
Tongyi万向ビデオのアップグレード、VBenchのトップ、中国語生成のためのビデオサポート、レンズのテクスチャを完全に引っ張る

2025年は始まったばかりで、AIビデオ世代は技術的なブレークスルーを迎えようとしている?
今朝、アリの動画生成モデル「トンイワンフェーズ」がバージョン2.1への大幅アップグレードを発表した。
今回発表されたモデルには、以下の2つのバージョンがある。Tomix 2.1 ExtremeとProfessionalで、前者は高性能を、後者は高い表現力を目指している。.
紹介によると、同志万向は今回、モデルの全体的な性能を総合的にアップグレードし、特に複雑な動きの処理、実際の物理法則の復元、フィルムの質感の向上、従うべき命令の最適化において、AIの芸術的創造に新たな扉を開いたという。
ビデオジェネレーションの効果を垣間見、あなたを驚かせることができるかどうか見てみよう。
定番の "ステーキカット "を例にとってみよう。 ステーキの質感がはっきりとわかり、表面は薄い油膜で覆われキラキラと輝き、刃は筋繊維に沿ってゆっくりと切り込まれ、Q弾力のある、細部にまでこだわった肉になっているのがわかるだろう。 
P︓プロンプト:レストランで、男が熱々のステーキを切っている。クローズアップの俯瞰ショットで、男は右手に鋭利なナイフを持ち、ステーキの上にナイフを置いて、ステーキの中心に沿って切っている。人物の服装は黒、手には白いマニキュア、背景は白い皿に黄色い料理、茶色のテーブルのボケ。
少女の表情、手や体の動きは自然で、協調性があり、髪を吹き抜ける風も運動の法則に沿っている。

プロンプト:花の茂みの中に佇み、両手をハートに見立てているかわいらしい少女。彼女はピンクのドレスを着て、長い髪を風になびかせ、甘い微笑みを浮かべている。背景は花々が咲き乱れ、明るい日差しが差し込む春の庭。HDリアルフォト、クローズアップ、ソフトな自然光。
このモデルはもう1つスコアを走れるほど強いのか。現在、ビデオ世代レビューの決定版であるVBench LeaderboardではアップグレードされたTongyi Wanxiangは、合計スコア84.7%で、Gen3、Pika、CausVidといった国内外のビデオジェネレーションモデルを凌いでトップに立った。..ビデオジェネレーションの競争環境には、また新たな変化の波が押し寄せたようだ。
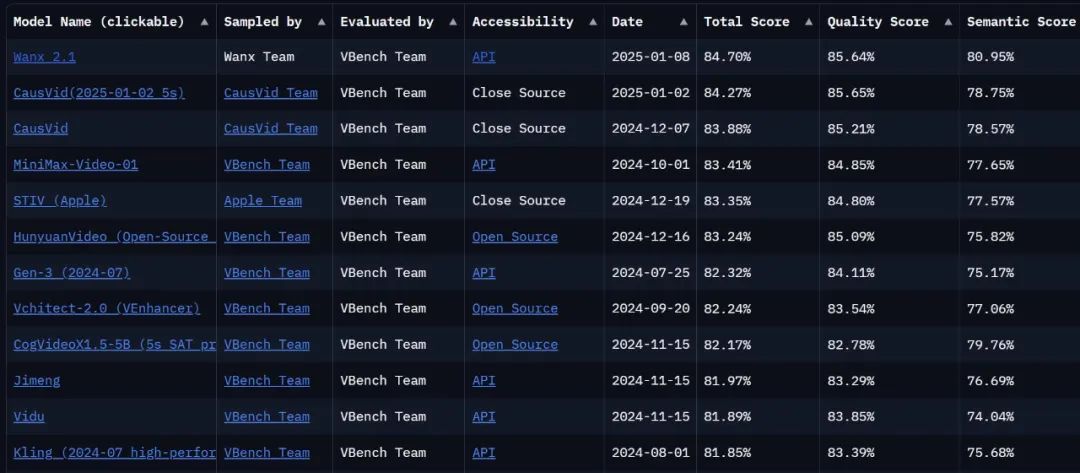
リストへのリンク:https://huggingface.co/spaces/Vchitect/VBench_Leaderboard
今後、ユーザーは同伊万象のウェブサイトで最新世代のモデルを利用できるようになる。同様に、開発者はAliCloud Bai LianのビッグモデルAPIを呼び出すこともできる。
公式ウェブサイトアドレス:https://tongyi.aliyun.com/wanxiang/
実体験表現力が増し、特殊効果フォントで遊べるようになった。
ここ最近、映像生成のための大型モデルのイテレーションが急速に進んでいるが、新バージョンの同伊万象は世代レベルの向上を達成したのだろうか?実際にテストしてみた。
AIビデオは書けるようになった。
第一に、AIが生成した動画は、ついに「ゴーストライティング」に別れを告げることができる。
これまで、市場で主流のAI動画生成モデルは、中国語と英語を正確に生成することができず、テキストがあるべき場所が判読不能なゴミの山になっていた。今、この業界の問題は同伊万向2.1によって解決された。
となった。中国語のテキストを生成し、英語と中国語の両方のテキスト効果をサポートする機能を備えた初のビデオ生成モデル。.
ユーザーは、短いテキスト説明を入力するだけで、映画のような効果を持つテキストとアニメーションを生成できるようになりました。
例えば、子猫がコンピューターの前でタイピングをしていると、画面に「仕事か食事か」という7つの大きな文字が飛び込んでくる。

