Voice-Pro: オープンソースの多機能ビデオ翻訳ツール、多言語への音声書き起こしおよび翻訳、Windowsワンクリックインストール

はじめに
Voice-Proは、Gradio WebUIをベースにした多機能ツールで、音声合成、テキスト読み上げ、リアルタイム翻訳、YouTubeビデオダウンロード、人声分離をサポートします。Whisper、Faster-Whisper、Whisper-Timestamped技術を統合し、多言語・多シナリオに対応した効率的な音声処理と翻訳を提供します。


機能一覧
- 音声テキストWhisper、Faster-Whisper、Whisper-Timestampedに対応し、高精度な音声認識を実現。
- 音声合成Edge-TTSとF5-TTSをサポートし、複数の言語と音声を選択でき、スピード、音量、ピッチの調整も可能。
- リアルタイム翻訳リアルタイムの音声認識と多言語翻訳をサポートします。
- YouTubeダウンロードYouTubeの動画をダウンロードしたり、音声(mp3、wav、flac)を抽出することができます。
- 声の分離MDX-NetエンジンとDemucsエンジンを使用したボーカルと背景音の分離。
- バッチファイル大容量ファイルの字幕生成、翻訳、音声合成をサポート。
- サブタイトル・ジェネレーション90以上の言語の字幕生成と編集に対応。
- マルチフォーマット対応ffmpegがサポートするすべてのビデオおよびオーディオフォーマットに対応しています。
ヘルプの使用
設置プロセス
- スターターパックGitHubから最新バージョンのソースコードをクローンまたはダウンロードする。
git clone https://github.com/abus-aikorea/voice-pro.git
- プログラムのインストールと実行::
- うごきだす
configure.bat必要な依存関係(git、ffmpeg、CUDAなど)をインストールします。 - うごきだす
start.batVoice-Proを起動すると、WebUIが自動的に実行されます。 - 最初にVoice-Proを起動すると、まずインストールが始まりますが、これには1時間以上かかる場合があります。
- うごきだす
使用機能
- 音声テキスト::
- スタジオタブで ウィスパー モデルと計算の種類。
- オーディオファイルをアップロードするか、オーディオ入力ソース(マイクなど)を選択します。
