
最初の金融業界の推論ビッグモデルRegulus-FinX1オープンソース!杜小曼重生産、金融の複雑な分析と意思決定に焦点を当てる

杜暁曼、世界初の金融業界推論ビッグモデル「Regulus-FinX1」をオープンソース化!
このモデルは、革新的なGPT-O1のような推論マクロモデルである。"思考の連鎖+プロセス報酬+強化学習"このトレーニングパラダイムは、論理的推論を大幅に改善し、O1モデルでは開示されない完全な思考プロセスを実証することができ、財務上の意思決定に深い洞察を提供します。Regulus-FinX1のターゲット金融シナリオにおける分析、意思決定、データ処理業務深い最適化が行われた。
Xuan Yuan-FinX1はDu Xiaoman AI-Labによって開発され、このリリースはオープンソースコミュニティで公開されているプレビュー版です。無料ダウンロード.その後の最適化されたバージョンも、ダウンロードと使用のためにオープンソースで提供され続ける。
Githubアドレス:https://github.com/Duxiaoman-DI/XuanYuan
ベンチマーク結果
第一世代のRegulus-FinX1は、金融ベンチマークであるFinanceIQで優れたパフォーマンスを示した。また公認会計士、銀行資格証券資格など10種類の金融資格。アクチュアリーのカテゴリーでは、これまでの大型モデルのスコアが全般的に低いのに対して、XuanYuan-FinX1は37.5から65.7までスコアを伸ばしており、GPT-4oやオープンソースモデルQwen2.5-72Bを凌駕する能力があることが顕著に反映されている。特にアクチュアリー部門では、これまでの大型モデルは総じてスコアが低かったのに対し、XuanYuan-FinX1は37.5点から65.7点までスコアを伸ばし、金融論理推論と数学計算における優位性が顕著に示された。 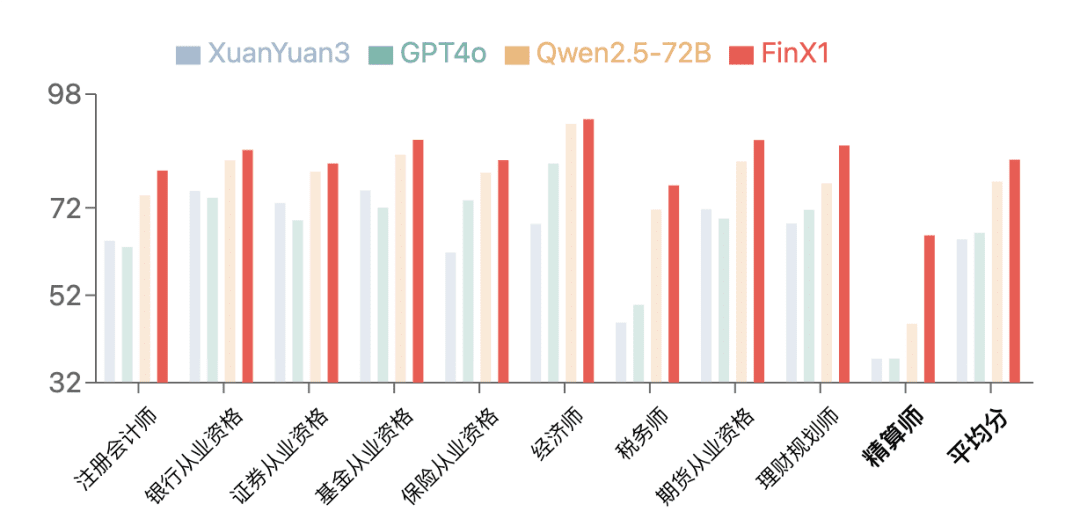
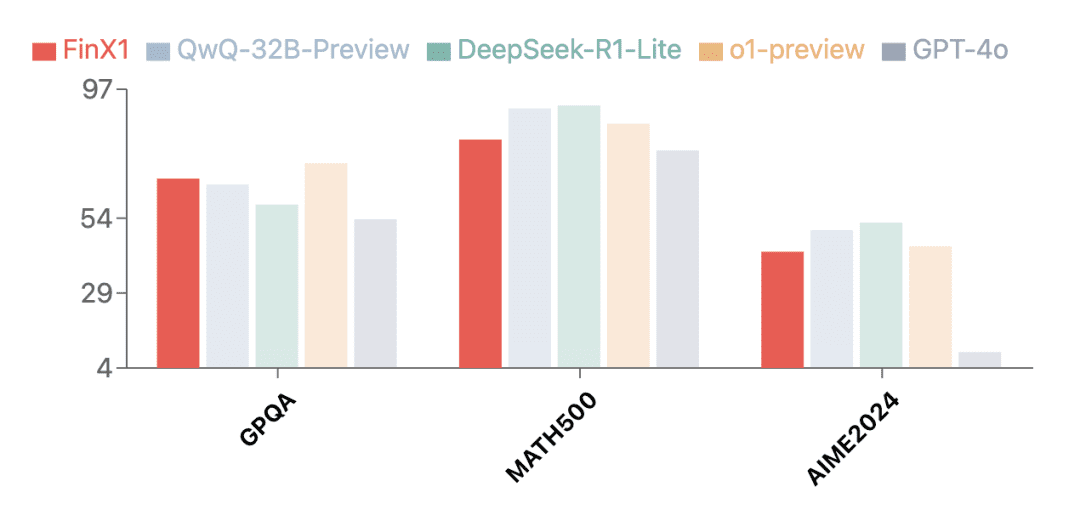
第一世代のRegulus-FinX1は、金融分野だけでなく、卓越した汎用性も実証しました。複数の権威ある評価セットでのテスト結果は、Regulus-FinX1が金融分野だけでなく、汎用分野でも優れていることを示しています。GPQA(科学的推論)そしてMATH-500(数学)歌で応えるAIME2024(数学コンクール)また、GPT-4oを上回り、O1や中国で新たにリリースされたビッグモデルの推論バージョンとともにトップクラスにランクされ、その強力な基本推論能力が実証された。
ブラックボックス」を打ち破る:思考の連鎖を完全に提示する
