Voxtral - Mistral AIによるオープンソース音声モデル

ヴォクストラルとは?
ヴォクストラル、そうだ。 ミストラルAI Voxtralは最先端のオープンソース音声モデルであり、強力な音声転写と理解機能を通じて、人間とコンピュータの自然な相互作用の進歩をサポートします。Voxtralは多言語対応で、自動的に言語を検出し、最大30分の音声トランスクリプションと40分の音声理解を処理することができます。VoxtralはQ&Aと要約機能を内蔵しており、追加の言語モデルを必要とせずに構造化されたコンテンツを生成することができ、音声対話の効率とコストを最適化するためにバックエンドの機能呼び出しを直接トリガーすることができます。Voxtralは音声認識と自然言語理解にディープラーニング技術を組み合わせており、会議録音、顧客サービス、コンテンツ作成、教育、インテリジェントアシスタントなどの分野で広く使用することができ、音声対話の普及に貢献します。会議録音、顧客サービス、コンテンツ作成、教育、インテリジェントアシスタントなどの分野で広く使用され、音声対話の普及に貢献しています。
Voxtralの主な特徴
- 長いオーディオ処理能力最大30分の音声トランスクリプションと最大40分の詳細な理解に対応。
- スマートなQ&Aとまとめ音声コンテンツへの直接質問をサポートし、音声認識や言語モデリング支援を追加することなく、明確な構造化要約を生成します。
- 多言語自動認識多くの主要言語(英語、フランス語、スペイン語など)をサポートし、異なる地域のユーザーのニーズを満たすために自動的に言語を検出することができます。
- ボイス・コマンド・トリガーAPIの最新バージョンは、音声コマンドに基づいてバックエンド機能やAPIコールを直接トリガーできるもので、操作プロセスを簡素化し、対話効率を向上させる。
- テキストの理解と処理テキスト入力と処理をサポートする強力なテキスト理解力。
- 効率的な転写性能大規模なアプリケーションに最適化されたトランスクリプションサービスを低コストで提供します。
ヴォクストラルの公式ホームページアドレス
- プロジェクトのウェブサイト:: https://mistral.ai/news/voxtral
- HuggingFaceモデルライブラリ::
- https://huggingface.co/mistralai/Voxtral-Small-24B-2507
- https://huggingface.co/mistralai/Voxtral-Mini-3B-2507
ヴォクストラルの使い方
- 公式ウェブサイトを見るVoxtralのプロジェクトウェブサイトとHuggingFaceモデルライブラリをご覧ください。
- 正しいバージョンを選ぶ::
- Voxtral-Small-24B-2507生産規模に適しており、性能が向上している。
- ヴォクストラル-ミニ3B-2507ローカル展開に適しており、リソースをあまり必要としない。
- 依存関係のインストールPythonと必要な依存関係があなたの環境にインストールされていることを確認してください。
transformers歌で応えるtorch.使用する次のコマンドでインストールします。::
pip install transformers torch- 積載モデルハギング・フェイスの
