GPUStackによるRAG 3-Pack for Difyの迅速な展開

GPUStack これは、Nvidia、Apple Metal、Huawei Rise、Moore Threadなど、さまざまな異種GPU/NPUリソースを効率的に統合して利用し、ビッグモデル・ソリューションのローカル・プライベート展開を提供できるオープンソースのビッグモデル・アズ・ア・サービス・プラットフォームである。
GPUStackは以下をサポートします。 ラグ システムに必要な3つの主要モデル:チャット対話モデル(大規模言語モデル)、埋め込みテキストモデル、Rerank再順序付けモデルは、3ピーススイートで利用可能であり、RAGシステムに必要なローカルプライベートモデルを展開することは、非常に簡単で確実な操作である。
GPUStackとDifyのインストール方法は以下の通りです。 ダイファイ GPUStackの対話モデル、埋め込みモデル、再ランカーモデルとのインタフェースを提供します。
GPUStackのインストール
LinuxまたはmacOSでは、以下のコマンドでオンライン・インストールする: curl -sfL https://get.gpustack.ai | sh -
GitHubに接続してバイナリをダウンロードできない場合は、以下のコマンドを使って、バイナリを --tools-download-base-url このパラメータは、Tencent Cloud Object Storageからのダウンロードを指定する:curl -sfL https://get.gpustack.ai | sh - --tools-download-base-url "https://gpustack-1303613262.cos.ap-guangzhou.myqcloud.com"
Windows上でPowershellを管理者として実行し、以下のコマンドでオンライン・インストールする:Invoke-Expression (Invoke-WebRequest -Uri "https://get.gpustack.ai" -UseBasicParsing).Content
