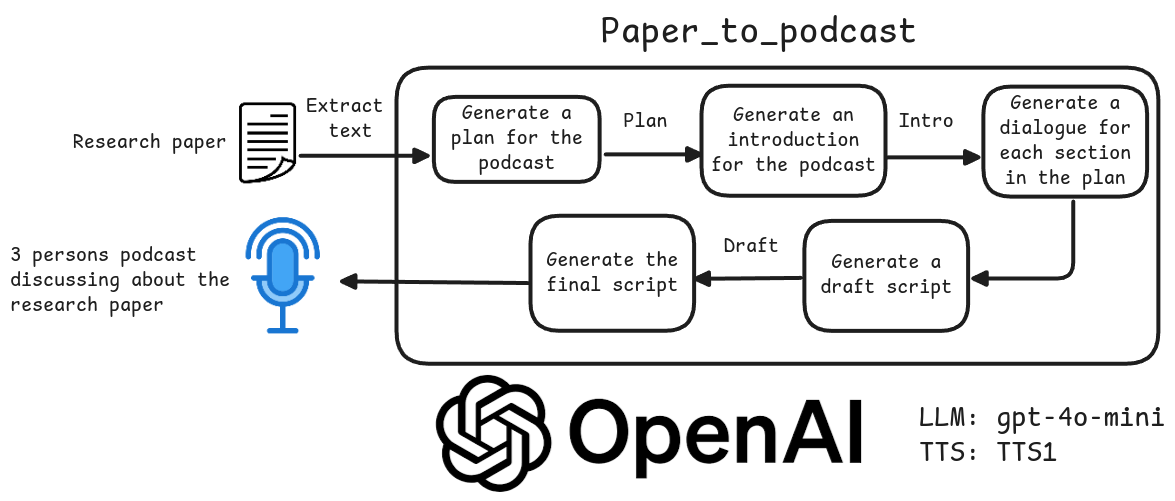
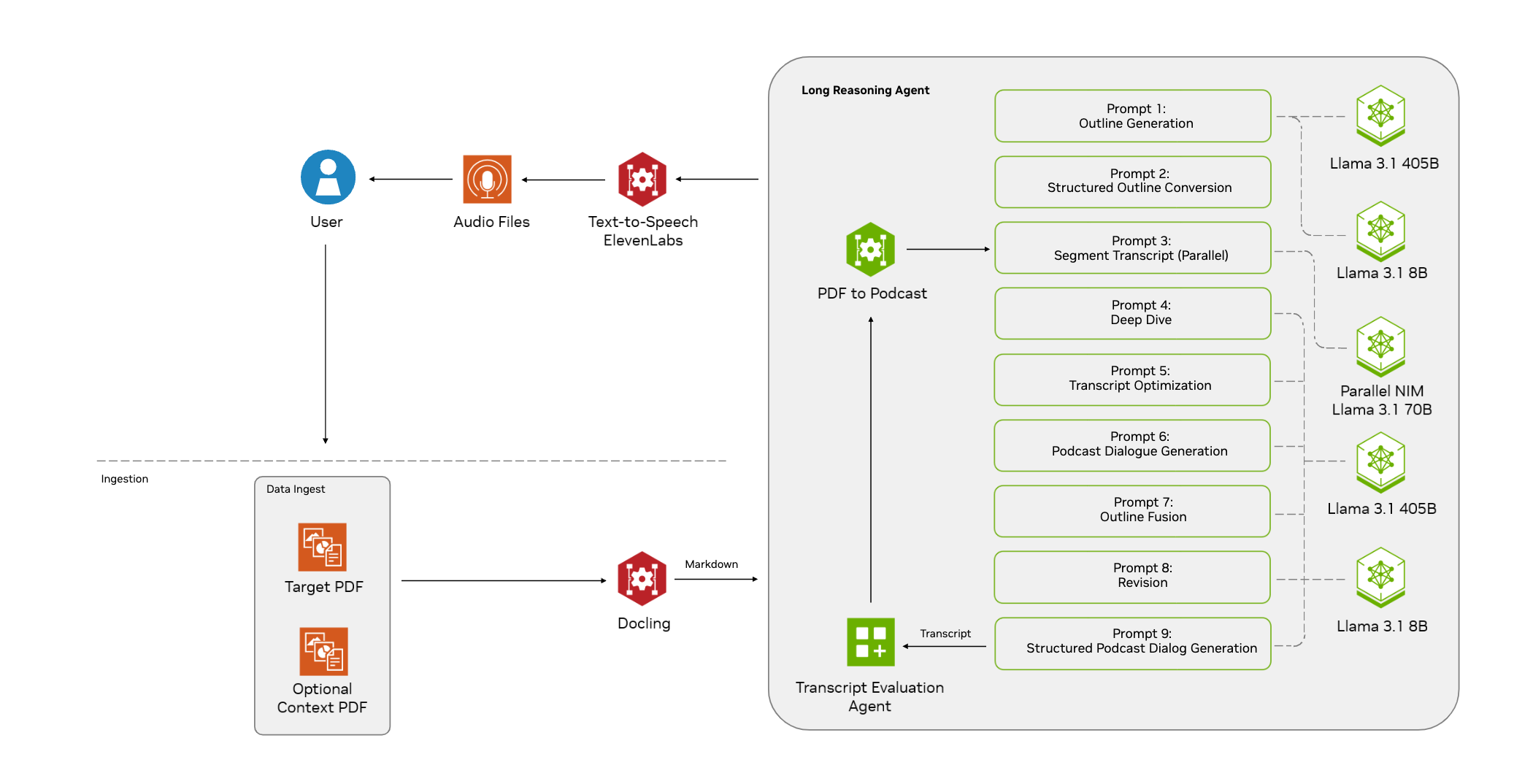
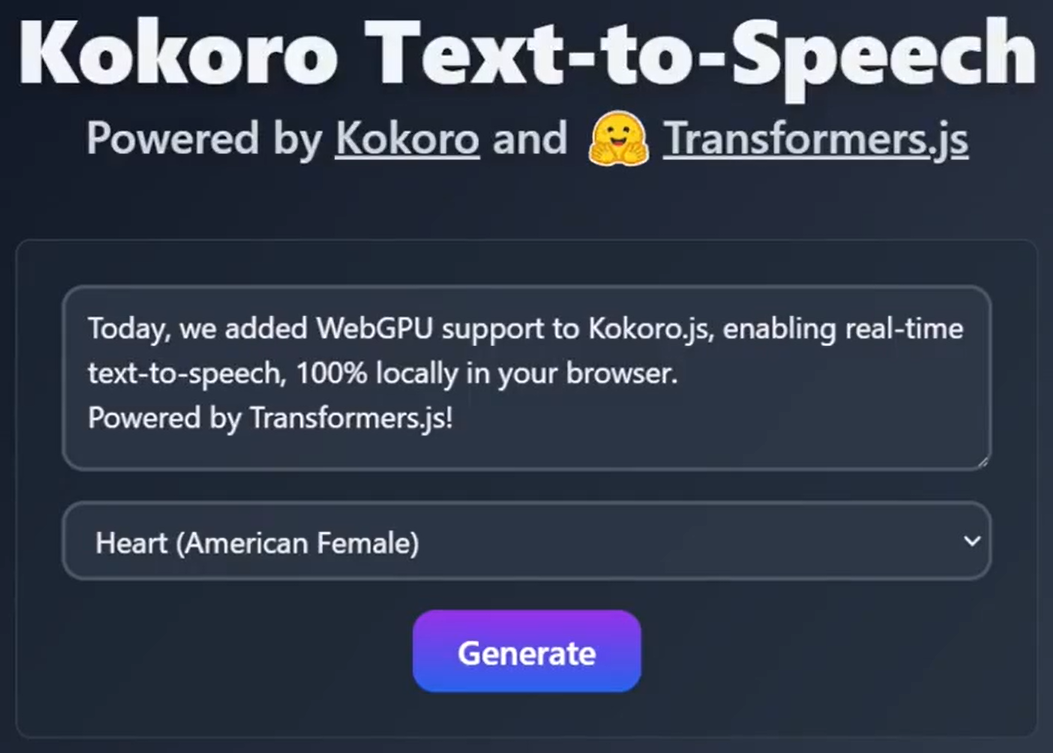