Tongyi Wanxiangによって生成されたビデオでは、猫はワークステーションに座り、キーボードとマウスを真剣な態度で操作している。
そして、小さなオレンジ色の四角いボックスから飛び出す「Synced」という英語。

中国語であろうと英語であろうと、誤字脱字や "ゴースト・ライティング "は一切なく、トンイー・ワンシャンはそれを正確に伝える。
それだけでなく、以下のようなさまざまなシナリオでのフォントの適用もサポートしている。特殊効果フォント、ポスターフォント、実際のシナリオで表示されるフォントなどを含む。.
例えば、セーヌ河畔のエッフェル塔の近くでは、鮮やかな花火が空中に咲き誇り、カメラが近づくにつれ、ピンクの数字「2025」が徐々に大きくなり、フレーム全体を埋め尽くす。

精力的な動きはもはや "不気味 "ではない
複雑なキャラクターの動きは、かつてAIの動画生成モデルにとって「悪夢」であり、AIが生成した動画は手足が飛んだり、生きた人間に変化したり、「振り向くだけで首は回らない」という奇妙な動きを見せたりしていた。 
また、高度なアルゴリズムの最適化とデータトレーニングによって、同義ワンシャンは、特に大規模な四肢の動きと正確な四肢の回転という点で、さまざまなシナリオで安定した複雑なモーション生成を実現することができ、上の写真で生成されたブレイクダンスは非常にシルキーで滑らかだ。
そしてまた、下の生成されたビデオでは、男性の動きはスムーズで自然な走りであり、左右の足の区別がつかなかったり、ねじれたりするような問題はない。また、男性がつま先で地面に触れるたびに跡がつき、細かい砂がわずかに盛り上がるなど、細部にも細心の注意が払われている。

プロンプト:夕暮れのきらめく海に金色の陽光、浜辺を走るハンサムな若者、安定したトラッキングショット。
巨匠のようなミラーリング。
偉大なるスピルバーグ監督はかつて、優れた映画の秘密はカメラの言語にあると言った。見事な映画映像を生み出すために、撮影監督は空に上り、壁を飛び越えることを嫌う。 
しかし、AIが発達した現代では、映画を『作る』のはずっと簡単だ。
レンズは左、レンズは遠く、レンズは前など、簡単なテキストコマンドを入力するだけで、同義語は次のことができる。映像の主な内容とカメラのニーズに応じて、妥当な映像を自動的に出力する。.
プロンプトを入力:前庭で演奏するロックバンド、カメラが進むと、革ジャンに身を包み、乱れた長い髪をビートに合わせて揺らすギタリストに焦点が合う。ギタリストの指は弦を素早く飛び越え、バックの他のバンドは全力を尽くしている。

すべてお見通し 2.1 指示は厳密に守られたビデオはギタリストとドラマーが情熱的に演奏しているところから始まり、カメラがゆっくりと近づいてくると、背景がぼやけたりズームアウトしたりして、ギタリストの態度と手の動きが強調される。
長いテキストコマンドも迷子にならない
AIが生成するビデオを魅力的なものにするには、正確なテキストプロンプトが不可欠だ。
しかし、ビッグモデルのメモリには限りがあり、さまざまなシーンの切り替えやキャラクターの相互作用、複雑なアクションを含むテキストコマンドに直面すると、詳細を見失ったり、論理的な順序に混乱したりする傾向がある。
新しい『同伊曼祥』は、長い文章での指示に従うという点では大きな前進だ。
プロンプト:炎が激しく轟き、鮮やかなオレンジ色の光を放ち、瓦礫や金属片が宙を舞い、現場の混乱に拍車をかけている。ダークカラーのギアを身にまとい、前かがみになってハンドルを強く握るライダーは、集中した様子で猛スピードで突進し、背後で猛威を振るう炎にもめげなかった。爆発が残した濃い黒煙が空気を満たし、背景は終末的な混沌に包まれている。しかし、ライダーは容赦なく、正確で過激な撮影、超微細なディテール、没入感のある3D、首尾一貫したアクションで混沌を縫っていく。

