
セサミ、AI音声対話をより自然にする会話音声モデルCSMをリリース

Brendan Iribe氏、Ankit Kumar氏、そしてSesameチームによる最近のブログポストでは、会話音声生成分野における同社の最新研究、Conversational Speech Model(CSM)について述べられている。CSM)である。このモデルは、現在の音声アシスタントとの対話における感情や自然さの欠如に対処し、AIの音声対話を人間レベルに近づけるために設計されている。
声の存在感」を求めて「恐怖の谷」を越える。
セサミ・チームは、音声は人間にとって最も親密なコミュニケーション媒体であり、文字通りの意味をはるかに超えた豊富な情報を含んでいると考えている。しかし、既存の音声アシスタントは感情表現が乏しく、平板な口調であることが多く、ユーザーとの深いつながりを築くことが難しい。そのような音声アシスタントを長期間使用すると、ユーザーは失望を感じるだけでなく、疲れさえ感じるだろう。
この問題を解決するために、セサミは "ボイス・プレゼンス "というコンセプトを開発した。"ボイス・プレゼンス "とは、ボイス・インタラクションがリアルに感じられ、理解され、評価されることを意味し、CSMモデルはこのゴールに向けた重要なステップである。セサミ・チームは、単にツールを作っているのではなく、ユーザーとの信頼関係を築く対話のパートナーであることを強調している。
声のプレゼンス」を実現するのは簡単なことではなく、以下の重要な要素を組み合わせる必要がある:
- エモーショナル・インテリジェンス: ユーザーの気分の変化を認識し、それに対応する。