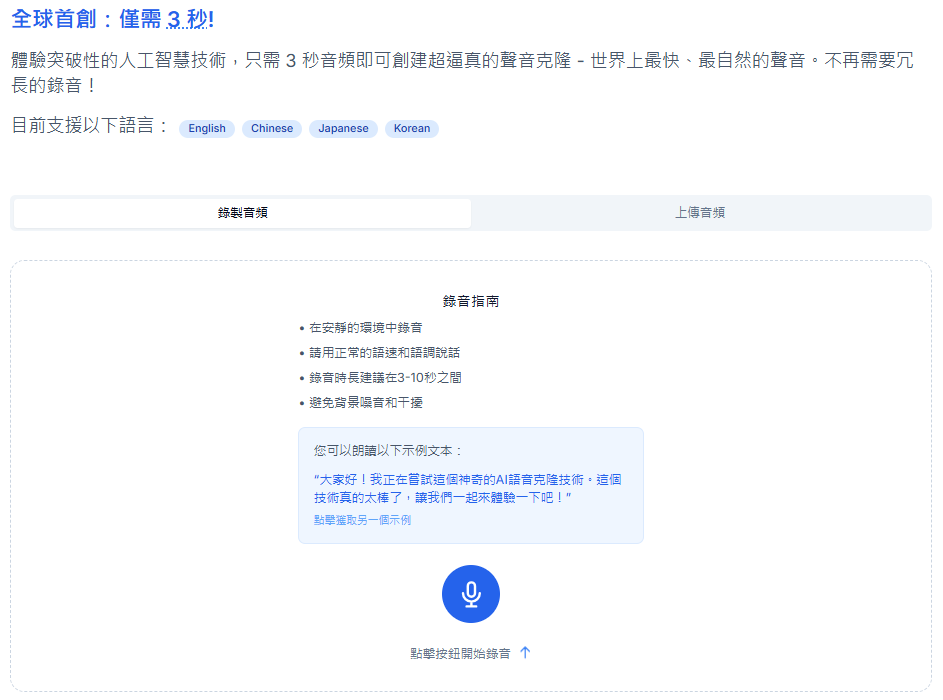
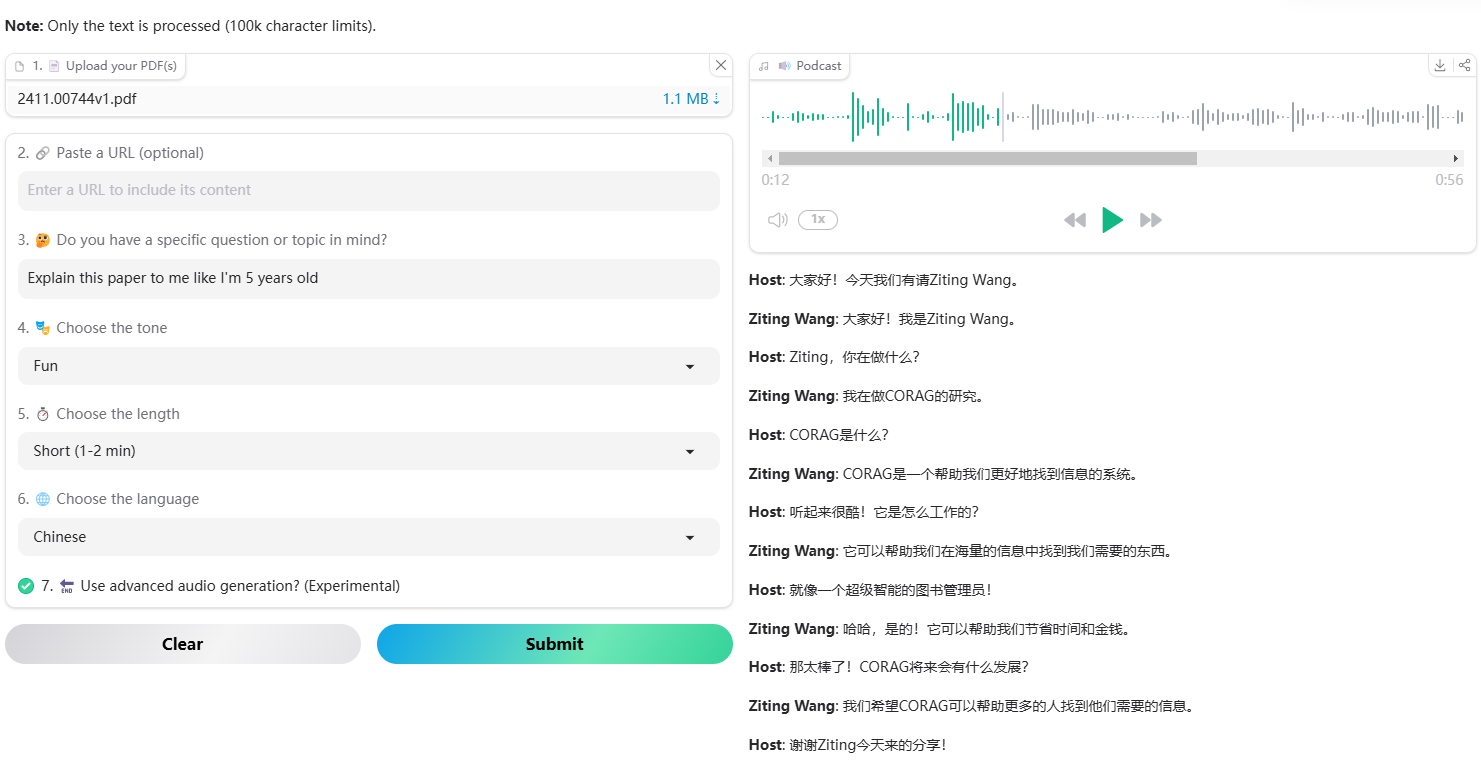
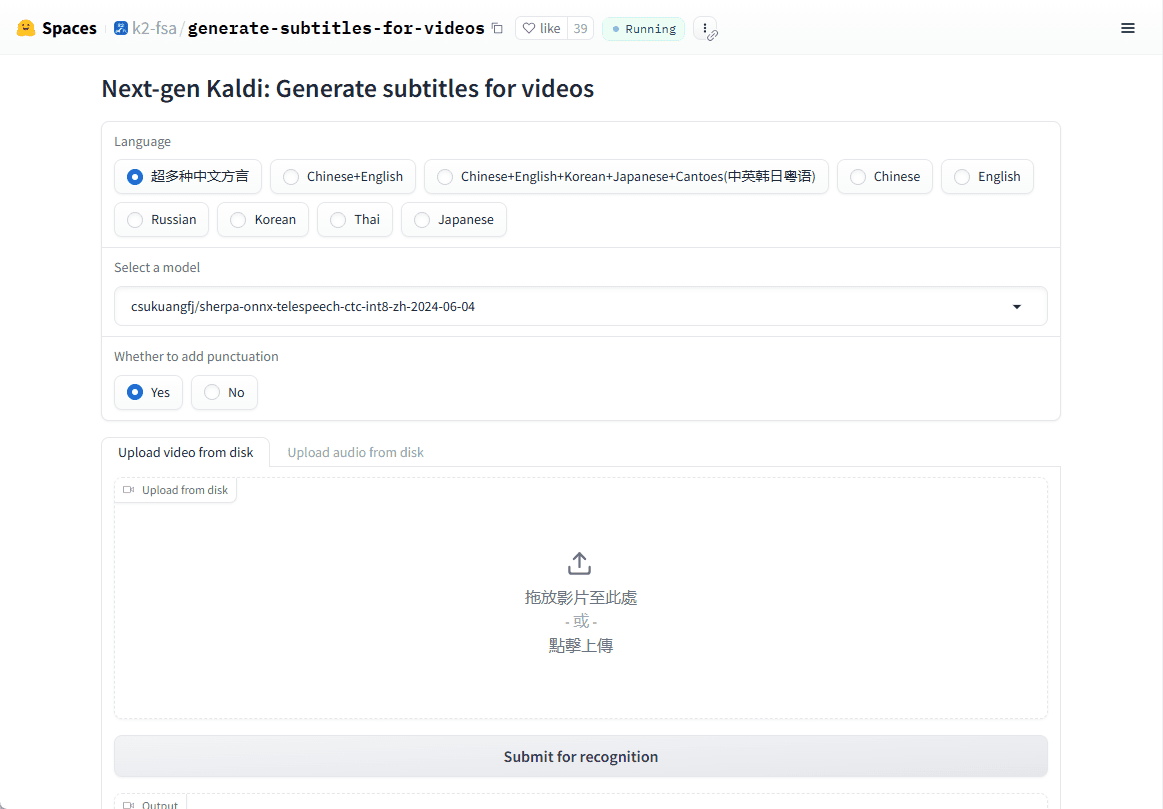