上の長い文章では、狭い通り、明るい炎、充満する黒煙、飛び散る破片、暗い色の服を着たライダー......すべて同義満翔がとらえたディテールである。
また、同志旺祥は、コンセプトを組み合わせることで、さまざまな異なるアイデア、要素、スタイルを正確に理解し、それらを組み合わせてまったく新しい映像コンテンツを生み出す、より強力な能力を持っている。
スーツ姿の老人が卵から割れて、カメラの白髪の老人を目を見開いて見つめる映像は、雄鶏の鳴き声と相まって非常に愉快だ。

漫画油絵とその他のスタイルを専門とする。
新バージョンのTongyi Manphaseは、映画のようなビデオ画像も生成し、漫画、シネマカラー、3Dスタイル、油絵、クラシックスタイルなど、様々なアートスタイルをサポートしています。
このかわいい3Dアニメーションのモンスターが、ブドウの木の上に立って踊り回っているのをご覧ください。

プロンプト:ふわふわで幸せそうな小さな緑のティティ・モンスターが、つるの枝に立って楽しそうに歌っている。
さらに、1:1、3:4、4:3、16:9、9:16などの異なるアスペクト比をサポートしており、テレビ、コンピューター、携帯電話などの異なるエンド・デバイスによりよく適応することができる。 
上記のパフォーマンスから、私たちはすでに同義万聖を使って創造的な仕事をし、インスピレーションを「現実」に変えることができる。
もちろん、この一連の進歩は、AliCloudがビデオ生成の基本モデルをアップグレードしたことにも起因している。
ベースモデルを大幅に最適化構造、トレーニング、評価、そして全面的な「変革」。
昨年9月19日、AliCloudはYunqi ConferenceでTongyi Wanphase映像生成モデルを発表し、映画やテレビグレードのHD映像を生成する能力をもたらした。AliCloudの完全自社開発映像生成モデルとして、Diffusion + Diffusion + Diffusion + Diffusion + Diffusion + Diffusion + Diffusionを採用している。 変圧器 このアーキテクチャは、画像およびビデオ生成クラスのタスクをサポートし、モデルフレームワーク、トレーニングデータ、アノテーション方法、および製品設計における多くのイノベーションにより、業界をリードするビジュアル生成機能を提供します。
このアップグレードモデルでは、同伊萬祥チーム(以下、同チーム)はさらに次のようになる。自社開発の効率的なVAEおよびDiTアーキテクチャ時空間的な文脈関係をモデル化するために強化され、生成が大幅に最適化された。
Flow Matchingは、近年登場した生成モデル学習のためのフレームワークで、学習が簡単で、Continuous Normalising Flowにより拡散モデルと同等かそれ以上の品質を達成し、推論速度も速く、映像生成の分野にも徐々に適用されつつある。例えば、Meta社が以前リリースした映像モデル「Movie Gen」では、Flow Matchingが採用されている。
トレーニング方法の選択について、Tongyi Wanxiang 2.1は、以下のものを使用している。線形ノイズ軌道に基づくフロー・マッチング方式また、フレームワークの綿密な設計により、モデルの収束性、生成の質、効率が改善された。