- 対話のダイナミクス: 話す速度、間、中断、強調など、対話の自然なリズムを把握する。
- 状況認識: さまざまな対話のシナリオに合わせて、トーンや表現を調整する。
- 一貫した性格: AIアシスタントの人格の一貫性と信頼性を維持する。
CSMモデル:シングルステージ、マルチモーダル、より効率的
これらの目標を達成するために、セサミ・チームは新しい会話音声モデル、CSMを提案した。CSMは、エンド・ツー・エンドのマルチモーダル学習フレームワークを使用し、会話の履歴からの情報を使用して、より自然で首尾一貫した音声を生成する。
従来の音声合成(TTS)モデルとは異なり、CSMモデルはRVQ(residual vector quantisation)トークンを直接操作する。この設計により、従来のTTSモデルでセマンティック・トークンに起因する情報ボトルネックが回避されるため、音声のニュアンスをよりよく捉えることができる。
シーエスエム モデルの構造設計も非常に素晴らしい。これは2つの自己回帰変換器を採用している:
- マルチモーダルなバックボーン: インターリーブされたテキストと音声情報を処理し、RVQコードブックのレイヤーゼロを予測する。
- オーディオデコーダー: 各コードブックに対して異なる線形ヘッダーを使用し、残りのN-1層を予測して音声を再構成する。
この設計により、デコーダーはトランクよりもはるかに小さくなり、エンド・ツー・エンドのモデルを維持しながら低遅延の音声生成が可能になる。

CSMモデルの推論プロセス