GitHubに接続してバイナリをダウンロードできない場合は、以下のコマンドを使って、バイナリを --tools-download-base-url このパラメータは、Tencent Cloud Object Storageからのダウンロードを指定する:Invoke-Expression "& { $((Invoke-WebRequest -Uri 'https://get.gpustack.ai' -UseBasicParsing).Content) } --tools-download-base-url 'https://gpustack-1303613262.cos.ap-guangzhou.myqcloud.com'"
以下の出力が表示された場合、GPUStack は正常にデプロイされ、起動されています:
[INFO] Install complete. GPUStack UI is available at http://localhost. Default username is 'admin'. To get the default password, run 'cat /var/lib/gpustack/initial_admin_password'. CLI "gpustack" is available from the command line. (You may need to open a new terminal or re-login for the PATH changes to take effect.)
次に、スクリプト出力の指示に従ってGPUStackにログインするための初期パスワードを取得し、以下のコマンドを実行します:
LinuxまたはmacOS上で:cat /var/lib/gpustack/initial_admin_password
Windowsの場合:Get-Content -Path (Join-Path -Path $env:APPDATA -ChildPath "gpustackinitial_admin_password") -Raw
ユーザー名admin、パスワードは上記で取得した初期パスワードでブラウザからGPUStack UIにアクセスします。
