 挙げる
挙げる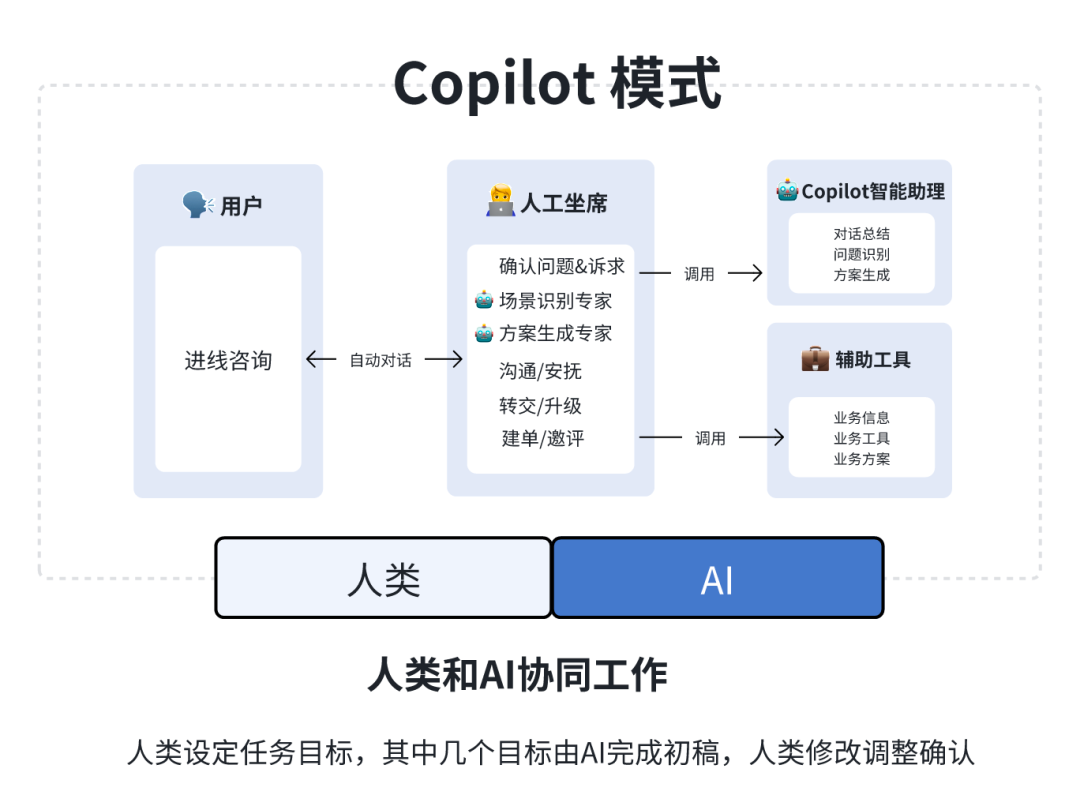
VespaによるPDF用Visual RAG - Pythonベースのデモアプリケーション

 挙げる
挙げる
トーマスは2024年4月にシニアソフトウェアエンジニアとしてVespaに入社しました。彼のAIコンサルタントとしての最後の前職では、Vespaの ラグ アプリケーション
PDFは企業ではどこにでもあるもので、そこから情報を検索して取り出すことは一般的なユースケースです。課題は、多くのPDFが通常、以下のカテゴリの1つ以上に分類されることです:
- スキャンされた文書であるということは、テキストを簡単に抽出できないことを意味するので、OCRを使用しなければならず、これが複雑さを増している。
- これらの文書には多くの図表が含まれており、たとえテキストを抽出できたとしても、簡単に取り出すことはできない。
- 多くの画像が含まれており、その中には貴重な情報が含まれていることもある。
という用語がある。 コルパリ 2つの意味がある:
- 特殊 モデリング および関連する 論文について論じる VLM(PaliGemma)の上にLoRaアダプタを学習させ、テキストと画像の埋め込み(画像内の各パッチに対して1つの埋め込み)を生成する。 コルバート 視覚言語モデルを拡張する方法。
- これはまた、視覚的な文書検索を表している。 オリエンテーション これは、VLMの機能と効率的なポストインタラクションメカニズムを組み合わせたものである。この方向性は原論文の特定のモデルに限定されるものではなく、他のVLMにも適用できる。例えば、ColQwen2やVespaの ノート .
