
LLMメモリーシステムを実装する5つの方法

大規模言語モデル(LLM)アプリケーションを構築する際、メモリシステムは対話のコンテキスト管理、長期的な情報保存、意味理解を強化するための重要な技術の一つである。効率的なメモリシステムは、モデルが長い会話の一貫性を維持し、重要な情報を抽出し、さらには過去の会話を検索する機能を持つことができ、よりスマートで人間的な対話体験につながります。以下は、LLM記憶システムを実装する5つの方法である!
- ベクターメモリ OpenAIのエンベッディング技術を使ってメッセージをベクター表現に変換し、会話の履歴から意味検索を可能にするメモリシステム。
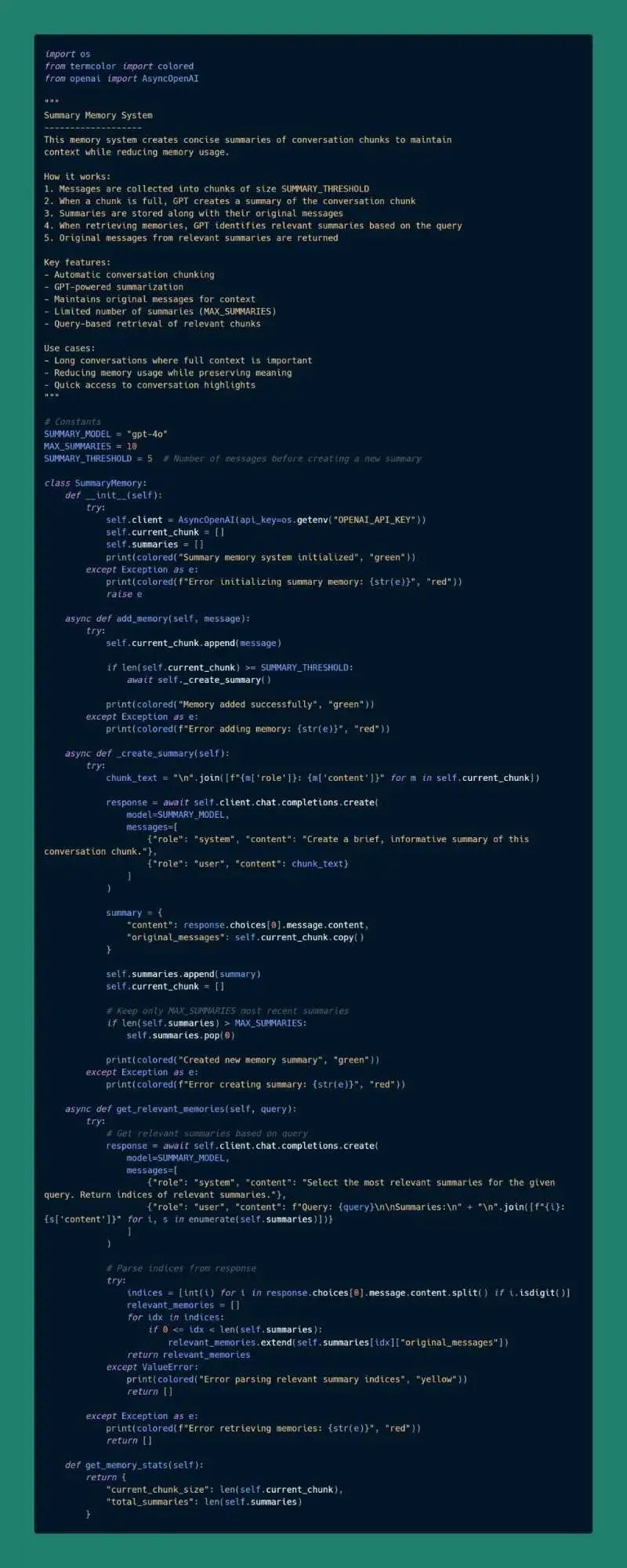
- 要約メモリ このメモリシステムは、ダイアログセグメントの簡潔な要約を作成することで、文脈の整合性を維持しながらメモリ使用量を削減する。
- タイム・ウィンドウ記憶 この記憶システムは、最近のニュースと重要な長期記憶を、時間と重要性に基づく二重記憶方式で組み合わせる。
- キーワード・メモリー このメモリー・システムは、自然言語処理技術を用いて、APIを呼び出すことなく、キーワードのマッチングに基づいてメモリーのインデックスを作成し、検索する。
- 階層記憶 これは最も複雑な記憶システムで、即時文脈記憶、短期要約記憶、長期埋め込み記憶の3層構造を持つ。
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事




コメントはありません