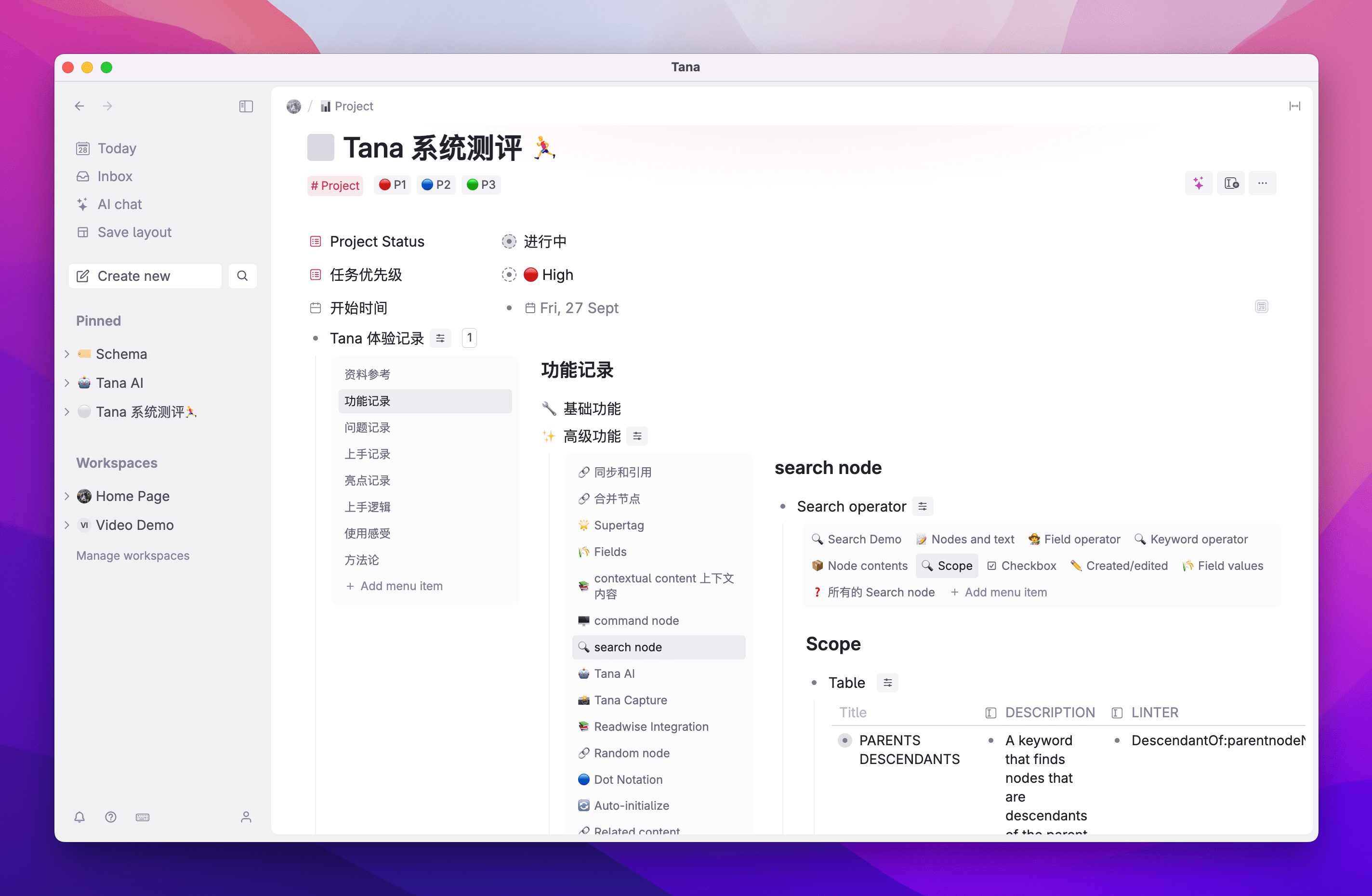
パスワードをリセットした後、GPUStackと入力してください: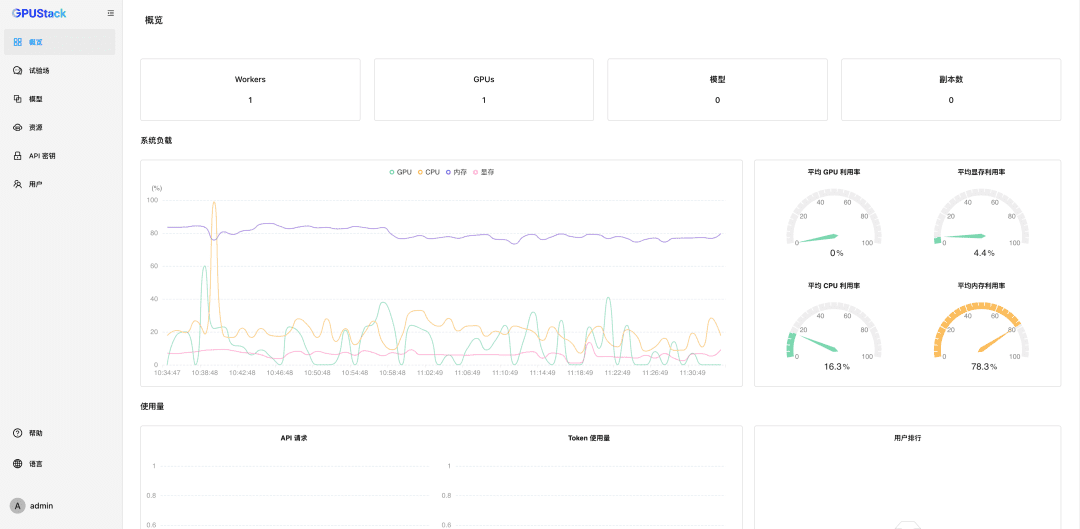
ナノマネジメントGPUリソース
GPUStackはLinux、Windows、macOSデバイスのGPUリソースをサポートし、以下の手順でこれらのGPUリソースを管理します。
他のノードは認証が必要 トークン GPUStackクラスタに参加し、GPUStackサーバノードで以下のコマンドを実行し、Tokenを取得します:
LinuxまたはmacOS上で:cat /var/lib/gpustack/token
Windowsの場合:Get-Content -Path (Join-Path -Path $env:APPDATA -ChildPath "gpustacktoken") -Raw
Tokenを入手したら、他のノードで以下のコマンドを実行してWorkerをGPUStackに追加し、それらのノードのGPUをnanomanageします(http://YOUR_IP_ADDRESSをGPUStackのアクセスアドレスに、YOUR_TOKENをWorkerの追加に使用した認証Tokenに置き換えてください):
LinuxまたはmacOS上で:curl -sfL https://get.gpustack.ai | sh - --server-url http://YOUR_IP_ADDRESS --token YOUR_TOKEN --tools-download-base-url "https://gpustack-1303613262.cos.ap-guangzhou.myqcloud.com"
Windowsの場合:Invoke-Expression "& { $((Invoke-WebRequest -Uri "https://get.gpustack.ai" -UseBasicParsing).Content) } --server-url http://YOUR_IP_ADDRESS --token YOUR_TOKEN --tools-download-base-url 'https://gpustack-1303613262.cos.ap-guangzhou.myqcloud.com'"