このブログポストでは、ColPaliエンベッドを使用してVespa上のビジュアルRAGを紹介するリアルタイムデモ・アプリケーションの構築方法について説明します。アプリケーションのアーキテクチャ、ユーザーエクスペリエンス、アプリケーションの構築に使用した技術スタックについて説明します。
以下はデモアプリのスクリーンショットです:
最初の例は一般的なクエリではないが、ある種のクエリに対するビジュアル検索の威力を示している。これは「What You See Is What You Search (WYSIWYS)」パラダイムの良い例です。
類似性マッピングは、ユーザーがページのどの部分がクエリに最も関連しているかを簡単に見ることができるように、最も類似しているセクションをハイライトします。
 2つ目の例は、より一般的なユーザークエリで、意味的類似性の観点からColPaliの威力を示している。
2つ目の例は、より一般的なユーザークエリで、意味的類似性の観点からColPaliの威力を示している。 
PDFを検索可能にすることの難しさを身をもって体験したトーマスは、視覚言語モデリング(VLM)分野の最新動向に特に関心を寄せている。
コルパリに関する前回の記事を読んで ベスパのブログ記事 協力 ジョー・バーグム 綿密な議論を重ねた結果、彼はVespaを使ってビジュアルなRAGアプリケーションを構築するプロジェクトを提案することになった。
Vespaでは、社員はイテレーションサイクルごとに実施したい仕事のプログラムを提案する機会があります。提案された仕事が会社の目標に沿ったもので、他に緊急の優先事項がない限り、着手することができる。コンサルティング業界出身のトーマスにとって、この自主性は新鮮な息吹だ。
TL;DR
を構築した。 リアルタイム・デモ・アプリケーションこの記事では、VespaとPythonのColPaliエンベッディングを使って、FastHTMLだけでPDFベースのVisual RAGを実装する方法を紹介します。
複製コードも提供する:
- 実行可能な ノートこれは、Visual RAGを実装するための独自のVespaアプリケーションをセットアップするために使用します。
- FastHTML アプリケーション コードを使って、Vespaアプリケーションと相互作用するWebアプリケーションをセットアップすることができます。
プロジェクト目標
このプロジェクトには主に2つの目的がある:
1.リアルタイム・デモンストレーションの構築
開発者たちは、JSONをUIとして出力するデモで満足するかもしれないが、実際のところ、ほとんどの人はウェブ・インターフェースを好む。
 これにより、ColPaliエンベッディングに基づくVespaのPDF Visual RAGを実証することができます。ColPaliエンベッディングは、法律、金融、建設、学術、医療など、幅広いドメインやユースケースに関連すると考えています。
これにより、ColPaliエンベッディングに基づくVespaのPDF Visual RAGを実証することができます。ColPaliエンベッディングは、法律、金融、建設、学術、医療など、幅広いドメインやユースケースに関連すると考えています。
私たちは、これが将来的に重要になると確信しているが、それを実証する実用的なアプリケーションはまだ見ていない。
同時に、効率性、スケーラビリティ、ユーザー・エクスペリエンスの面で、多くの貴重な知見を得ることができました。また、良いユーザー・エクスペリエンスを提供するのに十分なスピードがあるかどうか、非常に気になりました(あるいは少し不安でした)。
我々はまた、ベスパの便利な機能のいくつかを強調したかった:
- ステージ順
- キーワードの関連付けの提案
- マルチベクトルMaxSim計算
2.オープンソースのテンプレートを作成する
我々は、他の人々が独自のVisual RAGアプリケーションを構築するためのテンプレートを提供したい。
このテンプレートで十分だろう。よりシンプルに特定のプログラミング言語やフレームワークを多数マスターする必要はない。
データセットの作成
今回のデモでは、画像、表、グラフの形で重要な情報を大量に含むPDF文書のデータセットを使いたい。また、すべての画像を直接VLMにアップロードする(検索ステップをスキップする)ことが実行不可能であることを実証するために、十分なサイズのデータセットが必要である。
利用する gemini-1.5-flash-8b現在の最大入力画像数は3600枚。
私たちのニーズを満たす公開データセットがなかったため、自分たちで作ることにした。
誇り高きノルウェー人として、ノルウェー政府グローバル年金基金(GPFG、別名石油基金)が2000年以来、年次報告書とガバナンス文書をウェブサイトで公表していることを知り、嬉しく思った。ウェブサイトには著作権に関する記述はなく、最近の表現世界で最も透明性の高いファンドであることが実証されたので、私たちはこのデータを実証目的で使用できると確信している。
データセットには、2000年から2024年までの116種類のPDFレポートが含まれ、総ページ数は6992ページである。
このデータセットには、画像、テキスト、URL、ページ番号、生成された質問、クエリー、ColPali埋め込みが含まれ、現在、以下のサイトで公開されている。 以下は.

