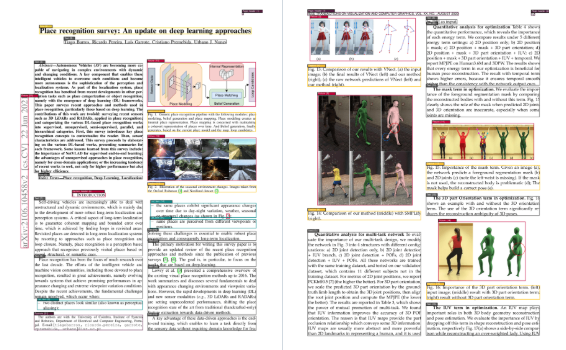
VOP: 複雑な図や数式を抽出するOCRツール包括的な紹介 Versatile OCR Programは、複雑な学術文書や教育文書を扱うために設計されたオープンソースの光学式文字認識(OCR)ツールです。PDF、画像、その他の文書からテキスト、表、数式、図、回路図を抽出し、OCRファイルを生成することができます。最新のAIリソース# AI Java オープンソースプロジェクト# OCR# ドキュメントの抽出とクリーニング1年前053.9K
PDFコンテンツを自動的に解析し、オープンソースサービスのテキストとテーブルを抽出します。総合紹介 PDF文書のレイアウトを自動的に分析し、ページ内のテキスト、タイトル、画像、表、数式、その他の要素を識別し、それらの正しい順序を決定します。このツールはOCR機能をサポートしており、スキャンしたPDFを検索可能なテキストに変換することができます。Docker上で動作し、2つのモデルを提供します。最新のAIリソース# AI Java オープンソースプロジェクト# OCR# ドキュメントの抽出とクリーニング1年前061.1K
RolmOCR: 手書き文字と斜め文字を認識する文書OCRモデル一般的な紹介 RolmOCRは、Reducto AIチームによって開発されたオープンソースの光学式文字認識(OCR)ツールで、Qwen2.5-VL-7B視覚言語モデルをベースにしています。類似のツールよりも高速に画像やPDFファイルからテキストを抽出することができます...最新のAIリソース# AI Java オープンソースプロジェクト# OCR1年前066K
uniOCR: クロスプラットフォームのオープンソーステキスト認識ツール概論 uniOCRはmediar-aiチームによって開発されたオープンソースのテキスト認識ツールです。Rust言語に基づいており、macOS、Windows、Linuxシステムをサポートしています。画像からテキストを抽出することができます。最新のAIリソース# AI Java オープンソースプロジェクト# OCR1年前082.9K