以上のステップで、GPUStack環境を構築し、複数のGPUノードを管理することができました。
プライベート・マクロモデルの展開
HuggingFace、Ollama Library、ModelScope、プライベートモデルリポジトリからのデプロイをサポートしています。
GPUStackサポート ブイエルエルエム とllama-box推論バックエンドは、vLLMは本番推論用に最適化されており、同時実行性とパフォーマンスの点で本番ニーズに適していますが、vLLMはLinux上でのみサポートされています。 ラマ.cpp Linux、Windows、macOSの各システムをサポートし、GPU環境だけでなく、大規模モデルを実行するためのCPU環境にも対応しているため、マルチプラットフォーム対応が必要なシーンに適している。
GPUStackは、モデルをデプロイする際に、モデルファイルの種類に応じて適切な推論バックエンドを自動的に選択します。GPUStackは、モデルがGGUF形式の場合はllama-boxを、GGUF形式以外の場合はvLLMをモデルサービスを実行するバックエンドとして使用します。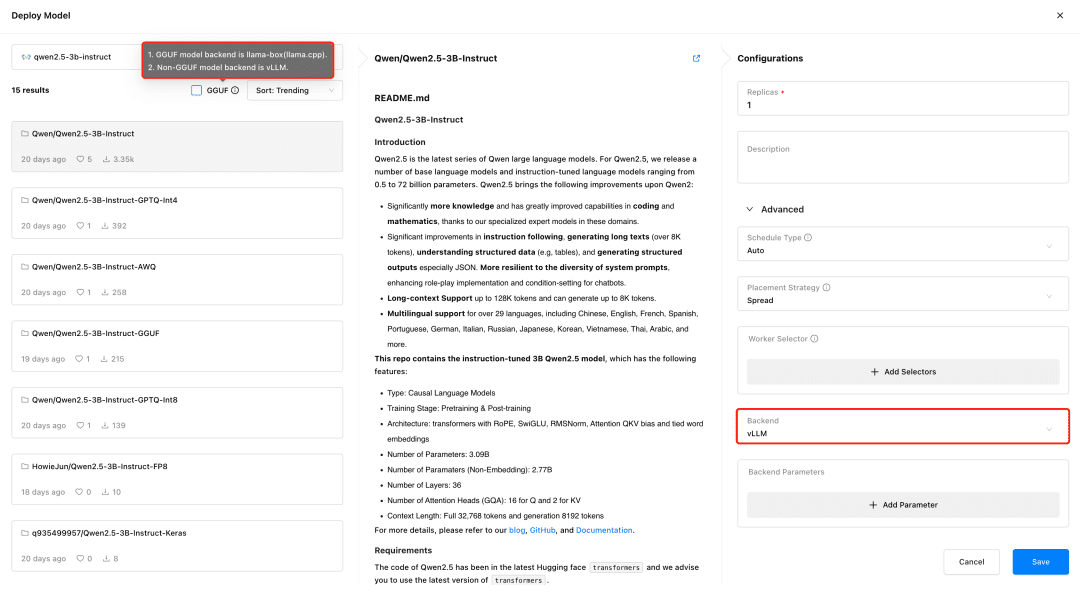
Difyのドッキングに必要なテキスト対話モデル、テキスト埋め込みモデル、Rerankerモデルをデプロイし、デプロイ時にはGGUFフォーマットのチェックを忘れずに:
- クウェン/Qwen2.5-7B-Instruct-GGUF
- gpustack/bge-m3-GGUF
- gpustack/bge-reranker-v2-m3-GGUF
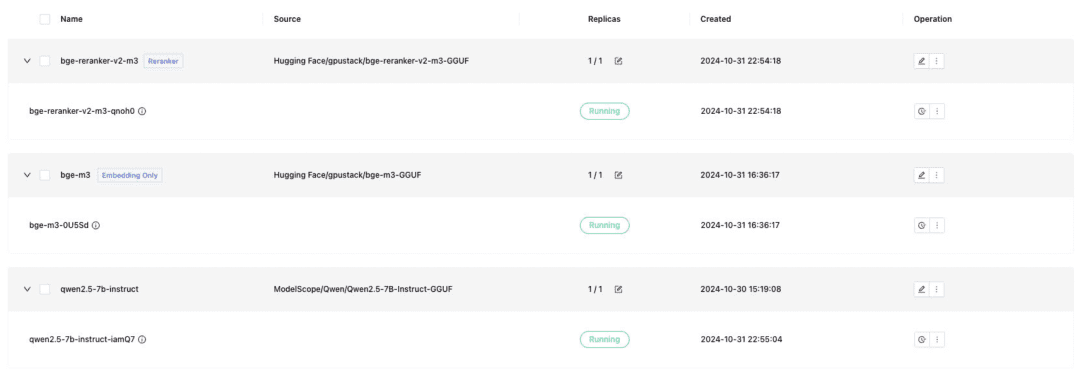
GPUStackはVLMマルチモーダルモデルもサポートしており、その展開にはvLLM推論バックエンドを使用する必要がある:
Qwen2-VL-2B-インストラクター 

