スタンドイン - Tencent WeChat Visualオープンソース軽量動画生成フレームワーク

スタンドインとは?
Stand-Inは、テンセントのWeChat Visionチームが開発した、軽量でプラグアンドプレイのID保持ビデオ生成フレームワークです。Stand-Inは、アイデンティティを保持したテキストからビデオへの生成、非人間的な被写体のビデオ生成、様式化されたビデオ生成、顔切り替えビデオ、ポーズガイド付きビデオ生成など、様々なアプリケーションシナリオをサポートしています。このフレームワークは、効率的に学習され、忠実度が高く、プラグアンドプレイが可能で、拡張性が高く、LoRAのようなコミュニティモデルと互換性があり、様々な下流のビデオタスクをサポートします。
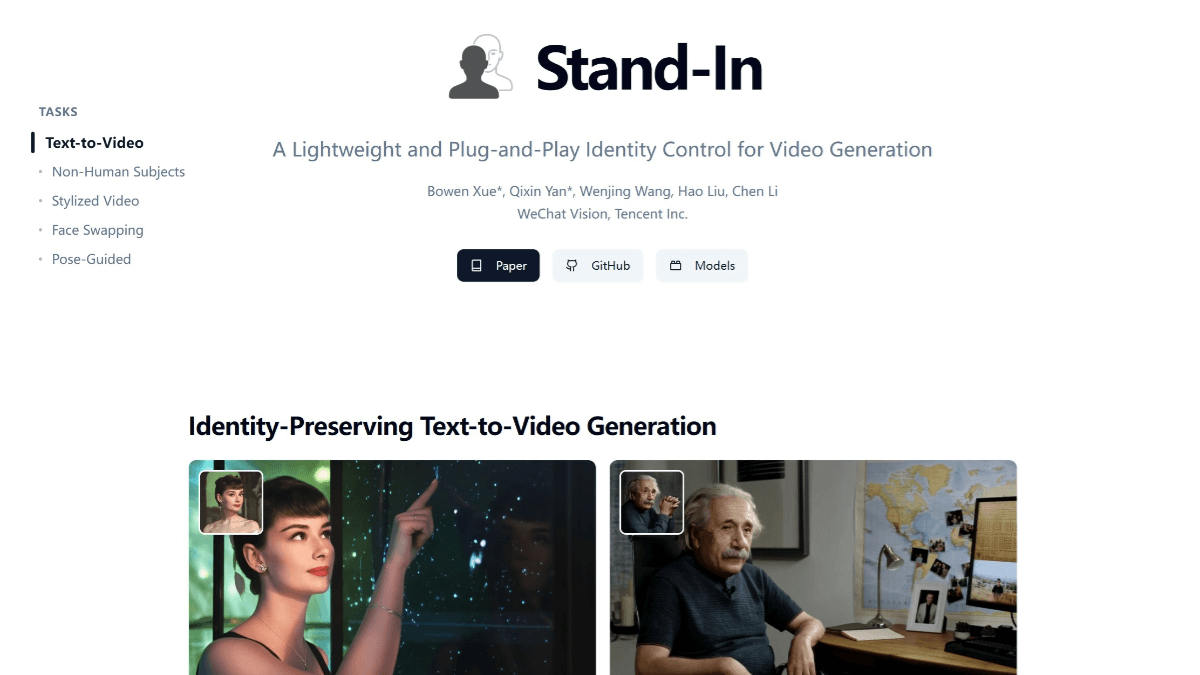
スタンドインの機能
- 効率的なトレーニングベースモデル1%の追加パラメータのみを学習すればよいため、他の手法に比べて学習コストが大幅に削減されます。
- ハイフィデリティ顔の類似性と映像の自然さにおいて優れた性能を発揮し、映像品質を犠牲にすることなく、アイデンティティを効果的に保持します。
- プラグアンドプレイ複雑な調整をすることなく、既存のT2V(Text-to-Video)モデルに簡単に統合することができます。
- 高い拡張性LoRAのようなコミュニティモデルと互換性があり、定型化されたビデオ生成、ビデオフェイススワッピングなど、さまざまなダウンストリームビデオタスクをサポートします。
- 多様なアプリケーション・シナリオID保持のためのテキストからビデオへの生成、人間以外の被験者のためのビデオ生成、ポーズガイド付きビデオ生成など、さまざまなアプリケーションシナリオをサポートしています。
スタンドインの強み
- 効率ベースモデル1%の追加パラメータのみをトレーニングする必要があるため、トレーニングのコストと時間を大幅に削減できます。
- ハイフィデリティ顔の類似性と映像の自然さに優れ、映像生成の品質を確保しながら、アイデンティティーの特徴を正確に保持します。
- 統合の容易さプラグ・アンド・プレイで、複雑な調整をすることなく、既存のテキスト・トゥ・ビデオ(T2V)モデルにシームレスに統合できます。
- 互換性LoRAのようなコミュニティモデルとの互換性が高く、複数のダウンストリーム映像タスクをサポートし、拡張性が高い。
- 豊富なアプリケーションシナリオアイデンティティ保持のためのテキストからビデオへの生成、人間以外の被験者のためのビデオ生成、様式化されたビデオ生成、ビデオフェイススワッピング、ポーズガイド付きビデオ生成など、幅広いシナリオをカバーしています。
スタンドインの公式ウェブサイトは?
- プロジェクトのウェブサイト:: https://www.stand-in.tech/
- GitHubリポジトリ:: https://github.com/WeChatCV/Stand-In
- HuggingFaceモデルライブラリ:: https://huggingface.co/BowenXue/Stand-In
- arXivテクニカルペーパー:: https://arxiv.org/pdf/2508.07901
スタンドインの対象者
- 動画コンテンツ制作者Stand-Inを使って、高品質でパーソナライズされたビデオコンテンツを素早く作成することで、撮影やポストプロダクションにかかる時間とコストを節約できます。
- 映画とテレビの特殊効果プロデューサーStand-Inは、IDの置き換えや特殊効果の合成が必要な場合に、効率的で自然なID保持ビデオ生成を提供し、制作効率を高めます。
- 広告・マーケティング担当者ターゲットとなる視聴者に似た人々のビデオを生成することで、より親近感と説得力のある、より魅力的で的を絞った広告ビデオを作成することができる。
- ゲーム開発者ゲームプレイアニメーションやビデオプロモーションにおいて、スタンドインを使用することで、ゲームキャラクターのアイデンティティにマッチしたビデオコンテンツを素早く生成し、ゲームへの没入感を高めることができます。
- 研究者と教育者研究プロジェクトや教育用ビデオ制作では、教育支援や研究成果の発表のために、IDに特化したデモビデオを生成するために使用することができます。
- ソーシャルメディア運営者ブランドのイメージや特定のテーマに合った動画コンテンツを素早く作成し、ソーシャルメディア上でプロモーションやユーザーとの交流を図ることができます。
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事


コメントはありません