さらに、学習過程におけるメモリのボトルネック問題を解決するために、Sesameチームは計算配分スキームを提案した。このスキームでは、音声フレームのランダムなサブセットに対してのみ音声デコーダを学習させることで、モデルの性能に影響を与えることなくメモリ消費量を大幅に削減します。

トレーニングの配分
実験結果:人間のレベルに近いが、まだギャップがある
セサミ・チームは、約100万時間の英語音声を含むデータセットでCSMモデルを訓練し、様々なメトリクスを使ってモデルの性能を徹底的に評価した。
評価結果は、CSMモデルが従来の指標である単語誤り率(WER)と話者類似度(SIM)において人間レベルに近いことを示している。
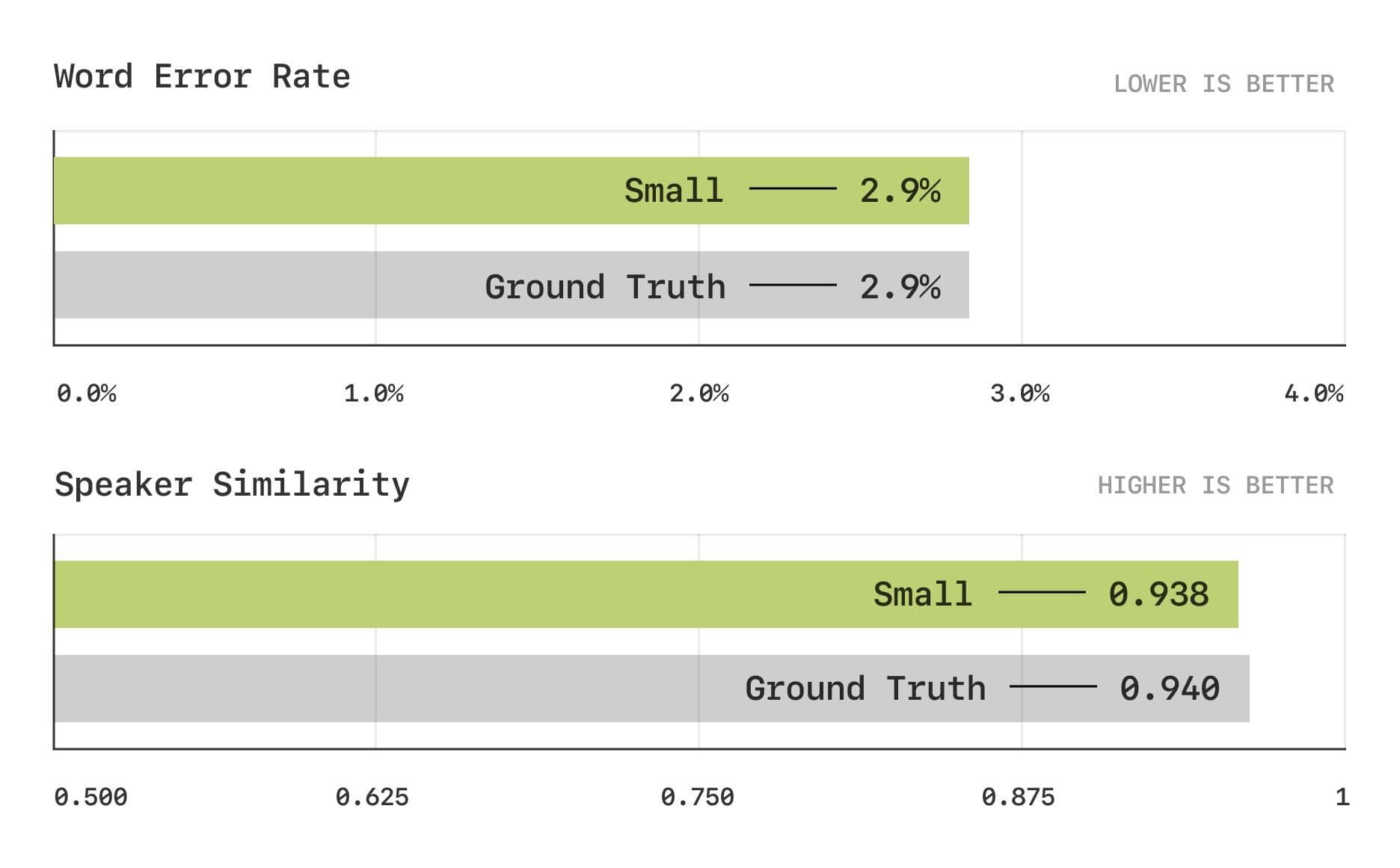
単語誤り率と話者の類似性テスト
発音と文脈理解におけるモデルの能力をより深く評価するため、セサミ・チームは、同音異義語の曖昧性解消と発音の一貫性テストを含む、音声書き起こしに基づくベンチマーク・テストの新しいセットも導入した。その結果、CSMモデルはこれらの分野でも優れた性能を発揮し、モデルサイズが大きくなるにつれて性能が向上することが示された。
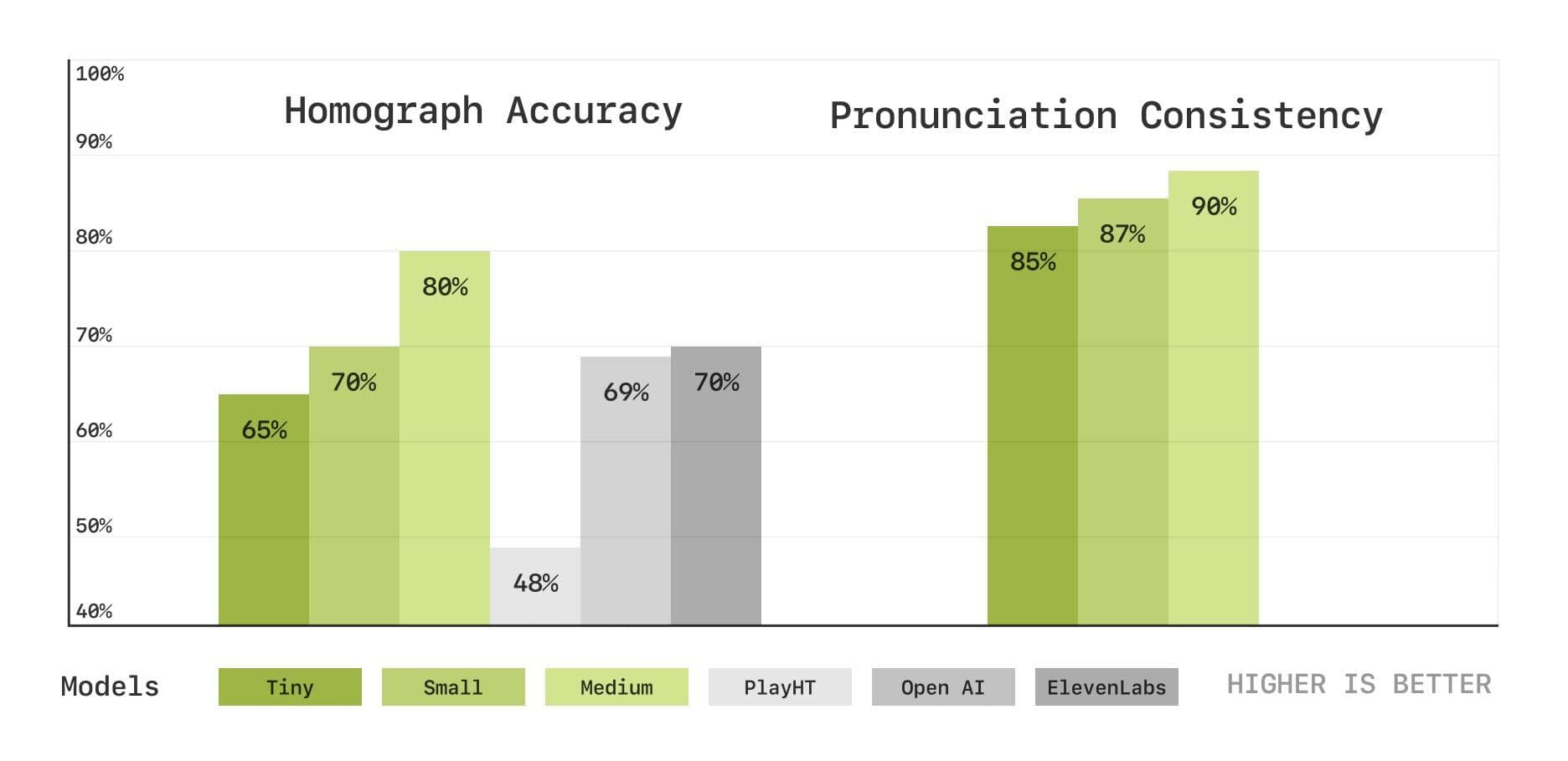
同音異義語の曖昧性解消と発音の一致テスト
しかし、主観的な評価という点では、CSMモデルと実際の人間の音声との間にはまだギャップがある。セサミ・チームは、Expressoデータセットを使用して2つのCMOS(Comparative Mean Opinion Score)研究を行った。その結果、文脈がない場合、聞き手はCSMで生成された音声と実際の人間の音声に対して同程度の選好を示した。しかし、文脈情報が提供された場合、聞き手は実際の人間の音声を有意に好んだ。このことは、対話における微妙なリズムの変化を捉える上で、CSMモデルにはまだ改善の余地があることを示唆している。