モデルがデプロイされると、RAGシステムや他のジェネレーティブAIアプリケーションは、GPUStackが提供するOpenAI / Jina互換APIを介してGPUStackデプロイモデルとインターフェイスすることができ、その後DifyがGPUStackデプロイモデルとインターフェイスします。
Dify 統合 GPUStack モデル
ディファイをインストールする
Dockerを使用してDifyを実行するには、Docker環境を用意し、DifyとGPUStackのポート80が競合しないように、他のホストを使用したり、ポートを変更したりする必要があります。以下のコマンドを実行し、Difyをインストールします:git clone -b 0.10.1 https://github.com/langgenius/dify.gitDifyのUIインターフェース(http://localhost)にアクセスし、管理者アカウントを初期化してログインします。
cd dify/docker/
cp .env.example .env
docker compose up -d
GPUStackモデルを統合するには、まずチャットダイアログモデルを追加します。Difyの右上にある "設定 - モデルプロバイダ "を選択し、リストからGPUStackタイプを見つけて、"モデルを追加 "を選択します:
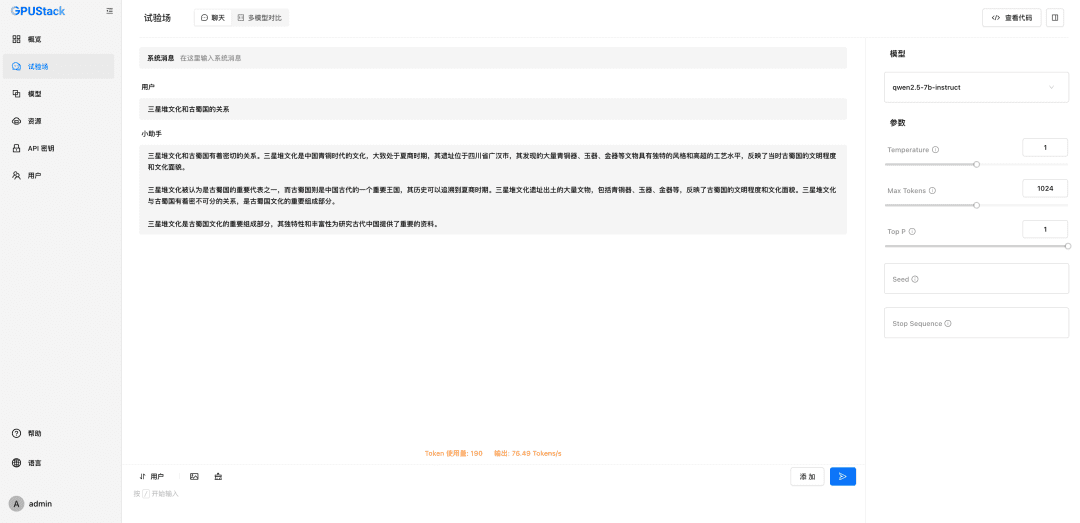
GPUStackに配置されたLLMモデルの名前(例:qwen2.5-7b-instruct)、GPUStackのアクセスアドレス(例:http://192.168.0.111)と生成されたAPI Key、モデルの設定のコンテキスト長8192とmaxを入力します。 トークン 2048: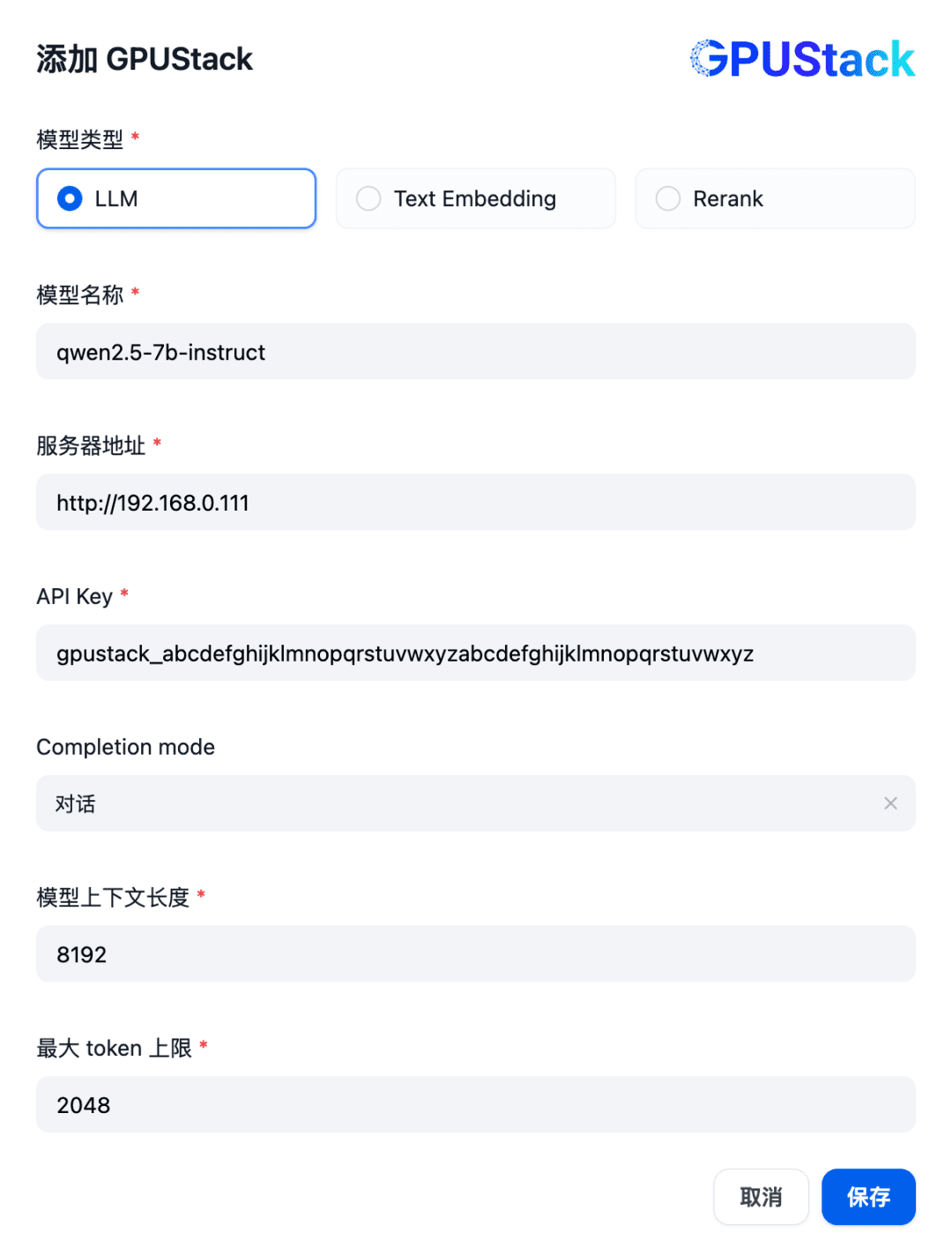
次にEmbeddingモデルを追加します。モデルプロバイダのトップでGPUStackタイプを選択し、Add Modelを選択します: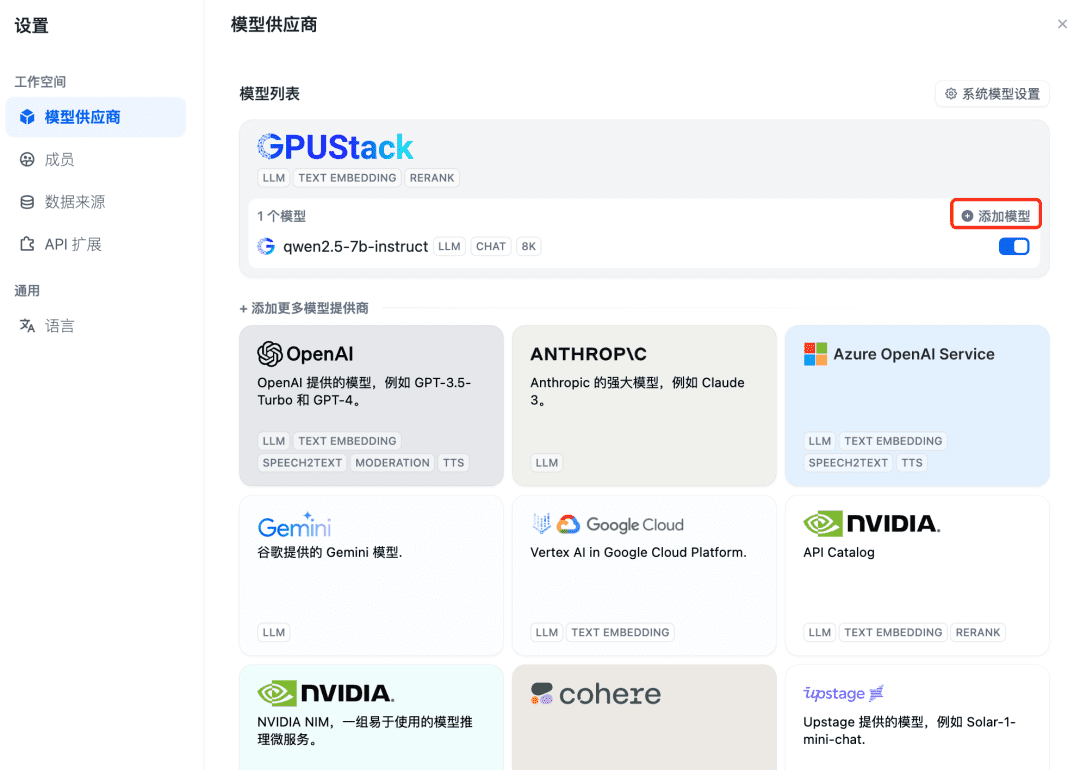