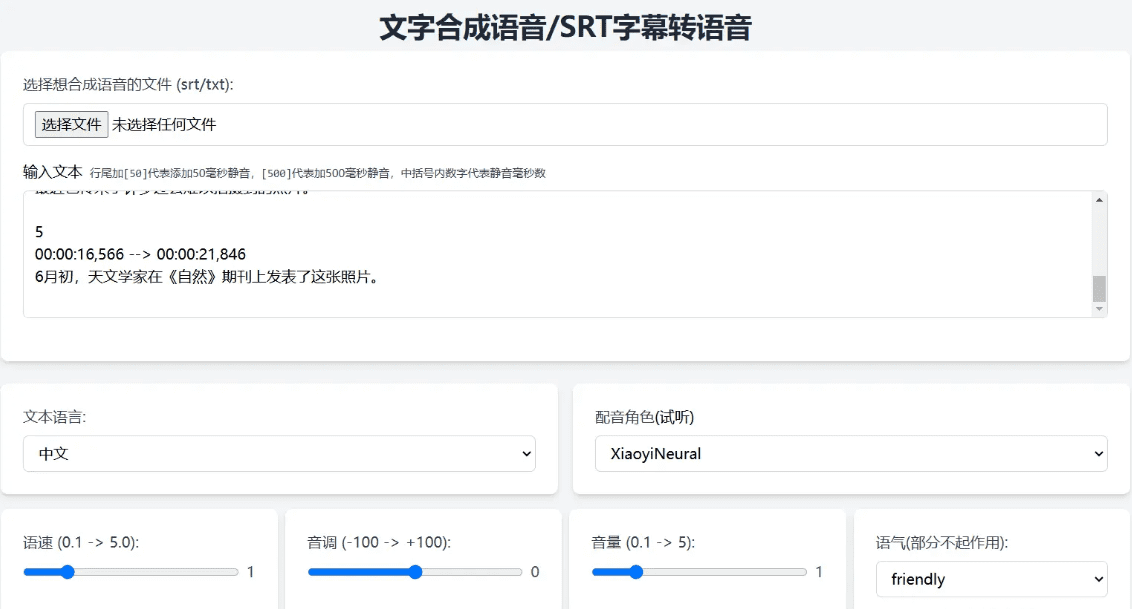
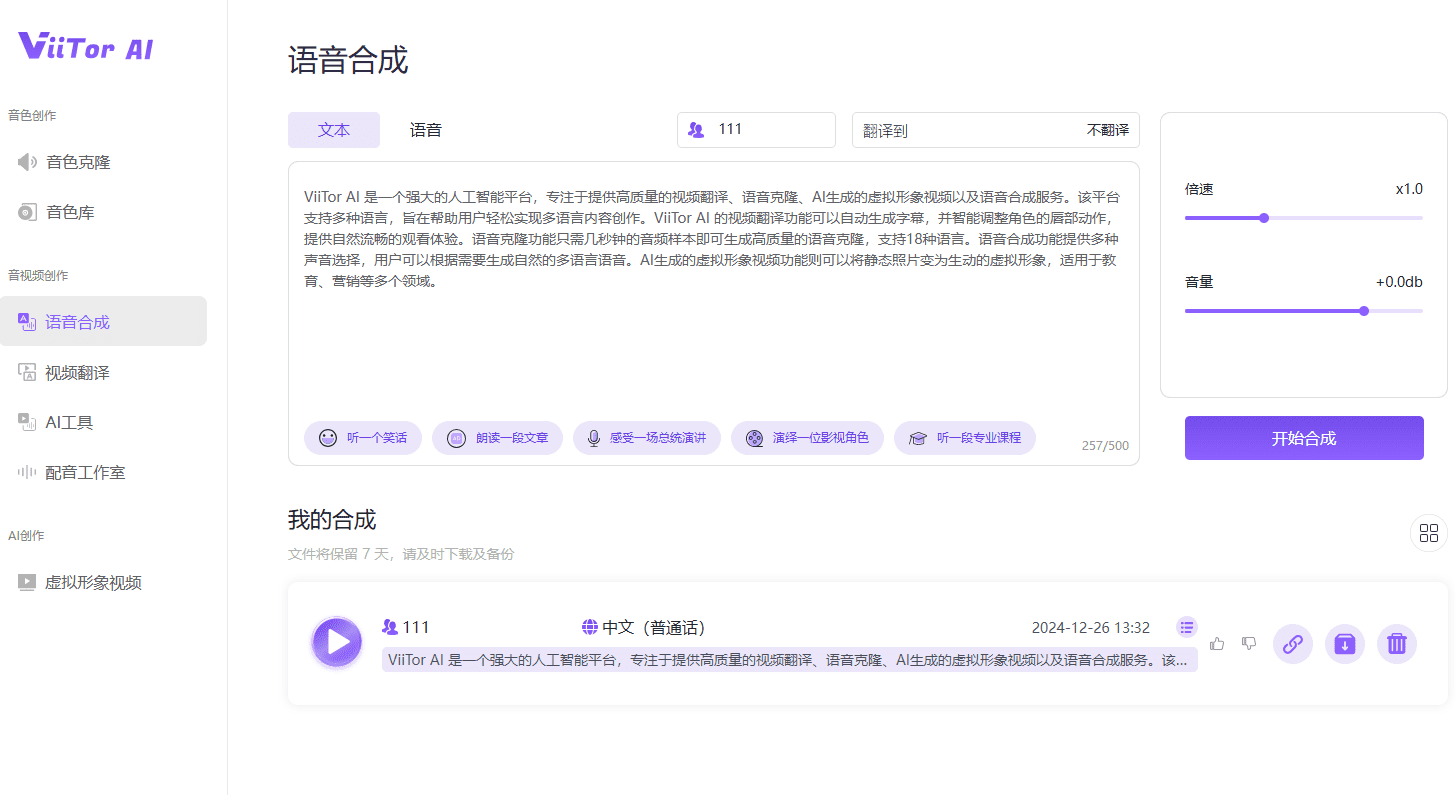
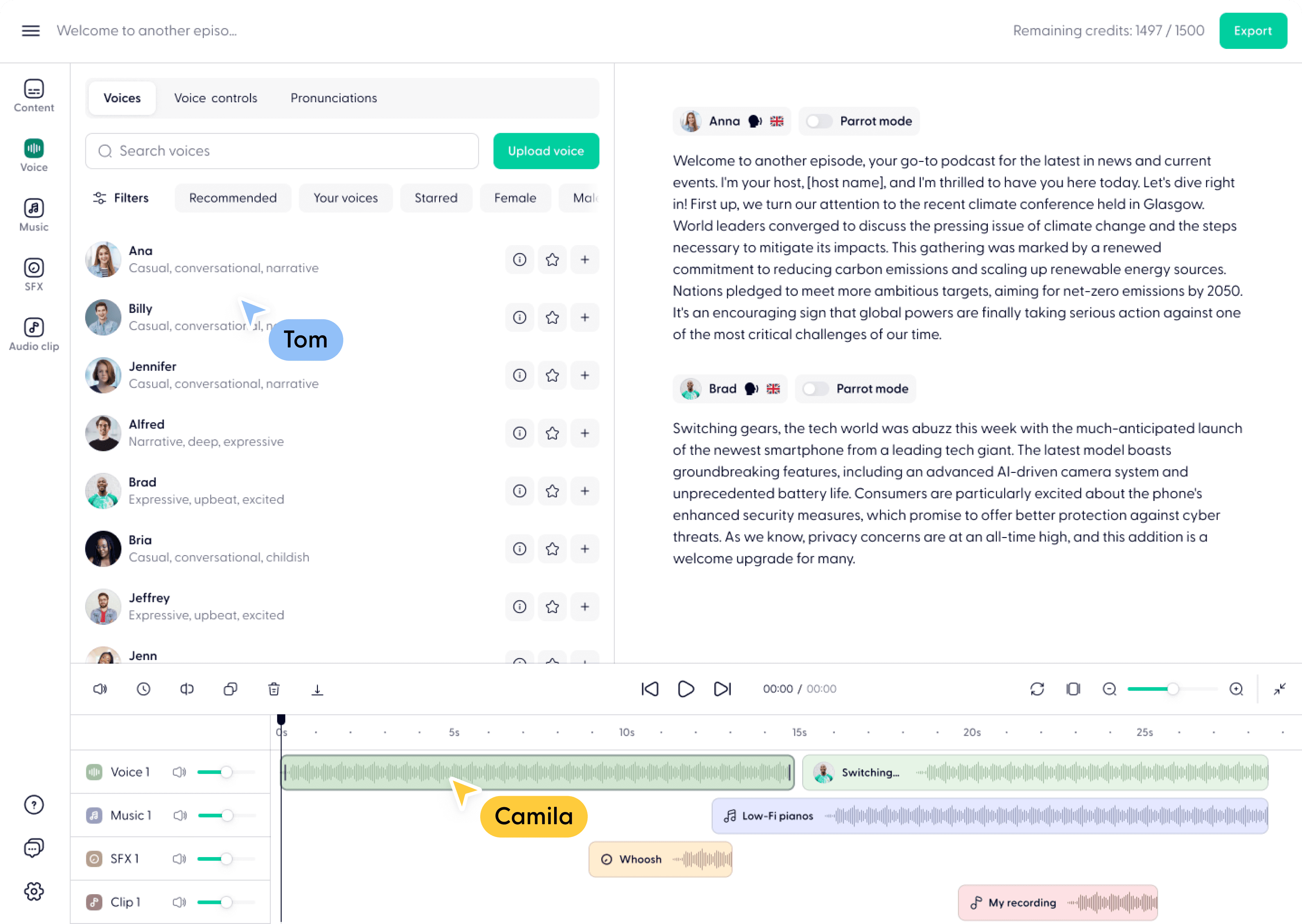