合成クエリと質問を生成する
また、各ページに対して合成クエリと質問を生成する。これらは2つの目的で使用することができます:
- ユーザーが入力すると、検索ボックスにキーワードの関連付けを提案します。
- 評価のため。
質問とクエリを生成するために使用するヒントは、以下のものです。 ダニエル・ファン・ストライエンによる素晴らしいブログ記事.
您是一名投资者、股票分析师和金融专家。接下来您将看到挪威政府全球养老基金(GPFG)发布的报告页面图像。该报告可能是年度或季度报告,或关于责任投资、风险等主题的政策报告。
您的任务是生成检索查询和问题,这些查询和问题可以用于在大型文档库中检索此文档(或基于该文档提出问题)。
请生成三种不同类型的检索查询和问题。
检索查询是基于关键词的查询,由 2-5 个单词组成,用于在搜索引擎中找到该文档。
问题是自然语言问题,文档中包含该问题的答案。
查询类型如下:
1. 广泛主题查询:覆盖文档的主要主题。
2. 具体细节查询:涵盖文档的某个具体细节或方面。
3. 可视元素查询:涵盖文档中的某个可视元素,例如图表、图形或图像。
重要指南:
- 确保查询与检索任务相关,而不仅仅是描述页面内容。
- 使用基于事实的自然语言风格来书写问题。
- 设计查询时,以有人在大型文档库中搜索此文档为前提。
- 查询应多样化,代表不同的搜索策略。
将您的回答格式化为如下结构的 JSON 对象:
{
"broad_topical_question": "2019 年的责任投资政策是什么?",
"broad_topical_query": "2019 责任投资政策",
"specific_detail_question": "可再生能源的投资比例是多少?",
"specific_detail_query": "可再生能源投资比例",
"visual_element_question": "总持有价值的时间趋势如何?",
"visual_element_query": "总持有价值趋势"
}
如果没有相关的可视元素,请在可视元素问题和查询中提供空字符串。
以下是需要分析的文档图像:
请基于此图像生成查询,并以指定的 JSON 格式提供响应。
只返回 JSON,不返回任何额外说明文本。
を使用する。 gemini-1.5-flash-8b 質問やクエリを作成する。
銘記する
最初の実行で、非常に長い問題がいくつか発生することがわかったので、新しいセクションを 世代設定 を追加した。 maxOutputTokens=500とても助かるよ。
また、生成された質問とクエリには、"string "が質問の中に複数回現れるなど、奇妙な点があることに気づきました。私たちは生成された質問とクエリのより詳細な検証を望んでいます。
Pythonを全面的に使用する
私たちのターゲットは、成長中のデータサイエンスとAIのコミュニティです。このコミュニティは、GitHub上のPythonへの最大の貢献者のひとつになるでしょう。 オクトバース・ステータス・レポート最も人気のある(そして最も急成長している)プログラミング言語としてランク付けされている主な理由のひとつは、世界で最も人気のあるプログラミング言語のひとつだからだ。
バックエンドでPythonを使用し、クエリを埋め込んだ推論を行う必要がある。 コルパリエンジン-ライブラリ) をサポートするようになりました。 ColpaliEmbedder (開発中。 github issue).フロントエンドに他の言語(とそのフレームワーク)が使われる場合、プロジェクトの複雑さが増し、他の人がアプリケーションを再現することが難しくなります。
そこで、アプリケーション全体をPythonで構築することにした。
フロントエンド・フレームワークの選択
ストリームリットとグラディオ
GradioとStreamlitを使ってシンプルなPoC(概念実証)を構築するのが非常に簡単であることは認めるし、そのために過去に使ったこともある。しかし、私たちがGradioやStreamlitを使わないことにした主な理由は2つあります:
- 私たちは、本番環境で使用できるプロフェッショナルな外観のUIを必要としていました。
- 私たちは優れたパフォーマンスを必要としている。数秒待たされたり、UIが断続的にフリーズするようでは、私たちが提示したいアプリケーションには不十分です。