transformersライブラリーはVoxtralモデルをロードする:
from transformers import AutoModelForSpeechSeq2Seq, AutoProcessor
model_name = "mistralai/Voxtral-Small-24B-2507" # 或者 "mistralai/Voxtral-Mini-3B-2507"
model = AutoModelForSpeechSeq2Seq.from_pretrained(model_name)
processor = AutoProcessor.from_pretrained(model_name)- オーディオデータの準備オーディオファイル形式がサポートされている形式(例:WAV、MP3など)であることを確認してください。
- 音声を書き起こしたもの:Voxtralモデルによる音声転写:
from transformers import pipeline
# 创建一个语音转录 pipeline
transcriber = pipeline("automatic-speech-recognition", model=model_name)
# 转录音频文件
transcription = transcriber("path/to/your/audio/file.wav")
print(transcription)Voxtralの核となる強み
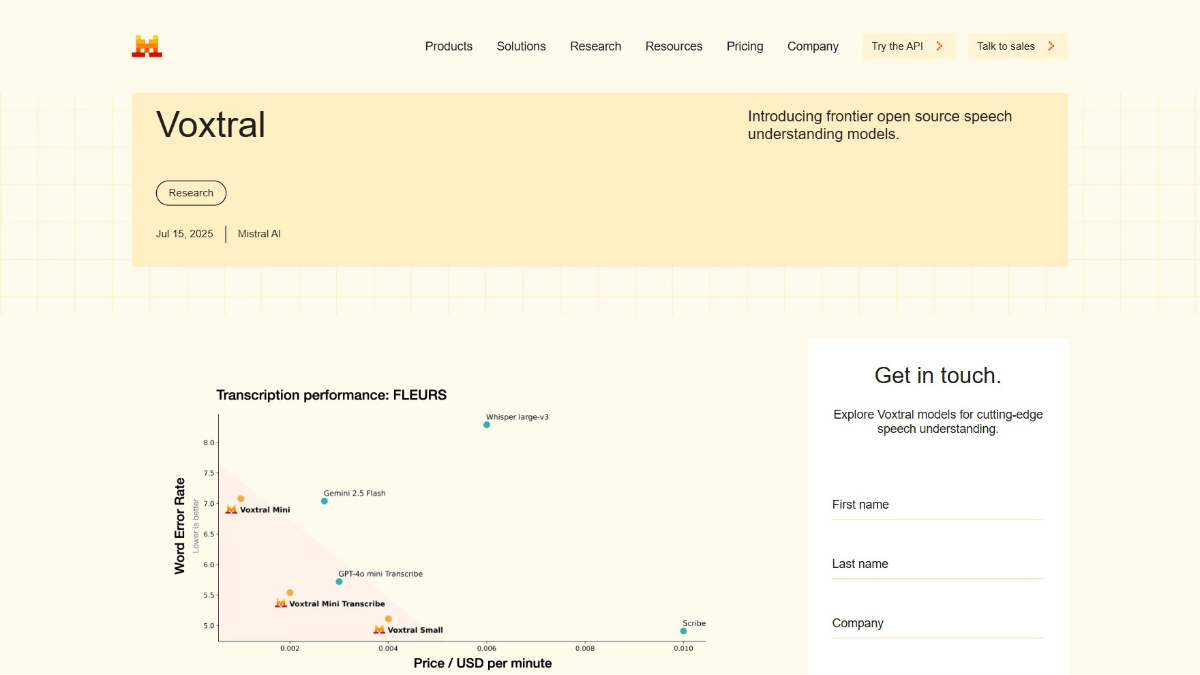
- パワフルな音声処理最大30分の音声書き起こし、最大40分の詳細な理解をサポートし、複雑な長文コンテンツにも高い書き起こし精度で対応します。
- 多言語サポート世界中のユーザーのニーズに応えるため、手動で切り替えることなく、複数の言語(英語、スペイン語、フランス語など)を自動的に検出します。
- 効率的な対話能力Q&A機能と要約機能を内蔵し、バックエンド機能の呼び出しを直接トリガーすることで、操作プロセスを簡素化し、対話の効率を向上させます。
- パフォーマンスとコストの最適化費用対効果が高く、大規模なアプリケーションに適しており、利用障壁が低い高性能なトランスクリプション・サービスを提供する。
- 柔軟な展開オプション本番用には24B、ローカル用には3Bがあり、簡単に統合できる。
- 理解の深さ音声認識と自然言語理解と組み合わせることで、エラー率を低減。
Voxtralの対象者
- ビジネスユーザー顧客サービスチームと会議記録担当者は Voxtral を使用して、サービス効率と会議要約を向上させています。
- 教育者教師はコースの内容を書き起こし、リアルタイムのQ&Aを提供することで、授業の双方向性を高める。
- コンテンツクリエータージャーナリスト、ポッドキャスト制作者、ビデオ制作者がコンテンツを効率的に書き起こし、クリエイティブな生産性を向上させます。
- 技術開発者Voxtral をプロジェクトに統合し、音声対話アプリケーションを開発します。
- 研究員Voxtralで音声データを処理し、言語とデータ分析研究を強化。
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事



コメントはありません