VikingDB - Volcano Engineの高性能クラウドネイティブベクターデータベース

VikingDBとは
VikingDBは、Volcano Engineが提供する高性能なクラウドネイティブベクトルデータベースで、膨大な高次元ベクトルデータを扱うように設計されています。VikingDBは、リアルタイム同期書き込み、非同期書き込みなど、複数のデータ書き込み方法を備えており、さまざまなシナリオのニーズに対応します。VikingDBは、HNSWやIVFなどの独自開発の高効率インデックス作成アルゴリズムに基づいており、数百億のベクトルをミリ秒で検索でき、密なベクトル検索と疎なベクトル検索に対応しています。VikingDBはSaaSコンソール、多言語のAPIとSDKを提供し、自動弾性拡張をサポートし、ストレージコストを効果的に削減することができます。VikingDBはマルチモーダル検索、インテリジェント推薦、RAGシナリオ、メモリ構築の分野で広く使用されており、企業が効率的なデータ管理とインテリジェントなアプリケーション開発を達成するのに役立ちます。
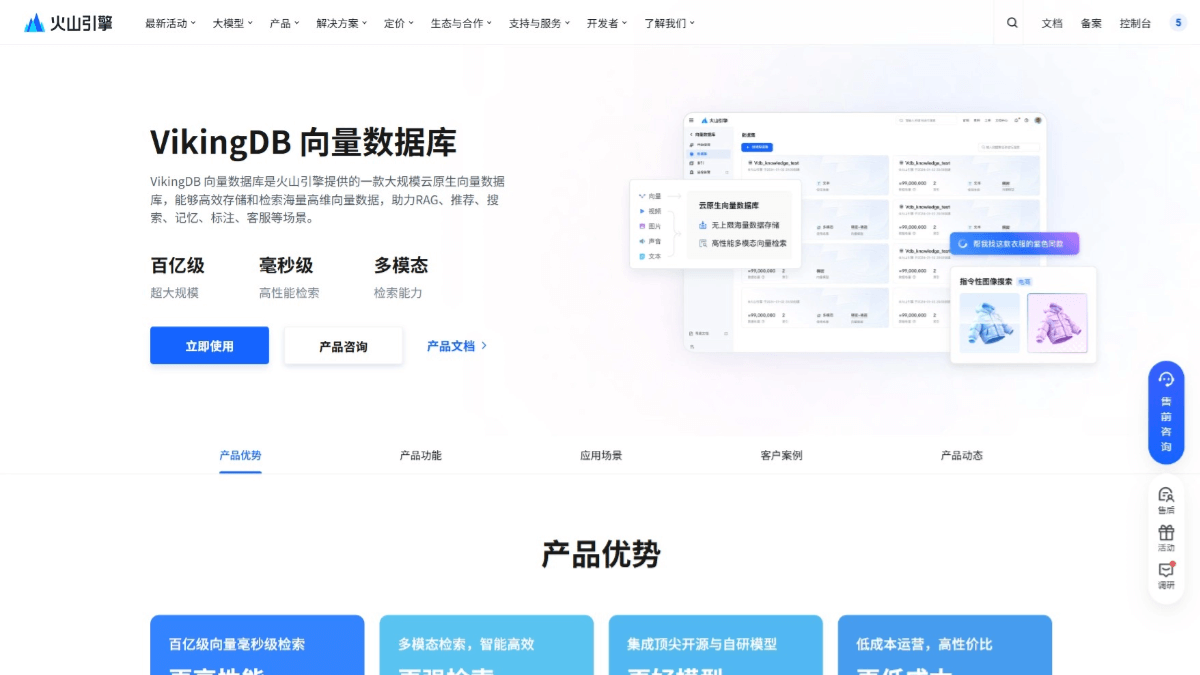
VikingDBの主な特徴
- 柔軟なデータ書き込みリアルタイム同期、非同期、単一データ書き込み、バッチ書き込みなど、さまざまなビジネスシナリオのニーズに対応する複数の書き込み方法を提供する。
- 効率的なインデックス作成とリアルタイム更新インデックス作成アルゴリズムは、HNSW、IVF、およびその他の高度なインデックス作成アルゴリズムに基づいており、ストリーミング更新アーキテクチャと組み合わせることで、高負荷下でもデータを迅速に更新し、リアルタイムの検索を保証します。
- 強力な検索機能ベクトル、スカラー、混合、マルチモーダルなデータ検索をサポートし、複雑なクエリ要件に対応するため、数百億のベクトルデータでミリ秒検索を達成することができます。
- エラスティックでスケーラブルなクラウドサービスSaaSコンソール、APIインターフェース、SDKを多言語で提供し、自動的な弾力的拡張をサポートし、ユーザーがデータ検索プロセスを迅速に構築・管理することを容易にする。
- 高性能とコストの最適化深く最適化されたインデックス作成アルゴリズムと定量化技術により、極めて高い検索効率を達成すると同時に、ストレージコストを削減し、大規模データシナリオにおける費用対効果を保証します。
- 知識ベースとメモリー機能複雑な意味検索と大規模モデルの長期記憶保存をサポートし、知的アシスタント、教育、指導など、パーソナライズされたインタラクションシナリオに適しています。
バイキングDB公式サイトアドレス
- 公式ウェブサイトアドレス:: https://www.volcengine.com/product/VikingDB
VikingDBの使い方
- 登録とログインボルケーノ・エンジンの公式サイトにアクセスし、アカウント登録を済ませ、ログインしてVikingDBコンソールにアクセスします。
- インスタンスの作成コンソールで VikingDB インスタンスを作成し、必要に応じて名前、ストレージ容量、パフォーマンス仕様などのパラメータを設定します。
- データの準備とベクトル化処理するデータを整理し、エンベッディング・モデルを使用する。 ドウバオ またはその他のオープンソースモデル)をベクター形式に変換する。
