V-JEPA 2 - Meta AIによる世界最強の大型モデル

V-JEPA 2とは
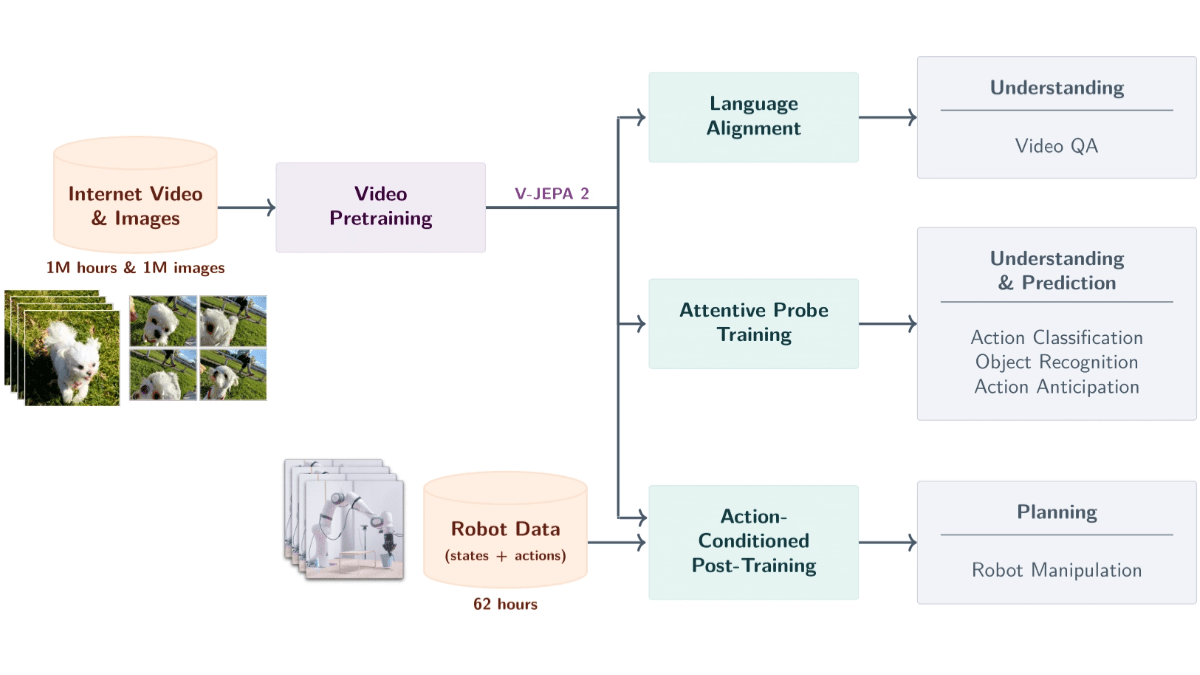
V-JEPA 2 はい メタAI 12億のパラメータを持つビデオデータに基づく世界規模のモデルを発表。このモデルは、100万時間を超える動画と100万枚の画像から自己教師付き学習に基づいて学習され、物理世界における物体、行動、動作を理解し、将来の状態を予測する。このモデルは、エンコーダ-予測アーキテクチャを使用し、行動条件予測と組み合わせることで、ゼロサンプルロボット計画をサポートし、ロボットが新しい環境でタスクを完了できるようにします。V-JEPA 2は、行動認識、予測、ビデオQ&Aなどのタスクに優れており、ロボット制御、インテリジェント監視、教育、ヘルスケアに強力な技術サポートを提供し、高度な機械知能への重要な一歩となる。
V-JEPA 2の主な特徴
- ビデオの意味解析映像から物体、行動、動作を認識し、シーンに関する意味情報を正確に抽出する。
- 将来の出来事の予測現在の状態や行動から、将来の映像フレームや行動結果を予測。
- ロボットゼロのサンプル計画新しい環境におけるロボットのタスク計画(物体の把持や操作など)を、学習データを追加することなく、予測能力に基づいて行う。
- ビデオ質疑応答言語モデルを組み合わせて、ビデオの内容に関連した質問に答える。
- シーンを超えた一般化また、ゼロサンプル学習や新しいシーンへの適応もサポートしています。
V-JEPA 2の公式サイトアドレス
- プロジェクトのウェブサイト::https://ai.meta.com/blog/v-jepa-2
- GitHubリポジトリ::https://github.com/facebookresearch/vjepa2
- 技術論文::https://scontent-lax3-2.xx.fbcdn.net/v/t39.2365-6
V-JEPA 2の使い方
- モデル・リソースへのアクセスGitHubリポジトリから学習済みモデルファイルと関連コードをダウンロードしてください。モデルファイルは.pthまたは.ckpt形式で提供されます。
- 開発環境のセットアップ::
- PythonのインストールPythonがインストールされていることを確認する(Python 3.8以上を推奨)。
- 依存ライブラリのインストールプロジェクトが必要とする依存関係をインストールするには、pipを使用します。通常、プロジェクトはrequirements.txtファイルを提供し、以下のコマンドに基づいて依存関係をインストールします:
pip install -r requirements.txt- ディープラーニング・フレームワークの導入V-JEPA 2はPyTorchをベースにしており、PyTorchのインストールが必要です。お使いのシステムとGPの設定によっては、PyTorchのウェブサイトからインストールコマンドを入手できます。
- 積載モデル::
- 訓練済みモデルの読み込みPyTorchで学習済みモデルファイルを読み込む。
import torch
from vjepa2.model import VJEPA2 # 假设模型类名为 VJEPA2
# 加载模型
model = VJEPA2()
model.load_state_dict(torch.load("path/to/model.pth"))
model.eval() # 设置为评估模式- データ入力の準備::
- ビデオデータの前処理V-JEPA 2は、入力としてビデオデータを必要とする。ビデオデータは、モデルが必要とする形式(通常はテンソル)に変換される。以下は簡単な前処理の例である:
from torchvision import transforms
from PIL import Image
import cv2
# 定义视频帧的预处理
transform = transforms.Compose([