Regulus FinX1の特徴の一つは、答えを生成する前に完全な思考プロセスを提示し、問題の分解から最終的な結論まで完全に透明な思考チェーンを構築できることです。このメカニズムにより、Regulus FinX1は推論の解釈可能性を向上させるだけでなく、従来の大規模モデルの「ブラックボックス」問題を解決し、金融機関により信頼性の高い意思決定支援ツールを提供します。

レグルス FinX1の思考連鎖生成の例
財務の複雑性と分析的意思決定に重点を置く
OpenAIのGPT-O1がその優れた「思考力」で業界の注目を集めたとき、重要な命題が浮上した:どうすればこの深い推論能力を、金融のプロのシナリオにおいて実質的な価値を生み出すことができるのだろうか?杜小万レグルスFinX1は革新的な答えを出すビッグ・モデルの深い推論能力が初めて金融分野に注入され、ビッグ・モデルの金融分野への応用が促進された。一般的なシナリオから、リスクコントロールの意思決定などの中核的なビジネスレベルまで深く掘り下げるために使用します。
金融業界におけるデジタル・インテリジェンス変革の波の中で「意思決定とリスク管理能力」、「調査と分析能力」、「データ・インテリジェンス能力は、事業革新と価値向上を推進する重要な次元を構成している。これらの能力はそれぞれ、正確なリスク識別と管理、綿密な市場調査と価値発見、効率的なデータモデリングと分析を通じて、金融機関に持続的な価値成長をもたらす。
Regulus FinX1は、革新的なトレーニングパラダイムを通じて、深い推論能力と金融の専門知識を深く統合し、これら3つの能力を特定のシナリオで完全に発揮できるようにし、金融業界に新しいインテリジェントなソリューションをもたらします。

01 意思決定とリスク管理能力
意思決定とリスクコントロール能力は金融機関の生命線であり、健全な経営と持続可能な発展に関係しています。Regulus FinX1は、リスク識別・予測、リスクコントロールモデル構築、戦略策定のコアタスクにおいて、その強力な推論能力と完全な連鎖的メカニズムにより、リスク要因間の相関と伝導経路を体系的に分析し、金融機関に包括的かつ詳細なリスクインサイトを提供することができます。例えば、Regulus FinX1は、ユーザーの認証によってアップロードされた銀行水に基づき、数千の取引記録から、高頻度の宝くじ消費、ゲーム消費などのリスクシグナルを正確に識別し、ユーザーの返済能力と信用リスクを科学的に評価し、所得水準と債務負担と連動させることができる。

Regulus FinX1 がクリップに返信
02 調査・分析能力