ワークアウトは大好きだが、Streamlitの画面右上に表示される "Running "というメッセージは好きではない。
FastHTMLによる救済
我々はそうだ。 アンサー 彼らの忠実なファンの。だから、彼らが今年初めにリリースした 高速HTML3その時は、喜んで挑戦させていただきます。
FastHTMLは、純粋なPythonを使ってモダンなWebアプリケーションを構築するためのフレームワークです。その ビジョン::
FastHTMLは、Django、NextJS、Ruby on Railsと同じカテゴリの、汎用フルスタック・ウェブ・プログラミング・システムです。そのビジョンは、迅速なプロトタイプを作成する最も簡単な方法であると同時に、スケーラブルでパワフルなリッチアプリケーションを作成する最も簡単な方法であることです。
FastHTML は スターレット 歌で応える ウビコーン.
これには以下が含まれる。 ピコCSS をスタイリングに使用しました。チームの経験豊富なウェブ開発者であるLeandroが、最近発見したTailwind CSSと一緒に試してみたいと言っていたので、Tailwind CSSを使うことにしました。 シャッド4ファーストFastHTMLと シャドック の美しい UI コンポーネントが、このような形で提供されている。
ピブスパ
ベスパ・パイソンのクライアント ピブスパ 過去には主にVespaアプリケーションのプロトタイピングに使われていました。しかし、私たちは最近pyvespaを通してVespaの機能をよりサポートするようになりました。本番環境へのデプロイがサポートされ、pyvespa経由でのVespaの高度な設定が追加されました! services.xml 関数を使用する。詳細は これら 例と詳細はノートに。
その結果、カスタムJavaコンポーネントを必要としないほとんどのVespaアプリケーションはpyvespaで構築できます。
逸話である:
pyvespaの高度なコンフィギュレーション機能は、実はFastHTMLが ft-コンポーネントがラップされ、HTMLタグに変換される方法にヒントを得ています。pyvespaでは vt-コンポーネントは同様の操作を行い、ベスパに変換する。 services.xml タグご興味のある方は このPR もっと詳しくこのアプローチは、サポートされているすべてのタグに対してカスタムクラスを実装するのに比べて、多くの作業を節約することができます。
さらに、pyvespaを使ってVespaアプリケーションを構築する過程で、実地検証を行うことができました。
ソフトウェア
VespaをネイティブにサポートするColPaliエンベッダーとして、それはまだ 仕掛品 の状態であれば、推論を完了するためにGPUが必要であることがわかる。Colabでの実験から、T4インスタンスで十分であると結論づけました。
データセットのPDFページをVespaに埋め込む前に埋め込みを生成するために、サーバレスGPUプロバイダ(モーダル (私たちのお気に入りのひとつ)。しかし、データセットが6,692ページしかないため、Macbook M2 Proを使い、5〜6時間かけてこれらの埋め込みを作成した。
信託統治
選択肢はたくさんある。AWS、GCP、Azureのような従来のクラウド・プロバイダーを利用することもできるが、その場合、インフラをセットアップして管理するための労力が必要になるし、他の人がアプリケーションを複製するのも難しくなる。
我々は次のことを学んだ。 ハギング・フェイス・スペース 必要に応じてGPUを追加できるホスティングサービスを提供している。また、ワンクリックで "Clone this space "ボタンが表示されるので、他の人がアプリケーションをコピーするのも簡単だ。
我々は次のことを発見した。 アンサー を作成する。 再利用可能なライブラリこれはHugging Face SpacesにFastHTMLアプリケーションをデプロイするのに使えます。しかし、さらに調べてみると、彼らのアプローチはDocker SDKを使ってSpacesを操作しており、実際にはもっとシンプルな方法があることがわかりました。
を使用する。 カスタムPythonスペース.