PDF Craft: PDFスキャン文書からMarkdownへのオープンソースツール一般的な紹介 PDF Craftは、書籍のPDFをスキャンしてMarkdown形式に変換するために設計されたオープンソースツールです。このツールはoomol-labによって開発され、電子書籍を整理したいユーザのためにGitHubでホストされています。このツールは、以下の方法で動作します。最新のAIリソース# AI Java オープンソースプロジェクト# OCR# ドキュメントの抽出とクリーニング1年前084.4K
SmolDocling:少量で効率的な文書処理のための視覚言語モデル包括的な紹介 SmolDoclingは、ds4sdチームがIBMと共同で開発したビジュアル言語モデル(VLM)で、SmolVLM-256Mをベースに構築され、Hugging Faceプラットフォームでホストされています。サイズは小さく、わずか ...最新のAIリソース# AI Java オープンソースプロジェクト# OCR# ドキュメントの抽出とクリーニング1年前053.7K
ミストラルOCR:94.89%総合精度、1000ページ/30秒、わずか1ドル人類の文明の長い歴史の中で、情報の取得と解析の方法が飛躍的に進歩するたびに、社会の進歩に大きく貢献してきた。古代の象形文字から、持ち運び可能なパピルス、その後の印刷機の出現、そして今日のデジタルの波に至るまで、技術革新のたびに人類の知識普及のパラダイムは大きく広がってきた。最新のAIリソース# AIオープンサービス# OCR# ドキュメントの抽出とクリーニング1年前061.5K