GPUStackに配置したEmbeddingモデルの名前(例:bge-m3)、GPUStackのアクセスアドレス(例:http://192.168.0.111)と生成したAPI Key、モデル設定のコンテキスト長8192を入力して、Text Embeddingタイプのモデルを追加します: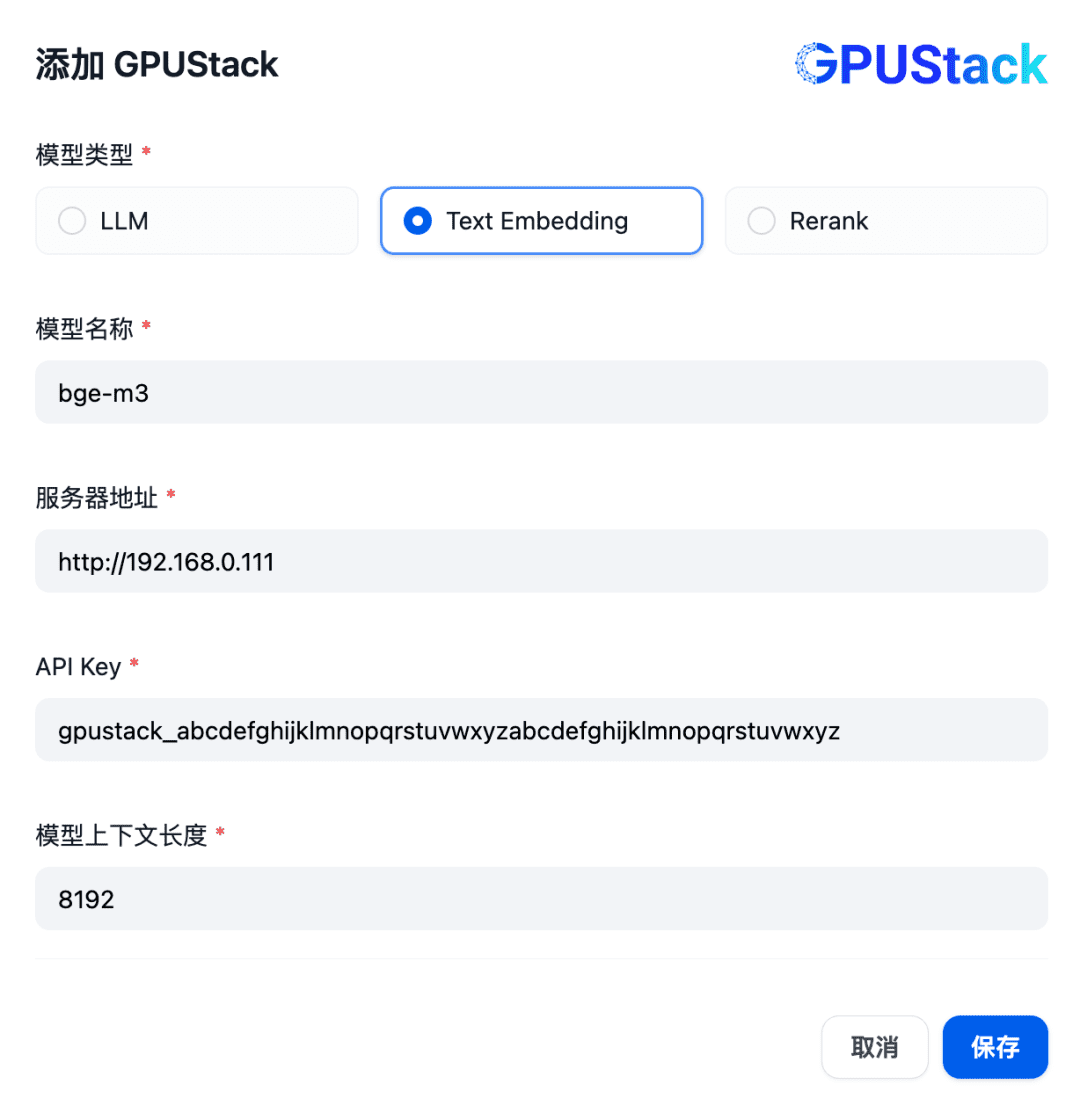
次に、Rerank モデルを追加するために、GPUStack のタイプを選択し、「Add Model」を選択し、Rerank タイプのモデルを追加し、GPUStack 上に配置された Rerank モデルの名前(例:bge-reranker-v2-m3)、GPUStack のアクセスアドレス(例:http://192.168.0.111)、生成されたAPI Key、モデル設定のコンテキスト長8192を指定します: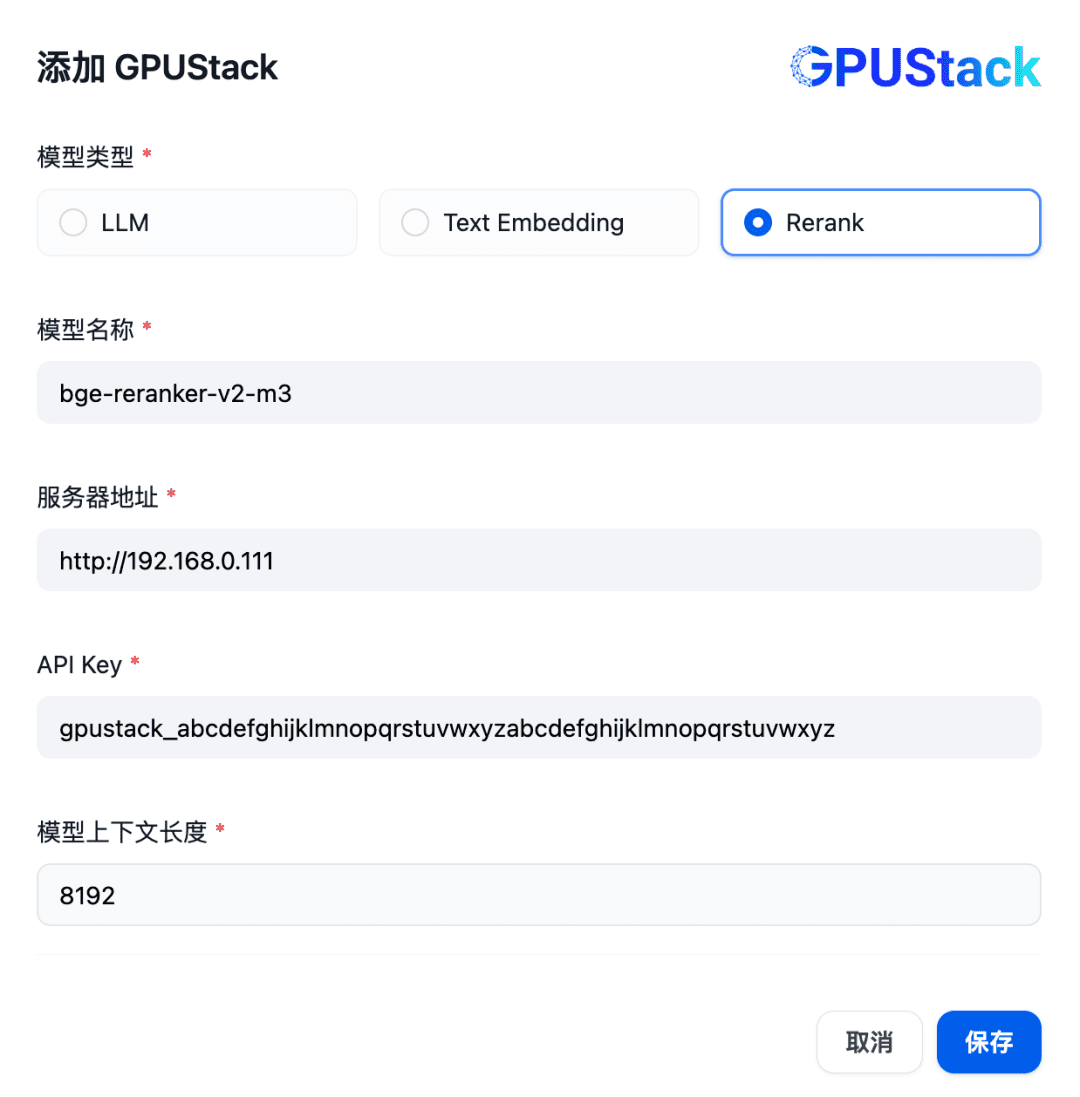
追加後にリフレッシュし、モデルプロバイダーでシステムモデルが上記で追加した3モデル用に設定されていることを確認する: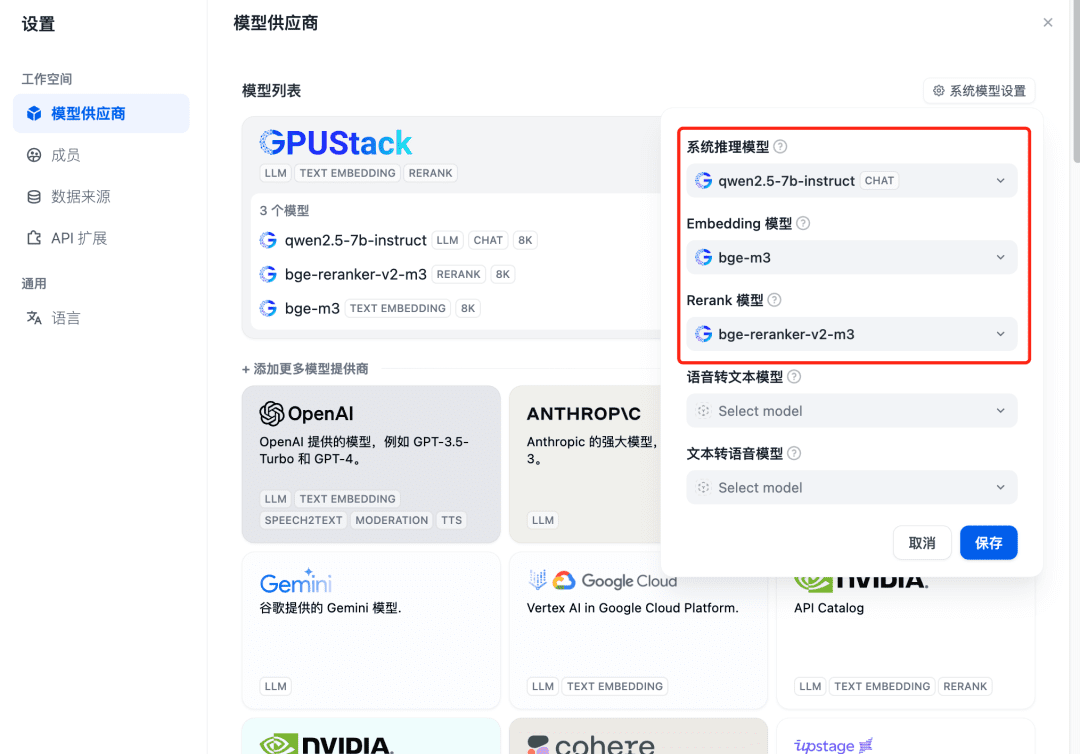
RAGシステムでモデルを使用する Dfiyのナレッジベースを選択し、ナレッジベースの作成を選択し、テキストファイルをインポートし、モデルの埋め込みオプションを確認し、検索設定に推奨されるハイブリッド検索を使用し、再ランクモデルをオンにします: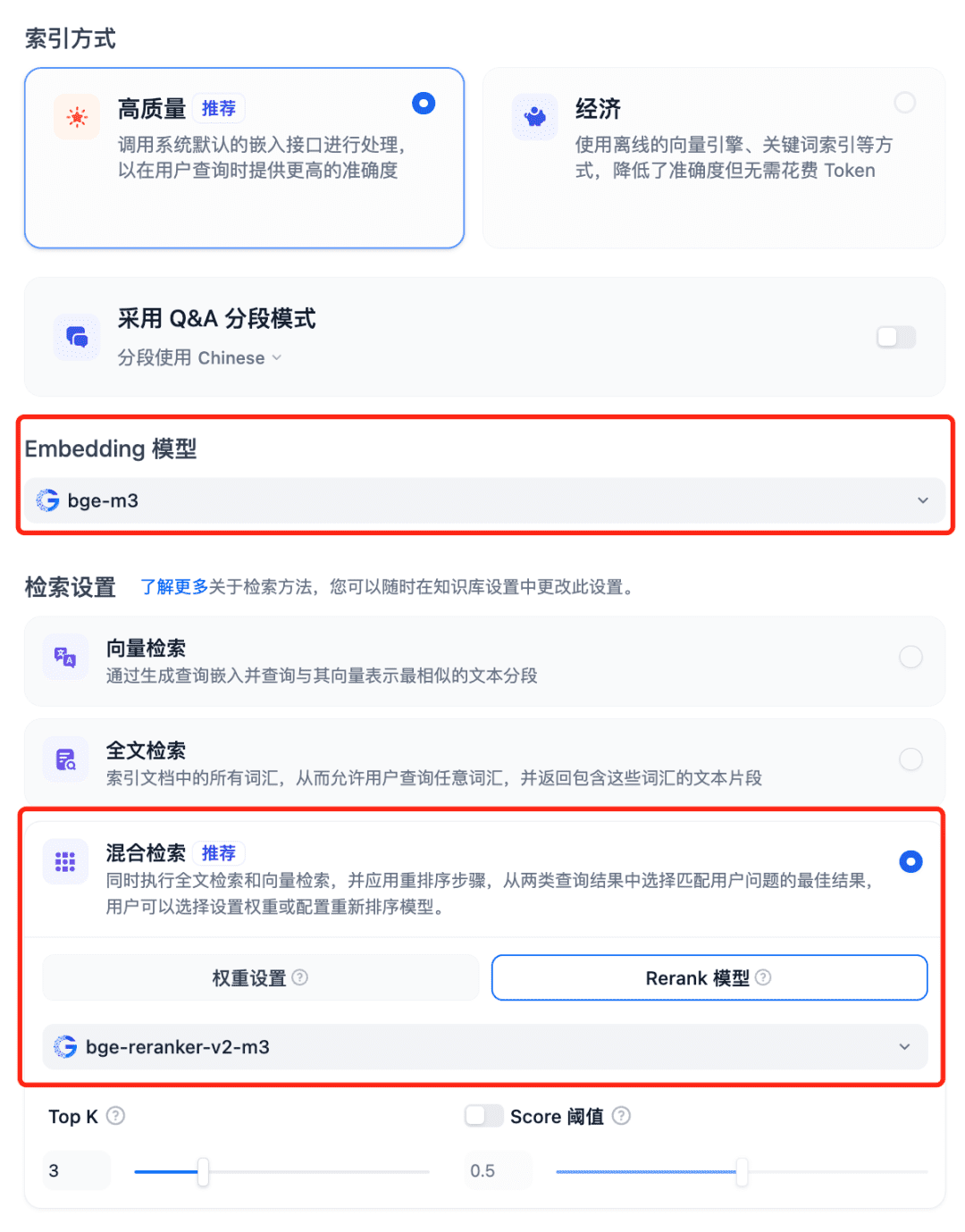
保存し、ドキュメントのベクトル化のプロセスを開始します。 ベクトル化が完了すると、知識ベースは使用できるようになります。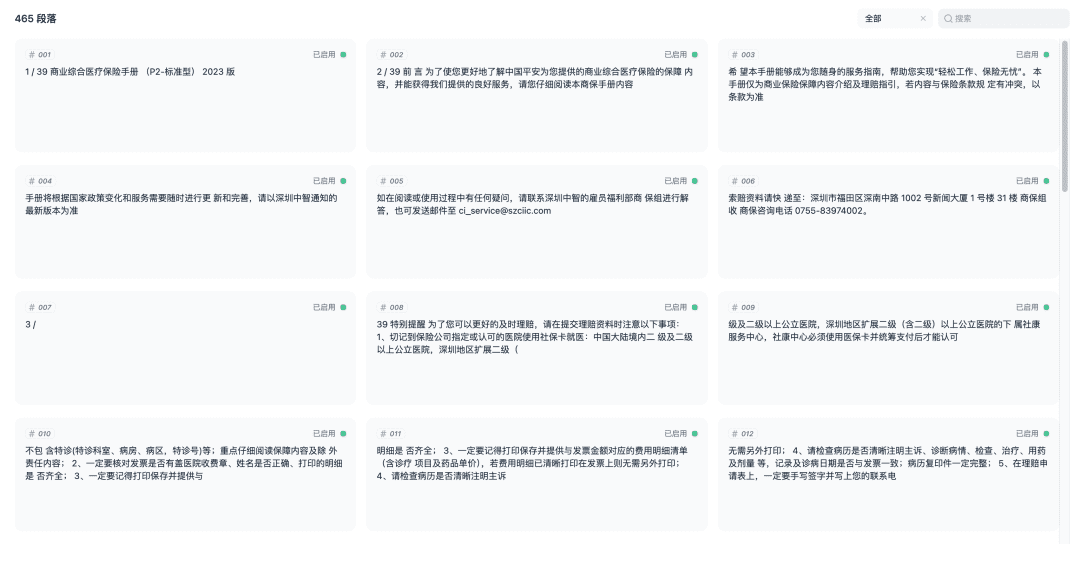
リコールテストは、知識ベースのリコール効果を確認するために使用することができ、Rerankモデルは、より良いリコール結果を達成するために、より関連性の高い文書をリコールするように改良される: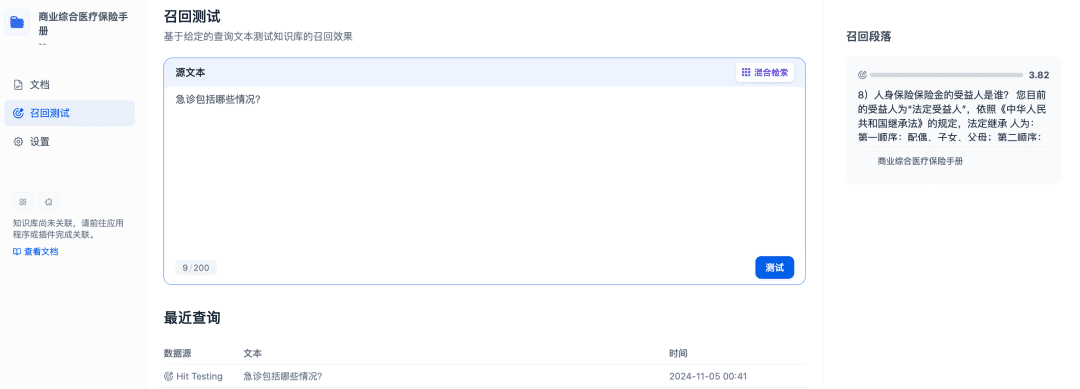
次に、チャットルームにチャットアシスタントアプリを作成します: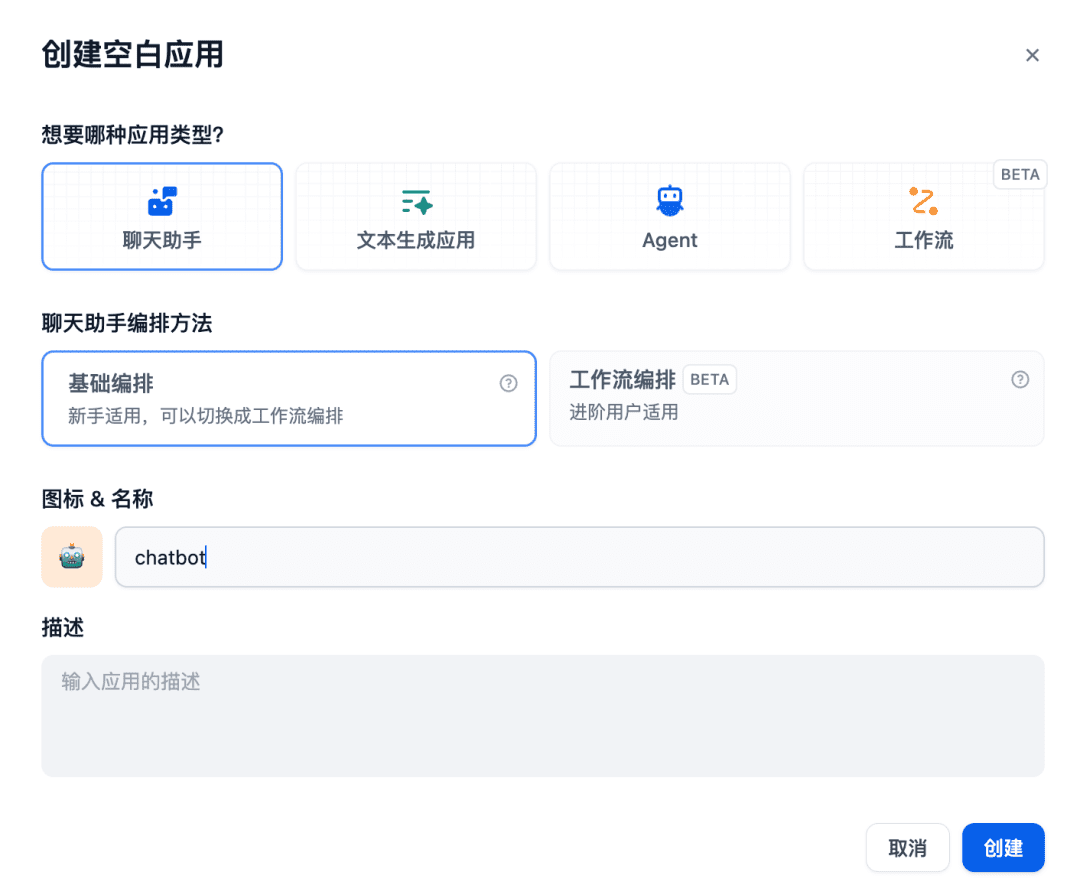
