なインストールガイドと事前トレーニング用ウェイトを提供するため、ユーザーはすぐに使い始め、実際のプロジェクトに適用することができ、使用への敷居を低くすることができます。
- 革新的な事前トレーニングパラダイムVTPは、マルチタスク学習によって生成能力を向上させ、視覚生成の分野に新しいアイデアと手法を提供する、視覚曖昧性解消器のための新しい事前学習パラダイムを提案する。
VTPの公式ウェブサイトは?
- GitHubリポジトリ:: https://github.com/MiniMax-AI/VTP
- HuggingFaceモデルライブラリ:: https://huggingface.co/collections/MiniMaxAI/vtp
- arXivテクニカルペーパー:: https://arxiv.org/pdf/2512.13687v1
VTPが適応となる人
- ディープラーニング研究者視覚的生成モデリングに興味を持ち、生成の質と意味理解を向上させるための新しい事前学習法を探求したい研究者に、VTPは新しい技術的フレームワークと実験的アイデアを提供する。
- コンピューター・ビジョン・エンジニア高品質の画像生成アプリケーション(画像生成、ビデオ生成など)に取り組むエンジニアは、VTPの効率的なスケーラビリティと優れた性能により、生成タスクを迅速に実装し、最適化することができます。
- 自然言語処理(NLP)エキスパートクロスモーダル学習とマルチモーダル融合に重点を置く研究者であるVTPは、画像とテキストのコントラスト学習などの技術を通じて、視覚と言語の共同モデリングのための新しい視点とツールを提供している。
- 機械学習開発者VTPのオープンソースコードと詳細なユーザーガイドは、使用への障壁を下げ、プロジェクトへの迅速な統合を促進します。
- 学術研究者VTPは、人工知能、コンピュータビジョン、自然言語処理に関連する分野の学術研究者に対し、新たな研究の方向性と実験プラットフォームを提供し、関連分野の学術的進歩を促進します。
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事



コメントはありません