Ollama OCR: Ollamaの視覚モデルを使った画像からのテキスト抽出包括的な紹介 Ollama OCRは、Ollamaプラットフォームが提供する最先端の視覚言語モデルを使用して画像からテキストを抽出する、強力な光学式文字認識(OCR)ツールキットです。このプロジェクトはPythonパッケージとして提供されており、ユーザーフレンドリーなストリー...最新のAIリソース# AI Java オープンソースプロジェクト# OCR# ドキュメントの抽出とクリーニング1年前0107.8K
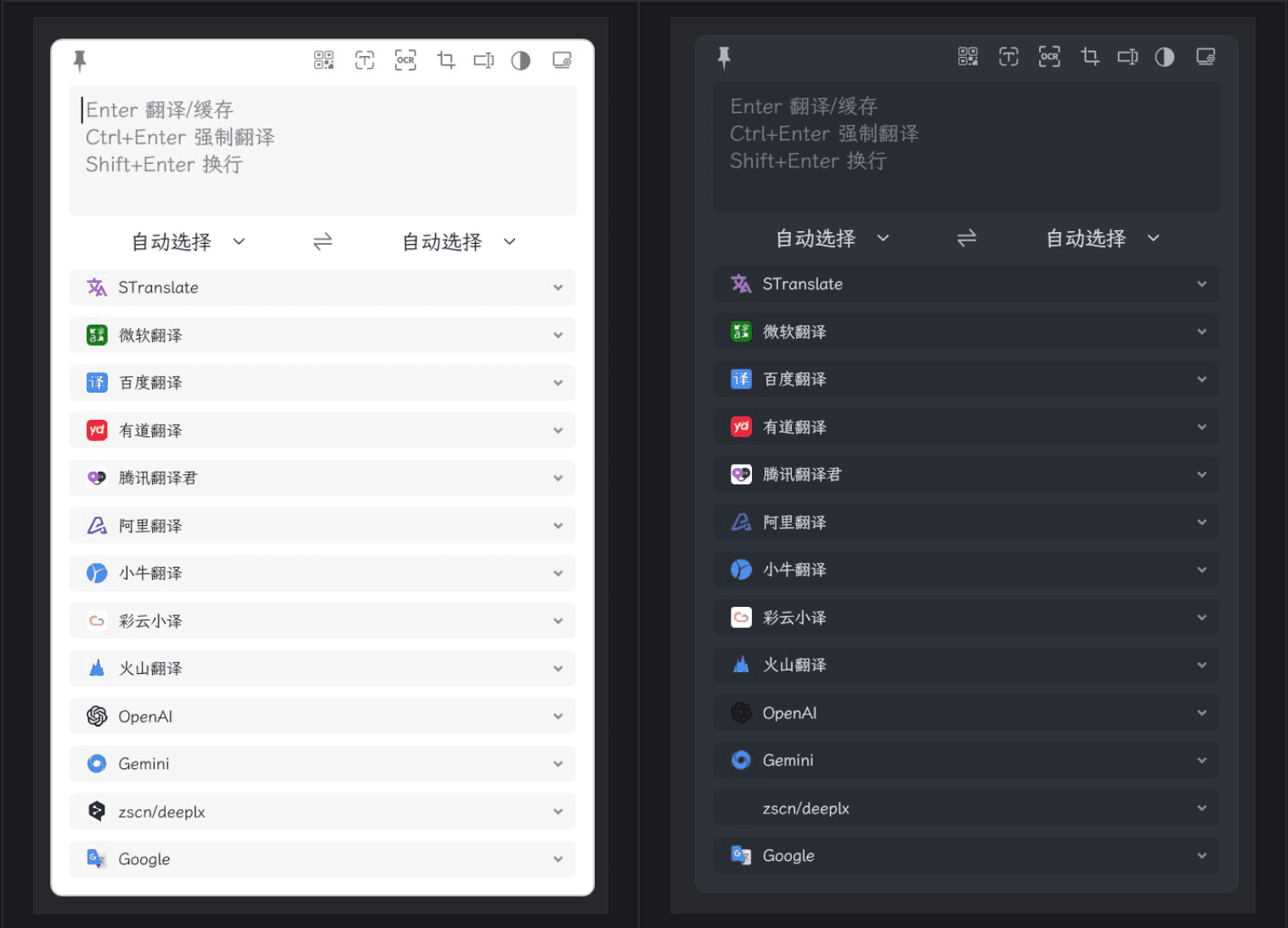
STranslate:複数の翻訳インターフェースとOCR機能を備えた軽量翻訳ツール一般的な紹介 STranslateは、WPFによって開発されたすぐに使用できる翻訳とOCRツールです。このツールは、幅広い言語とテキストタイプに対して、効率的で便利な翻訳と光学式文字認識(OCR)機能を提供するように設計されています。最新のAIリソース# AI翻訳# OCR1年前063.4K
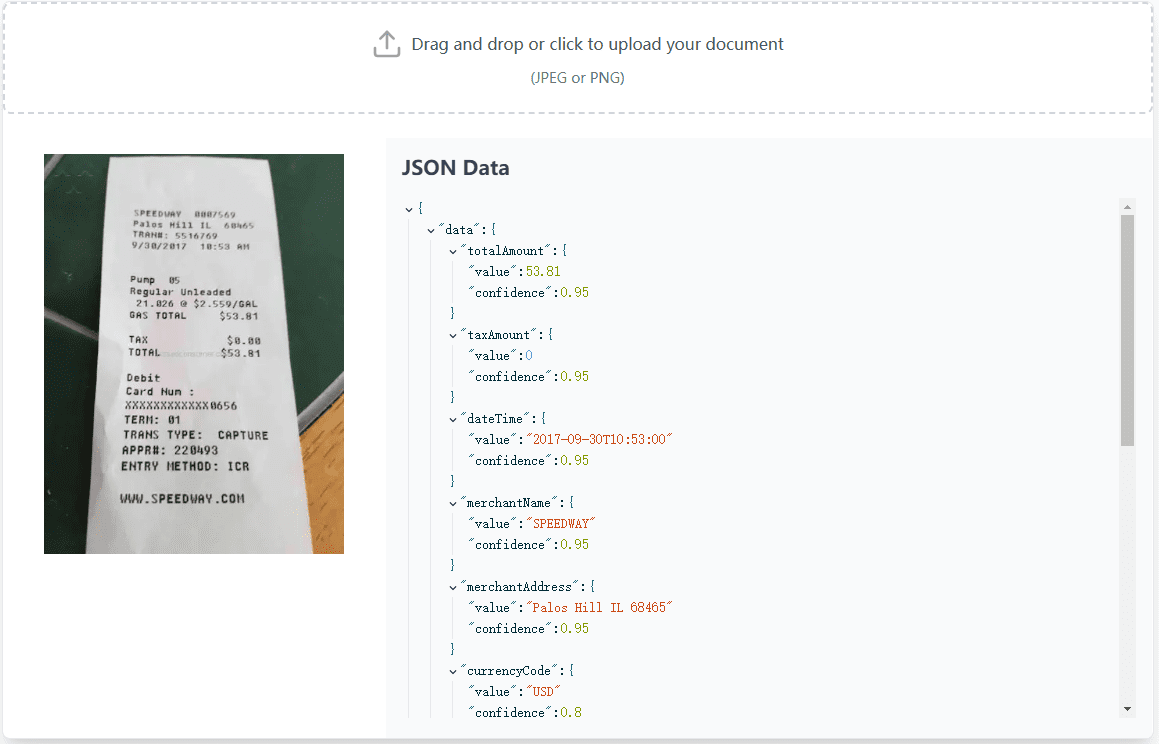
VisionParser:領収書や請求書を高精度に処理するOCRツール、APIあり概要 VisionParserは、領収書や請求書を処理するために設計されたOCR(光学式文字認識)ツールです。高度な生成AI技術により、VisionParserはあらゆる種類の領収書や請求書を迅速かつ正確に構造化されたデータに変換することができます。最新のAIリソース# OCR1年前059.1K
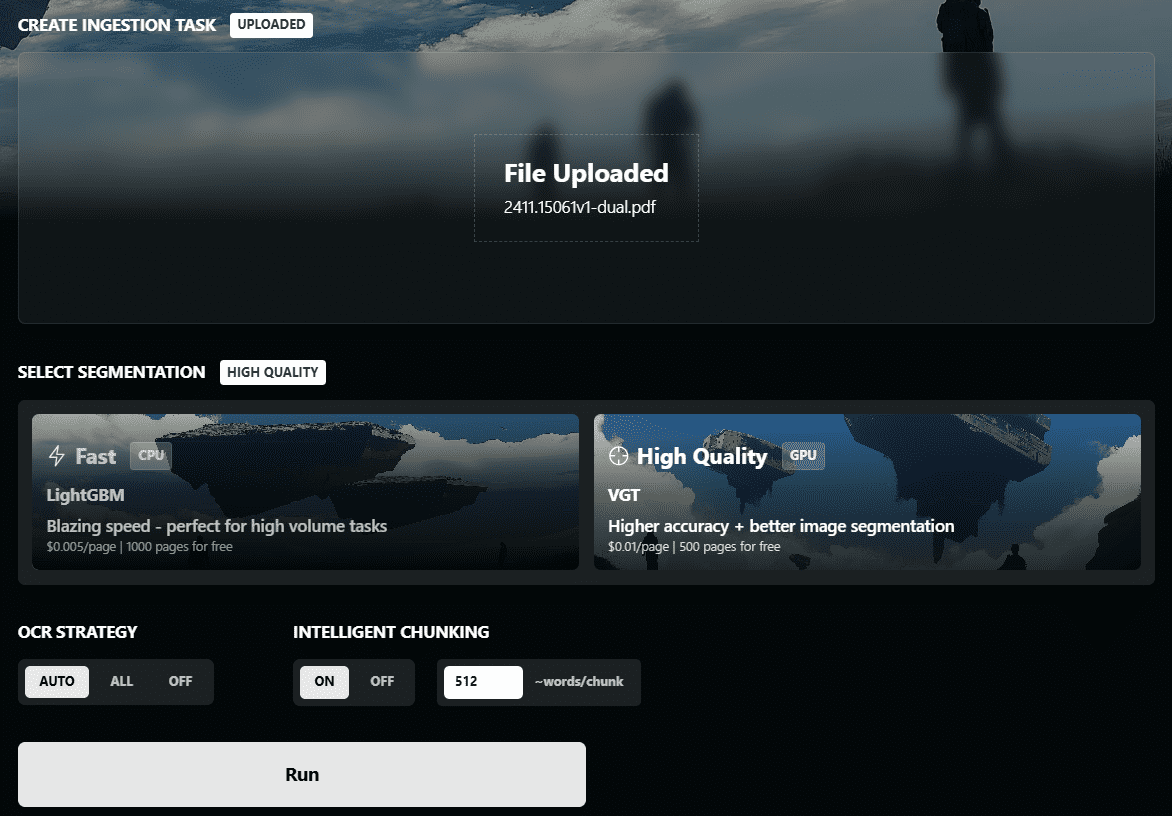
Chunkr: 文書の取り込みにビジュアルモデルを使用し、テキストの段落階層に基づくインテリジェントなチャンキングを行うオールインワンサービス。概要 Chunkrは、PDF、PPTX、DOCX、ExcelファイルをRAG(Retrieval Augmented Generation)やLLM(Large Language Modelling)で使用するのに適したデータに変換するためのセルフホストAPIです。