関連する知識ベースは使用されるコンテキストに追加され、その時点でチャットモデル、エンベッディングモデル、リランカーモデルはRAGアプリケーションをサポートするために連携し、エンベッディングモデルはベクトル化を担当し、リランカーモデルはリコールの内容の微調整を担当し、チャットモデルは質問の内容とリコールのコンテキストに基づいて回答を担当する: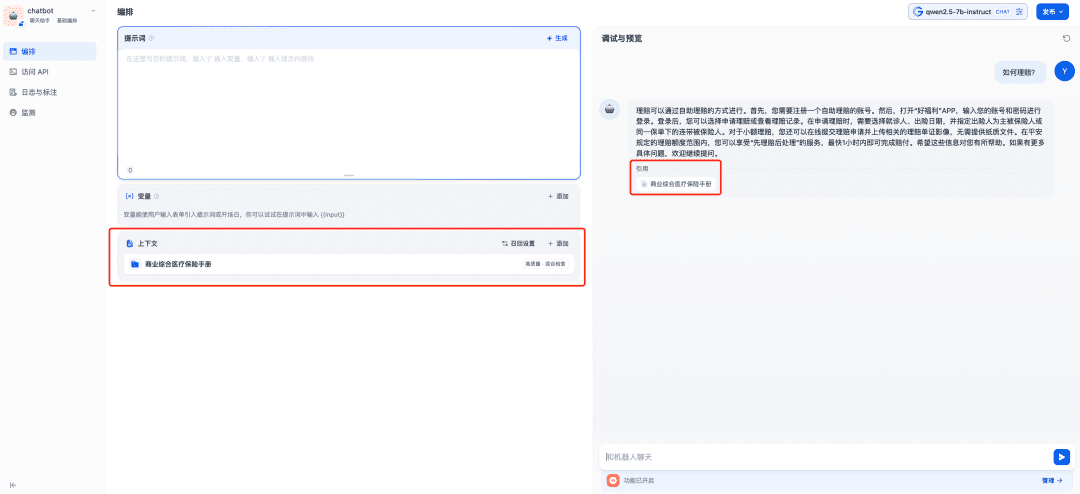
上記はGPUStackモデルとのインターフェースにDifyを使用した例です。 他のRAGシステムもOpenAI / Jina互換APIを介してGPUStackとインターフェースすることができ、RAGシステムをサポートするためにGPUStackプラットフォームによって展開される様々なチャット、エンベッディング、リランカーモデルを利用することができます。
以下はGPUStack関数の簡単な説明である。
GPUStackの特徴
- ヘテロジニアスGPUサポート:ヘテロジニアスGPUリソースをサポートし、現在Nvidia、Apple Metal、Huawei Rise、Moore ThreadなどのGPU/NPUをサポート
- マルチ推論バックエンドのサポート:vLLMとllama-box (llama.cpp)の推論バックエンドがサポートされています。
- マルチプラットフォームのサポート:Linux、Windows、macOSプラットフォーム、amd64およびarm64アーキテクチャをカバー。
- マルチモデルのサポート:LLMテキストモデル、VLMマルチモーダルモデル、Embeddingテキスト埋め込みモデル、Reranker並び替えモデルなど、様々なタイプのモデルをサポート。
- マルチ・モデル・リポジトリのサポート: HuggingFace、Ollama Library、ModelScope、プライベート・モデル・リポジトリからのモデルのデプロイをサポートします。
- 豊富な自動/手動スケジューリングポリシー:コンパクトスケジューリング、分散スケジューリング、指定ワーカータグスケジューリング、指定GPUスケジューリング、その他のスケジューリングポリシーをサポートします。
