Step-Audio-AQAA - StepFunのエンドツーエンド・ビッグオーディオ言語モデル

Step-Audio-AQAAとは?
Step-Audio-AQAAは、StepFunチームによる、音声クエリ・オーディオアンサー(AQAA)タスクのためのエンドツーエンドの大規模音声言語モデルです。従来の自動音声認識(ASR)や音声合成(TTS)モジュールに頼ることなく、音声入力を直接処理して自然で正確な音声応答を生成できるため、システム・アーキテクチャが簡素化され、連鎖的なエラーがなくなります。Step-Audio-AQAAの学習プロセスには、マルチモーダル事前学習、教師あり微調整(SFT)、直接選好最適化(DPO)、モデル・マージが含まれます。これらの手法により、発話感情制御、ロールプレイング、論理的推論などの複雑なタスクにおいて、モデルが優れた性能を発揮します。StepEval-Audio-360ベンチマークにおいて、Step-Audio-AQAAは、いくつかの主要な次元において既存のLALMモデルを凌駕し、エンドツーエンドの音声対話のための強力な可能性を示しています。
Step-Audio-AQAA 主な特長
- オーディオ入力の直接処理従来の自動音声認識(ASR)や音声合成(TTS)モジュールに頼ることなく、生の音声入力から直接音声応答を生成します。
- シームレスな音声対話音声読み上げインタラクションをサポートすることで、ユーザーは声で質問し、モデルは直接声で答えることができ、インタラクションの自然さとスムーズさが向上します。
- 感情のトーン調整例えば、嬉しさ、悲しさ、深刻さなどの感情を表現するために、文のレベルでスピーチの感情的なトーンを調整することができます。
- スピーチコントロールユーザーは必要に応じて音声応答のスピードを調整し、シナリオのニーズに合ったものにすることができます。
- トーン&ピッチ・コントロール声のトーンやピッチをユーザーのコマンドに応じて調整し、さまざまな役割やシーンに適応させることができます。
- 多言語インタラクション中国語、英語、日本語、その他の言語をサポートし、様々なユーザーの言語ニーズを満たします。
- 方言サポート四川語や広東語などの中国語の方言をカバーし、特定地域でのモデルの適用性を高める。
- 音声による感情コントロールコンテクストとユーザーコマンドに基づいて、特定の感情を持つ音声応答を生成することができます。
- ロールプレイング接客、教師、友人など、対話の中で特定の役割を演じ、その役割の特徴に合った音声応答を生成することをサポートする。
- 論理的推論と知識クイズ複雑な論理的推論タスクや知識クイズに対応し、正確な音声応答を生成。
- 高品質の音声出力高忠実度、自然で滑らかな音声波形をニューラルボコーダで生成し、ユーザーエクスペリエンスを向上させます。
- おんせいごつれん長い文章や段落を作成する際、話の切れ目や突然の変化を避け、一貫性と一貫性を保つ。
- テキストと音声のインターリーブ出力テキストと音声のインターリーブ出力をサポートし、ユーザーは必要に応じて音声またはテキストの応答を選択できます。
- マルチモーダル入力の理解音声とテキストが混在した入力を理解し、適切な音声応答を返すことができる。
Step-Audio-AQAAプロジェクトアドレス