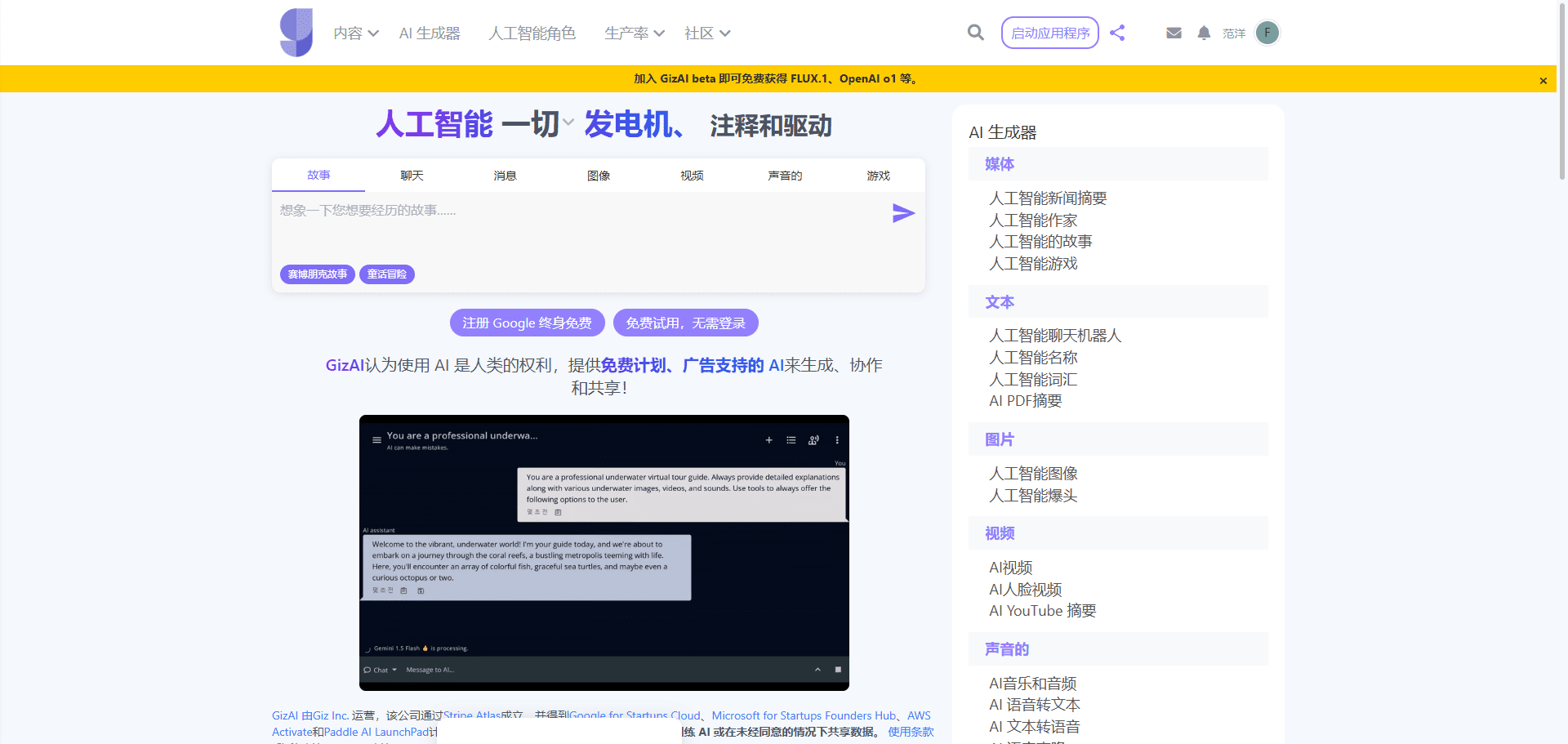
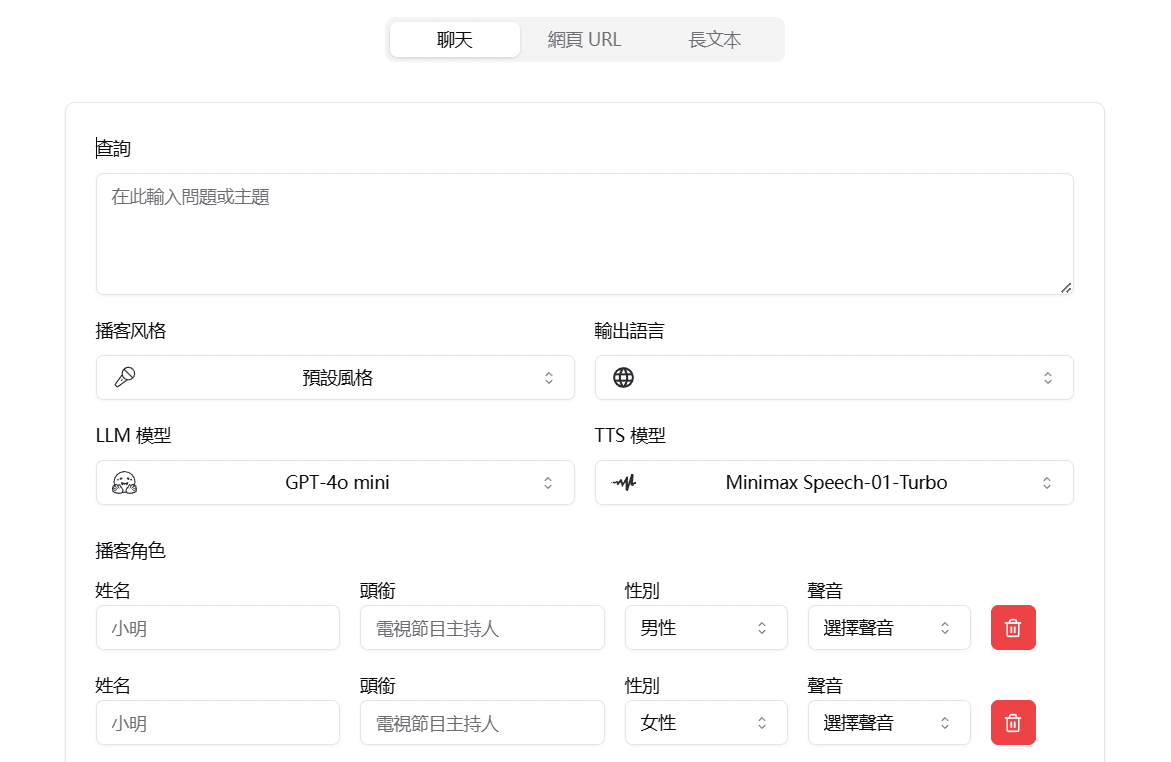
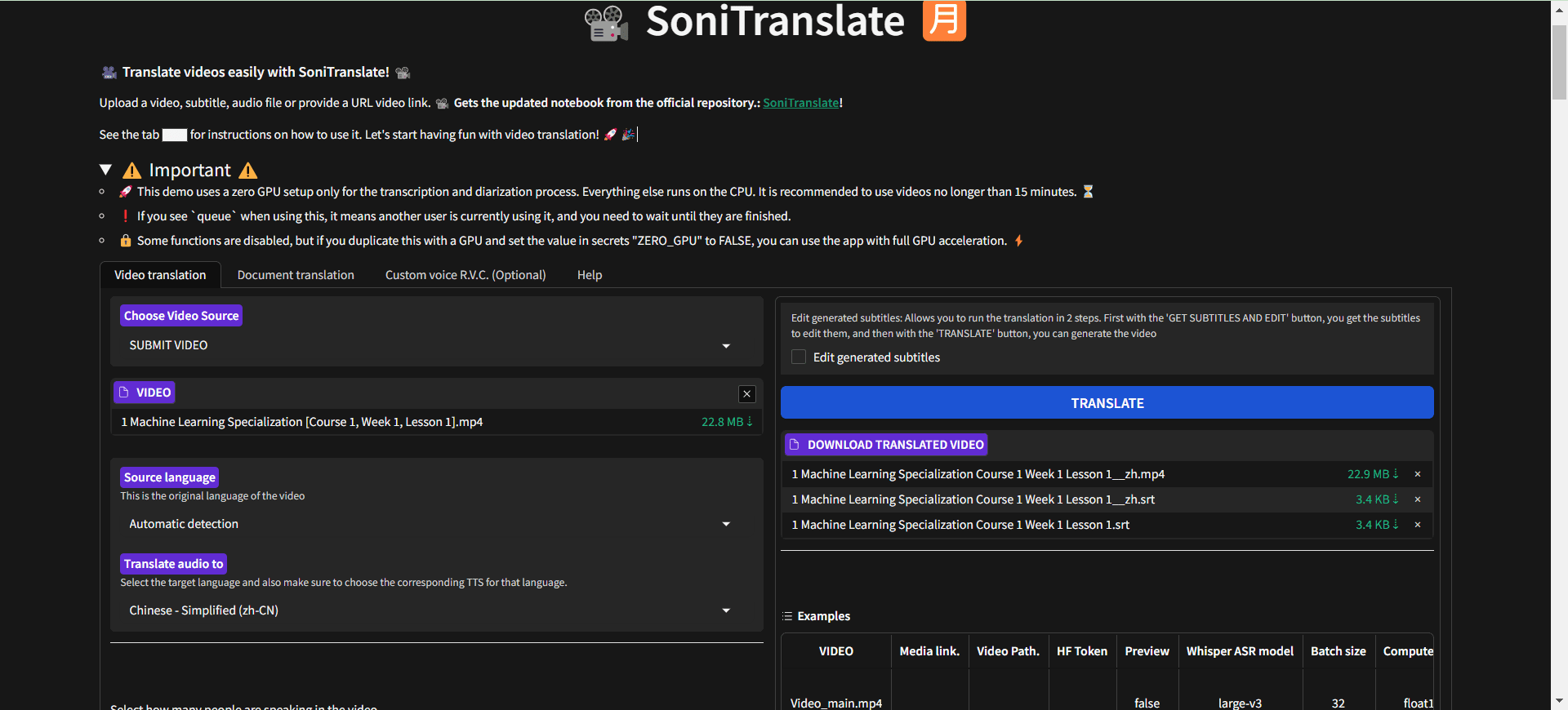