transforms.Resize((224, 224)), # 调整帧大小
transforms.ToTensor(), # 转换为张量
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # 标准化
])
# 读取视频帧
cap = cv2.VideoCapture("path/to/video.mp4")
frames = []
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break
frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
frame = Image.fromarray(frame)
frame = transform(frame)
frames.append(frame)
cap.release()
# 将帧堆叠为一个张量
video_tensor = torch.stack(frames, dim=0).unsqueeze(0) # 添加批次维度- モデルによる予測::
- 実施見通し前処理されたビデオデータをモデルに入力し、予測結果を得ます。以下はサンプルコードです:
with torch.no_grad(): # 禁用梯度计算
predictions = model(video_tensor)- 予測結果の解析と適用::
- 予測結果の分析タスクの要求に従ってモデルの出力を解析する。
- 実際のシナリオへの適用ロボット制御、ビデオクイズ、異常検知などの実世界タスクに予測を適用する。
V-JEPA 2の主な利点
- 物理的世界への強い理解V-JEPA 2は、ビデオ入力に基づいて物体の動作や動きを正確に認識し、シーンに関する意味情報を取得し、複雑なタスクの基本的なサポートを提供します。
- 効率的な未来状態予測このモデルは、現在の状態と行動に基づいて、将来のビデオフレームや行動の結果を予測することができ、短期的な予測と長期的な予測の両方をサポートし、ロボットのプランニングやインテリジェントなモニタリングなどのアプリケーションを後押しします。
- ゼロサンプル学習と汎化能力V-JEPA 2は、未知の環境や物体に対して優れた性能を発揮し、ゼロサンプル学習と適応をサポートし、新しいタスクを完了するために追加の学習データを必要としない。
- 言語モデリングと組み合わせたビデオQ&A機能V-JEPA 2は、言語モデルと組み合わせることで、物理的な因果関係やシーンの理解など、映像コンテンツに関する質問に答えることができ、教育や医療などの分野での応用が広がります。
- 自己教師付き学習に基づく効率的なトレーニング人手によるラベル付けを行うことなく、自己教師学習に基づいて大規模なビデオデータから汎用的な視覚表現を学習することで、コストを削減し、汎化を向上させる。
- 多段階トレーニングと運動状態の予測V-JEPA 2は、多段階学習により、エンコーダの事前学習と運動状態予測器の学習を行い、視覚情報と運動情報を組み合わせることで、高精度な予測制御をサポートします。
V-JEPA 2の対象者
- 人工知能研究者V-JEPA2の最先端技術による学術研究と技術革新で、機械知能化を推進する。
- ロボット工学エンジニア新しい環境や複雑なタスクに適応するロボットシステムを、モデルゼロサンプル計画機能を用いて開発する。
- コンピュータ・ビジョン開発者インテリジェント・セキュリティ、産業オートメーション、その他の分野で使用されるV-JEPA 2で、ビデオ解析の効率を高めます。
- 自然言語処理(NLP)エキスパート視覚的モデリングと言語的モデリングを組み合わせて、バーチャルアシスタントやインテリジェントカスタマーサービスのようなインテリジェントインタラクションシステムを開発する。
- 教育者ビデオクイズ機能をベースとした没入型教育ツールを開発し、教育・学習効果を高める。
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事


コメントはありません