このプロジェクトはLumina...によって開発されました。最新のAIリソース# AI Java オープンソースプロジェクト# OCR# ドキュメントの抽出とクリーニング1年前056.3K
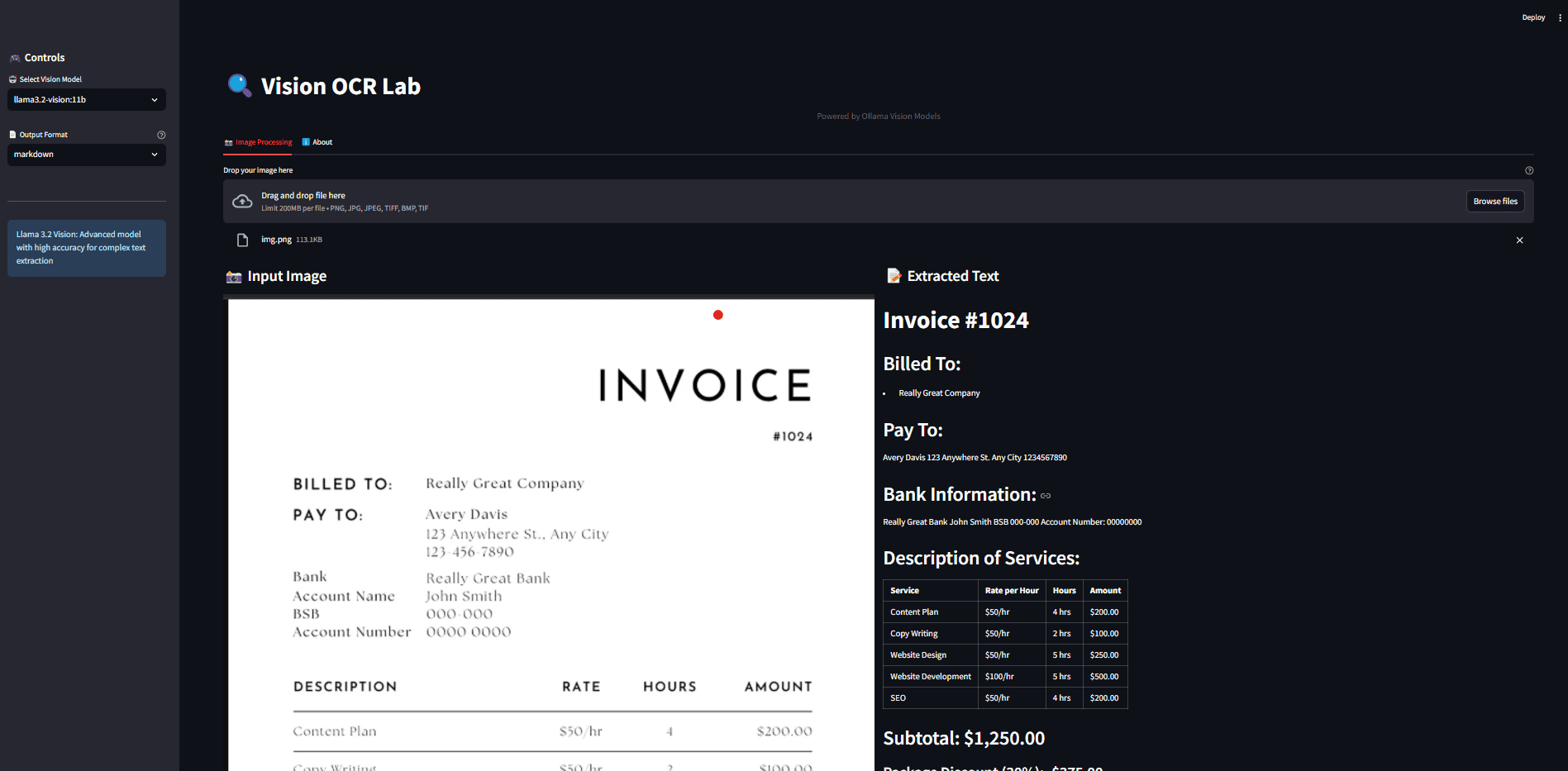
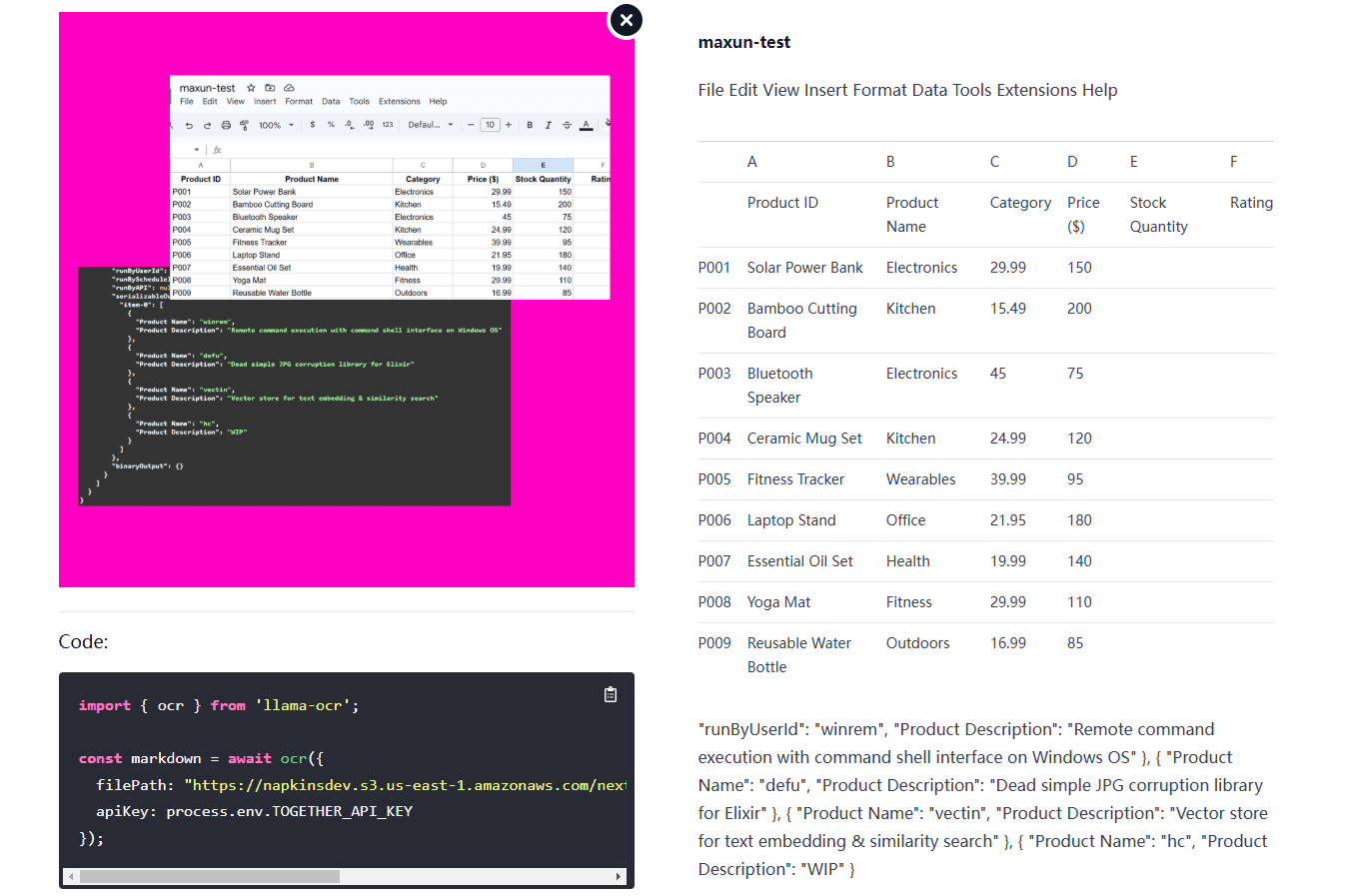
Llama OCR: 3行のコードで画像をMarkdownに変換するOCRライブラリ。概要 Llama OCRは、Llama 3.2 VisionをベースにしたOCR(光学式文字認識)ライブラリで、文書をMarkdown形式に変換することができます。このライブラリーはNutlope社によって開発され、Togetherを使用しています。最新のAIリソース# AI Java オープンソースプロジェクト# OCR# Free Large Model API1年前063.6K
Docling:様々なフォーマットのドキュメントをサポート MarkdownやJSONへの解析とエクスポート PDFサポート OCR包括的な紹介 Doclingは、PDF、DOCX、PPTX、XLSX、画像、HTML、AsciiDocおよびMarkdownを含む幅広い文書形式をサポートする強力な文書解析およびエクスポートツールです。最新のAIリソース# AI Java オープンソースプロジェクト# OCR# ドキュメントの抽出とクリーニング1年前0110.9K
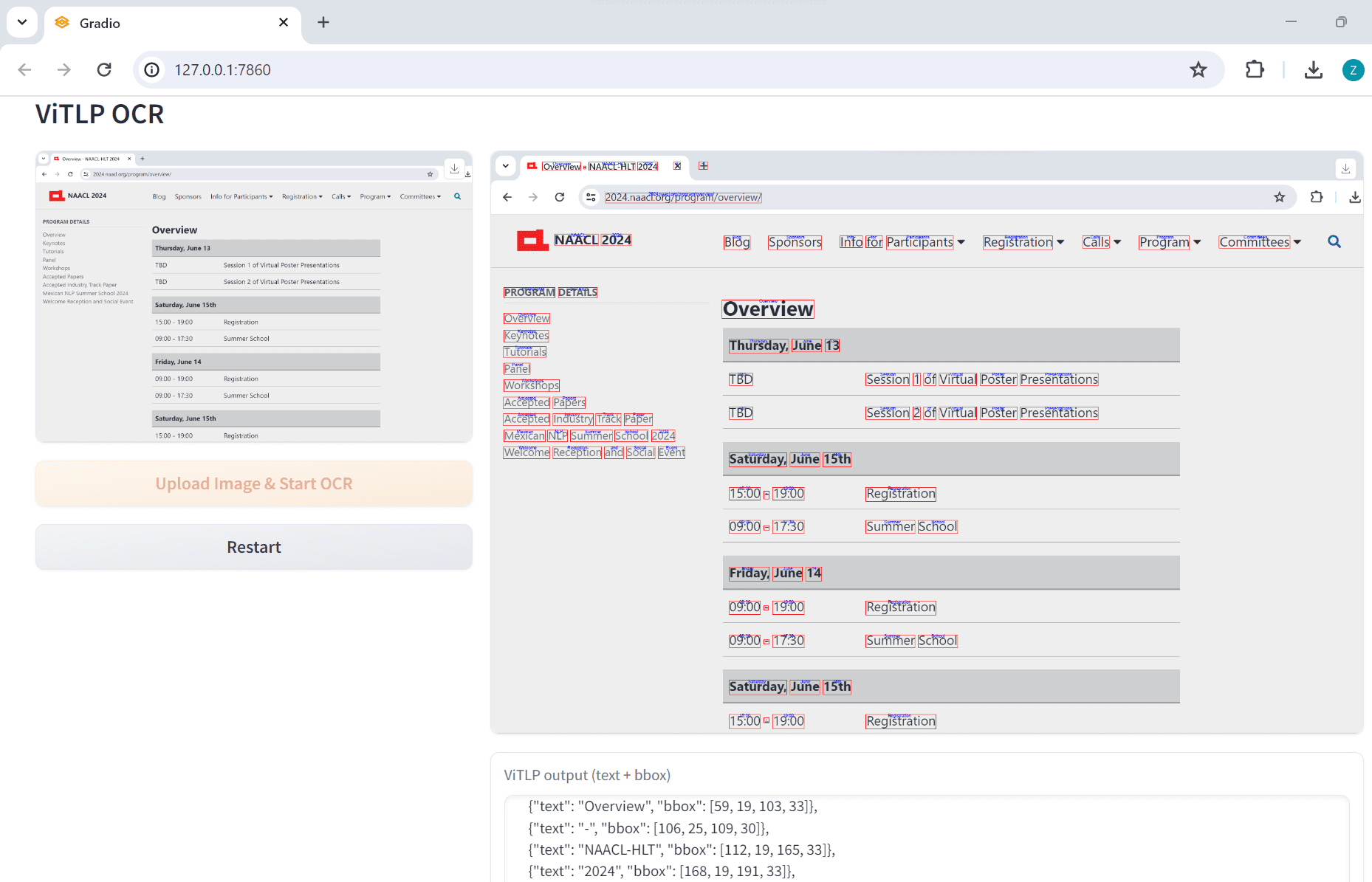