- SDKへのアクセスVikingDBが提供するSDK(Python, Java, Goなど)をインストールして初期化し、作成したデータベースインスタンスに接続します。
- データを書き込むSDKに基づき、ベクターデータをVikingDBに書き込みます。リアルタイム同期、非同期、その他の書き込み方法から選択できます。
- 取り出すSDKを使用して、ベクトル、スカラー、またはハイブリッド検索を実行し、最も類似した結果を得ます。
- モニタリングと最適化コンソールでインスタンスのパフォーマンス・メトリクスを監視し、実際の使用状況に基づいてパフォーマンスとコストを最適化するように設定を調整します。
VikingDBの主な利点
- 高性能検索独自に開発した効率的なインデックス作成アルゴリズム(HNSW、IVFなど)に基づき、数百億のベクトルに対してミリ秒単位の検索を実現し、検索レイテンシは10msと低く、クエリの効率を大幅に向上させる。
- 多様性データのサポート密なベクトルや疎なベクトルの検索をサポートし、ベクトル、スカラー、混合、マルチモーダルデータの検索に対応し、幅広い複雑なデータタイプやシナリオに適用できる。
- 柔軟なデータ書き込みリアルタイム同期書き込み、非同期書き込み、単一データ書き込み、バッチ書き込みを提供し、さまざまなビジネスシナリオにおけるデータ書き込み要件を満たし、データ処理の柔軟性と効率性を確保します。
- 弾力性と拡張性クラウドネイティブデータベースとして、SaaSコンソール、API、SDKを多言語で提供し、自動的な弾力的拡張をサポートし、データ量やクエリの負荷に応じて動的にリソースを調整することで、システムの安定性と効率性を確保します。
- 低コストのストレージ最適化されたインデックス作成アルゴリズムと定量化技術により、ストレージコストを削減し、価格/パフォーマンスを向上させながら、高いパフォーマンスを実現します。
- 知識ベースとメモリー機能インテリジェントアシスタント、教育、ロールプレイングなどのパーソナライズされたインタラクションシナリオに適用可能な、大規模モデルの複雑な意味検索と長期記憶保存を提供し、大規模モデルの効率的な検索と記憶管理をサポートします。
VikingDBの対象者
- 人工知能・機械学習エンジニア大規模ベクトルデータの処理・検索を必要とするエンジニアのための、モデル学習、特徴検索、マルチモーダルデータ処理を支援する効率的なツール。
- データサイエンティストデータ分析およびマイニングの際、多様な検索機能と柔軟なデータライティングは、データ科学者がモデルを迅速に検証し、複雑なデータを処理するのに役立ちます。
- コーポレート・テクニカル・チームVikingDBの高いパフォーマンスと弾力的なスケーラビリティは、インテリジェントなレコメンデーションシステム、マルチモーダル検索プラットフォーム、ナレッジベースの構築を必要とする組織のビジネス成長と技術ニーズをサポートします。
- システムアーキテクトシステム・アーキテクチャの設計を担当するアーキテクト向けに、既存のテクノロジー・スタックにシームレスに適合する、高性能でスケーラブル、かつ統合が容易なソリューションを提供します。
- 開発者VikingDBは、開発者が効率的なデータ管理とアプリケーション開発のためにVikingDBに素早くアクセスして使用できるように、多言語のSDKと詳細なドキュメントを提供します。
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事


コメントはありません