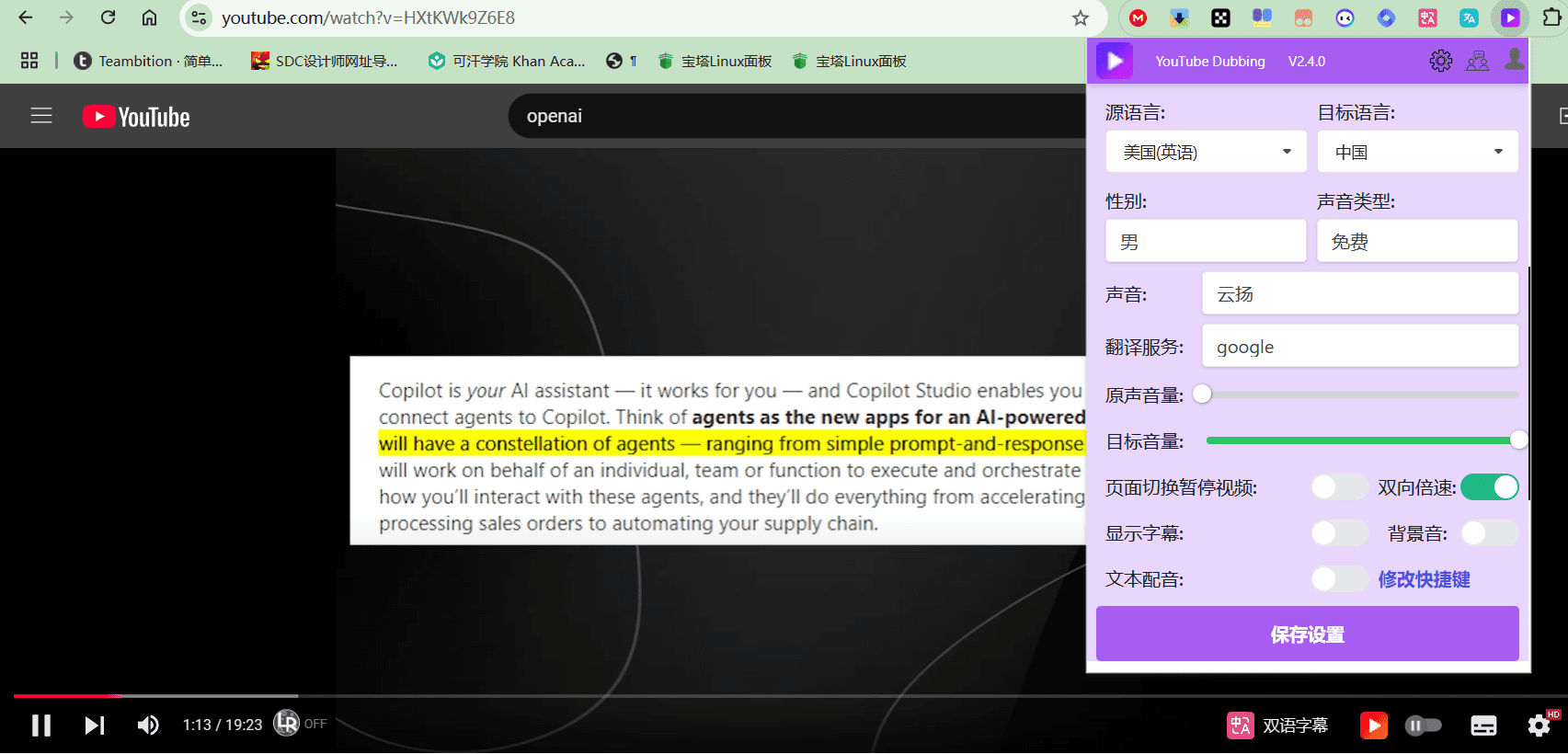
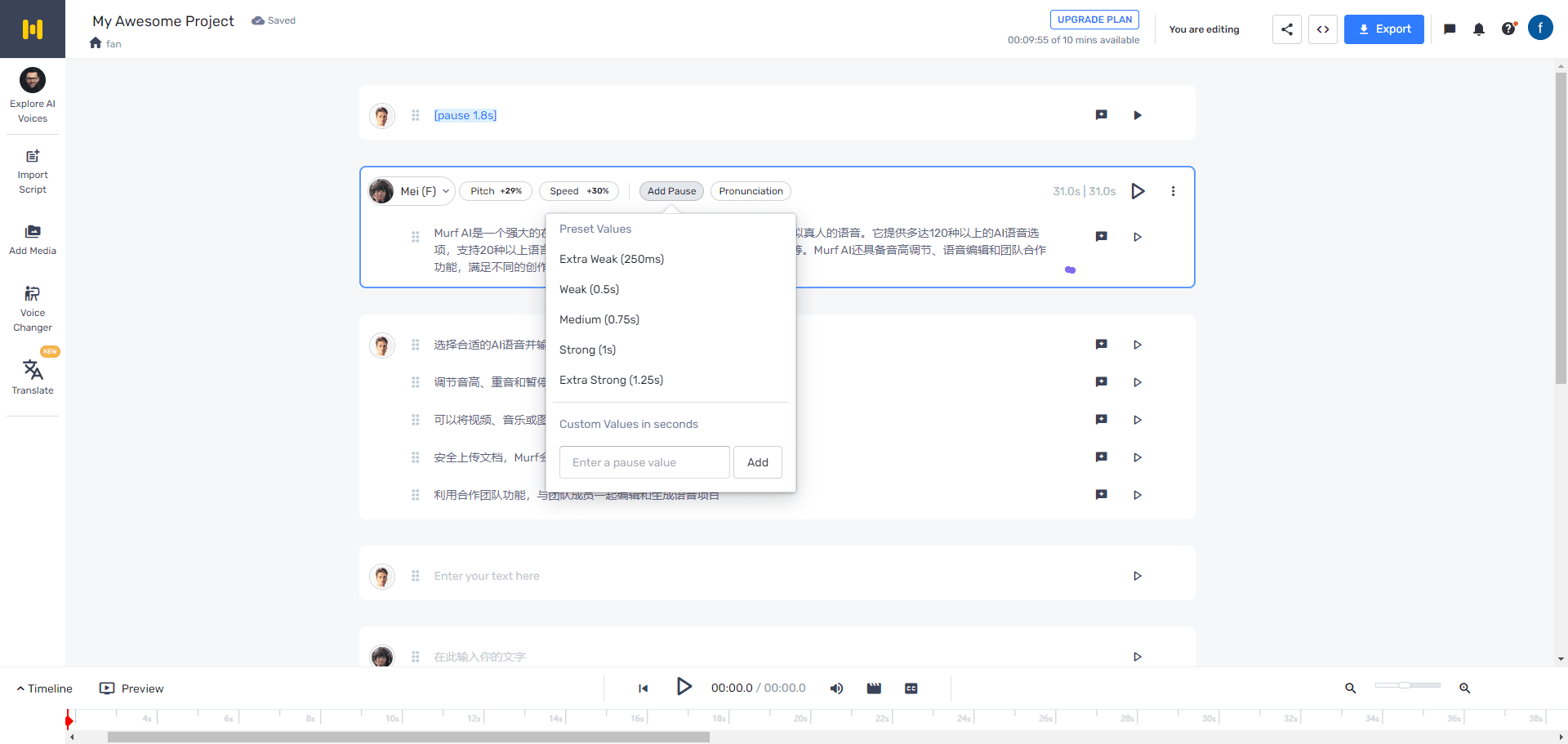
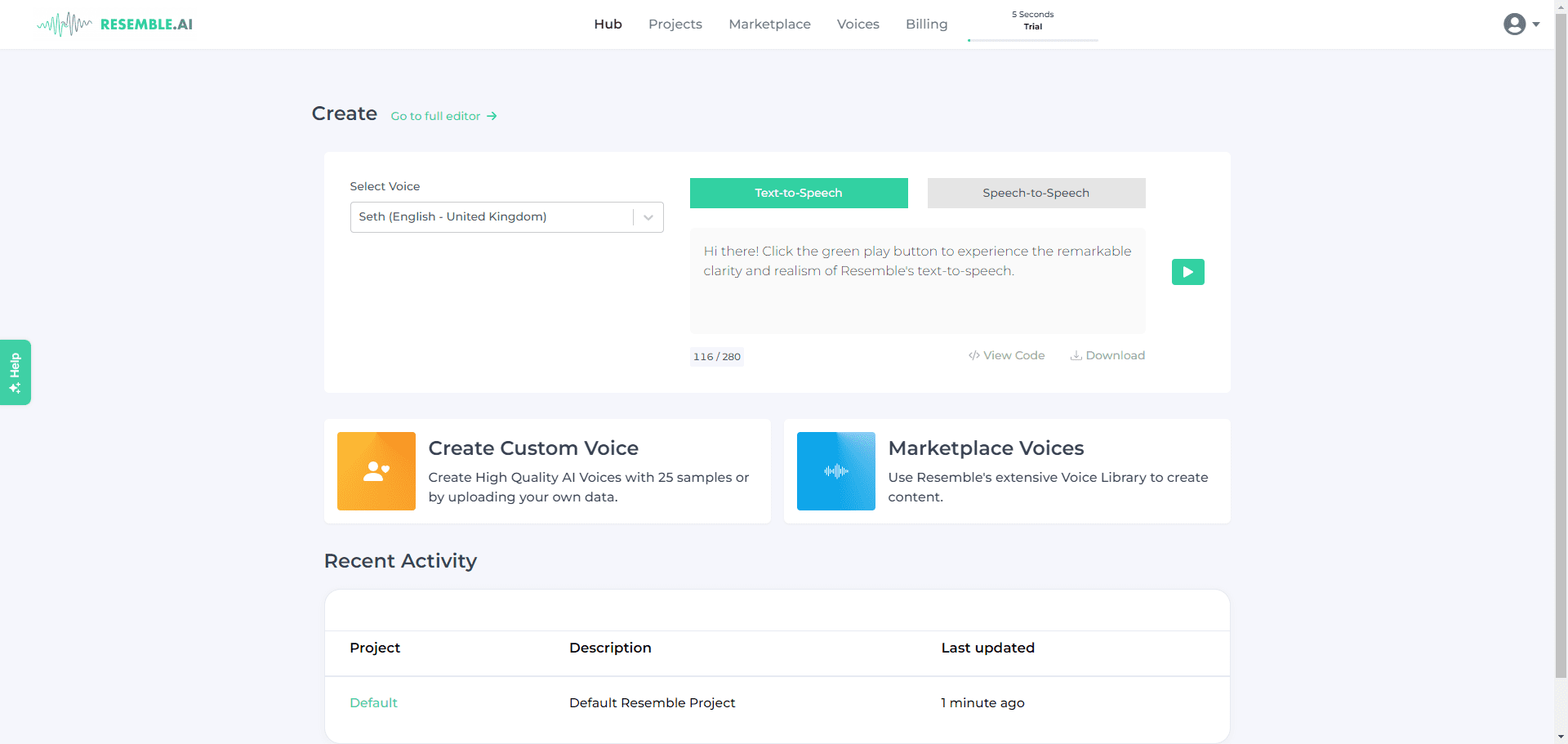