ViTLP: 組版が複雑なPDF文書から構造化データを抽出し、テキストレイアウトのための事前学習済みモデルを視覚的に誘導して生成する包括的な紹介 ViTLP(Visually Guided Generative Text-Layout Pre-training for Document Intelligence)は、ドキュメント・インテリジェンスのための視覚的ガイド付き生成テキストレイアウト事前学習(Visually Guided Generative Text-Layout Pre-training for Document Intelligence)のオープンソースプロジェクトです。最新のAIリソース# OCR# ドキュメントの抽出とクリーニング1年前055.5K
ScreenPipe:記録された画面や操作情報を24時間収集し、AIアシスタント対話、要約、知識の見直しを通じて、ローカルの知識ベースに変換する概要 ScreenPipeはmediar-aiによって開発されたAIアシスタントツールで、スクリーンコンテンツの録画、スクリーンショットのキャプチャ、24時間365日の音声の録音に特化しています。rewind.aiとcursor.comを組み合わせたものです。最新のAIリソース# AIテキストおよび音声/ビデオ要約ツール# AIノート# OCR1年前068.3K
テキスト抽出 API (text-extract-api): テキスト情報の視覚的抽出、匿名化 PDF 抽出ツール包括的な紹介 テキスト抽出API(text-extract-api)は、さまざまな文書形式(PDF、Word、PPTXなど)からコンテンツを抽出し、解析するために設計された強力なツールです。このAPIは、最先端の光学式文字認識(OCR)技術とOl...最新のAIリソース# AI Java オープンソースプロジェクト# OCR# ドキュメントの抽出とクリーニング1年前059K
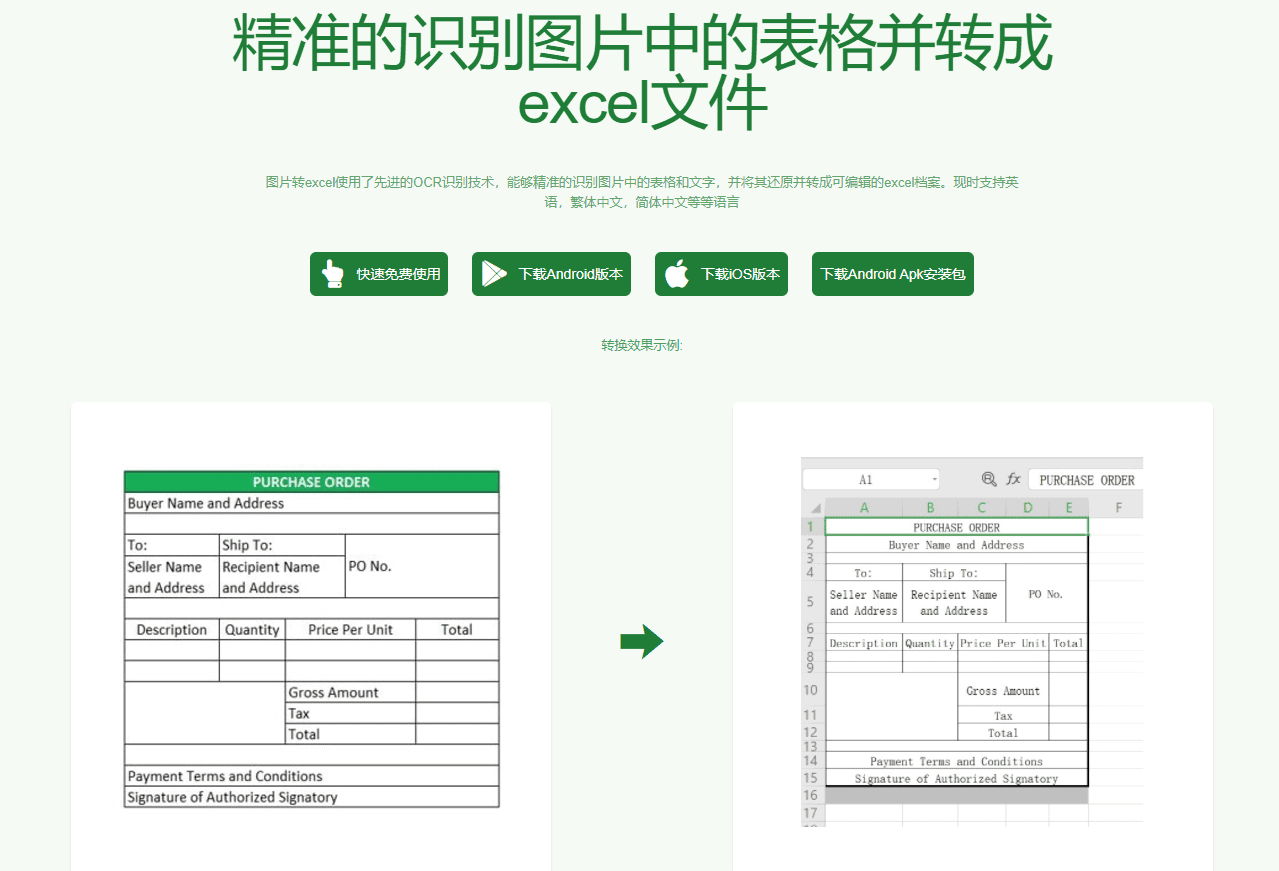