基礎 huggingface-hub ドキュメンテーション::
これは公式のワークフローではないが、SDKとしてGradioを選択し、ポート7860でフロントエンド・インターフェースを提供することで、Spacesで独自のPython +インターフェース・スタックを実行することができる。
逸話2: ドキュメントの中で、サービスが提供されるポートが次のようになっているという誤字があります。 7680.幸いなことに、正しいポートが次のものであることを見つけるのに時間はかからなかった。 7860を提出した。 PRHugging FaceのCTOであるJulien Chaumond氏によってマージされ、バグが修正された。チェックリストのタスク完了!
視覚言語モデル
ビジュアルRAGの「生成」の部分では、Vespaから得られた上位k位の文書に基づいて回答を生成するための視覚言語モデル(VLM)が必要である。
ベスパ・ネイティブ・サポート LLM(大規模言語モデル)は、外部または内部で統合されていますが、VLM(視覚言語モデル)はまだVespaでネイティブにサポートされていません。
昨年、OpenAI、Anthropic、Googleが優れた視覚言語モデル(VLM)を発表し、この分野は急速に成長している。パフォーマンス上の理由から、私たちはより小さなモデルを選びたかった。 ジェミニ APIは最近、開発者のエクスペリエンスを向上させた。 gemini-1.5-flash-8b.
もちろん、本番環境でモデルを選択する前に、さまざまなモデルを定量的に評価することが推奨されるが、これはこのプロジェクトの範囲外である。
ビルド
テクノロジー・スタックが整ったので、アプリケーションの構築を開始できる。アプリケーションのハイレベルなアーキテクチャは以下の通りだ:

ベスパ・アプリケーション
ベスパの主なコンポーネントは以下の通り:
- フィールドとタイプを含む文書 スキーマ定義.
- ランクプロフィール 定義
- アン
services.xml設定ファイル。
全員だ。 可能 pyvespaを使ってPythonで定義されていますが、生成された設定ファイルをチェックすることもお勧めします。 app.package.to_files() をご覧ください。詳細については pyvespaドキュメント.
ランキング構成
ベスパの最も過小評価されている特徴のひとつは、次のようなものだ。 ステージ別ランキング 機能複数のランキング・プロファイルを定義でき、各プロファイルには、コンテンツ・ノード(フェーズ 1 とフェーズ 2)またはコンテナ・ノード(フェーズ 1 とフェーズ 2)で実行できる、異なる(または継承された)ランキング・フェーズを含めることができます。グローバルステージ).
これにより、さまざまなユースケースを個別に処理し、それぞれの状況に応じて遅延、コスト、品質の理想的なバランスを見つけることができる。
コンピュートをデータ側に移動させるというアーキテクチャの逆転について、CEOのジョン・ブラッツェスのコメントをお読みください。 このブログ記事.
このアプリケーションでは、3つの異なるランキング構成を定義した:
銘記する 取り出すこの段階は、クエリーを yql 指定されランキング戦略は、ランキング構成ファイル(デプロイ時に提供されるアプリケーション・パッケージの一部)で指定される。
1.ピュア・コルパリ
私たちのアプリケーションでこのランキング・モードに使用されているyqlは次のとおりである:
select title, text from pdf_page where targetHits:{100}nearestNeighbor(embedding,rq{i}) OR targetHits:{100}nearestNeighbor(embedding,rq{i+1}) .. targetHits:{100}nearestNeighbor(embedding,rq{n}) OR userQuery();
私たちはまた hnsw.exploreAdditionalHits このパラメータは、検索段階で関連するマッチを見逃さないように、300に調整される。これにはパフォーマンス・コストがかかることに注意してください。
この中には rq{i} はクエリのi番目 トークン (HTTPリクエストのパラメータとして提供されなければならない)。n は取得するクエリートークンの最大数である(このアプリケーションでは64を使用)。
このランキング構成では max_sim_binary Vespaの最適化されたハミング距離計算機能を利用したランキング式(詳しくは ColPaliを数十億ドルに拡大.これはランキングの第一段階で使用され、上位100試合はColPaliエンベッディングの完全な浮動小数点表現を使って再ランキングされる。
2.純粋なテキストベースのランキング(BM25)
この場合、私たちがベースにしているのは weakAnd ドキュメントを取得する。
select title, text from pdf_page where userQuery();
ランキングの段階では bm25 フェーズⅠのランキングを実施する(フェーズⅡは実施しない)。
最適なパフォーマンスを得るためには、テキストベースと視覚ベースのランキング機能を組み合わせて使用することが望ましいだろう。 相互ランキング統合)が、このデモでは最適な組み合わせを見つけるのではなく、それらの違いを示したい。
3.BM25とコルパリのミックス
検索段階では、純粋なColPaliランキング構成と同じyqlを使用する。
いくつかのクエリ、特に短いクエリでは、純粋なColPaliはテキストなし(画像のみ)の多くのページにマッチする一方、私たちが探していた答えの多くは、実際にはテキストのあるページに表示されることに気づきました。
この問題を解決するために、BM25スコアとColPaliスコアを組み合わせた第2段階のランキング式を追加した。max_sim + 2 * (bm25(title) + bm25(text))).