- HuggingFaceモデルライブラリ:: https://huggingface.co/stepfun-ai/Step-Audio-AQAA
- arXivテクニカルペーパー:: https://arxiv.org/pdf/2506.08967
ステップ・オーディオの技術原理-AQAA
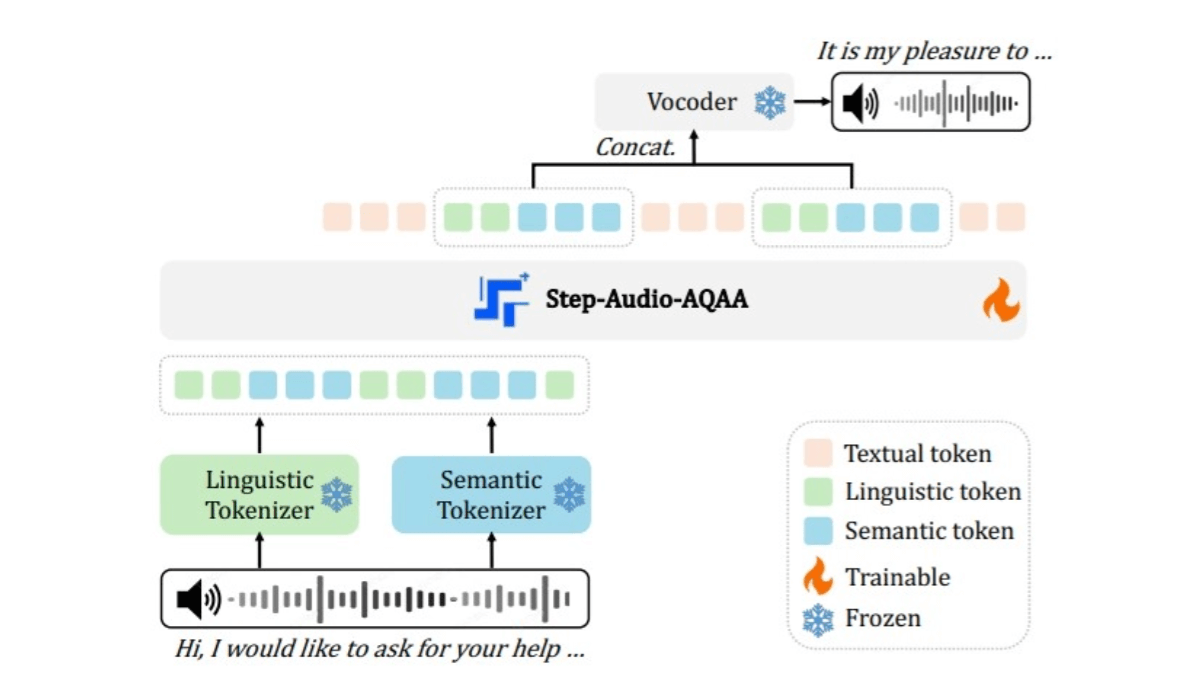
- デュアル・コードブック・オーディオ・スプリッター入力音声信号をトークンの構造化シーケンスに変換します。言語レクサーは16.7 Hzでサンプリングされ、コードブックのサイズは1024です。セマンティックレクサーは25 Hzでサンプリングされ、コードブックのサイズは4096です。
- バックボーンLLM事前学習された1300億パラメータのマルチモーダルLLM(Step-Omni)を使用し、事前学習データはテキスト、音声、画像の3つのモダリティをカバーする。バイコードテキストの音声トークンは、複数のLLMによって一様なベクトル空間に埋め込まれる。 変圧器 深い意味理解と特徴抽出のためのブロック。
- ニューラルボコーダ生成された音声トークンを自然で高品質な音声波形に合成します。U-NetアーキテクチャとResNet-1Dレイヤー、トランスフォーマーブロックを組み合わせることで、離散的な音声トークンを連続的な音声波形に効率的に変換します。
Step-Audio-AQAAの主な特典
- エンド・ツー・エンドのオーディオ・インタラクションStep-Audio-AQAAは、生の音声入力から自然で滑らかな音声応答を直接生成するため、従来の自動音声認識(ASR)や音声合成(TTS)モジュールに頼る必要がありません。エンド・ツー・エンドの設計により、従来のソリューションにおけるASRやTTSのエラーによる結果の歪みを回避します。
- 多言語サポート中国語(四川語、広東語を含む)、英語、日本語などの多言語をサポートしており、さまざまなユーザーの言語ニーズを満たすことができます。
- きめ細かな音声機能コントロールStep-Audio-AQAAは、感情のイントネーションや発話速度など、きめ細かな音声特徴制御を可能にし、より応答性の高い音声応答を生成します。特に感情制御を得意としています。
Step-Audio-AQAAは誰のためのものですか?
- インテリジェント音声アシスタント・ユーザー音声対話デバイス(スマートスピーカー、スマートアシスタントなど)を日常的な操作(情報の確認、リマインダーの設定、音楽の再生など)に使用したいユーザー。
- ゲームマニアより没入感のあるゲーム体験のために、ゲーム内のNPCと交流したいゲーマー。
- 教育ユーザー音声対話による学習(語学学習、知識クイズなど)を希望する生徒や保護者。
- 高齢者と子供音声対話は、文字入力が苦手なユーザーにとって、より便利で自然なものです。
- オーディオブック・クリエーターオーディオブックやラジオドラマなど、高品質な音声コンテンツを必要とするクリエイター。
- ビデオプロデューサービデオコンテンツ(ショートビデオ、ライブストリームなど)を制作する際に、音声対話や音声生成機能を必要とするクリエイター。
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事

コメントはありません