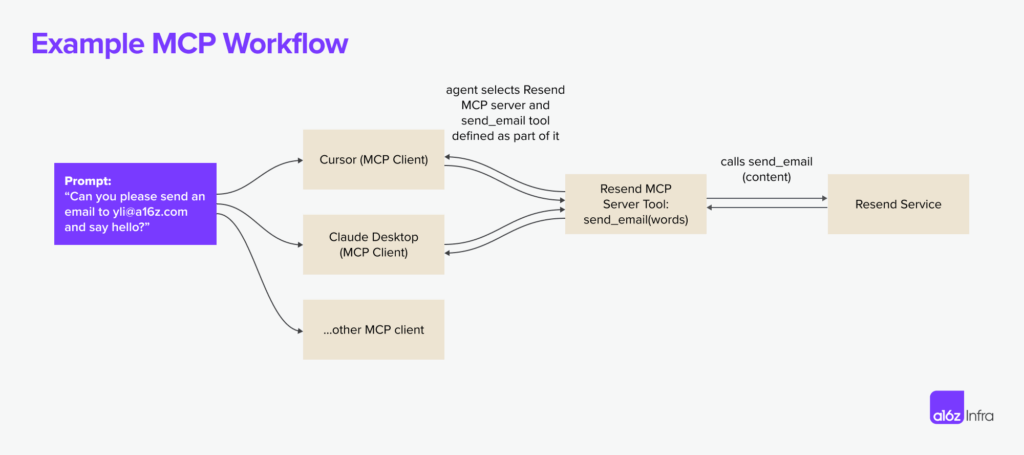
シリコンクラウド、CosyVoice2の高速化を発表:150msのリアルタイム音声合成、混合言語と方言のサポート


最近、アリ・トンイ研究所の音声チームが音声合成モデルを正式に発表した。コージーボイス2.このモデルは、テキストと音声の双方向ストリーミングをサポートし、多言語、混合言語、方言をサポートし、より正確で安定した、より高速で優れた音声生成機能を提供します。現在、シリコンベースのフローであるSiliconcloudは、推論アクセラレーションバージョンのCosyVoice2-0.5B(価格105円/M UTF-8バイト、各文字は1~4バイトを占有)を正式にオンライン化し、ネットワーク伝送時間を含むため、モデルの出力レイテンシを150msと低くし、生成AIアプリケーションにより効率的なユーザーエクスペリエンスをもたらします。SiliconCloud上の他の言語合成モデルと同様に、CosyVoice2は8つのプリセットトーン、ユーザープリセットトーン、ダイナミックトーン、カスタマイズ可能なスピーチレート、オーディオゲイン、出力サンプルレートをサポートします。
オンライン体験
https://cloud.siliconflow.cn/playground/text-to-speech/17885302679
APIドキュメント
https://docs.siliconflow.cn/api-reference/audio/create-speech
SiliconCloudの推論アクセラレータ版CosyVoice 2.0をお試しください。
シリコンクラウドが以前からライブで行っているアリ音声認識モデル SenseVoice-Small(無料で利用可能)モデルAPIの助けを借りて、開発者はオーディオブック、ストリーミング音声出力、バーチャルアシスタント、その他のアプリケーションを含むエンドツーエンドの音声対話アプリケーションを効率的に開発することができる。
モデルの特徴と性能
コージーボイス2 は、統一されたストリーミング/非ストリーミングフレームワークを用いて設計された、大規模な言語モデルに基づくストリーミング音声合成モデルである。このモデルは、FSQ(Finite Scalar Quantisation)により音声トークンのコードブック利用を改善し、音声合成言語モデルアーキテクチャを簡素化し、異なる合成シナリオをサポートするチャンク認識因果ストリームマッチングモデルを開発する。ストリーミングモードでは、非ストリーミングモードとほぼ同じ合成品質を維持しながら、150msという超低遅延を達成した。
さらに、CosyVoice2はベースモデルとコマンドモデルの統合において大きな進歩を遂げ、感情、話し方、きめ細かな制御コマンドのサポートを継続するだけでなく、中国語のコマンドを扱う機能も追加した。CosyVoice2はまた、ロボットやPeppa Pigの話し方を模倣する機能など、ロールプレイング機能を導入した。
具体的には、バージョン2.0はCosyVoiceバージョン1.0に比べて次のような利点があります:
多言語サポート
- 対応言語:中国語、英語、日本語、韓国語、中国語方言(広東語、四川語、上海語、天津語、武漢語など)
- クロスランゲージ&ミックスランゲージ:クロスランゲージやコードスイッチングシナリオでのゼロサンプル音声クローニングをサポートします。
超低遅延
- 双方向ストリーミングのサポート:CosyVoice 2.0はオフラインとストリーミングのモデリング技術を統合。
- 高速ファーストパケット合成:高品質のオーディオ出力を維持しながら、150ミリ秒という低レイテンシーを実現。
高精度
- 発音の改善:CosyVoice 1.0と比較して、発音の誤りが30%から50%減少しました。
- ベンチマーク達成:Seed-TTS評価セットの難易度の高いテストセットにおいて、最も低い文字誤り率を達成する。
高い安定性
- トーンコンシステンシー:ゼロサンプルおよびクロスリンガル音声合成において、信頼性の高いトーンコンシステンシーを保証します。
- クロスランゲージ合成:バージョン1.0から大幅に改善。
自然な流暢さ
- リズムと音色の強化:MOS評価スコアが5.4から5.53に上昇。
- 感情と方言の柔軟性:より細かい感情のコントロールと方言アクセントの調整をサポート。
開発者評価
CosyVoice 2.0がリリースされると、一部の開発者はまずこれを体験した。超微細なコントロール機能をサポートし、よりリアルで自然な音声合成が可能になったという声も聞かれた。 
 しかし、その優れた音声生成性能に魅力を感じながらも、導入が大きな課題になったというユーザーもいる。
しかし、その優れた音声生成性能に魅力を感じながらも、導入が大きな課題になったというユーザーもいる。  現在、SiliconcloudはCosyVoice 2.0をリリースし、複雑なデプロイの必要性を排除している。
現在、SiliconcloudはCosyVoice 2.0をリリースし、複雑なデプロイの必要性を排除している。
東建ファクトリーSiliconCloud Qwen 2.5 (7B)と他の20以上のモデルを無料で!