この方法は単純なヒューリスティックに基づいているが、ランキング実験を行うことによって、さまざまな特徴の最適な重みを見つける方が有益であろう。
ベスパのフラグメント生成
検索フロントエンドでは、特定の単語を含む原文からの抜粋を 太字 (ハイライト)表示。

一致するクエリー用語のスニペットを文脈に沿って表示することで、ユーザーはその結果が自分の情報ニーズを満たす可能性が高いかどうかを素早く判断することができる。
Vespaでは、この機能は「ダイナミック・スニペット」と呼ばれ、どの程度周囲の文脈を含めるか、一致する単語を強調するために使用するラベルなど、調整可能なさまざまなパラメーターを持っている。
このデモでは、比較のために、スニペットとページの全抽出テキストの両方を示している。
結果の視覚的ノイズを減らすため、ユーザーのクエリーからストップワード(and, in, theなど)を削除し、ハイライトされないようにした。
ベスパの推奨クエリー
検索における一般的な機能として、ユーザーの入力に合わせて表示される「検索候補」がある。
実際のユーザークエリは、しばしば事前計算された結果を提供するために使用されるが、ここでは分析するユーザートラフィックがない。

この例では、ユーザが入力した接頭辞とPDFページから生成された関連する質問とをマッチさせる単純な部分文字列検索を使用して、提案を提供しています。
これらの提案を得るために使用するyqlクエリは次のとおりです:
select questions from pdf_page where questions matches (".*{query}.*")
このアプローチの利点のひとつは、推薦文に登場する疑問が、利用可能なデータの中に答えがあることを確認できることである!
提案された質問を生成するページが常に上位3つの回答に表示されるようにすることもできましたが(ソート設定にユーザークエリとドキュメントが生成した質問の間の類似性メトリックを追加することによって)、これはColPaliモデルの機能を実証するという観点からは少し「ズル」でした。
ユーザーエクスペリエンス
私たちは幸運にも、同大学のチーフ・サイエンティストを迎えることができた。 ジョー・バーグム 彼は私たちから素晴らしいUXのフィードバックを得た。彼はUXを "速く、流動的に "するよう私たちに迫った。人々はGoogleに慣れているので、検索(とRAG)のユーザー体験にとってスピードが重要であることは間違いない。AIコミュニティでは、多くの人が5秒から10秒待つことに満足しているようだが、これはまだやや過小評価されていることだ。そして、私たちはミリ秒単位の応答時間を実現したいと考えている。
彼のフィードバックに基づいて、結果を表示する前にVespaから完全な画像と類似度マッピングテンソルが返されるのを待たないように、段階的なリクエストプロセスを設定する必要がある。
解決策は、まず結果から最も重要なデータだけを抽出することだ。私たちにとって、これは titleそしてurlそしてtextそしてpage_noまた、最初の検索結果表示用に、画像の縮小(ぼかし)バージョン(32x32ピクセル)も用意されています。これにより、結果を即座に表示し、バックグラウンドで完全な画像と類似性マッピングの読み込みを続けることができます。
完全なUXプロセスを以下に示す:
 遅れの主な原因は以下の通りだ:
遅れの主な原因は以下の通りだ:
- ColPaliエンベッディングを生成するための推論時間(クエリーのTokenの数に応じてGPU上で行われる)
- そこで
@lru_cacheデコレータを使うことで、同じクエリに対して何度も埋め込みを再計算する必要がなくなります。
- そこで
- Face SpacesとVespa(TCPハンドシェイクを含む)間のネットワーク待ち時間をハグする。
- また、完全な画像の転送時間も大きい(1画像あたり約0.5MB)。