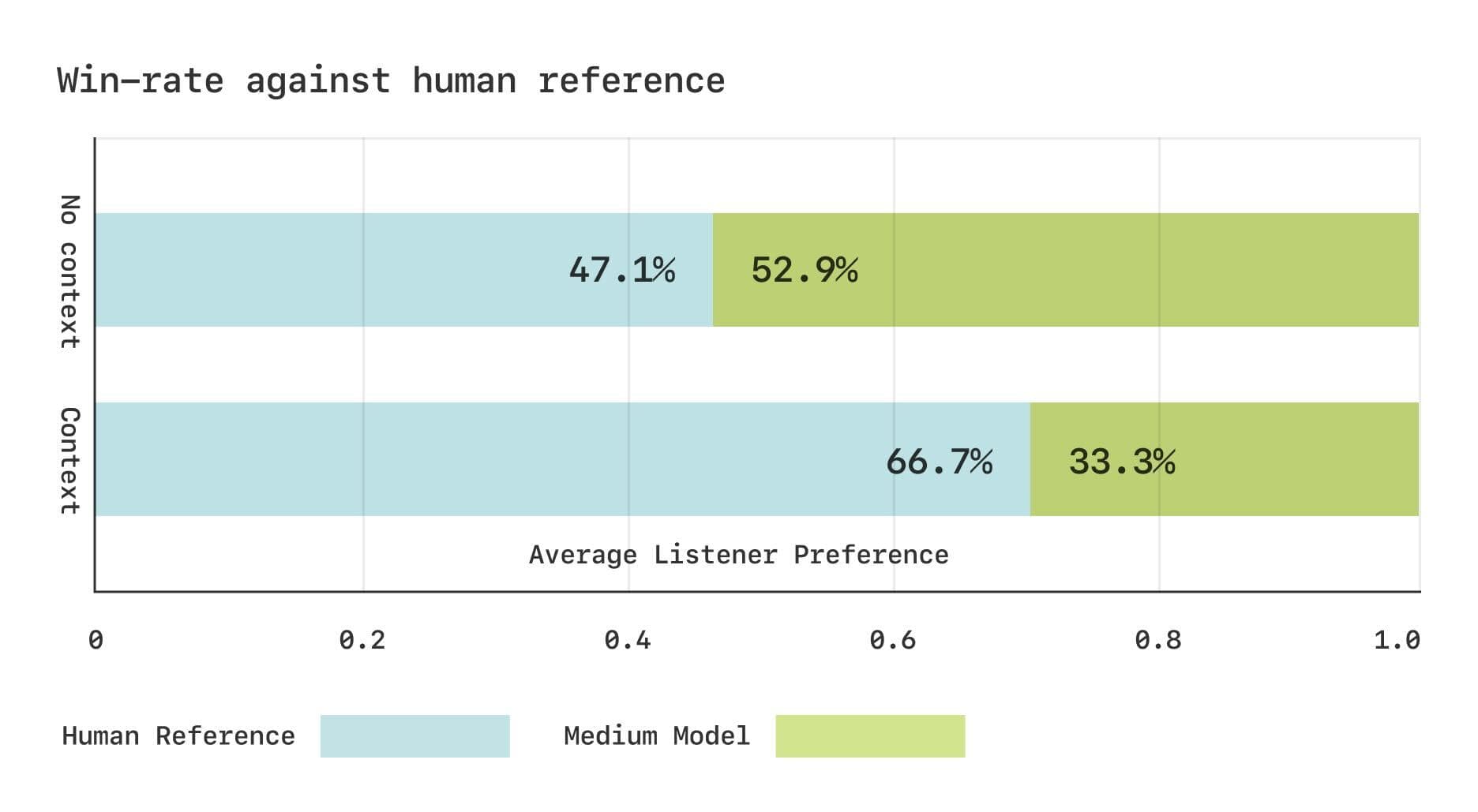
Expressoデータセットの主観的評価結果
オープンソースの共有、今後の展望
オープンソースの精神に則り、セサミ・チームはCSMモデルの主要コンポーネントをオープンソース化し、コミュニティの相互発展に役立てる計画だ。
https://github.com/SesameAILabs/csm
CSMモデルは大きな進歩を遂げたが、主に英語をサポートしており、多言語機能を改善する必要があるなど、まだいくつかの制約がある。セサミチームは、今後、CSMモデルのパフォーマンスをさらに向上させるために、モデルサイズの拡大、データセット容量の増加、言語サポートの拡大、事前学習言語モデルの使用の探求を続けると述べている。セサミチームは、研究の将来の方向性に自信を持っている。セサミチームは、AI対話の未来は完全二重モデル、すなわちデータから対話ダイナミクスを暗黙的に学習できるモデルにあると確信している。
全体として、セサミが発表したCSMモデルは、会話音声生成の分野における重要な前進であり、より自然で感情的なAI音声インタラクションを構築するための新しいアイデアを提供するものである。まだ改善の余地はあるが、セサミ・チームのオープンソース精神と将来への計画は、楽しみにする価値がある。
© 著作権表示
記事の著作権 AIシェアリングサークル 無断転載はご遠慮ください。
関連記事



コメントはありません