- 分散推論: GPUStackの分散推論機能を使用すると、1つのGPUで大規模なモデルを実行できない場合、ホスト間の複数のGPUでモデルを自動的に実行することができます。
- CPU推論:GPUがない、またはGPUリソースが不十分な場合、GPUStackはCPUリソースを使用して大規模なモデルを実行することができ、GPUとCPUのハイブリッド推論と純粋なCPU推論の2つのCPU推論モードをサポートしています。
- 複数モデルの比較:GPUStackの場合 遊び場 異なるモデル、異なる重み、異なるプロンプトパラメータ、異なる定量化、異なるGPU、異なる推論バックエンドのモデルサービング効果を評価するために、複数のモデルのQ&Aコンテンツとパフォーマンスデータを同時に比較するためのマルチモデル比較ビューが提供されています。
- GPUおよびLLM Observables: GPUおよびLLMの利用状況を評価するために、包括的なパフォーマンス、利用状況、ステータス監視、および利用状況データメトリクスを提供します。
GPUStackは、プライベート・ラージ・モデル・アズ・ア・サービス・プラットフォームを構築するために必要なエンタープライズクラスの機能をすべて提供しています。 オープンソースプロジェクトであるため、インストールとセットアップが非常に簡単で、すぐにエンタープライズ・プライベート・ラージ・モデル・アズ・ア・サービス・プラットフォームを構築することができます。
概要
上記はGPUStackをインストールし、Difyを使用してGPUStackモデルを統合するための設定チュートリアルです。プロジェクトのオープンソースアドレスはhttps://github.com/gpustack/gpustack。
GPUStackは障壁が低く、使いやすく、すぐに使える。オープンソースプラットフォームこれは、企業が異種GPUリソースを迅速に統合して活用し、短期間でエンタープライズグレードのプライベート・ビッグ・モデル・アズ・ア・サービス・プラットフォームを迅速に構築するのに役立ちます。
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事

コメントはありません