- 類似性マッピングテンソルのサイズはより大きい(
n_query_tokensxn_images(1030パッチ×128)。
- 類似マッピングされたハイブリッド画像を作成するのはCPU負荷の高い作業だが、これは
fastcoreな@threadedデコレータはマルチスレッドのバックグラウンドタスクで実行され、各画像は対応するエンドポイントをポーリングして、類似マッピングの準備ができたかどうかをチェックする。
ストレステスト
トラフィック急増時のアプリケーションのパフォーマンスが心配だったので、簡単なストレステスト実験を行った。実験はブラウザの開発ツールを使い、リクエストを送信することで行われた。 /fetch_results cURLコマンドをコピーし(キャッシュは有効にしていない)、10台の並列端末でループさせた。 (この時点で @lru_cache 装飾家)
結局
テストは非常に基本的なものでしたが、最初のテストでは、検索スループットのボトルネックは、Huggingface空間のGPU上でColPaliエンベッディングを計算することであることが示されました。一方、Vespaバックエンドは、非常に低いリソース使用量で、毎秒20以上のクエリを簡単に処理することができました。これはデモには十分すぎるほどだと思います。もし規模を拡大する必要があるならば、私たちの最初のステップは、Huggingface空間により大きなGPUインスタンスを有効にすることでしょう。
ベスパのアプリケーションは、以下のグラフに示すように、負荷がかかった状態でも良好な性能を発揮します。


FastHTMLの使用についての考察
FastHTML を使って得た主な収穫は、フロントエンドとバックエンドの開発の垣根が取り払われたことです。コードは緊密に統合され、私たち全員がアプリケーションのあらゆる部分を理解し、貢献することができます。これは過小評価すべきではありません。
ブラウザの開発ツールを使ってフロントエンドのコードを検査し、そのほとんどを実際に見て理解することができたのは本当に楽しかった。
スタンドアロンのフロントエンド・フレームワークを使う場合に比べて、開発とデプロイのプロセスが大幅に簡素化される。
これによって、我々は 紫外線 経営上 所有権 これは Python における依存関係の扱い方を劇的に変えるものです。
トーマスの見解
データサイエンスとAIのバックグラウンドを持つ開発者として、Pythonを好みますが、いくつかのJSフレームワークを使ったことがあり、私の経験は非常にポジティブなものでした。プロジェクトに複雑さを加えることなく、フロントエンド関連のタスクに取り組むことができると感じました。アプリケーションのあらゆる部分を理解できることが本当に楽しかったです。
アンドレアスの見解
私は長い間Vespaに取り組んできましたが、Pythonやフロントエンド開発にはあまり手を出していませんでした。最初の1、2日は少し圧倒された感じでしたが、フルスタックで作業でき、自分の変更の効果をほぼリアルタイムで確認できるのはとてもエキサイティングです!大きな言語モデルの助けを借りて、慣れない環境に入るのはこれまで以上に簡単です。Vespa内でテンソル式を使って画像パッチの類似度を計算し(ベクトルはすでにメモリに保存されていた)、検索結果と一緒に返すことで、より低いレイテンシとリソース消費で類似度マッピングを作成できるようになったのは本当によかった。
レアンドロの見解
React、JavaScript、TypeScript、HTML、CSSを使ったウェブ開発でしっかりとした基礎を持っている開発者として、FastHTMLへの移行は比較的簡単でした。フレームワークの直接的なHTML要素のマッピングは、私のこれまでの知識と非常に一致しており、学習曲線が短縮されました。主な課題は、標準的なHTML/JS構造とは異なるFastHTMLのPythonベースの構文に適応することでした。
必要なのは映像技術だけか?