同伊万向2.1ビデオ生成アーキテクチャ図
ビデオVAEについては、キャッシュ機構と因果的畳み込みを組み合わせた革新的なビデオコーデック方式を設計した。.また、因果畳み込みは、映像の時間的特徴を捉え、映像コンテンツの漸進的な変化に適応することができる。
この実装では、長い動画に対する直接的なE2Eデコード処理の代わりに、動画をチャンクに分割し、中間フィーチャーをキャッシュすることで、グラフィックカードの使用量が元の動画の長さに関係なくチャンクのサイズにのみ関係するようにし、モデルが無制限の長さの1080P動画を効率的にエンコードおよびデコードできるようにしている。研究チームによれば、このキーテクノロジーは、任意の長さのビデオをトレーニングするための実行可能な道を提供するとのことである。
次の図は、異なるVAEモデルの結果を比較したものである。モデルの計算効率(フレーム/遅延)とビデオ圧縮再構成(ピーク信号対雑音比、PSNR)の指標では、Tongyi Wanxiangが採用したVAEは、依然としてパラメータを支配することなく、以下の結果を達成しています。業界をリードするビデオ圧縮と再構成品質.
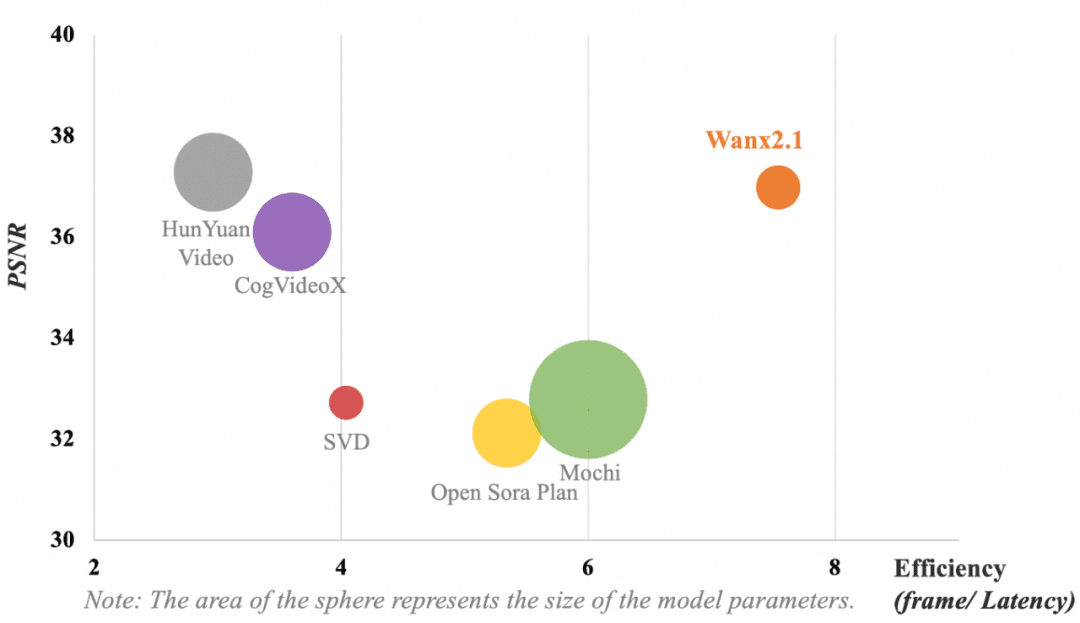
注:円の領域はモデルのパラメータサイズを表す。
DiT(ディフュージョン・トランスフォーマー)に対するチームの中心的な設計目標は、効率的なトレーニングプロセスを維持しながら、強力な時空間モデリング機能を実現することだった。そのためには、多くの革新的な変更が必要でした。
第一に、時空間関係のモデル化能力を向上させるため、時空間フルアテンションメカニズムを採用し、現実世界の複雑なダイナミクスをより正確にシミュレートできるようにした。第二に、パラメータ共有メカニズムを導入することで、性能を向上させながら学習コストを効果的に削減した。さらに、テキスト特徴の埋め込みにクロスアテンションメカニズムを用いることで、テキスト埋め込み性能を最適化し、より優れたテキスト制御性と計算量の削減を両立させた。
これらの改良と試みのおかげで、一般化ユニバーサルフェーズのDiT構造は、同じ計算コストで、より顕著な収束優位性を達成した。
モデル・アーキテクチャの革新に加え、チームは次のことを行った。超長鎖配列のトレーニングと推論、データ構築パイプライン、モデル評価の分野でも、いくつかの最適化が行われている。このモデルは、複雑な生成タスクを効率的に処理することができ、効率が向上する。
数百万の超長シークエンスで効率的にトレーニングする方法
超長時間のビジュアルシーケンスを扱う場合、大規模モデルはしばしば、計算、メモリ、学習の安定性、推論レイテンシといった複数のレベルでの課題に直面する。
このため、研究チームは、新しいモデルのワークロードの特性と訓練クラスタのハードウェア性能を組み合わせて、モデルの反復時間を保証することを前提に、訓練性能を最適化するための分散メモリ最適化訓練戦略を開発し、最終的に、次のような結果を得た。業界トップクラスのMFUを達成し、100万本の超長シークエンスの効率的なトレーニングを実現.
一方では、DP、FSDP、RingAttention、Ulyssesを用いた4次元並列トレーニングを採用することで分散戦略を革新し、トレーニング性能と分散スケーラビリティの両方を向上させている。一方、メモリの最適化を実現するため、チームは階層的メモリ最適化戦略を採用し、Activationメモリを最適化し、シーケンス長に起因する計算量と通信量に基づくメモリの断片化問題を解決する。
さらに、計算の最適化により、モデル学習の効率を向上させ、リソースを節約することができるため、チームは、時空間フルアテンション計算にFlashAttention3を採用し、異なるサイズの訓練クラスタの計算性能を組み合わせることにより、パーティショニングのための適切なCP戦略を選択する。同時に、いくつかの主要モジュールについて計算の冗長性を排除し、効率的なカーネル実装によってアクセスオーバーヘッドを削減し、計算効率を向上させている。ファイルシステムの面では、AliCloud訓練クラスタの高性能ファイルシステムの読み書きの特性を最大限に活用し、Save/Loadのスライスによって読み書きの性能を向上させています。