調査・分析能力は、マクロ、業界、企業レベルの詳細な洞察を通じて資本配分の科学を強化する、金融意思決定の基本的なサポートです。Regulus FinX1は、マクロ経済データ、市場センチメント、政策の影響などを多角的に分析し、明確なロジックチェーンを通じて複雑な問題を徐々に解体していくことができます。例えば、経済データに基づいて2025年のFRBの利下げを予測する場合、モデルは様々な経済要因を分析し、様々な仮想シナリオに基づいて幅広い可能性を探り、包括的かつ客観的に2025年のFRBの利下げの見通しを示し、これは現在多くの機関の予測分析見解と一致しています。 
03 データインテリジェンス機能
データインテリジェンス機能は、金融機関が正確な意思決定を行うための重要なサポートであり、その中核となるのは効率的なデータ処理能力と詳細な分析能力です。Regulus FinX1は、金融機関がデータの背後にあるビジネスロジックと価値を迅速に探索するのに役立ちます。例えば、ある企業の四半期財務データがRegulus FinX1に入力された場合、モデルは中核となる情報を正確に抽出し、資産の質、流動性、ビジネスダイナミクスを視覚的に表示することができます。Regulus FinX1は、「流動性圧力」や「資産拡大ドライブ」などの主要指標を分析することで、定量的な比較に基づく定性的な説明を加え、財務データの背後にある潜在的なリスクや成長機会を明らかにし、企業の意思決定の最適化を支援します。 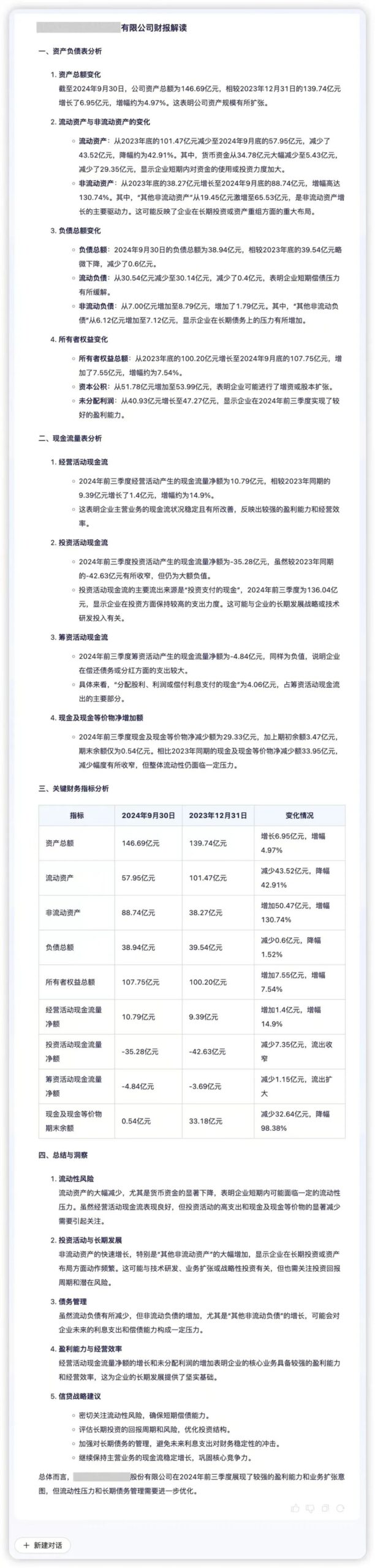
Regulus-FinX1の技術的実装
特に金融領域における複雑な意思決定分析シナリオにおいて、O1のような推論能力を持つ大規模なモデルを実現するために、広範な調査と検証の後、3つの重要なステップを含む技術的解決策を提案する:安定した思考連鎖生成モデル、財務判断強化のための二重報酬モデル、PRMとORMの二重指導の下での強化学習の微調整に向けて。
01 思考の連鎖の安定した生成モデルの初期構築
金融領域における複雑な意思決定分析シナリオに対して、安定した思考連鎖生成機能を持つ基本モデルを構築した。まず、高品質なCOT/Answerのデータ合成を行い、質問に基づく思考プロセスを生成し、質問と思考プロセスに基づく最終的な回答を生成する。この戦略により、モデルはタスクの各段階に集中し、より首尾一貫した推論連鎖と答えを生成することができる。