- 開始」ボタンをクリックし、音声認識と字幕作成が完了するのを待ちます。
- レンダリング::
- 翻訳タブに翻訳するテキストまたは字幕ファイルをアップロードします。
- ターゲット言語を選択し、"翻訳 "ボタンをクリックします。
- 翻訳が完了したら、翻訳されたファイルをダウンロードすることができます。
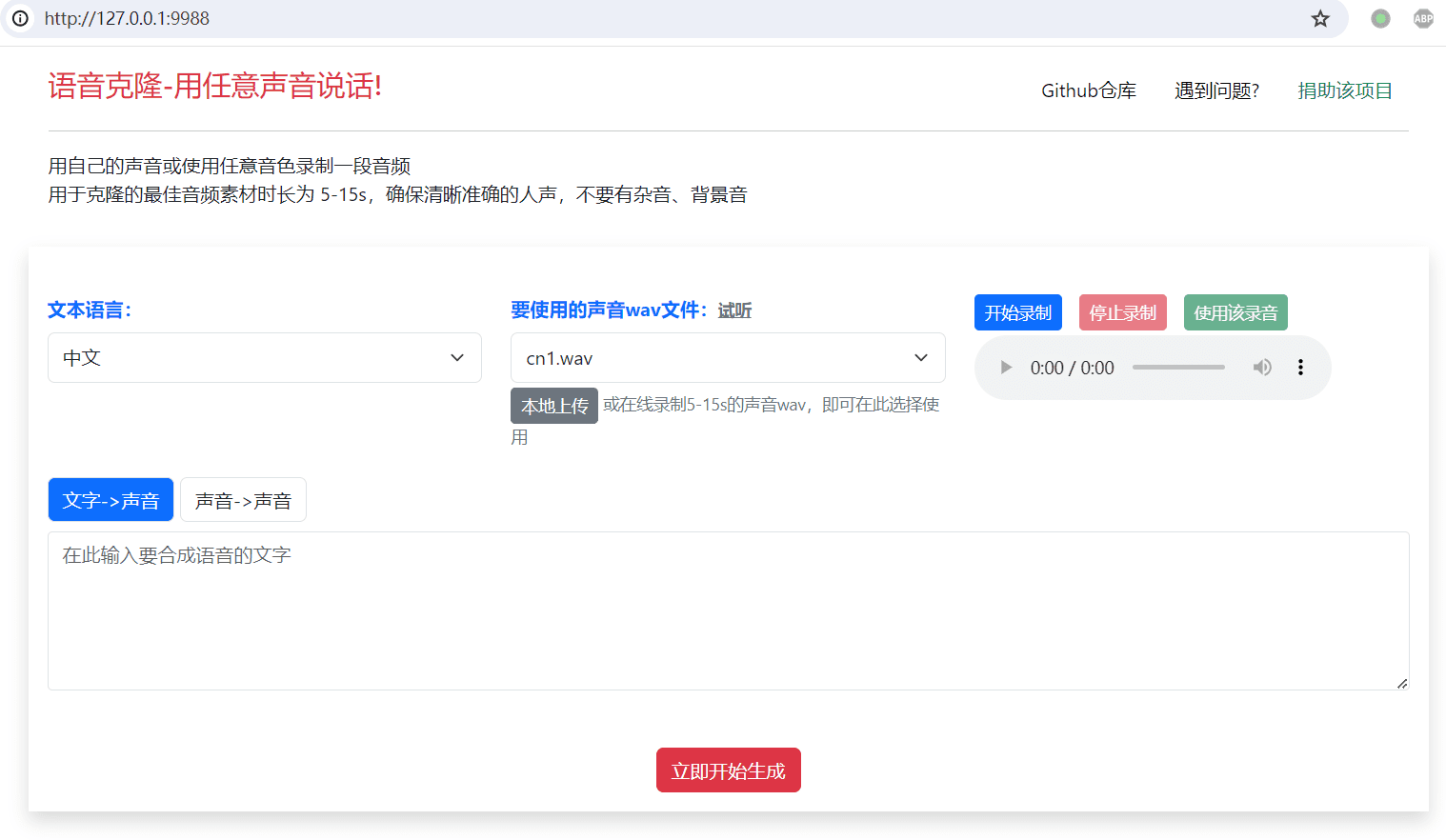
- 音声合成::
- TTSタブでEdge-TTSまたはF5-TTSを選択します。
- 変換するテキストを入力し、音声パラメータ(速度、音量、ピッチなど)を選択します。
- Generate Voice "ボタンをクリックし、音声生成が完了するまで待つ。
- YouTubeダウンロード::
- YouTube DownloaderタブにYouTubeビデオのリンクを入力します。
- オーディオフォーマット(mp3、wav、flac)を選択し、「ダウンロード」ボタンをクリックします。
- ダウンロードが完了したら、指定したフォルダにオーディオファイルがあります。
- サウンドセパレーション::
- Vocal Removerタブでオーディオファイルをアップロードします。
- MDX-Net または Demucs エンジンを選択し、[Start] ボタンをクリックします。
- 音の分離が完了するまで待つと、分離されたオーディオファイルをダウンロードできます。
- バッチファイル::
- バッチタブで複数のファイルをアップロードします。
- 希望する操作(字幕、翻訳、音声合成)を選択する。
- Start "ボタンをクリックし、バッチ処理が完了するのを待つ。
一般的な問題
- ブラウザが自動的に起動しないWindowsのコマンドウィンドウを閉じ、再度実行する。
start.batまたは、ブラウザ(例:http://127.0.0.1:7892)に表示されたアドレスを手動で入力してください。 - CUDA メモリ不足エラーGPUメモリの状態を確認し、ノイズ低減レベルや計算タイプを調整します。
- Windows Defenderの警告バッチファイルを例外として追加するか、Windows Defenderを一時的に無効にします。
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事

コメントはありません