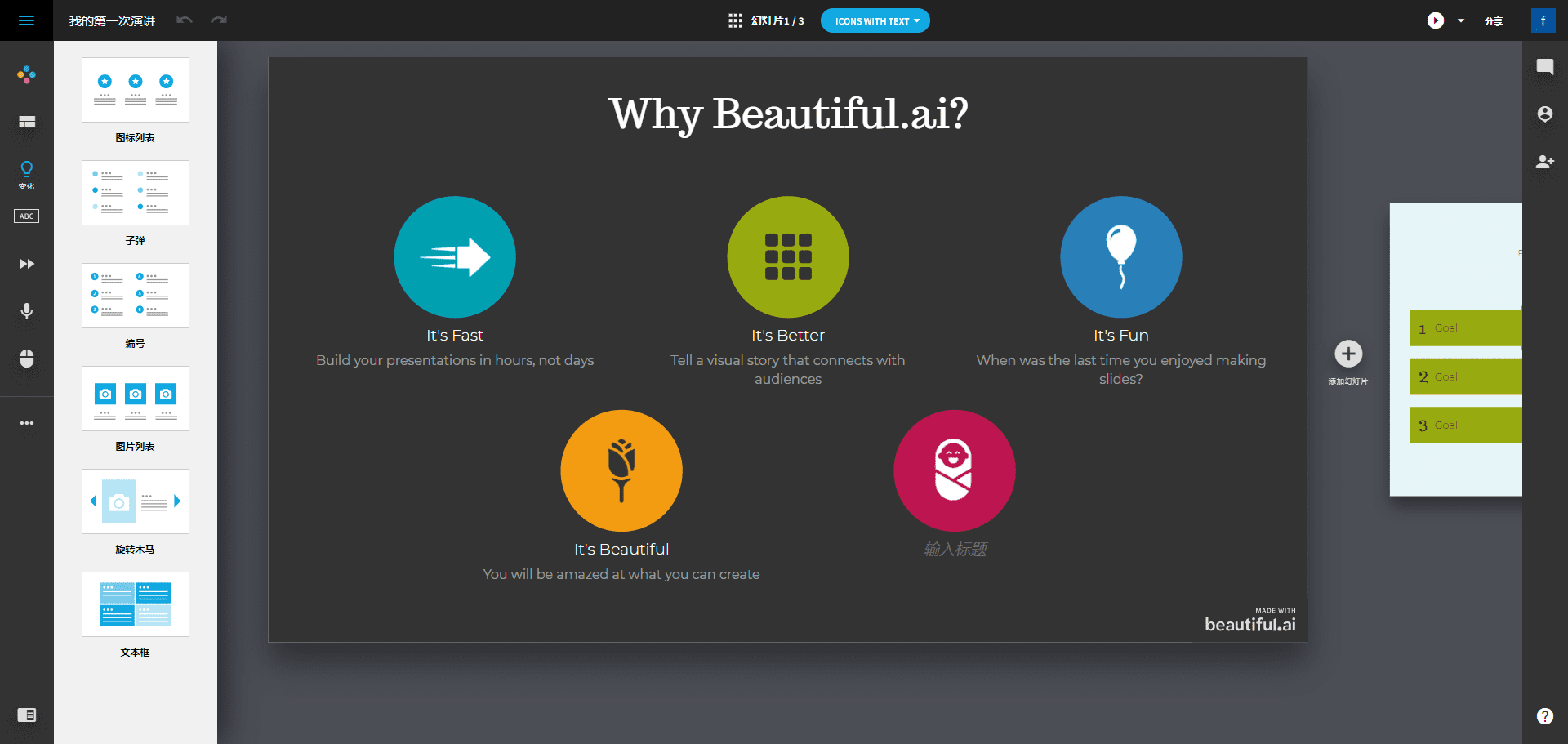
Story-Flicks:トピックを入力することで、子供向けのショートストーリービデオが自動生成される。

はじめに
Story-FlicksはオープンソースのAIツールで、ユーザーがHDストーリービデオを素早く生成できるようにすることに重点を置いています。ユーザーはストーリーのトピックを入力するだけで、システムは大規模な言語モデルを通じてストーリーのコンテンツを生成し、AIが生成した画像、音声、字幕と組み合わせて、完全なビデオ作品を出力します。このプロジェクトのバックエンドはPythonとFastAPIフレームワークに基づいており、フロントエンドはReact、Ant Design、Viteで構築されています。OpenAI、AliCloud、DeepSeekなどのモデルサービスプロバイダをサポートしており、ユーザーはテキストや画像の生成モデルを柔軟に選択できる。童話、短編アニメーション、教育用ビデオなど、Story-Flicksは開発者、クリエイター、教育者のニーズに簡単に応えることができる。