V2.5-1210、mochi-1-preview、Llama-3.3-70B-Instruct、HunyuanVideo、fish-speech-1.5、QwQ-32B-Preview、Qwen2.5-Coder-32B-Instruct、InternVL2Qwen2.5-7B/14B/32B/72B、FLUX.1、InternLM2.5-20B-Chat、BCE、BGE、SenseVoice-Small、GLM-4-9B-Chat、および数十のオープンソースの大規模言語モデル、画像/ビデオ生成モデル、音声モデル、コード/数学モデル、ベクトル/並び替えモデル。および並べ替えモデル。 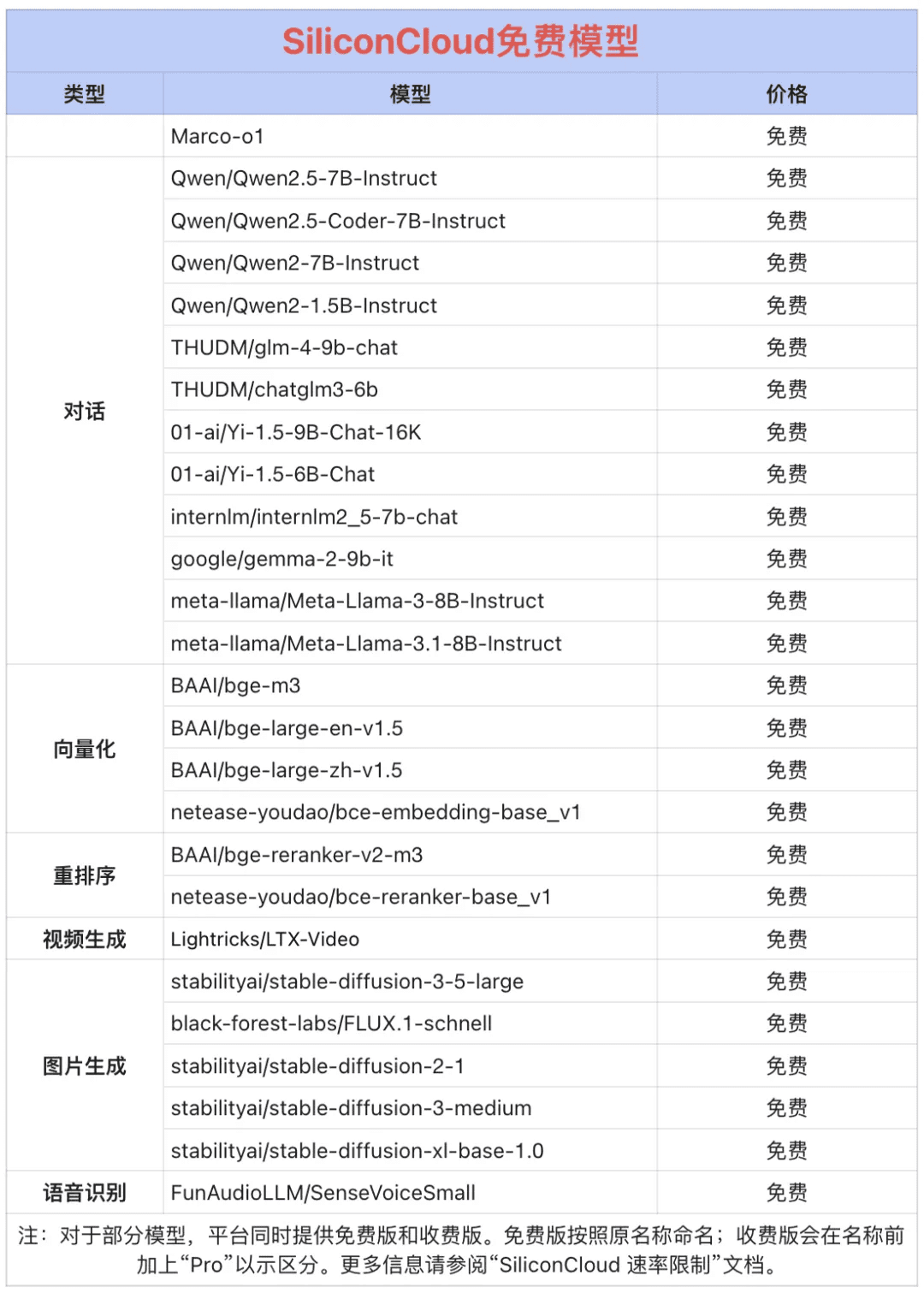 その中で、Qwen2.5(7B)、Llama3.1(8B)および他の20以上の大きなモデルのAPIは無料で使用することができますので、開発者や製品管理者は、「トークンの自由」を達成するために、R&D段階と大規模なプロモーションの演算コストを心配する必要はありません。
その中で、Qwen2.5(7B)、Llama3.1(8B)および他の20以上の大きなモデルのAPIは無料で使用することができますので、開発者や製品管理者は、「トークンの自由」を達成するために、R&D段階と大規模なプロモーションの演算コストを心配する必要はありません。
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事



コメントはありません