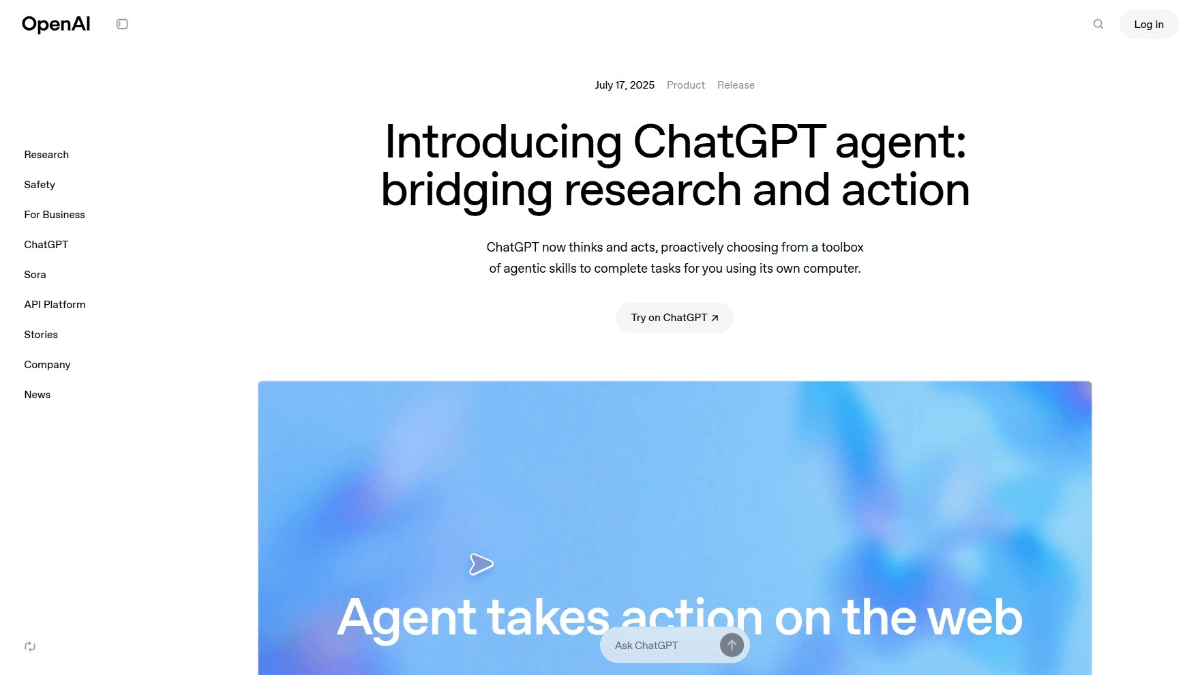
UnDatas.IO: さまざまな種類の非構造化データを正確に解析するAPIサービス(有料)

はじめに
UnDatas.IOは、非構造化データの解析と処理に特化したプラットフォームです。高度な技術を駆使して、ドキュメントのレイアウトを自動的に認識し、表、画像、数式、テキストを分類することで、データ処理プロセスを大幅に簡素化します。このプラットフォームは、データ整理の時間を大幅に節約するだけでなく、ユーザーがデータから貴重な洞察を引き出し、より戦略的な意思決定を行うのを支援します。UnDatas.IOは、学術研究、ビジネス分析、技術開発のための強力なデータサポートを提供します。
機能一覧
- 文書レイアウトの自動認識
- 表、画像、数式、テキストを分類する
- データの抽出と変換
- 複数のデータ形式をサポート
- 大規模言語モデルとの統合によるデータ処理能力の向上
- 開発者の便宜のためにAPIインターフェイスを提供する
ヘルプの使用
設置プロセス
- UnDatas.IOの公式サイトで登録し、APIキーを取得してください。
- UnDatas.IO Python APIライブラリをインストールします:
pip install undatasio
- OpenAI Python SDK をインストールします:
pip install openai
- APIキーを保存するための環境変数を設定する:
import os
os.environ['UNDATASIO_API_KEY'] = 'your_api_key'
os.environ['OPENAI_API_KEY'] = 'your_openai_api_key'
使用プロセス
- UnDatas.IOライブラリをインポートし、初期化する:
from undatasio.undatasio import UnDatasIO
undatasio_obj = UnDatasIO(os.getenv('UNDATASIO_API_KEY'))
- 利用する
get_result_typeメソッドを使ってデータ型を抽出する:
result_type = undatasio_obj.get_result_type('your_document')
- 利用する
show_versionメソッドを使ってバージョン情報を見ることができる:
version_info = undatasio_obj.show_version()
主な機能
- 文書レイアウトの自動認識文書がアップロードされると、プラットフォームは自動的に文書内の表、画像、数式、テキストを認識し、分類します。
- データの抽出と変換必要なデータ形式は、APIインターフェースを通じて簡単に抽出・変換できます。
- 大規模言語モデルとの統合OpenAIの大規模言語モデルで、データ処理と分析機能を強化します。例えば、数学的な問題はQwen-maxモデルを使って解くことができます:
from openai import OpenAI
openai_obj = OpenAI(os.getenv('OPENAI_API_KEY'))
response = openai_obj.Completion.create(
model="qwen2.5-math-72b-instruct",
prompt="Solve the following math problem: ...",
max_tokens=100
)
print(response.choices[0].text)
詳しい操作手順
- データアップロード: UnDatas.IOのアップロードインターフェイスを使って、解析対象のドキュメントをUnDatas.IOにアップロードします。
- データ分類このプラットフォームは、文書のさまざまな要素を自動的に認識し、分類して表示します。
- データ抽出API インターフェイスを使用して、必要なデータ型(表データ、画像データなど)を抽出します。
- データ変換必要に応じて、抽出されたデータを必要な形式に変換し、その後の分析や処理に使用する。
- データ分析プラットフォームが提供する分析ツールを使ってデータを分析し、価値ある洞察を引き出す。
- 結果出力分析結果をレポートや他のフォーマットにエクスポートし、簡単に共有・利用することができます。
以上の手順により、ユーザーは簡単にUnDatas.IOを使用して非構造化データの解析と処理を開始することができ、データ処理の効率を向上させ、時間と労力を節約することができます。
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事

コメントはありません