我々は、VLM(Vision Language Model)からトークン・レベルのレイト・インタラクション・エンベッディングを利用することが、ある種のクエリには非常に強力であることを見てきた。
ColPaliに加え、私たちは昨年、視覚的検索における他の革新を見てきた。特に興味深いアプローチが2つある:
- ドキュメントのスクリーンショット埋め込み(DSE)5 - ドキュメントのスクリーンショットの高密度埋め込みを生成し、検索に利用するための二重エンコーダモデル。
- IBM ドクリング - 複数のタイプのドキュメント(PDF、PPT、DOCXなど)をMarkdownにパースするためのライブラリで、OCRを避け、代わりにコンピュータ・ビジョン・モデルを使用する。
Vespaはこれらのアプローチの組み合わせをサポートし、開発者が特定のユースケースに対して、レイテンシー、コスト、品質の最も魅力的なバランスを見つけることを可能にする。
Doclingや同様のツールによる高品質のテキスト抽出、ドキュメントのスクリーンショット埋め込みによる集中的な検索、テキストの特徴とColPaliのようなモデリングによる集中的な検索を組み合わせたアプリケーションを想定することができる。 MaxSim スコアはソートされる。もし本当にパフォーマンスを向上させたいのであれば、これらの機能すべてを以下のような機能と組み合わせることもできる。 XGBoost もしかしたら ライトGBM のGBDTモデルを組み合わせた。
したがって、ColPaliはテキスト中の抽出が困難な情報を検索可能にする強力なツールではあるが、万能薬ではなく、最適なパフォーマンスを得るためには他のアプローチと組み合わせる必要がある。
失われたリンク
モデリングは一時的なものだが、評価は永続的なものだ。
自動化された評価を追加することは、このデモの範囲を超えていますが、あなた自身のユースケースのための評価データセットを作成することを強くお勧めします。LLM-as-a-judgeを使ってブートストラップすることができます。 ブログ記事私たちがどのようなサービスを提供しているかについては、こちらをご覧ください。 search.vespa.ai (そのことに気づいて)。
Vespaは調整可能なパラメーターを数多く提供しており、さまざまな実験に対する定量的なフィードバックを提供することで、特定のユースケースに最も魅力的なトレードオフを見つけることができます。
評決を下す
ColPaliエンベッディングを使用して、VespaでPDFのビジュアルRAG検索を実行する方法を示すライブデモ・アプリケーションを構築しました。
ここまで読んでくださった方は、コードに興味があるかもしれない。コードは こちら アプリのコードを探す。
さあ、あなた自身のビジュアルRAGアプリを作ってみよう!
ビジュアル・リトリーバル、コルパリ、ベスパについてもっと知りたい方は、お気軽にご参加ください! ベスパのSlackコミュニティ 質問をしたり、コミュニティから助けを求めたり、ベスパの最新の開発について学んだりすることができます。
一般的な問題
ColPaliを使うには、推論にGPUを使う必要がありますか?
現在、妥当な時間でクエリーを推論するためには、GPUを使う必要がある。
将来的には、ColPaliのようなモデルの品質と効率(例えば、より小さな埋め込み)が改善され、より類似したモデルが出現することが期待される。 アンサーアイ-コルベール-スモール-v1ColBERTモデルは初めて開発され、オリジナルモデルの3分の1以下のサイズながら、その性能はオリジナルColBERTモデルを上回る。
こちらも参照 ベスパ・ブログ ベスパの使い方についてもっと知る answerai-colbert-small-v1.
ColPaliをVespaのクエリーフィルターと併用することは可能ですか?
できる。このアプリケーションでは、ページを published_year フィールドがありますが、フィルターオプションとしての機能はまだフロントエンドに実装されていません。
VespaがColPaliエンベッドをネイティブサポートするのはいつですか?
こちらも参照 このGitHubの課題.
これは何十億もの文書に対応できますか?
はい。Vespaは水平スケーリングをサポートしており、特定のユースケース向けにレイテンシ、コスト、品質のトレードオフを調整することができます。
このデモをColQwen2に対応させることはできますか?
それは可能だが、類似性マップの計算にはいくつかの違いがある。
こちらも参照 このノート 出発点として。
自分のデータでこのデモを実行できますか?
もちろんだ!付属の ノート あなたのデータを指して、ビジュアルRAGのためにあなた自身のVespaアプリケーションをセットアップすることができます。また、提供されたウェブアプリケーションをあなた自身のフロントエンドの出発点として使用することもできます。
書誌
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事



コメントはありません