Picture to Excelフリーツール: 写真の複雑な書式を持つ表を効率的に識別し、Excelファイルに変換します。概要 Picture to Excel Free Toolは、画像からExcelファイルへの表形式データの変換を迅速かつ正確に行う効率的なオンラインツールです。このツールは、JPGやPNGなどの幅広い画像形式をサポートしており、Webページ、iOSアプリ、Androidアプリで使用することができます...最新のAIリソース# OCR1年前080K
Datalab:専用のOCR認識AIモデル、PDF to Markdown(オープンソース/API)包括的な紹介 Datalabは、OCR、レイアウト分析、PDFからMarkdownへの変換などに焦点を当てた高度なAIモデルを幅広く提供しています。これらのモデルは高性能であるだけでなく、使いやすくオープンソースです。プラットフォーム上のマーカーモデルは、迅速かつ正確に...最新のAIリソース# AIオープンサービス# AI Java オープンソースプロジェクト# OCR1年前067.5K
eSearch:多機能クロスプラットフォームOCRツール、統合検索|翻訳|検索マップ|画面録画およびその他の機能一般的な紹介 eSearchは、xushengfengによって開発されたオープンソースのクロスプラットフォームスクリーンショットツールで、Windows、macOS、Linuxシステムをサポートしています。スクリーンショット、OCR認識、検索、翻訳、マッピングなど様々な機能を統合しています。最新のAIリソース# OCR2年前059.9K
Surya: プロフェッショナルな多言語ドキュメントOCRツール、オープンソース・ネイティブデプロイメント包括的な紹介 Suryaは、90以上の言語のテキスト認識をサポートするオープンソースの多言語文書OCRツールキットです。行単位のテキスト検出だけでなく、レイアウト分析、読み順検出、表認識も実行します。Suryaの性能は、あらゆる種類の文書でクラウドサービスに匹敵します。最新のAIリソース# AI Java オープンソースプロジェクト# OCR2年前0122.2K