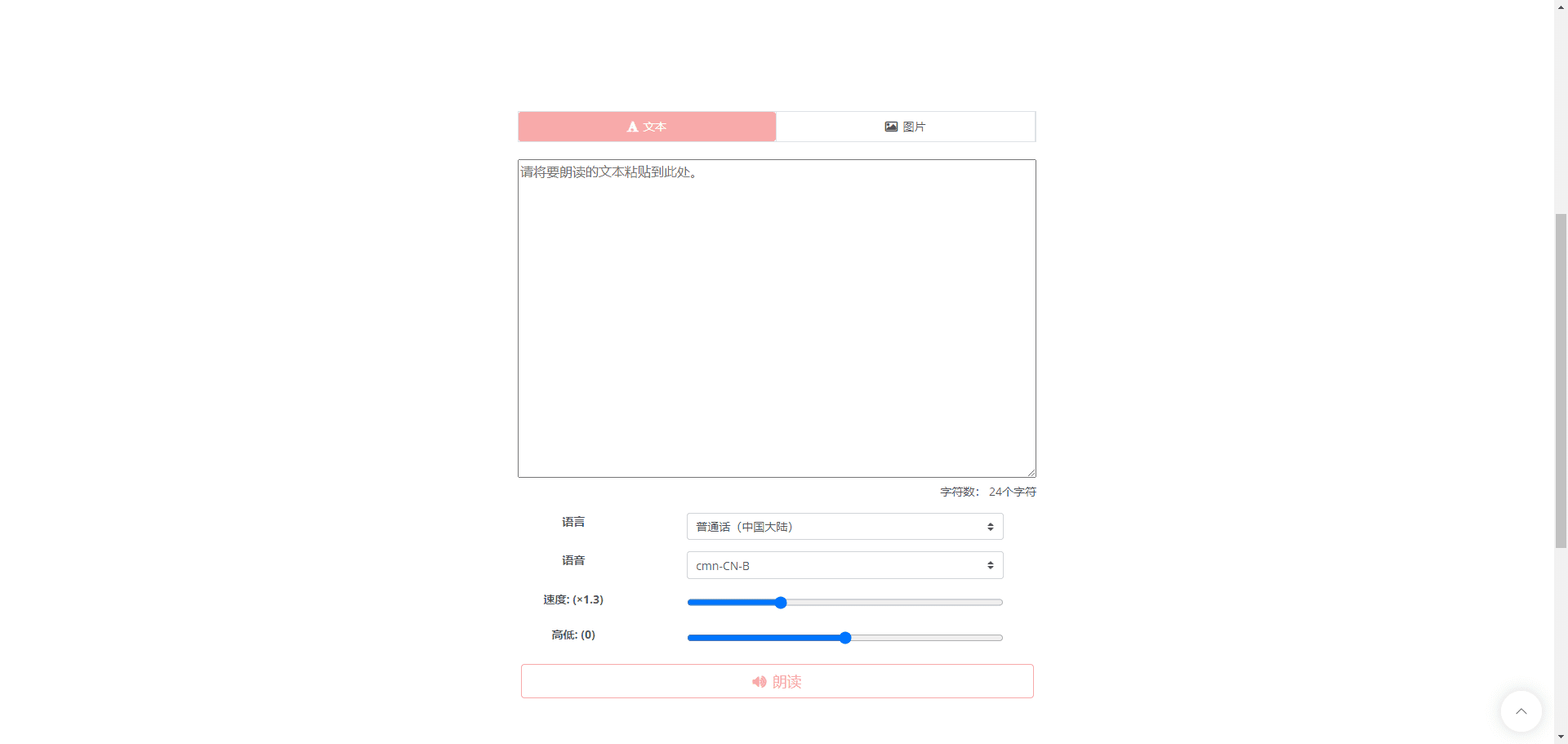
概要 Open NotebookLMは、あらゆるPDF文書をポッドキャストに変換するために設計されたオープンソースプロジェクトです。このツールは、オープンソースのLarge Language Model (LLM)とText-to-Speech (TTS)モデルを使用してPDFコンテンツを処理し、オーディオポッドキャストに適した自然なダイアログを生成します...