4Dパラレル分散トレーニング戦略
同時に、チームは、トレーニング中にDataloader Prefetch、CPU Offloading、Save Checkpointによって引き起こされるOOM問題に対処するために、時差メモリ使用スキームを選択しました。さらに、トレーニングの安定性を確保するため、チームはAliCloudのトレーニングクラスタのインテリジェントなスケジューリング、低速マシン検出、自己修復機能を活用し、障害のあるノードを自動的に特定し、タスクを迅速に再起動しました。
データ構築とモデル評価に自動化を導入
大規模なビデオ生成モデルは、大規模で高品質なデータと効果的なモデル評価なしには学習できない。前者は、モデルが多様なシナリオ、複雑な時空間依存関係を学習し、汎化を向上させることを保証し、モデルトレーニングの基礎となる。後者は、モデルのパフォーマンスを監視し、期待される結果をより良く達成することを助け、モデルトレーニングの風見鶏となる。
データ構築の面では、人間の嗜好分布と映像品質、動き品質などの点で整合性の高い高品質を基準とした自動データ構築パイプラインを構築しており、多様性が高く、バランスの取れた分布などを持つ高品質な映像データを自動的に構築することができる。
モデル評価のために、チームは同様に、美的採点、モーション分析、コマンドの順守など20以上の次元を組み込んだ自動化されたメトリクスの包括的なセットを設計し、人間の嗜好に合わせることができるプロの採点者をターゲットにして訓練した。これらのメトリクスからの効果的なフィードバックにより、モデルの反復と最適化のプロセスは大幅に加速された。
アーキテクチャ、トレーニング、評価など、いくつかの側面における相乗的な革新により、アップグレードされたトンイワンフェーズのビデオ生成モデルは、実世界での経験において大幅な世代交代を果たすことができたと言える。
ビデオ生成のためのGPT-3モーメントあとどれくらい?
昨年2月以来、OpenAIの ソラ その登場以来、動画生成モデルはテック界で最も競争の激しい分野となっている。国内から海外まで、スタートアップからテック大手までが独自の動画生成ツールを発表している。しかし、テキストの生成に比べ、AI動画は受容される度合いを実現するための難易度が一段と高い。
もし、OpenAIのCEOであるサム・アルトマンが言うように、Soraが映像生成のグランドモデルにおけるGPT-1の瞬間を表しているのであれば、それを土台にして、テキストコマンドの精密な制御や、キャラクターの一貫性を確保するためのアングルやカメラ位置の調整機能を実現することができる。この基盤の上に、テキストコマンドによるAIの精密な制御、アングルやカメラ位置の調整、一貫したキャラクター設定などの映像生成能力を実現し、さらにAIならではのスタイルやシーンの素早い変更能力を加えれば、新たな「GPT-3の瞬間」が訪れる日も近いかもしれない。
技術開発の道筋から見れば、映像生成モデルはスケーリング法則を検証するプロセスである。基本モデルの能力が向上すれば、AIはより多くの人間の命令を理解し、よりリアルで合理的な環境を作り出すことができるようになる。
昨年来、ショートビデオやアニメーション、さらには映画やテレビに携わる人々が、映像生成AIをクリエイティブな探求のために使い始めている。現実の限界を突破し、これまで想像もできなかったことが映像生成AIで可能になれば、業界の新たな変革はすぐそこまで来ている。
そして今、同志満翔は最初の一歩を踏み出したようだ。
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事



コメントはありません