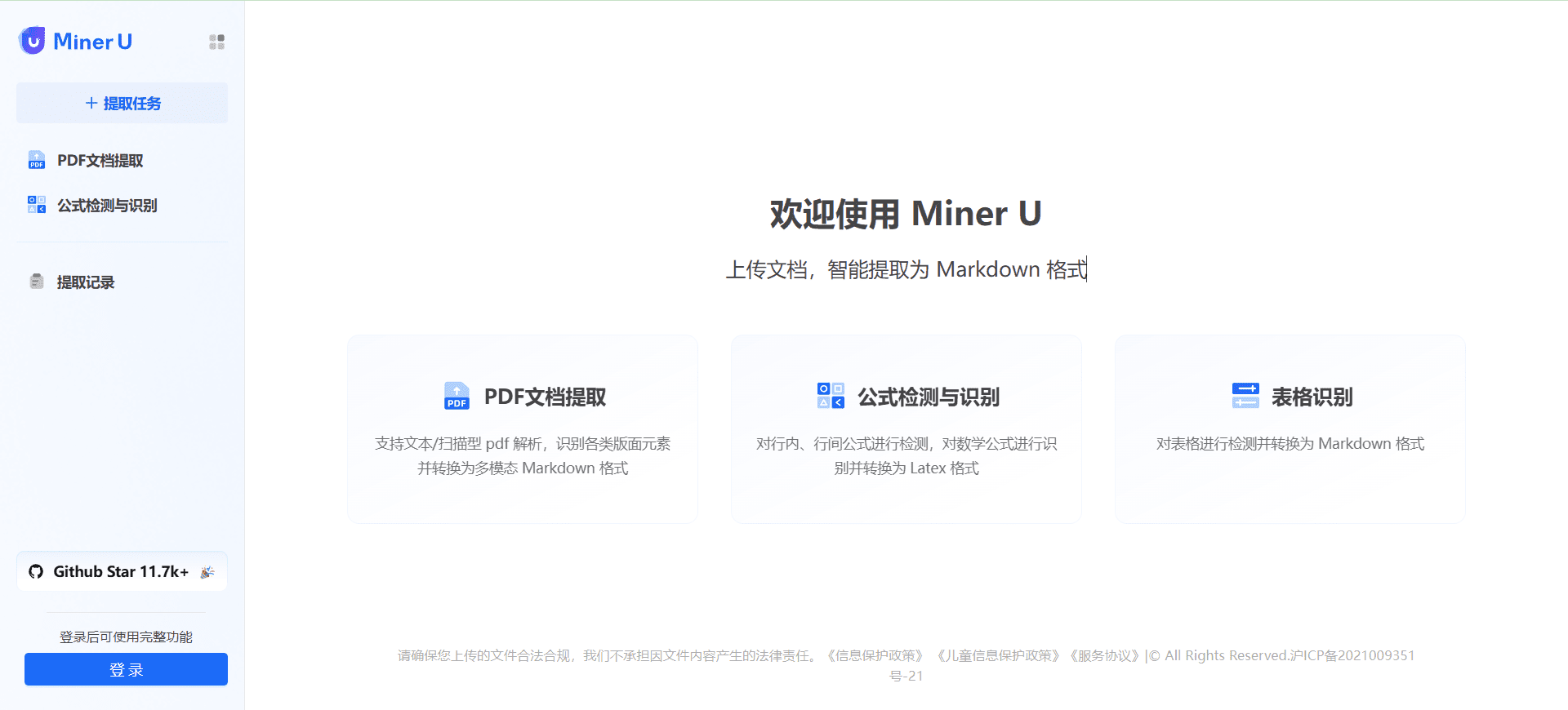
MinerU: PDFドキュメントの抽出とマルチモーダルMarkdownフォーマットへの変換、電子書籍OCRスキャンのサポート包括的な紹介 MinerUは、上海人工知能研究所のOpenDataLabチームによって開発されたオープンソースのデータ抽出ツールで、複雑なPDF文書、ウェブページ、電子ブックからコンテンツを効率的に抽出することに重点を置いている。画像、数式、表、その他の要素を含むマルチモーダルPDFを取り込むことができる。最新のAIリソース# AI Java オープンソースプロジェクト# OCR# ドキュメントの抽出とクリーニング2年前0143.4K
PixPin:長尺でダイナミックなスクリーンショット、ネイティブテキスト認識(OCR)内蔵はじめに PixPin は、ユーザーの生産性を向上させるために設計された、強力な スクリーンショットおよび投稿ツールです。PixPin は、日常的なオフィスでもプロフェッショナルなニーズでも、便利なスクリーンショット、貼り付け、ロングスクリーンショット、テキスト認識(OCR)、ダイナミックスクリーンショット機能を提供します。シンプルなインターフェースと...最新のAIリソース# OCR2年前0113.6K
GOT-OCR2.0: QWen2 0.5Bエンドツーエンド・マルチモーダルOCRモデルに基づく包括的な紹介 GOT-OCR2.0は、統一されたエンドツーエンドモデルを通じて、OCR技術をOCR-2.0に向けて推進することを目的とした、StepStar共同提案のオープンソース光学式文字認識(OCR)モデルです。このモデルは、通常のテキスト認識、gr...最新のAIリソース# AI Java オープンソースプロジェクト# OCR2年前066.9K