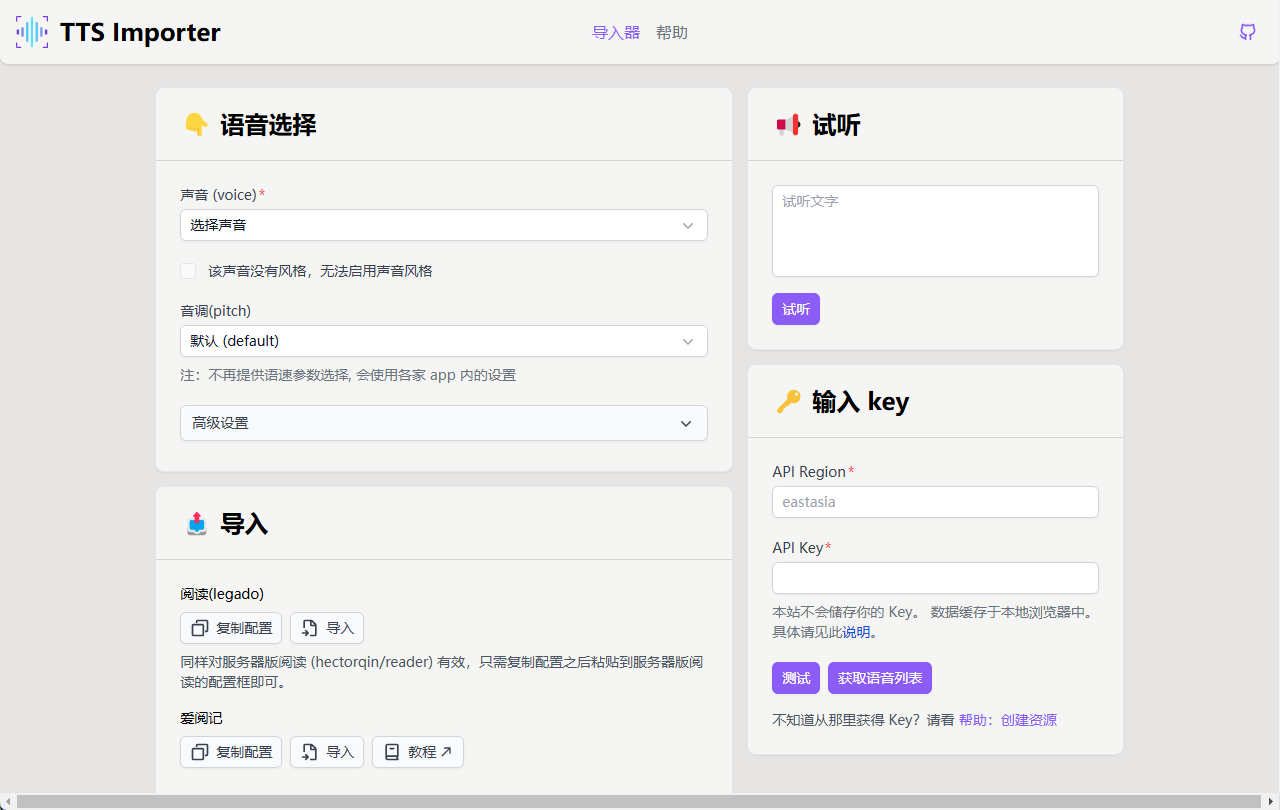
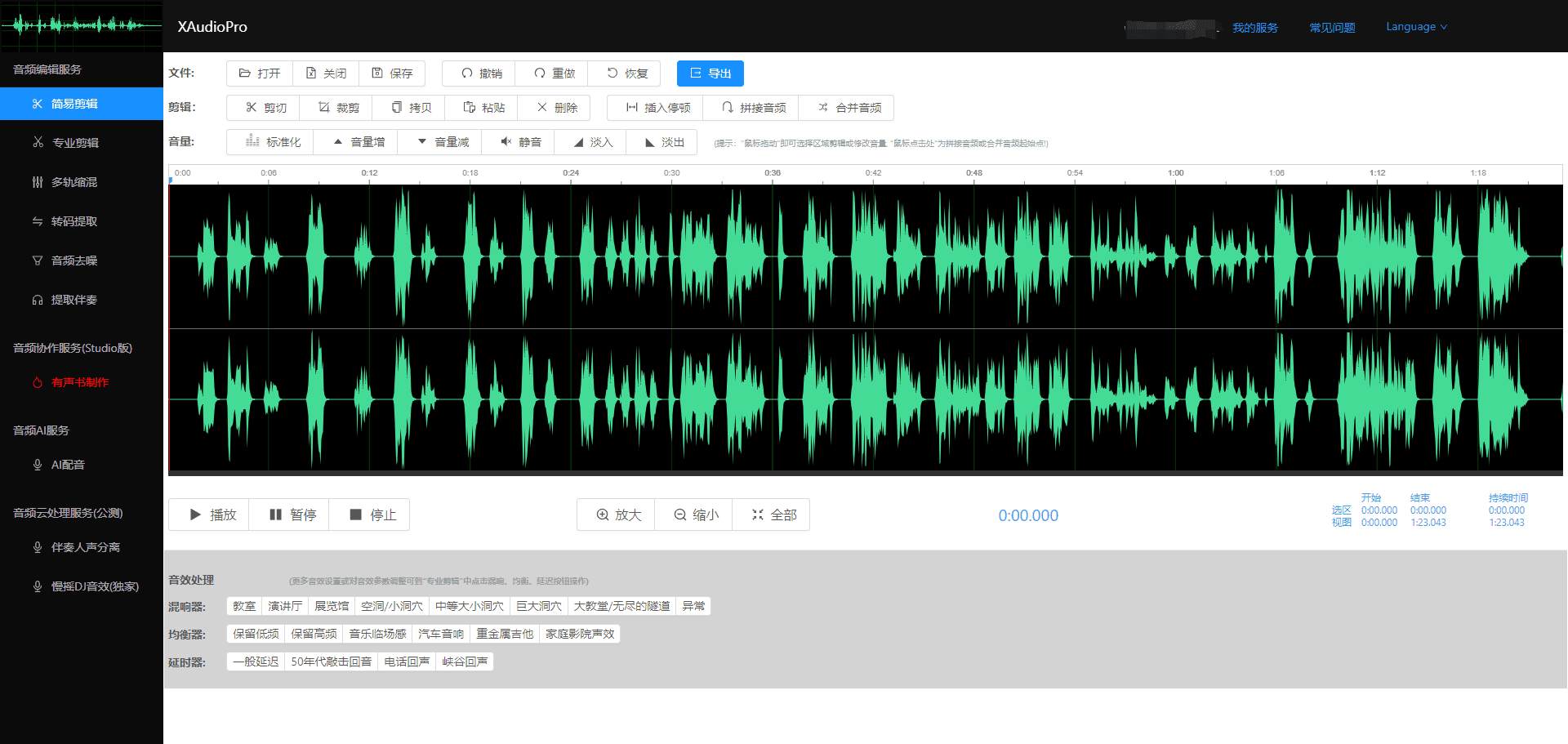
総合紹介 Record Cafeはワンストップの音声/動画処理プラットフォームで、AI動画対話、AI字幕、AI音声テキスト化サービスを提供する。画面録画、動画編集、GIF/音声変換などの機能があり、クラウドストレージや共有もサポートします。インターフェースは直感的で使いやすく、マルチスクリーン録画と多言語スマートフォンにも対応しています。