概要 Make Senseは、コンピュータ・ビジョン・プロジェクト用のデータセットを素早く準備できるように設計された、無料のオンライン画像注釈ツールです。複雑なインストールは不要で、ブラウザからアクセスするだけで使用でき、複数のオペレーティングシステムをサポートし、小規模なディープラーニングプロジェクトに最適です。ユーザーは...
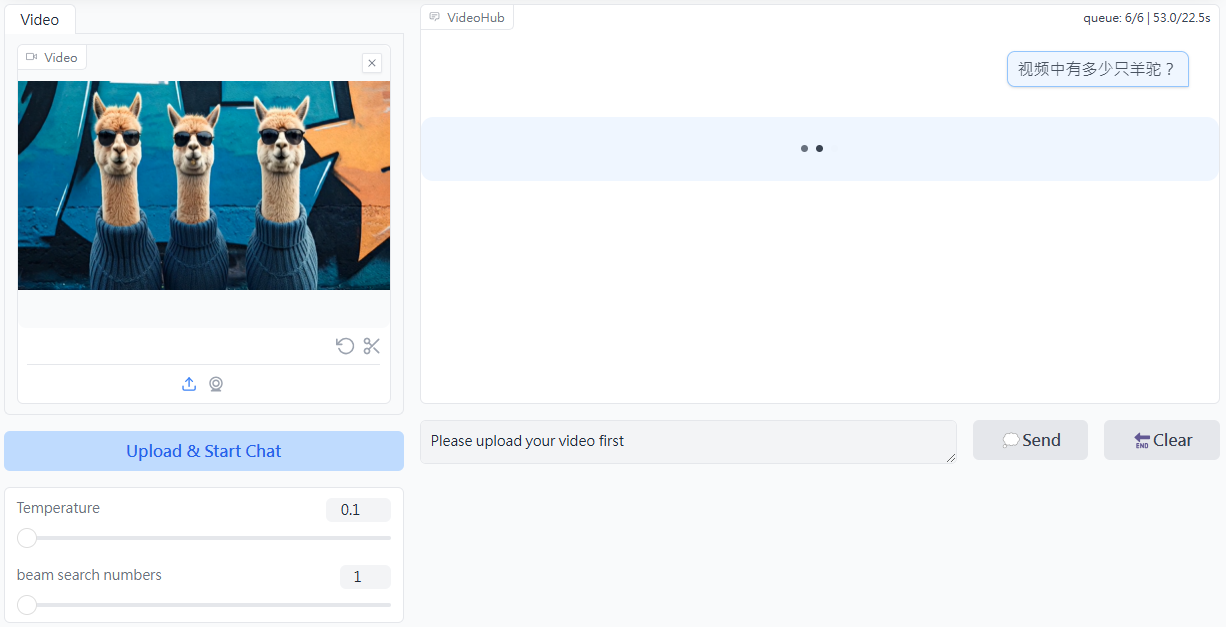
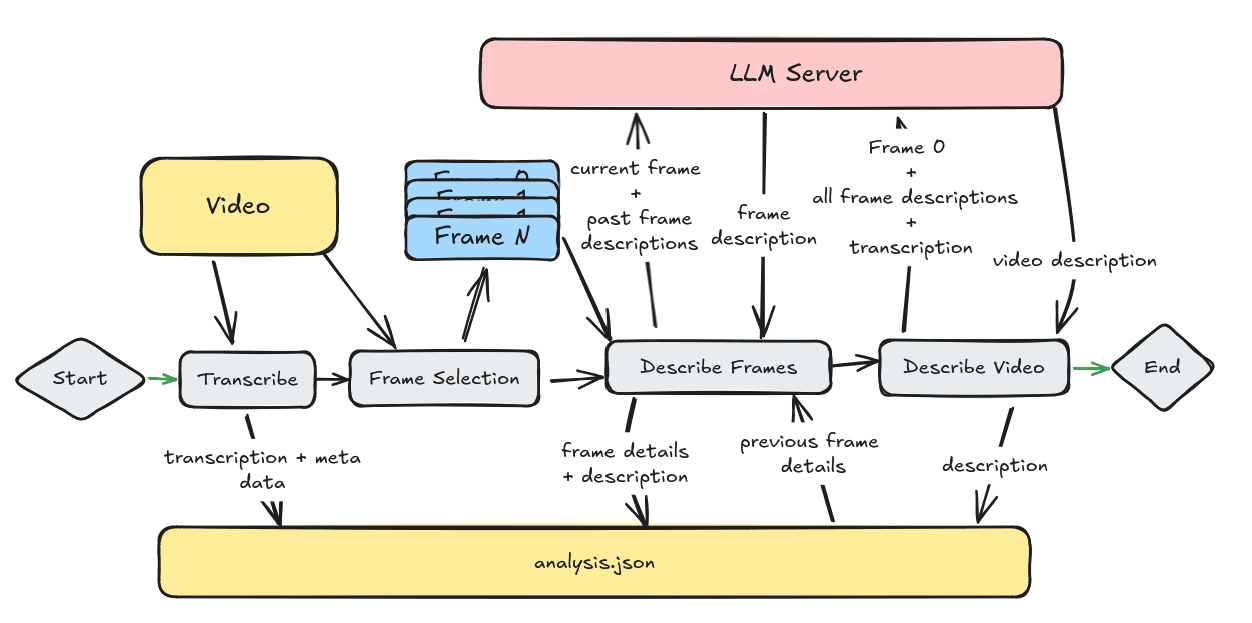
Comprehensive Introduction Video Analyzerは、コンピュータ・ビジョン、音声転写、自然言語処理技術を組み合わせて、詳細なビデオ・コンテンツの説明を生成する、総合的なビデオ分析ツールです。このツールは、動画から主要なフレームを抽出し、音声コンテンツを書き起こします。