機能一覧
- ワンクリックでビデオを作成ストーリーのトピックを入力すると、画像、テキスト、音声、字幕を含むビデオが自動的に生成されます。
- マルチモデル対応OpenAI、Aliyun、DeepSeek、Ollamaと互換性があります。 シリコンフロー テキストと画像モデルの
- セグメントのカスタマイズユーザーはストーリーの段落数を指定でき、段落ごとに対応する画像が生成される。
- 多言語出力グローバルユーザー向けに、多言語でのテキストおよび音声生成をサポート。
- オープンソース展開手動インストールとDockerデプロイの両方を提供し、ローカルでの運用を容易にします。
- 直感的なインターフェースフロントエンドのページは使いやすく、パラメーターの選択とビデオのプレビューをサポートしています。
ヘルプの使用
設置プロセス
Story-Flicksは手動インストールとDockerデプロイの2つのインストール方法を提供しています。以下は、ユーザーがスムーズに環境を構築できるようにするための詳細な手順です。
1.手動インストール
ステップ1:プロジェクトのダウンロード
ターミナルで以下のコマンドを入力して、プロジェクトをローカルにクローンする:
git clone https://github.com/alecm20/story-flicks.git
ステップ2:モデル情報の設定
バックエンドのディレクトリに行き、環境設定ファイルをコピーする:
cd backend
cp .env.example .env
見せる .env ファイルでテキストと画像の生成モデルを設定します。例
text_provider="openai" # 文本生成服务商,可选 openai、aliyun、deepseek 等
image_provider="aliyun" # 图像生成服务商,可选 openai、aliyun 等
openai_api_key="你的OpenAI密钥" # OpenAI 的 API 密钥
aliyun_api_key="你的阿里云密钥" # 阿里云的 API 密钥
text_llm_model="gpt-4o" # 文本模型,如 gpt-4o
image_llm_model="flux-dev" # 图像模型,如 flux-dev
- OpenAIを選択する場合は、次のようにすることをお勧めします。
gpt-4oテキストモデルとして。dall-e-3イメージモデルとして。 - AliCloudを選択する場合は、以下の使用をお勧めします。
qwen-plusもしかしたらqwen-max(テキストモデリング)とflux-dev(イメージモデル、現在無料トライアル中。アリユン・ドキュメンテーション). - 設定が完了したらファイルを保存する。
ステップ3:バックエンドの起動
ターミナルでバックエンドディレクトリに移動し、仮想環境を作成し、依存関係をインストールする:
cd backend
conda create -n story-flicks python=3.10 # 创建 Python 3.10 环境
conda activate story-flicks # 激活环境
pip install -r requirements.txt # 安装依赖
uvicorn main:app --reload # 启动后端服务
起動に成功すると、端末にこう表示される:
INFO: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)
INFO: Application startup complete.
これは、バックエンド・サービスが http://127.0.0.1:8000.
ステップ4:フロントエンドの起動
新しいターミナルでフロントエンドのディレクトリに移動し、依存関係をインストールして実行する:
cd frontend
npm install # 安装前端依赖
npm run dev # 启动前端服务
起動に成功すると、端末にこう表示される:
VITE v6.0.7 ready in 199 ms
➜ Local: http://localhost:5173/
ブラウザからアクセス http://localhost:5173/フロントエンドのインターフェイスを見ることができる。
2.Dockerデプロイメント
ステップ1:環境を整える
DockerとDocker Composeがローカルにインストールされていることを確認し、インストールされていない場合は公式サイトからダウンロードする。
ステップ2:プロジェクトの開始
プロジェクトのルート・ディレクトリで実行する:
docker-compose up --build
Dockerは自動的にフロントエンドとバックエンドのサービスをビルドして起動する。完了したら http://localhost:5173/ フロントエンドのページを見る。
使用方法
インストール後、ユーザーはフロントエンドのインターフェイスからストーリービデオを生成することができます。具体的な操作の流れは以下の通り:
1.フロントエンド・インターフェースへのアクセス
ブラウザに入力 http://localhost:5173/Story-Flicksのメインページが開きます。
2.発電パラメーターの設定
このインターフェイスには以下のオプションがある:
- テキスト生成モデル・プロバイダーセレクション
openaiそしてaliyunその他 - 画像生成モデル・プロバイダーセレクション
openaiそしてaliyunその他 - テキストモデルモデル名を入力してください。
gpt-4oもしかしたらqwen-plus. - イメージモデリングモデル名を入力してください。
flux-devもしかしたらdall-e-3. - ビデオ言語中国語や英語など、言語を選択してください。
- 声のタイプ男性、女性など、オーディオのスタイルを選択します。
- トピックス例:「ウサギとキツネの冒険」。
- ストーリーの段落数各セグメントが画像に対応するように、数字(例えば3)を入力します。
3.ビデオ生成
パラメータを入力した後、「生成」ボタンをクリックしてください。システムは設定に従ってビデオを生成します。生成時間は段落数に関係し、段落数が多いほど時間がかかります。完成したら、ビデオはページに表示され、再生とダウンロードをサポートします。
ほら
- 生成に失敗した場合は
.envファイルに正しいAPIキーを入力するか、ネットワーク接続が機能していることを確認してください。 - 利用する オーラマ 設定時
ollama_api_key="ollama"おすすめqwen2.5:14bまたはそれ以上のモデルでは、小型のモデルではうまく動作しない場合があります。 - SiliconFlowのイメージモデルはまだテストされていない。
black-forest-labs/FLUX.1-dev対応機種をお選びください。
注目の機能操作
ワンクリックでフルビデオを生成
インターフェイスで「オオカミとウサギの物語」と入力し、3つの段落を設定して「生成」をクリックします。数分後、3つの画像、ナレーション、字幕が入ったビデオが出来上がります。例えば、公式デモビデオでは、「ウサギとキツネ」と「オオカミとウサギ」の物語が紹介されています。
多言語サポート
英語のビデオを作成したいですか?ビデオ言語」を「英語」に設定すれば、システムは英語のテキスト、音声、字幕を生成します。他の言語への切り替えも簡単です。
カスタム・セグメンテーション
長いストーリーが必要ですか?段落数を5以上に設定してください。段落ごとに新しい画像が生成され、それに応じてストーリーが展開します。
以上の手順で、Story-Flicksを簡単にインストールして使用し、HDストーリーテリングビデオを素早く作成することができます。個人的な娯楽であれ、教育目的であれ、このツールはクリエイティブな作業に役立ちます!
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事


コメントはありません