異なるドメイン(例えば、数学、論理的推論、金融分析など)に対して、我々は特別なデータ合成方法を設計した。例えば、金融分析タスクに対して、我々は分析プロセスの包括性を確保するために反復合成方法を設計し、その後、コマンド微調整を使用してXuanYuan 3.0モデルに基づいて訓練し、統一された思考プロセス 回答出力形式を採用する(我々はまた、モデルを強化するために、今回、粗視化された長文テキストデータを公開する)。thinking> answerの出力形式(今回は粗視化された思考ノードも公開する)同時に、より多くの長文データを構築することに注力し、「答えを生成する前に詳細な思考プロセスを生成する」ことができるよう、モデルの長文文脈処理能力を高める。これにより、その後のプロセス教師あり学習と強化学習の最適化のための強固な基礎が築かれる。
02 財務上の意思決定強化のための二重報酬モデル
財務上の意思決定シナリオにおけるモデルのパフォーマンスを評価するために、私たちは次のようなモデルを設計した。成果志向型(ORM)とプロセスレベル(PRM)の2つの補完的報酬モデル.その中で、ORMはXuanYuan 3.0の技術的な解決策を引き継いでおり、対比学習と逆強化学習によって学習されます。PRMは推論プロセスのための我々の革新であり、オープンエンドの金融問題(市場分析、投資判断など)の評価の難しさを解決することに焦点を当てています。
PRMの学習データ構築には、シナリオごとに異なる戦略を採用する。リスク評価のような答えが明確な質問に対しては、MCTSに基づく逆検証法を用い、自由形式の財務分析質問に対しては、複数の大規模モデルを通じて、正しさ、必要性、論理性などの次元で注釈を付け、ダウンサンプリングと能動学習によってデータの不均衡問題を解決する。03 PRMとORMの二重ガイダンスによる強化学習の微調整強化学習の段階では、PRMとORMを報酬シグナルとして使用するPPOアルゴリズムをモデルの最適化に使用する。との間の思考プロセスでは、PRMが各思考ステップをスコアリングするために使用され、思考経路のエラーを検出し、タイムリーに修正することができる。例えば、市場分析)はORMを使用して総合的にスコアリングされる。学習プロセスを安定させるために、動的KL係数や支配関数の正規化などの技術も同時に導入される。この二重報酬に基づくトレーニング・メカニズムこれは、単一の報酬モデルの限界を克服するだけでなく、安定した強化学習訓練を通じて、金融意思決定シナリオにおけるモデルの推論能力を大幅に向上させる。
このように、数学や論理学とは異なる金融分析の未解決問題に対する思考連鎖データの構築と報酬モデルの評価が上記のルートにおける鍵であり、現在も最適化と反復の過程にあり、より効果的な技術的ルートの探求を続けていく。
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事



コメントはありません