PaddleOCR: Flying Paddleベースの多言語OCRツールライブラリ。包括的な紹介 PaddleOCRはPaddlePaddleをベースにした多言語OCRツールキットで、実用的で超軽量のOCRシステムを提供するように設計されています。80以上の言語の認識をサポートし、データ注釈と合成ツールを提供し、実...最新のAIリソース# AI Java オープンソースプロジェクト# OCR1年前089K
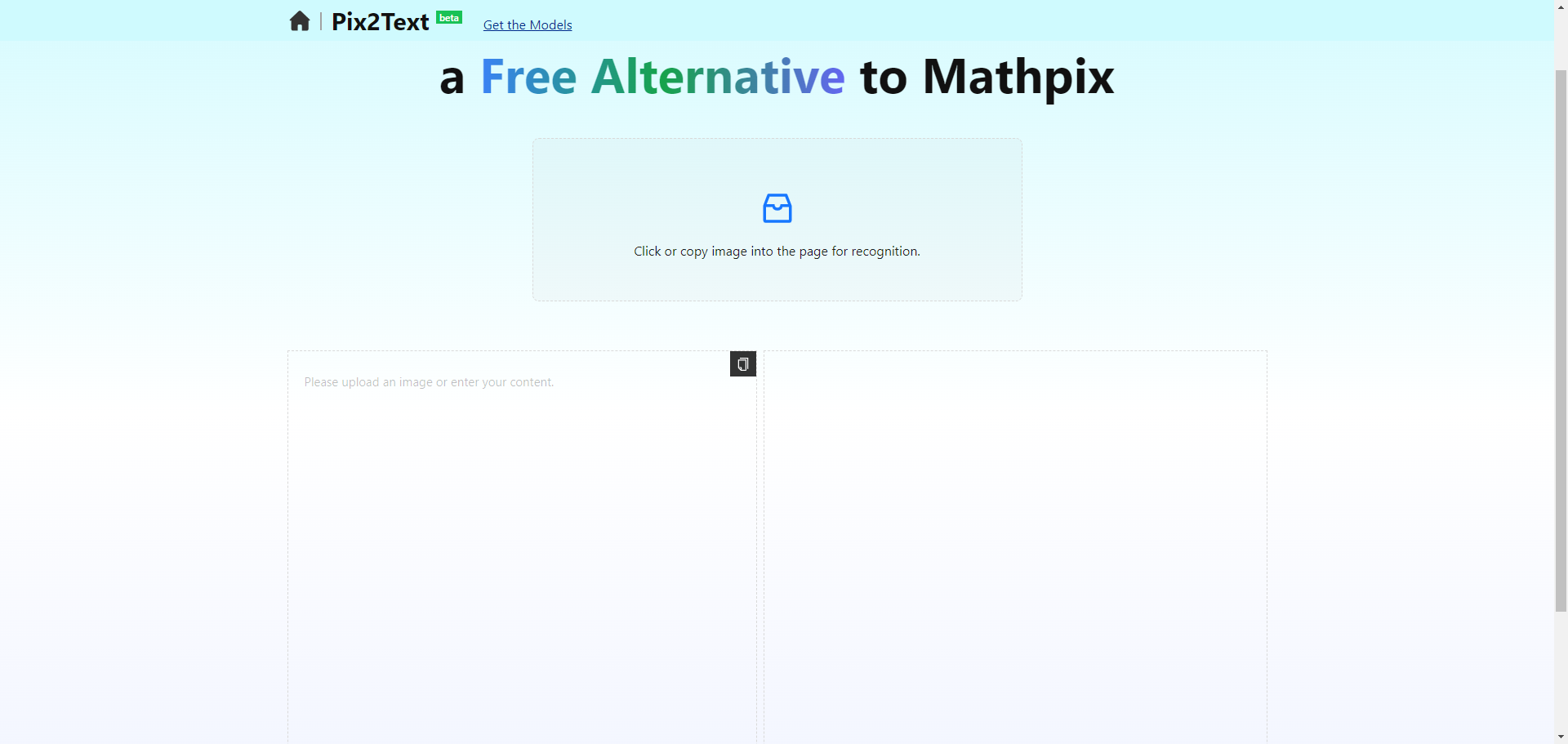
Pix2Text: オープンソースのフリー画像テキスト認識ツールPix2Text 概要 Pix2Text (P2T) は、Mathpix を置き換えるために設計されたオープンソースのフリーツールで、画像テ キストおよび数式認識を提供します。ユーザはウェブバージョンから無料でこのツールを使用でき、1日あたり最大10,000件まで認識することができます...最新のAIリソース# OCR2年前072.4K
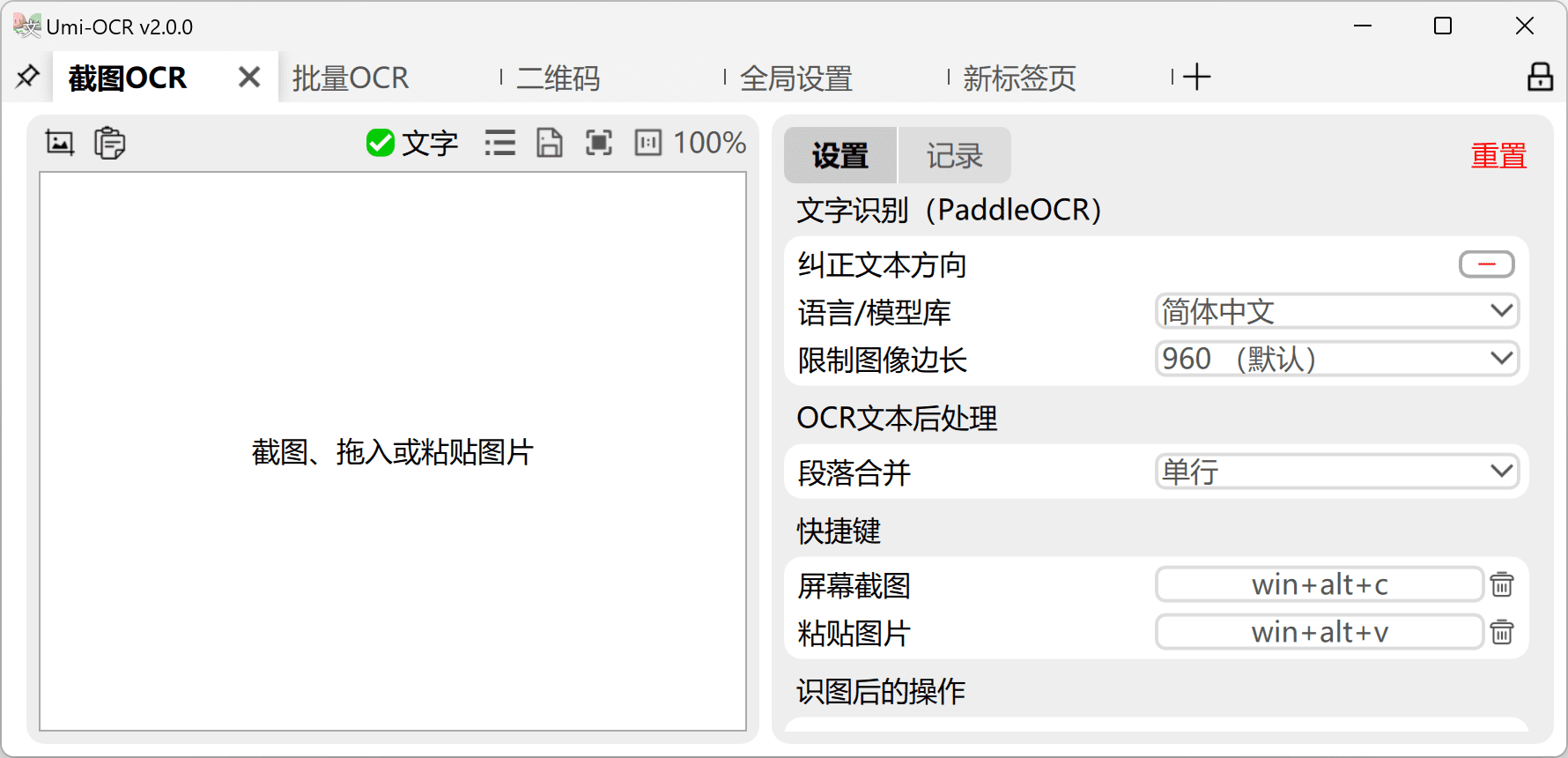
Umi-OCR: オープンソースのオフラインOCRソフトウェア、バッチ画像認識、PDF認識Umi-OCR 概要 Um-OCRは、スクリーンショット、画像の一括取り込み、PDF文書の認識、透かしやヘッダー・フッターの除外、スキャン、QRコードの生成をサポートする、オープンソースの無料オフラインOCRソフトウェアです。このソフトウェアには、WindowsおよびLi...最新のAIリソース# OCR2年前0105.4K
TTime: 画像認識・テキスト翻訳ソフトウェアTTime 概要 TTime は InkTimeRecord が GitHub で公開しているプロジェクトで、シンプルで効率的な翻訳ソフトウェアです。主に入力、スクリーンショット、ストローク、ホバーボール翻訳機能を提供し、複数の翻訳ソースとテキスト認識サービスをサポートしています。最新のAIリソース# AI翻訳# OCR2年前055.3K