TF-ID:学術論文フォーム/画像認識ツール

はじめに
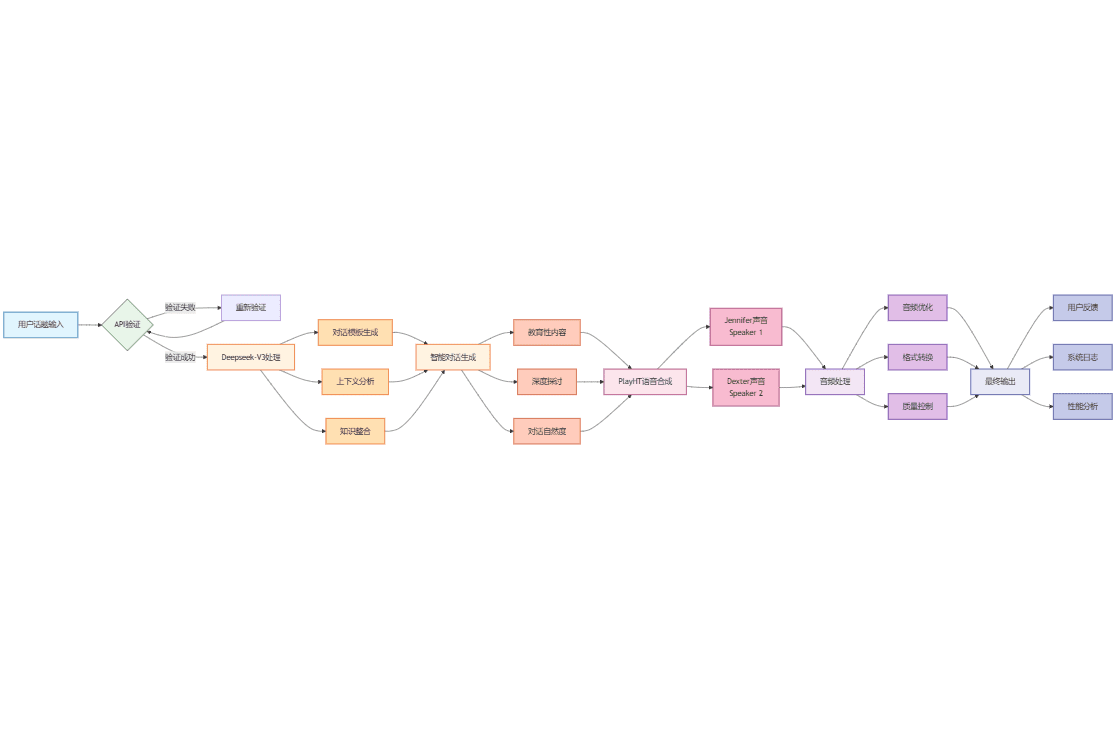
TF-ID (Table/Figure IDentifier)は、学術論文から表や画像を抽出するためのオブジェクト検出モデル群です。TF-IDモデルは、学術論文から表や画像を認識・抽出するために微調整されており、キャプションテキストの有無に関わらず抽出をサポートします。このプロジェクトでは、完全な学習コード、モデルの重み、手動でラベル付けされたデータセットを提供しており、すべてMITライセンスの下でオープンソース化されています。

機能一覧
- 学術論文から表や画像を抽出
- ヘッダーテキストの有無にかかわらず抽出をサポート
- 完全なトレーニングコードとモデルの重みを提供する
- PDFファイルからの表と画像の抽出をサポート
- さまざまなニーズに合わせて複数のモデルバージョンを用意
ヘルプの使用
設置プロセス
- クローン倉庫
git clone https://github.com/ai8hyf/TF-ID cd TF-ID - データセットのダウンロード: Hugging Faceからデータセットをダウンロードし、適切なディレクトリに解凍する。
wget https://huggingface.co/datasets/yifeihu/TF-ID-arxiv-papers/resolve/main/arxiv_paper_images.zip unzip arxiv_paper_images.zip -d ./images - データセット形式を変換する:
python coco_to_florence.py - トレーニングモデル:
accelerate launch train.py
使用プロセス
- 1枚の画像から表と画像を抽出します:
python inference.py --image_path path/to/image.png - PDFファイルからすべての表と画像を抽出します:
python pdf_to_table_figures.py --pdf_path path/to/paper.pdf --output_dir ./sample_output
詳しい操作手順
- 1枚の画像から表と画像を抽出::
- 画像パスを
inference.pyスクリプトは、デフォルトのTF-ID-largeモデルを使用して、画像内のテーブルと画像を抽出します。 - 抽出結果は、画像内の表と画像の位置を特定するバウンディングボックスの形で返されます。
- 画像パスを
- PDFファイルからすべての表と画像を抽出::
- PDFファイルのパスを
pdf_to_table_figures.pyスクリプトは、PDFファイルからすべての表と画像を抽出し、指定された出力ディレクトリに切り取られた画像を保存します。 - デフォルトでは、TF-ID-largeモデルが抽出に使用されるが、これはスクリプトの
model_idパラメータを使用して、別のモデルのバージョンに切り替えることができます。
- PDFファイルのパスを
- トレーニングモデル::
- リポジトリをクローンし、データセットをダウンロードしたら
coco_to_florence.pyスクリプトはデータセットをフローレンス2フォーマットに変換する。 - 利用する
accelerate launch train.pyコマンドを実行するとモデルのトレーニングが開始され、トレーニング中にチェックポイントファイルが保存されます。
- リポジトリをクローンし、データセットをダウンロードしたら
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事



コメントはありません